概要
CLAMは2020年にハーバード大学医学部ブリガム・アンド・ウイメンズ病院 病理部のMing Y.Lu氏らが発表した、スライド画像から特徴量を抽出し、スライド単位のラベルを用いて弱教師あり学習でクラス分類を行うスクリプトです。
スライド画像とラベルを用いてモデルに学習させることで、パッチ単位でラベルの特徴が強い箇所を推測することができます。
スライド単位のラベルを持つ画像に対して、スライドに含まれる多くの情報を活かすことでより効率的に学習が行えるという考え方のようです。
・イメージ図

基本的にはLinuxを前提としていますが、フォルダパスを一部編集することでWindowsでも使用できます。
概要と実際の使用した結果についてはこちらの記事をご参照いただけましたら幸いです。
➡ CLAM(Clustering-constrained Attention Multiple Instance Learning)実行してみた
本記事では、CLAMにおけるモデル学習時の処理について、コードや出力を元に確認できたことを記載いたします。CLAMを使ってみた方や調べてみたい方にとって、少しでも参考になればと思います。
CLAMの実行ファイル
CLAMではおおよそ以下の順で処理を進めます。
1.create_patches_fp.py
各WSIをパッチに分割する処理。 二値化 ➡ 組織の輪郭情報作成 ➡ パッチ情報作成 ➡ WSI単位でパッチ情報を含む.h5ファイル等を出力するコード。2.extract_features_fp.py
各スライドをパッチ単位でresnet(ディープラーニングのモデル)に通して特徴量を抽出し、.ptファイル(特徴量)および.h5ファイル(特徴量,パッチ座標)に保存する処理。 このステップで画像から低次元の特徴量を抽出することで、後の学習において学習時間の大幅削減や計算コストの抑制ができるとのことです。3.create_splits_seq.py
クロスバリデーション用のfold数に合わせて、各スライドをtrain,val,testに分けたcsvファイル等を保存する処理。
4.main.py 本記事の対象
extract_features_fp.pyで出力した特徴量データを用いて、アテンションネットワークを通してモデルの学習を行い、パラメータ概要、fold情報、fold毎のモデルファイル(.pt)、予測結果(.pkl)等を保存する処理。
5.eval.py
学習したモデルの検証を行う処理。スライド単位のラベルの予測結果等を出力します。6.create_heatmaps.py
4.で学習したモデルとスライド画像から、パッチ単位でラベルの特徴の強さを示すヒートマップを作成する処理。全体的にはおおよそ以下のような流れになります。

今回は、上記4.main.py のアテンションネットワークについて見ていきたいと思います。
main.pyの処理ではモデルがMILとCLAMに分かれていますが、MILは比較のためのベースラインとして実装されているため、本記事では特にCLAMについて記載いたします。
CLAMの繰り返し図
main.pyでは全体としては以下のような繰り返し処理が行われています。
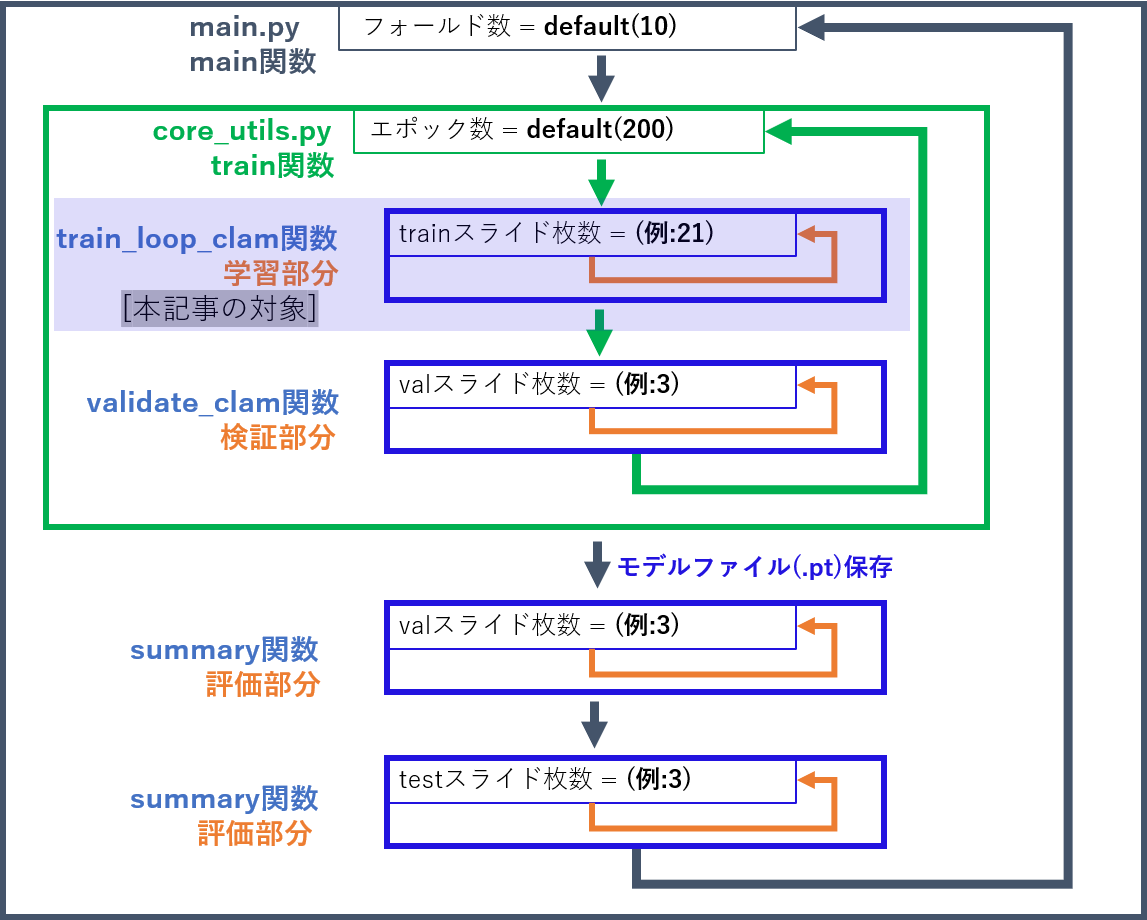
フォールド数:
交差検証のフォールド数
(各フォールドにおける学習, 検証, テストの振り分けは 3.create_splits_seq.py にてcsvで出力)
本記事では、上記塗りつぶし部分で示された学習部分の主な箇所を説明したいと思います。
また、厳密には引数等を変更するなどにより多くの分岐が見られますが、基本的にデフォルト設定を前提として記載しております。
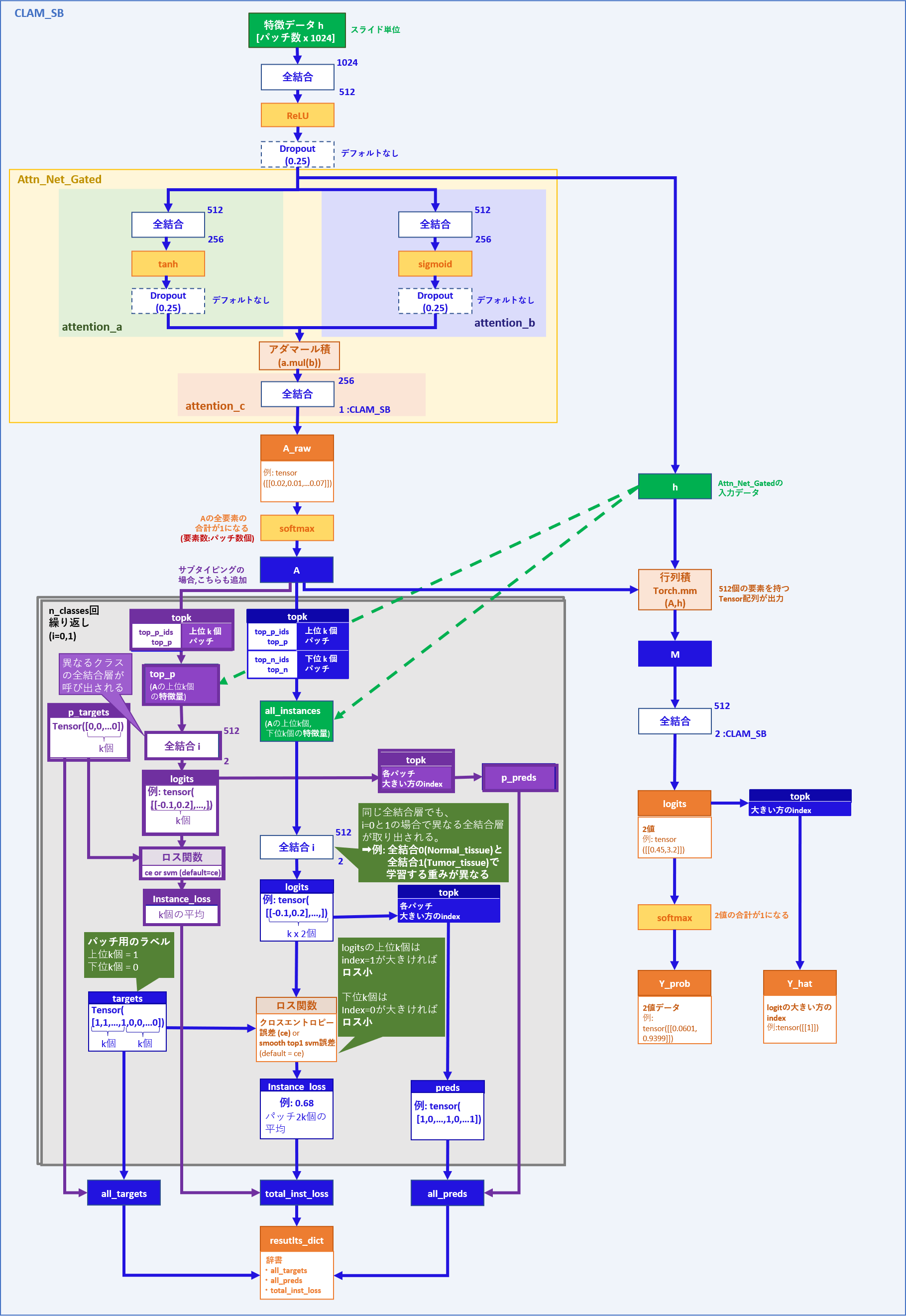
CLAMの構造
CLAMには、大きく2クラス分類を行うCLAM_SBクラスと、3クラス分類を行うCLAM_MBクラスの2つがあります。2クラス分類には腫瘍vs正常とサブタイピングがあります。
(main.pyのコマンド引数にて、『--task task_2_tumor_subtyping』 と 『--subtyping』を指定することで2クラスのサブタイピングとなります。)
大まかなネットワークとしては以下のような構造になっております。
CLAM_SB
CLAM_MB
主要なクラス、メソッド、関数を表示していますが、全てのクラスやメソッド、変数までは記載しておりません。
モデル引数
各モデルのネットワーク説明の前に、モデルのインスタンスを作成する際の引数について整理します。
モデルへの引数には辞書形式のmodel_dictと、変数instance_loss_fnが用いられています。
model_dictにはコマンド実行時の引数などに応じて以下のような値が入ります。
model_dict =
{
"dropout": args.drop_out, # ドロップアウトを用いるかどうか, default=False
"n_classes": args.n_classes, # クラス数,task引数=’task_1_tumor_vs_normal’=> 2, ‘task_2_tumor_subtyping’=> 3
"subtyping": True, # サブタイピングをするかどうか,task引数= “task_2_tumor_subtyping”の場合True, default=False
"size_arg": args.model_size, # モデルサイズ, コマンド実行時のmodel_size引数= small 又は big, default=small
"k_sample": args.B # アテンションスコアを元に使用するパッチ数/2, default=8
}
instance_loss_fn = instance_loss_fn # inst_loss引数, svm,ce,None default=None
# ※Noneでもce同様クロスエントロピー誤差が用いられる
・その他gateという引数もありますが、基本的にTrueが選択されるようになっています。
・モデルサイズはsmall [1024, 512, 256] と big [1024, 512, 384] がありますが、本記事ではデフォルトのsmallのケースを記載します。
上記を引数として、CLAM_SB又はCLAM_MBクラスのインスタンスを作成します。
次に、CLAM_SBに特徴量データhを通す際の処理を見ていきます。
CLAM_SBでの処理
CLAMでは、パッチ毎の特徴量をアテンションネットワークに通し、パッチ単位の分類とスライド単位の分類を行い、それぞれの分類に対してロスを計算しています。
そのため、ここでも以下3つに分けて見ていきます。
①アテンションネットワーク
②パッチ単位学習部分
③スライド単位学習部分
① アテンションネットワーク
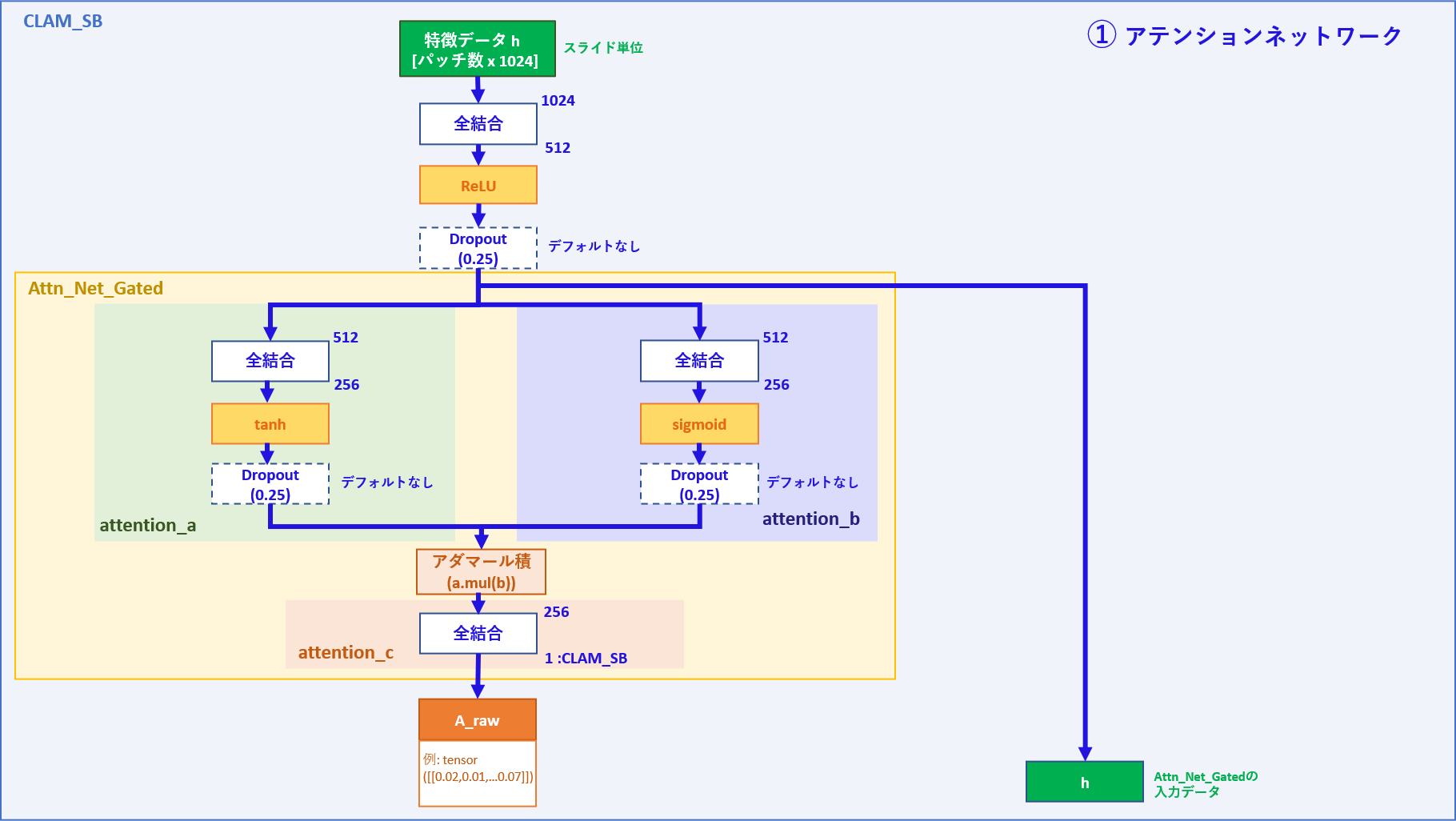
| 入力データ | メモ |
|---|---|
| h | パッチ数 x 1024次元の特徴量 |
| 出力データ | メモ |
|---|---|
| h | パッチ数 x 512次元の特徴量 |
| A_raw (A) | パッチ数 x 1次元のアテンションスコア |
処理:
データローダーからスライド単位で特徴量データhが入ってきます(バッチ数=1)
入力データhは最初の全結合層を通り、その後、Attn_Net_Gatedのネットワークを通してアテンションスコアAが出力されます。
最初の全結合層を通った後をh'とすると、
attention_aではh'が全結合層を通り512次元=> 256次元となった後にtanh関数で各値が-1~1に変換されます。
結果、特徴量の値が大きい程1に近くなると思われます。
attention_bではh'が全結合層を通り512次元=> 256次元となった後にsigmoid関数で各値が0~1に変換されます。
こちらも、特徴量の値が大きいほど1に近くなると思われます。
attention_cではattention_aとattention_bのアダマール積(要素積)が求められ、全結合層を通ることでアテンションスコアとしてパッチ毎に1つの値が出力されます。
コマンドの引数でdrop_out=Trueとした場合は、図の位置に25%のdrop-out層が配置されます。
最初の全結合層を通ったhと、attention_cを通ったアテンションスコアAが返り値として出力されます。 (hは、model_clam.pyのAttn_Net_Gatedクラスではx表記)
Aは後にsoftmax関数を通した値との区別のためA_rawとされます。
本記事のアテンションネットワークとは構造は異なりますが、
画像領域で用いられるアテンションについてこちらの記事が参考になりました。
② パッチ単位学習部分

ここでの入力・出力データは部分的な処理としてみたものですので、
コード上は関数やメソッドの返り値として出力されるものではなく1つの変数として
見ていただけましたら幸いです。
| 入力データ | メモ |
|---|---|
| A_raw (A) | パッチ数 x 1次元のアテンションスコア |
| 出力データ | メモ |
|---|---|
| result_dict | 辞書 (all_targets, all_preds, total_inst_loss) |
処理:
A_rawがsoft-max関数を通してAに変換されます。
この時点で、各パッチがアテンションスコアを1つ持っている状態となっています。
(アテンションスコア:全パッチの値の合計が1となる値)
ここで、アテンションスコア上位 k 個、下位 k 個のパッチのインデックスを元に、
k x 2個のパッチについて特徴量 h (①の出力値)を抽出しall_instancesとします。
※ k個 = main.pyの引数Bで指定した数(default = 8)
次に、all_instancesをクラス毎に異なる全結合層iに通します。
CLAM_SBでは、スライドのクラスがnormal_tissueの場合はi=0 で全結合層を通して
各パッチの値が2つのlogitsとなります。
クラスがtumor_tissueの場合はi=1で別の全結合層を通して同じく各パッチ値が2つのlogitsとなります。
各クラスで同形状の異なるネットワークにて別々に重みを学習する形になります。
例:logits
| Tensor( | [[0.04,0.01], | [0.03,-0.05], | …, | [-0.12,0.08]]) |
|---|---|---|---|---|
| パッチ 0 | パッチ 1 | … | パッチ 2 x k -1 |
また、all_targetsがk x 2個のパッチのラベルとして用意されます。
前半 k個が1, 後半 k個が0からなるテンソルで、正解のインデックスと考えられます。
例:all_targets
| Tensor([ | 1,1,…1, | 0,0,…0 | ]) |
|---|---|---|---|
| k個 | k個 |
all_instancesをall_targetsと併せて損失関数に通すことで、instance_lossを出力します。
アテンションスコア上位k個については、パッチ毎の2つの値の内、インデックス1の方が大きければロスが小さくなります。逆に下位k個については、インデックス0の方が大きければロスが小さくなります。
こういった手法により、アテンションスコアが高いほどスライドの特徴を良く表し、逆にスコアが低いほどスライドの特徴を表さない方向に学習をしていくものと思われます。
例えば、正常(normal_tissue)スライドの場合は、正常の特徴を表すパッチほどアテンションスコアが高い方向へ学習していると考えられます。
ロスの計算とは別に、logitsからパッチ毎の2値の内、値が大きい方のインデックスを記録したテンソルをall_predsとします。
厳密にはinst_evalメソッド内で上記の通りall_targets, all_preds, instance_lossとなっており、forwardメソッド内ではそれぞれtargets, preds, instance_lossとなっているようです。
腫瘍vs正常ではなくサブタイピングの場合、癌のサブタイプが互いに排他的であることを仮定として、追加で以下の処理が行われます。
(図内紫色部分)
Ⓐ アテンションスコア上位k個のパッチの特徴量をスライドラベルと異なるクラスの全結合層に通します。(logits)
Ⓑ 要素の値が0のk個の項目を持つテンソルp_targetsと損失関数でロス(instance_loss)を求めます。
Ⓒ logits(2値)の大きい方のインデックスをp_predsとします。
Ⓓ p_targetsはall_targetsに、p_predsはall_predsに追加し、instance_lossは下記のtotal_inst_lossの値に追加します。
例えば「サブタイプ1」に分類されるスライドについて、アテンションスコアの高いパッチが「サブタイプ2」の特徴を示した場合、同時に存在するはずのない「サブタイプ2」について陽性の判断をしたということで、"偽陽性"としてロスに加算する、といった考え方のようです。
CLAM_SB(正常 vs 腫瘍)の場合は、1つのスライドに正常部分と腫瘍部分が共存するため、上記処理は行われていません。
上記を各クラスで計算し、ラベル(all_targets, p_targets), 予測値(all_preds, p_preds)をall_targets, all_predsリストに追加し、instance_lossはtotal_inst_lossとして、この3つがresult_dict辞書に入ります。
サブタイピングの場合、total_inst_lossには別クラスの全結合に通した際の
instance_lossも追加されているため、クラス数(全結合層の数)で平均されます。
③ スライド単位学習部分
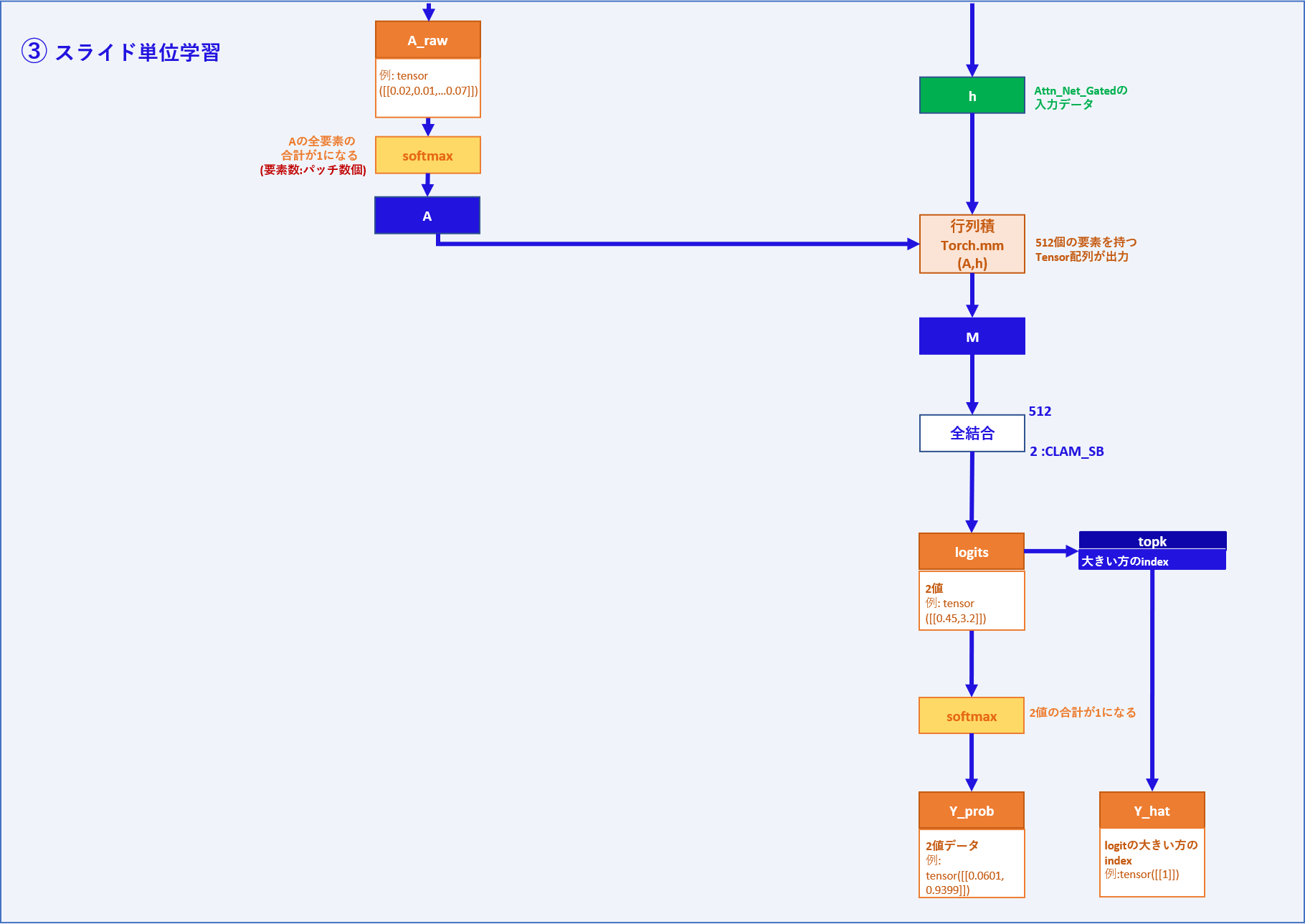
ここでの入力・出力データは部分的な処理としてみたものですので、
コード上は関数やメソッドの返り値として出力されるものではなく1つの変数として
見ていただけましたら幸いです。
| 入力データ | メモ |
|---|---|
| A | パッチ数 x 1次元のアテンションスコア |
| h | パッチ数 x 512次元の特徴量 |
| 出力データ | メモ |
|---|---|
| logits(スライド単位) | Aとhの行列積を全結合層に通して2値となったテンソル |
| Y_prob | logitsをsoft_max関数に通して、合計1になるように調整したテンソル |
| Y_hat | logitの2値の内大きい方のインデックスを取った予測値 |
処理:
Aを重みとしてhとの行列積を取ることで、512個の要素を持つテンソルMを出力します。
Mは全結合層を通り、2つの値を持つテンソルlogitsとなります。
②のlogitsと同じ変数名ですが、こちらはスライド単位の値となります。
次に、logitsをsoftmax関数を通すことで正規化し、2値の合計が1となるY_probを出力します。
また、logitsの値が大きい方のインデックスを取ったテンソルをY_hatとします。
CLAM_SB全体としては、①~③から
A_raw、result_dict、logits(スライド単位)、Y_Prob、Y_hatを返り値としています。
CLAM_SB全体の主な入力データと出力データとしては、以下のようになると思われます。
| 入力データ | メモ |
|---|---|
| h | パッチ数 x 1024次元の特徴量 |
| 出力データ | メモ |
|---|---|
| A_raw | パッチ数 x 1次元のアテンションスコア |
| result_dict | 辞書 (all_targets, all_preds, total_inst_loss) |
| logits(スライド単位) | Aとhの行列積を全結合層に通して2値となったテンソル |
| Y_Prob | logitsをsoft_max関数に通して、合計1になるように調整したテンソル |
| Y_hat | logitの2値の内大きい方のインデックスを取った予測値 |
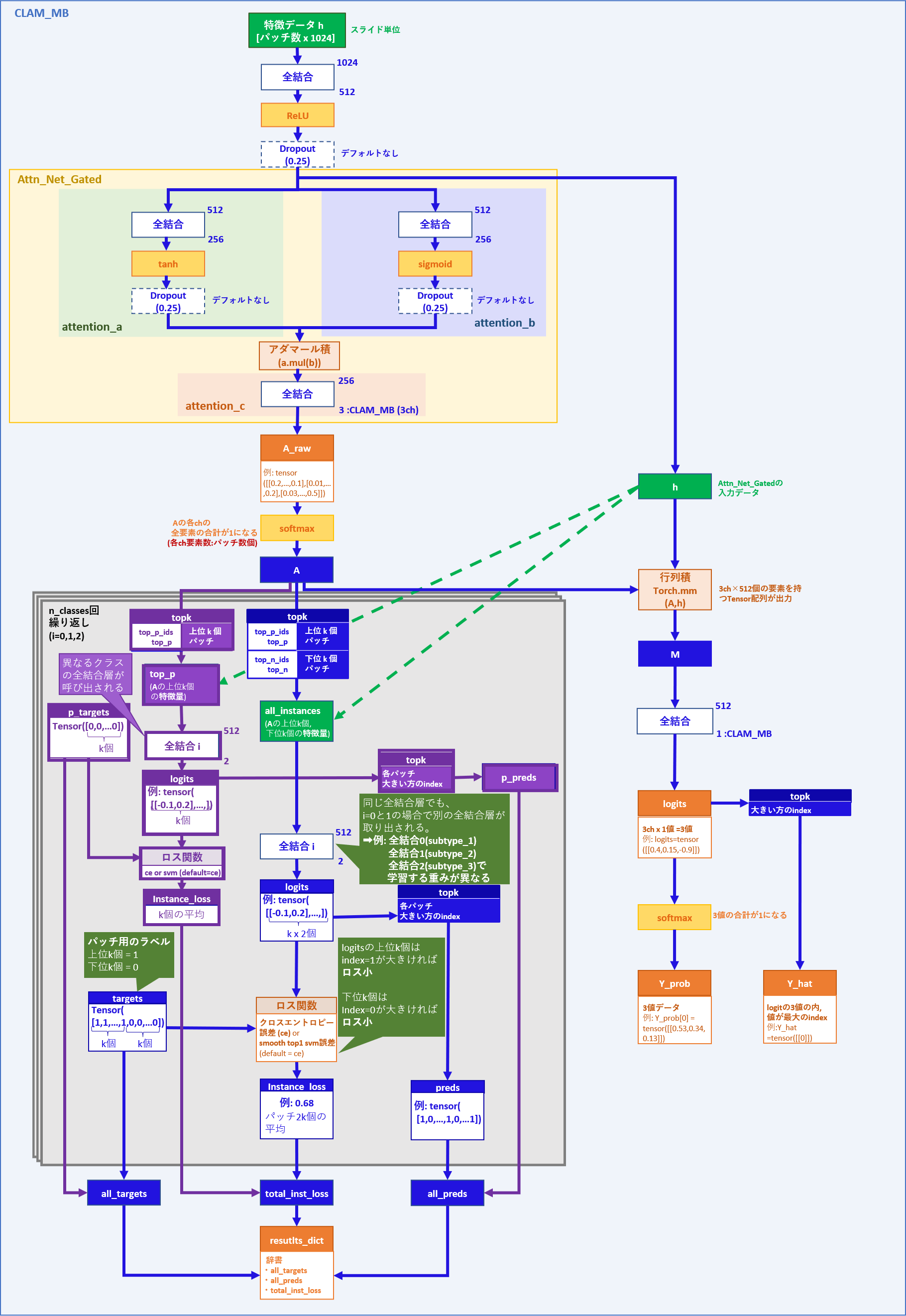
次にCLAM_MBについて順に見ていきます。
CLAM_MBでの処理
① アテンションネットワーク
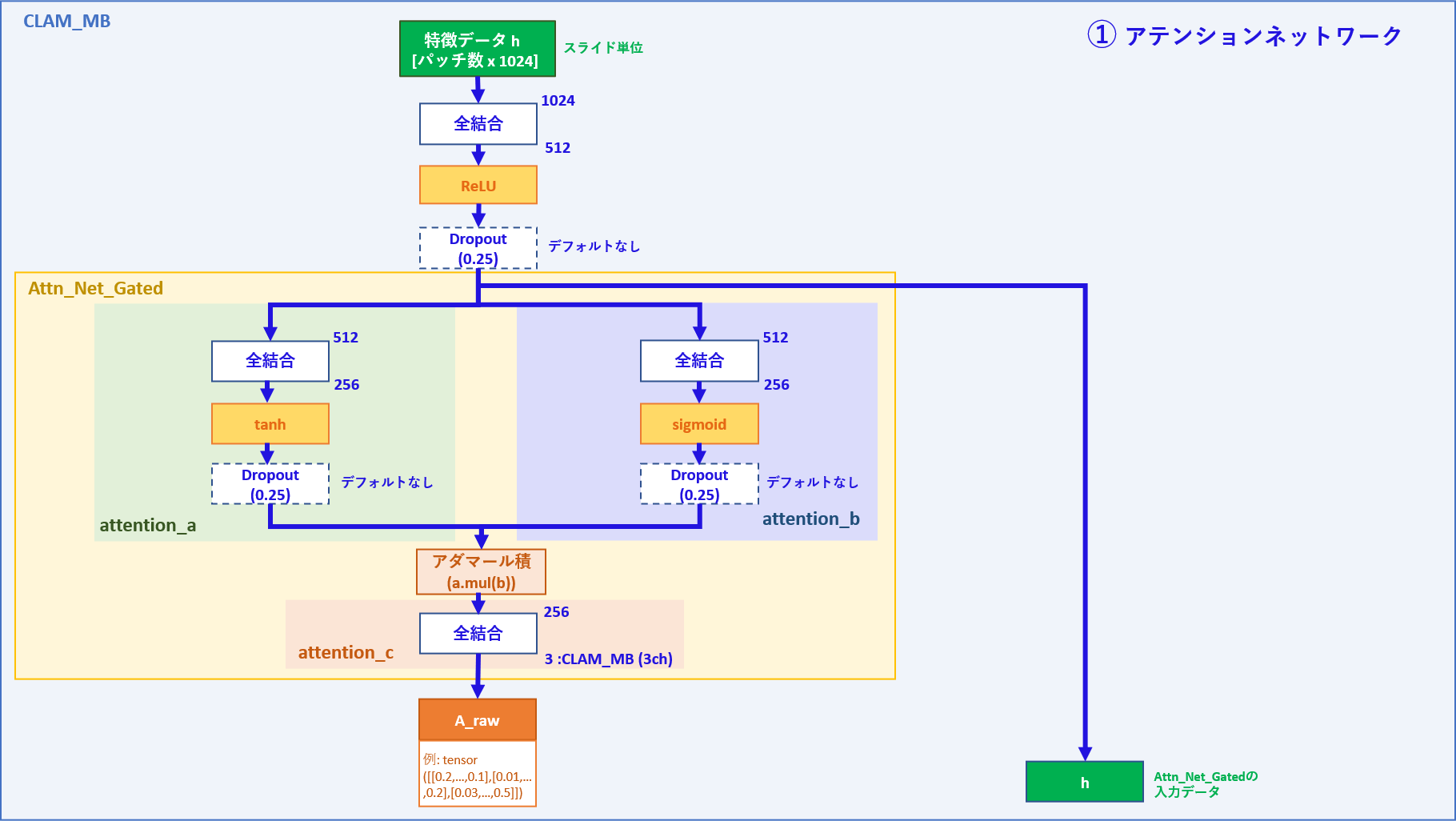
| 入力データ | メモ |
|---|---|
| h | パッチ数 x 1024次元の特徴量 |
| 出力データ | メモ |
|---|---|
| h | パッチ数 x 512次元の特徴量 |
| A_raw (A) | パッチ数 x 3次元のアテンションスコア |
処理:
クラスが3つに分かれる以外はCLAM_SBと同じような処理になります。
データローダーからスライド単位で特徴量データが入ってきます(バッチ数=1)
入力データhは最初の全結合層を通り、その後、Attn_Net_Gatedのネットワークを通してアテンションスコアAが出力されます。
最初の全結合層を通った後をh'とすると、
attention_aではh'が全結合層を通り512次元=> 256次元となった後にtanh関数で各値が-1~1に変換されます。
結果、特徴量の値が大きい程1に近くなると思われます。
attention_bではh'が全結合層を通り512次元=> 256次元となった後にsigmoid関数で各値が0~1に変換されます。
こちらも、特徴量の値が大きいほど1に近くなると思われます。
attention_cではattention_aとattention_bのアダマール積(要素積)が求められ、全結合層を通ることでアテンションスコアとしてパッチ毎に3つの値(各クラスに1つの値)が出力されます。
コマンドの引数でdrop_out=Trueとした場合は、図の位置に25%のdrop-out層が配置されます。
最初の全結合層を通った後のhと、attention_cを通ったアテンションスコアAが返り値として出力されます。 (hは、model_clam.pyのAttn_Net_Gatedクラスではx表記)
Aは後にsoftmax関数を通した値との区別のためA_rawとされます。
本記事のアテンションネットワークとは構造は異なりますが、
画像領域で用いられるアテンションについてこちらの記事が参考になりました。
② パッチ単位学習部分
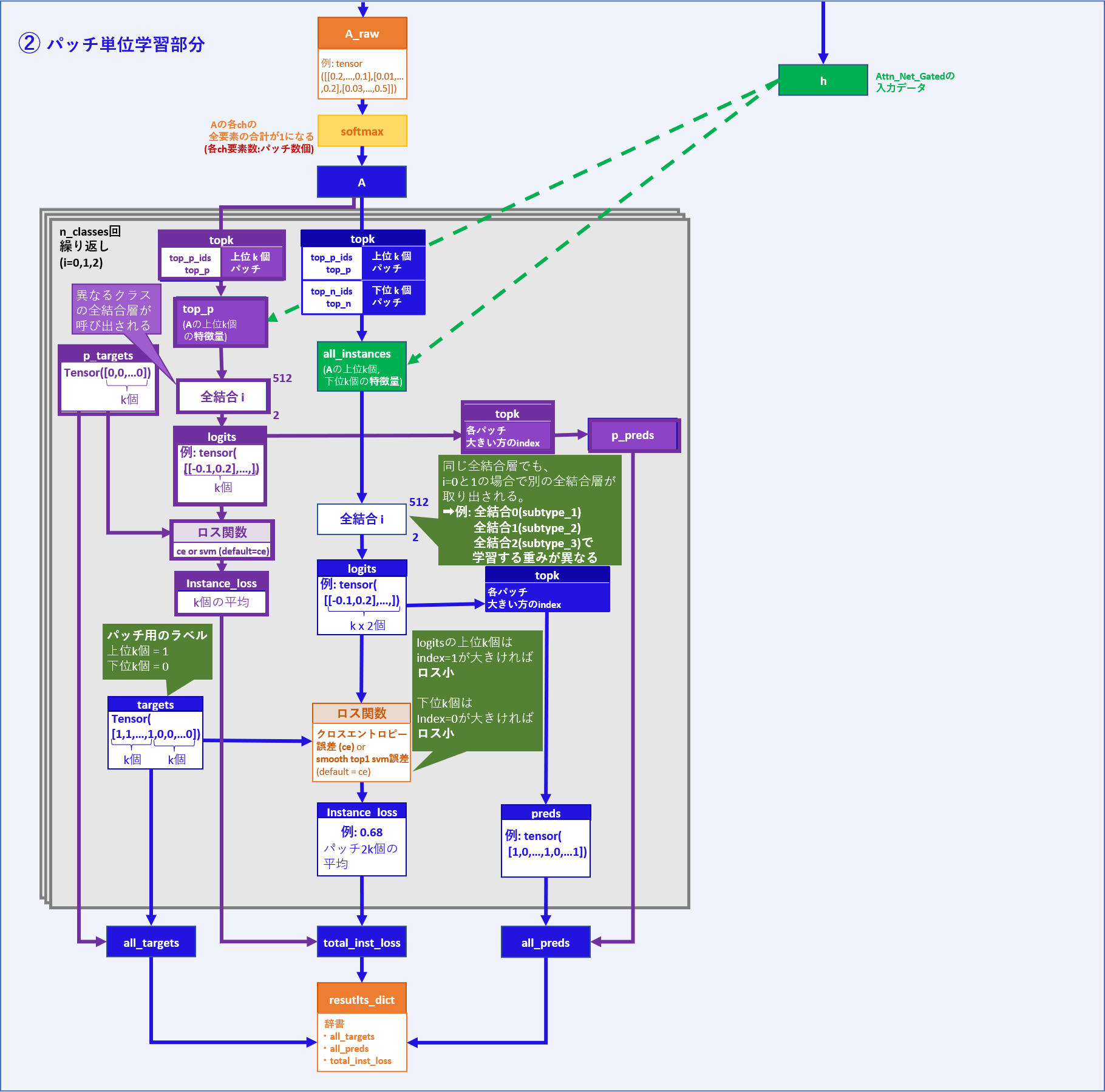
ここでの入力・出力データは部分的な処理としてみたものですので、
コード上は関数やメソッドの返り値として出力されるものではなく1つの変数として
見ていただけましたら幸いです。
| 入力データ | メモ |
|---|---|
| A_raw (A) | パッチ数 x 3次元のアテンションスコア |
| 出力データ | メモ |
|---|---|
| result_dict | 辞書 (all_targets, all_preds, total_inst_loss) |
処理:
まずA_rawがsoft-max関数を通してAに変換されます。
この時点で、各パッチが3チャンネル(3クラス分)を持ち、
各チャンネルがアテンションスコアを1つずつ持っている状態となっています。
(アテンションスコア:各チャンネルにおいて、全パッチの値の合計が1)
ここで、各チャンネル(i)について以下の処理が進みます。
アテンションスコア上位 k 個、下位 k 個のパッチのインデックスを元に、
k x 2個のパッチについて特徴量 h (①の出力値)を抽出しall_instancesとします。
※ k個 = main.pyの引数Bで指定した数(default = 8)
次に、all_instancesをクラス毎に異なる全結合層iに通します。
CLAM_MBでは、スライドのクラスがsubtype_1の場合はi=0 で全結合層を通して
各パッチの値が2つのlogitsとなります。
クラスがsubtype_2の場合はi=1で別の全結合層を通して同じく各パッチ値が2つのlogitsとなります。各クラスで同形状の異なるネットワークにて別々に重みを学習する形になります。
例:logits
| Tensor( | [[0.04,0.01], | [0.03,-0.05], | …, | [-0.12,0.08]]) |
|---|---|---|---|---|
| パッチ 0 | パッチ 1 | … | パッチ 2 x k -1 |
また、all_targetsがk x 2個のパッチのラベルとして用意されます。
前半 k個が1, 後半 k個が0からなるテンソルで、正解のインデックスと考えられます。
例:all_targets
| Tensor([ | 1,1,…1, | 0,0,…0 | ]) |
|---|---|---|---|
| k個 | k個 |
all_instancesをall_targetsと併せて損失関数に通すことで、instance_lossを出力します。
アテンションスコア上位k個については、パッチ毎の2つの値の内、インデックス1の方が大きければロスが小さくなります。逆に下位k個については、インデックス0の方が大きければロスが小さくなります。
こういった手法により、アテンションスコアが高いほどスライドの特徴を良く表し、逆にスコアが低いほどスライドの特徴を表さない方向に学習をしていくものと思われます。
例えば、正常(normal_tissue)スライドの場合は、正常の特徴を表すパッチほどアテンションスコアが高い方向へ学習していると考えられます。
ロスの計算とは別に、logitsからパッチ毎の2値の内、値が大きい方のインデックスを記録したテンソルをall_predsとします。
厳密にはinst_evalメソッド内で上記の通りall_targets, all_preds, instance_lossとなっており、forwardメソッド内ではそれぞれtargets, preds, instance_lossとなっているようです。
また、CLAM_MBは腫瘍のサブタイピングを前提とするため、サブタイプが互いに排他的であると仮定して以下の追加処理が行われます。
(図内紫色部分)
Ⓐ アテンションスコア上位k個のパッチの特徴量を異なるクラスの全結合層に通します。(logits)
Ⓑ 要素の値が0のk個の項目を持つテンソルp_targetsと損失関数でロス(instance_loss)を求めます。
Ⓒ logits(2値)の大きい方のインデックスをp_predsとします。
Ⓓ p_targetsはall_targetsに、p_predsはall_predsに追加し、instance_lossは下記のtotal_inst_lossの値に追加します。
例えば「サブタイプ1」に分類されるスライドについて、アテンションスコアの高いパッチが「サブタイプ2」の特徴を示した場合、同時に存在するはずのない「サブタイプ2」について陽性の判断をしたということで、"偽陽性"としてロスに加算する、といった考え方のようです。
上記を各クラスで計算し、ラベル(all_targets, p_targets), 予測値(all_preds, p_preds)をall_targets, all_predsリストに追加し、instance_lossはtotal_inst_lossとして、この3つがresult_dict辞書に入ります。
total_inst_lossには別クラスの全結合に通した際のinstance_lossも追加されているため、
後にクラス数(全結合層の数)で平均されます。
③ スライド単位学習部分
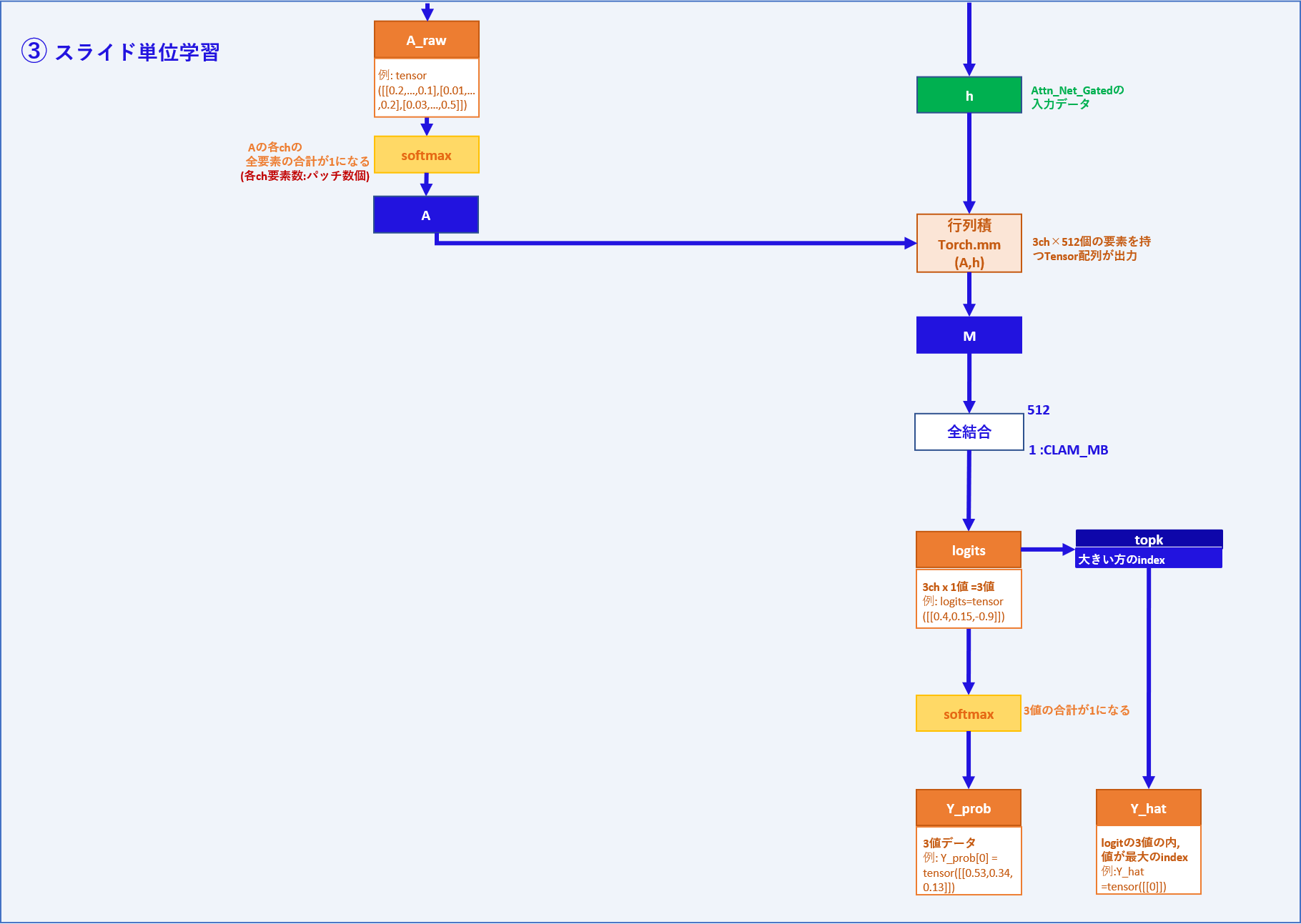
ここでの入力・出力データは部分的な処理としてみたものですので、
コード上は関数やメソッドの返り値として出力されるものではなく1つの変数として
見ていただけましたら幸いです。
| 入力データ | メモ |
|---|---|
| A | パッチ数 x 3チャンネルのアテンションスコア |
| h | パッチ数 x 512次元の特徴量 |
| 出力データ | メモ |
|---|---|
| logits(スライド単位) | Aとhの行列積を全結合層に通して3ch x 1=3値となったテンソル |
| Y_prob | logitsをsoft_max関数に通して、合計1になるように調整したテンソル |
| Y_hat | logitの3値の内、最大値のインデックスを取った予測値 |
処理:
Aを重みとしてhとの行列積を取ることで、3ch x 512個の要素を持つテンソルMを出力します。
Mは各ch毎に3つの全結合層を通り、3つの値を持つテンソルlogitsとなります。
つまり、
M[0]がクラス0(subtype_1)の全結合層を通り1つの値を出力、
M[1]がクラス1(subtype_2)の全結合層を通り1つの値を出力、
M[2]がクラス2(subtype_3)の全結合層を通り1つの値を出力しており、
logitsは、logits = ([[0.4773, 0.930, -0.7090]])のような3値となります。
②のlogitsと同じ変数名ですが、こちらはスライド単位の値となります。
次に、logitsをsoftmax関数を通すことで正規化し、3値の合計が1となるY_probを出力します。
また、logitsの最大値のインデックスを取ったテンソルをY_hatとします。
CLAM_MB全体としては、①~③から
A_raw、result_dict、logits(スライド単位)、Y_Prob、Y_hatを返り値としています。
次に以下の処理へとつながります。
CLAM_MB全体の主な入力データと出力データは以下の様になります。
| 入力データ | メモ |
|---|---|
| h | パッチ数 x 1024次元の特徴量 |
| 出力データ | メモ |
|---|---|
| A_raw | パッチ数 x 3次元のアテンションスコア |
| result_dict | 辞書 (all_targets, all_preds, total_inst_loss) |
| logits(スライド単位) | Aとhの行列積を全結合層に通して3ch x 1=3値となったテンソル |
| Y_Prob | logitsをsoft_max関数に通して、合計1になるように調整したテンソル |
| Y_hat | logitの3値の内、最大値のインデックスを取った予測値 |
CLAM_SB/MB出力~パラメータ更新
次に、CLAM_SB及びCLAM_MBからの出力~パラメータ更新を見てみたいと思います。
おおよそ以下のようになっています。

図の④~⑥について、順に確認してみます。
④ スライド単位で正解数の記録
| 入力データ | メモ |
|---|---|
| Y_hat | 予測インデックス |
| label | 正解ラベル |
処理:
スライド単位の予測インデックスY_hat、スライドラベルlabelを比較し、
クラス毎に処理数(self.data[Y][“count”])と正解数(self.data[Y][“correct”])を記録していきます。
⑤ パッチ単位で正解数の記録
| 入力データ | メモ |
|---|---|
| inst_preds | 予測インデックス |
| inst_labels | 正解ラベル |
処理:
パッチ単位の予測インデックスと正解ラベルを比較し、
ラベルの種類(label_class)毎に処理数(self.data[label_class][“count”])と
正解数(self.data[label_class][“correct”])を記録していきます。
⑥ ロスの計算
| 入力データ | メモ |
|---|---|
| logits | スライド単位の予測値 |
| label | スライド単位の正解ラベル |
| instance_loss | パッチ単位のロス |
| 出力データ | メモ |
|---|---|
| loss | スライド単位のロス |
| total_loss | パッチ単位ロスとスライド単位ロスを合わせた最終的なロス |
処理:
logitsとlabelがロス関数(default=クロスエントロピー誤差)に通されlossを出力します。
次にlossとinstance_lossについて、以下の計算を通してtotal_lossを出力します。
total_loss = bag_weight * loss + (1-bag_weight) * instance_loss
※ bag_weight: default 0.7
ロスとパラメータ更新について
スライド単位
ネットワークの出力がラベル値と一致するほどロスが小さくなると思われます。
パッチ単位
アテンションスコアの高いパッチがスライドのクラスの特徴を示し、アテンションスコアが低いパッチとの特徴が明確に分かれるほどロスが小さくなると思われます。CLAM_MBの場合は偽陽性の観点が加わり、アテンションスコアの高いパッチが別のクラスの特徴を示すとロスが大きくなります。
全体のロス
デフォルトでは、スライド単位のロスを7割、パッチ単位のロスを3割として全体のロス値が計算されます。
パラメータ更新
ロス値を元にtotal_loss.backward()で勾配が計算され、optimizer.step()でパラメータが更新されています。
モデルの学習について
CLAMでは、上記の形でロスの計算とパラメータの更新を繰り返すことで、モデルがスライドとラベルからパッチ単位で注目すべき箇所を予測できるような形に学習していくものと思われます。
おわりに
本記事の内容は以上となります。
分からないところ等ありましたら、お気軽にご質問をいただけましたら幸いです。
作成者:平尾
参考文献URL
-
CLAM github
Lu, M.Y., Williamson, D.F.K., Chen, T.Y. et al. Data-efficient and weakly supervised computational pathology on whole-slide images. Nat Biomed Eng 5, 555–570 (2021). https://doi.org/10.1038/s41551-020-00682-w