はじめに
数式の基礎から初めて機械学習をある程度学習できたので、
練習も兼ねてYolo v5で自作データを用いて物体検知してみることにしました。
がyoloは学習から推論まで簡単に実施できるようになってるので、
あまり基礎から学んだことを使う機会はなかったですが・・・。
とりあえず近くに子供のすみっコ人形たちが転がってたので、すみっコぐらしのメインキャラを判定してみました笑
開発環境
スマホ:写真撮影用
windows 10 ノートPC(GPUなし): 画像整理編集、物体検知実施
Google Colabo Pro : モデル学習
画像準備
まずは撮影会
横向きで110枚ほど撮影。
全然足りない気もしますがまぁお試しなので。

リサイズ
今回スマホで画像を撮影しており、画面サイズが大きいため
画像をアスペクト比を保ったままリサイズします。
リサイズには前に何かで使っていてPC上にあった
Ralphaを使っています。
https://forest.watch.impress.co.jp/library/software/ralpha/
幅は640pixelにして変換をかけました。
基が4:3の画像だったので640*480の画像に変換
リサイズの設定を入れて、赤枠の矢印でリサイズ実施。
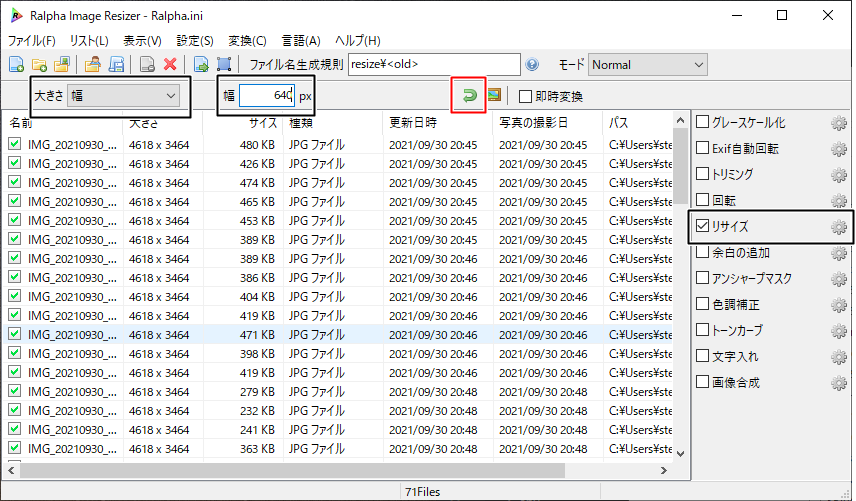
※後から思うとカメラで物体検知するからPCカメラで撮影すればリサイズ作業しなくてよかったなと・・・。
ラベリング
ラベリングツールには「labelImg」を利用しました。
Windows10PCで作業してるので以下からwindows_v1.8.1.zipをダウンロードして展開!
https://github.com/tzutalin/labelImg/releases
クラスリストの作成
LabelImgをインストールしたフォルダ配下の data/predefined_classes.txt に認識させたいクラスの名称を記載します。
今回はすみっコの主要メンバーにします。
neko
pengin?
ebihurai no sippo
shirokuma
tonkatsu
tokage
ラベリング作業
-
labelImg.exeを実行
-
画像にラベルを付けていく
wを押してマウスで囲って、クラスリストの中からラベルを選択します。
その画像の対象オブジェクトにラベルを付けたら「Ctr+s」で保存。
その後に「Next Image」押下の流れでラベリングしていきました。
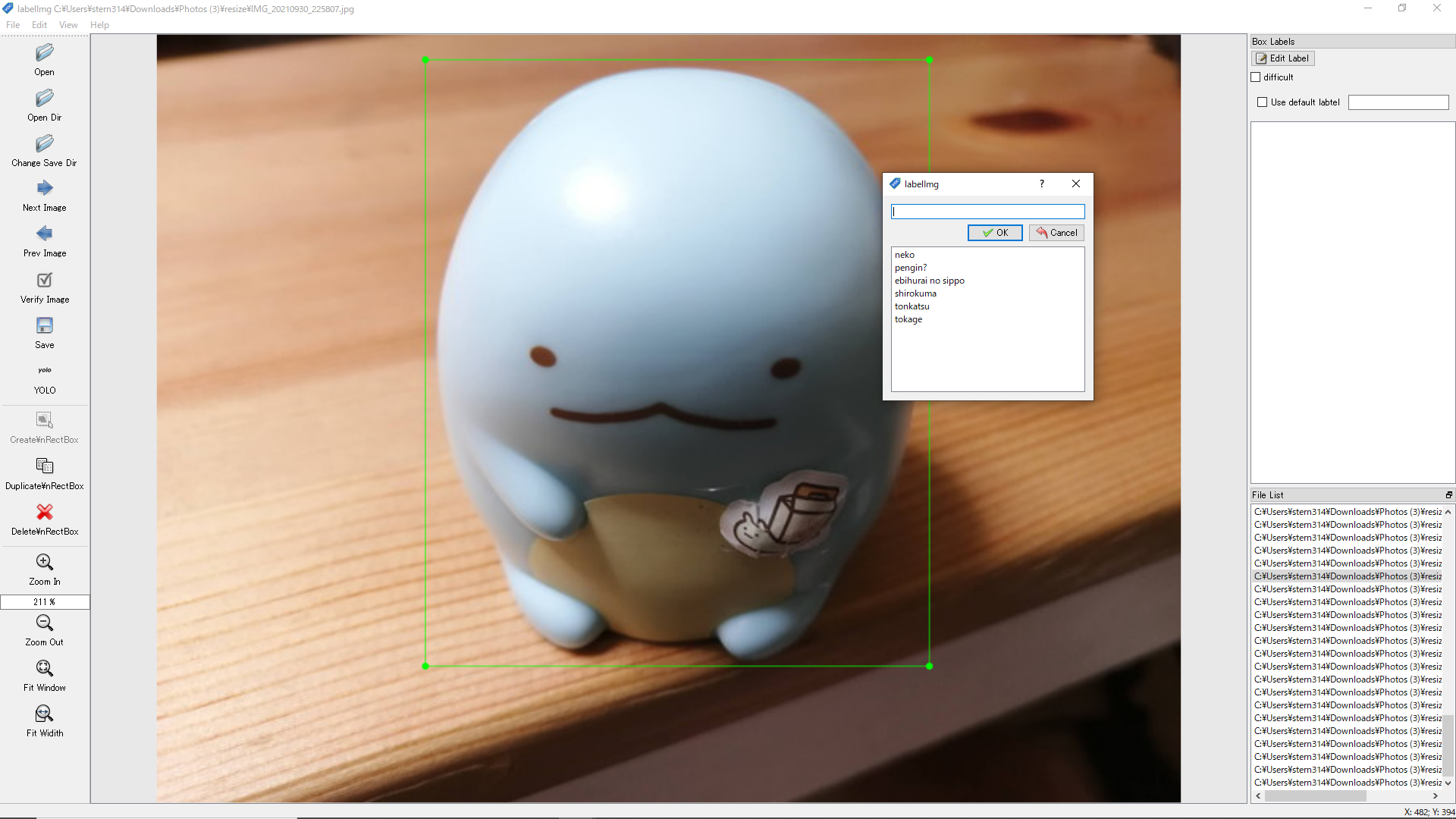
うーん地味な作業・・・。
編集後のフォルダ内を確認
今回「sumikko」フォルダに画像とラベリングデータを保存。
sumikko
| - train 学習用画像(100枚ほど)
| | - classes.txt クラスラベルの一覧
| | - IMG_・・・.jpg 画像ファイル
| | - IMG_・・・.txt ラベリング情報
| | - IMG_・・・.jpg
| | - IMG_・・・.txt
| ・・・
| - val 検証用画像(10枚ほど)
| - classes.txt クラスラベルの一覧
| - IMG_・・・.jpg
| - IMG_・・・.txt
・・・
学習準備
私のPCは貧弱マシンなのでGoogleColab上でyoloの学習を行います。
学習については以下の記事を参考にさせていただきました。
https://qiita.com/PoodleMaster/items/5f2cc3248c03b03821b8
データセットの格納場所&クラス分類定義のファイルを作成(dataset.yaml作成)
上記yolo v5のチュートリアルの
Or manually prepare your dataset (click to expand)
にある通りdataset.yamlを「sumikko」フォルダ直下に作成します。
「sumikko」フォルダはGoogleマイドライブ直下に置くので、
移動後は以下のようなパスとなります。
/content/drive/MyDrive/sumikko/
dataset.yamlへはtrain,valのフォルダを指定して記載
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
train: /content/drive/MyDrive/sumikko/train/
val: /content/drive/MyDrive/summikko/val/
# number of classes
nc: 6
# class names
names: ['neko', 'pengin?', 'ebihurai no sippo', 'shirokuma', 'tonkatsu', 'tokage']
ラベリングデータの転送
GoogleのMyドライブ直下に「sumikko」フォルダを丸ごと毎転送します。
この時点ではこんなフォルダ構成
sumikko
| - dataset.yaml
| - train 学習用画像(100枚ほど)
| | - classes.txt クラスラベルの一覧
| | - IMG_・・・.jpg 画像ファイル
| | - IMG_・・・.txt ラベリング情報
| | - IMG_・・・.jpg
| | - IMG_・・・.txt
| ・・・
| - val 検証用画像(10枚ほど)
| - classes.txt クラスラベルの一覧
| - IMG_・・・.jpg
| - IMG_・・・.txt
・・・
GoogleColabでの学習実施
GoogleColabに接続して新規でNotebookを作成する。
学習するのでGPUをONにしておく。
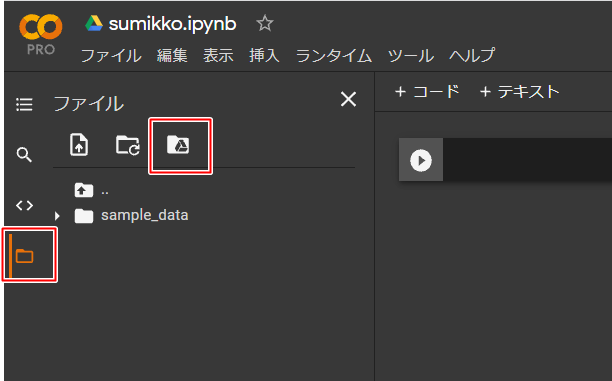
MyDriveのマウント
データセットを読み込むためにMydriveをマウントします。
GoogleColabでYOLOインストール
!git clone https://github.com/ultralytics/yolov5
!pip install -r yolov5/requirements.txt
wandbのインストール(任意)
yoloのTrain-Custom-Dataのtutorialに記載のあるツールで、
学習結果をリアルタイムで確認するためのツールとなります。
使用するには以下のサイトへの登録が必要です。
https://wandb.ai/site
個人で使う分には無料のようです。
!pip install wandb
Yoloモデルのトレーニング時に、登録したアカウントに学習データをリアルタイムで連携しているようです。
上記サイトにログインすることで学習状況が見られます。
学習の実施
途中で切断されると怖いので、「--project」指定でモデル学習結果をMydrive側に保存するようにしました。
%cd /content/yolov5
!python train.py --imgsz 640 --batch 8 --epochs 300 --data '/content/drive/MyDrive/sumikko/dataset.yaml' --project '/content/drive/MyDrive/sumikko/train' --name sumikko --weights yolov5s
wandbに連携する場合のみ
wandbに連携する場合は学習実施のコマンド実行後に、以下のようにwandbに関する選択肢が出ますので、
2を選択し、ログイン及びワンタイムパスワードを入力してください。
入力後はそのまま学習が開始されます。
/content/yolov5
Downloading https://ultralytics.com/assets/Arial.ttf to /root/.config/Ultralytics/Arial.ttf...
wandb: (1) Create a W&B account
wandb: (2) Use an existing W&B account
wandb: (3) Don't visualize my results
wandb: Enter your choice: (30 second timeout)
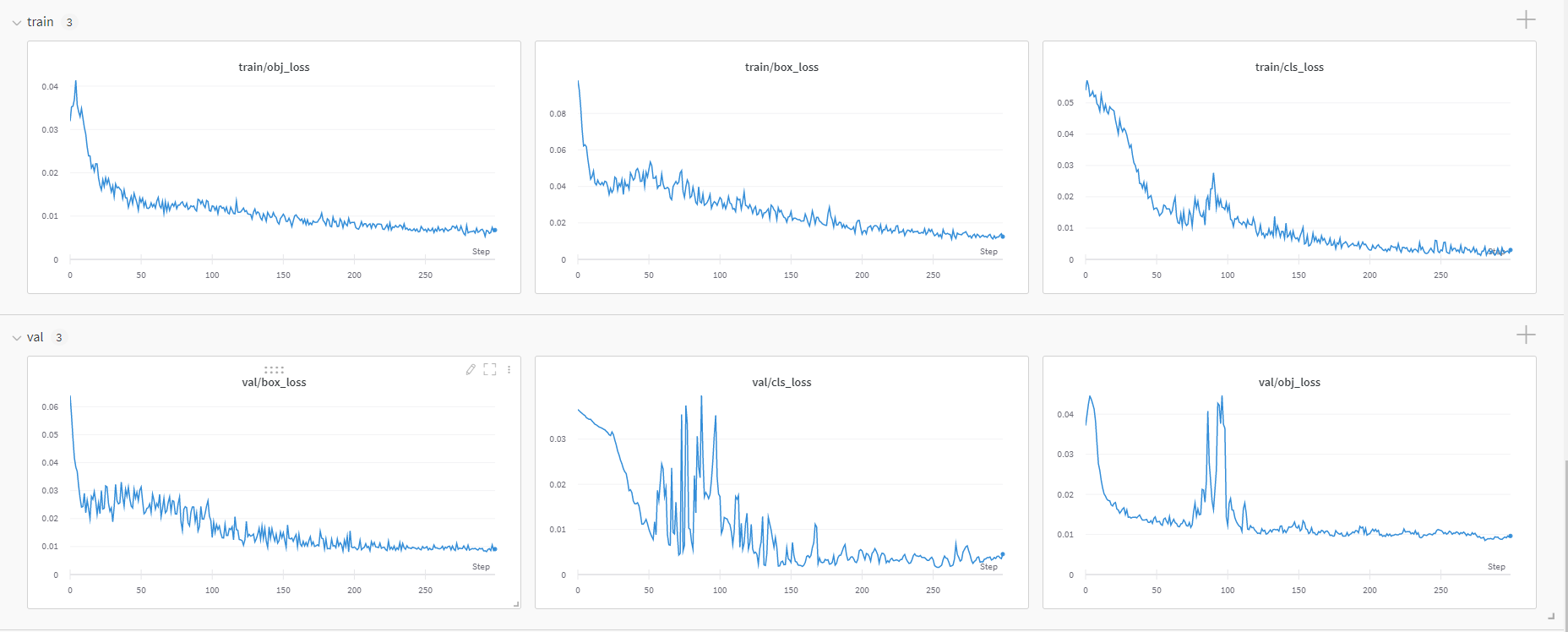
wandbによる学習推移確認
以下は最終結果ですが、このようなグラフがwandbのダッシュボードでリアルタイムに更新されていきます。
metrics
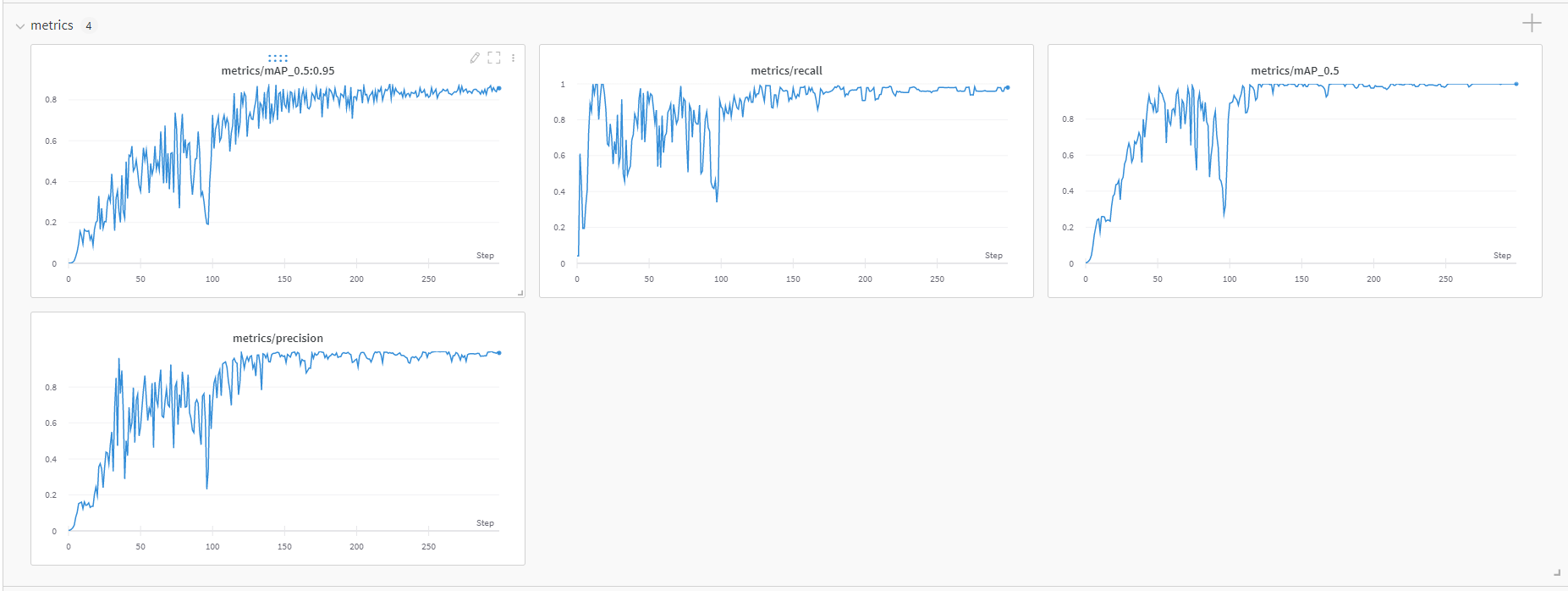
train/val
ローカルPC側の準備
anacondaは他のソフトへの影響があったり、
pipを叩いてしまった際に競合して環境ごと壊れることがあって(実際壊れたことも・・・)あんまり好きじゃないので、環境構築はpipでやります。
Pytorchのインストール
yolov5で利用しているので先にインストールする必要があります。
python3.6以降?で64bitである必要があります。
※最初3.7の32bitのPythonで実施していましたがpipインストールでエラーとなっていました。
https://www.python.org/
以下はPytorchインストールコマンドは、WindowsでGPUなしのPCにPipでインストールする場合のコマンドです。
環境に合わせてコマンドが違うので公式で確認してください。
https://pytorch.org/get-started/locally/
# 先に仮想環境を作成(任意のフォルダに移動しておく)
PS C:\yolo_pj> python -m venv yolo_env
PS C:\yolo_pj> .\yolo_env\Scripts\activate
# Pytorchインストールコマンド実施
(yolo_env) PS C:\yolo_pj> pip3 install torch torchvision torchaudio
yoloのインストール
(yolo_env) PS C:\yolo_pj> git clone https://github.com/ultralytics/yolov5
(yolo_env) PS C:\yolo_pj> cd yolov5
(yolo_env) PS C:\yolo_pj\yolov5> pip install -r requirements.txt
モデルの移植
学習時に以下のパスに学習結果を保存していたので
/content/drive/MyDrive/sumikko/results
モデルの場所は以下となります。{name}は学習時に指定したnameとなります。
/content/drive/MyDrive/sumikko/results/{name}/weight/best.pt
モデルをダウンロードしてyolov5フォルダの直下に配置します。
今回は以下の場所
C:\yolo_pj\yolov5
すみっコ検出確認
物体検出実行
(yolo_env) PS C:\yolo_pj\yolov5> python detect.py --source 0 --weight best.pt
検出結果
大きめに映ってれば特に問題なく検出できているようです。
登録していないキャラもちゃんと認識外になっていました。

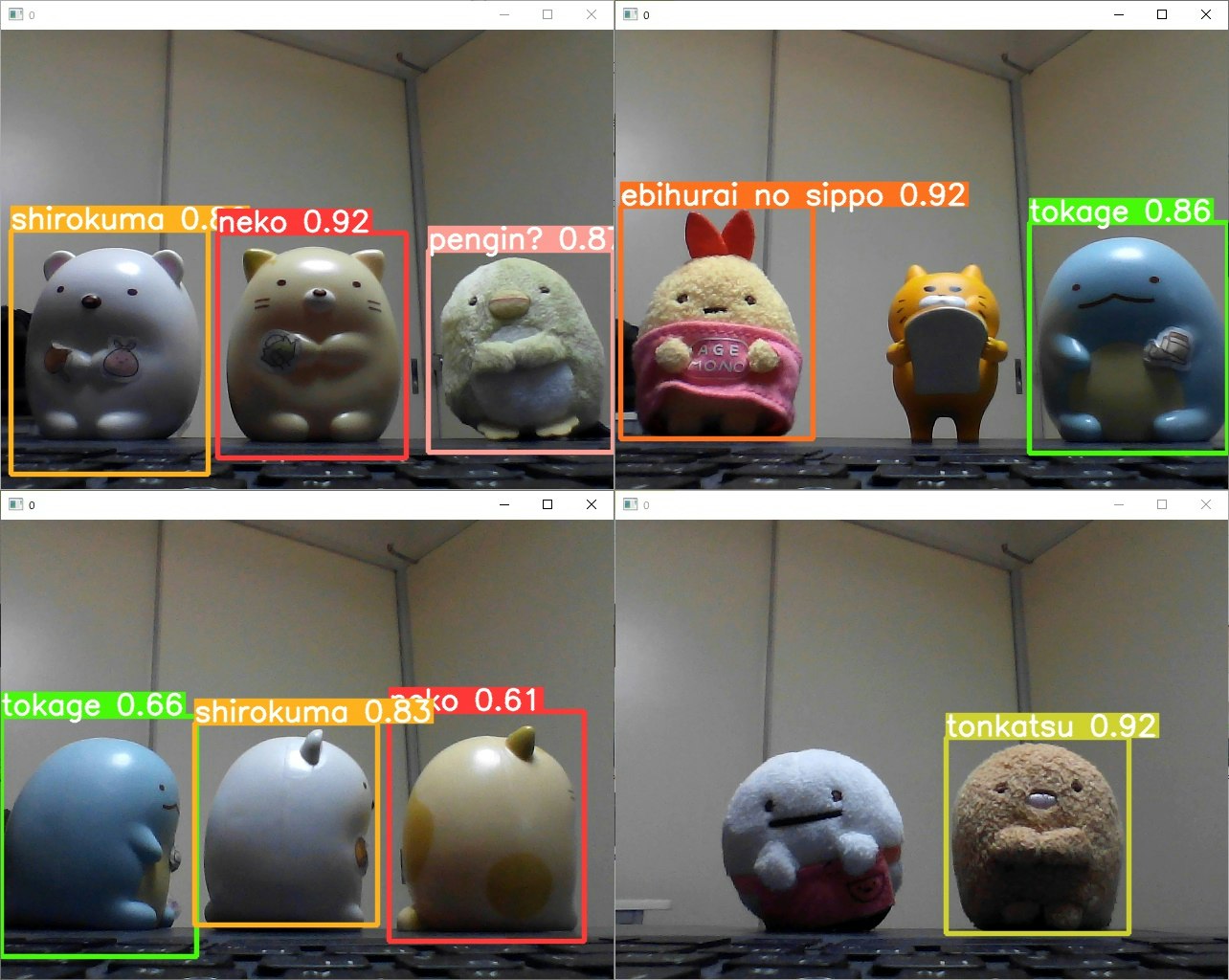
自作データでも問題なく物体検知させることができました。
yolov5は学習から推論まで簡単ですごいですね。
お疲れさまでしたー。