はじめに
この記事は、エクセル帳票からデータを抽出し、pandasを使ってデータフレームに入れる所について、特に実際の現場で痛い目をみる例を紹介します。
その1についてはこちら⇒エクセル帳票からのデータ取得は辛いよ その1
今回は過去のデータもさかのぼって抽出し、1枚のデータフレームに入れる場面です。
今使っている帳票が、過去から一貫して共通しているなど、ゆめゆめ思ってはいけません。
「信じた私がばかでした」となるのが落ちです。
今日はそんな場面を再現し、対処法の一つを語ろうと思います。
尚、今回もjupyternotebookでの使用を想定して書いてます。
誰かのお役に立てれば幸いです。
(需要あるかわからんけど、連載をやってみると自分で決めたのでやってみよう!)
さて、やるか。
過去のデータを持ってくる
フォルダ構成は以下のように年代別フォルダの中に見積もりのエクセルファイルが入っていると仮定します。
あまり数多く例があっても意味がないので、2018年から2022年まで各1ファイルずつ存在しているとします。

存在する過去のエクセルファイルをリスト化して、その1で使った関数をfor文で回してやれば、やりたいことはできそうですね。
道筋が決まったので、さっそくコードを書いていきましょう。
#exampleフォルダ配下の最下層にあるエクセルファイルのパスをすべて取得
import glob
file_list = glob.glob('example/*/*.xlsx')
file_list
#出力は以下記の通り
'''
['example\\2019\\mitsumori_201901.xlsx',
'example\\2020\\mitsumori_202001.xlsx',
'example\\2021\\mitsumori_202101.xlsx',
'example\\2022\\mitsumori_202201.xlsx']
'''
あれ、2018年のフォルダが読めていませんね。
その原因は何でしょうか?
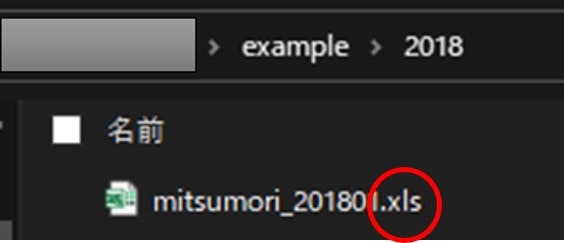
拡張子が.xlsでした。。。
コードでは、.xlsxを含むものを選択的に抽出してきたので、引っかからないわけです。
ですので、下記の様に変更しましょう。
#exampleフォルダ配下の最下層にあるエクセルファイルのパスをすべて取得
#拡張子は.xlを含めばなんでも可 とした。
import glob
file_list = glob.glob('example/*/*.xl*')
file_list
#出力は下記の通り
'''
['example\\2018\\mitsumori_201801.xls',
'example\\2019\\mitsumori_201901.xlsx',
'example\\2020\\mitsumori_202001.xlsx',
'example\\2021\\mitsumori_202101.xlsx',
'example\\2022\\mitsumori_202201.xlsx']
'''
きちんと.xlsも抽出できました。これで2018年から2022年の見積表のパスリストが取得できたので、その1で作成した関数を流用します。
for l in range(len(file_list)):
if l == 0:
df_conc = make_df(file_list[l])
else:
dfx = make_df(file_list[l])
#file_listのパスを順に読んでいって、逐次データフレームを結合していく。
df_conc = pd.concat([df_conc, dfx], axis=0)
df_conc
おかしいぞ?
InvalidFileException: openpyxl does not support the old .xls file format, please use xlrd to read this file, or convert it to the more recent .xlsx file format.
この様なエラーが出ました。これはmake_df関数で
data = pd.read_excel(path, engine="openpyxl")エンジンをopenpyxlにしていたことが原因の様です。
なので、このengineごと外しましょう。
data = pd.read_excel(path) こうします。
再度上記処理を実行したら、異なるエラーが出てきました。
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
<ipython-input-26-2c96a77ccf32> in <module>
1 for l in range(len(file_list)):
2 if l == 0:
----> 3 df_conc = make_df(file_list[l])
4 else:
5 dfx = make_df(file_list[l])
<中略>
IndexError: single positional indexer is out-of-bounds
現物見るかー
これはデータフレームに値がないときに出てくるエラーです。
for文の最初の処理で出てきているので、2018年のファイルで何か不都合があるようです。
なので、一度現物(ファイル)を見てみましょう。

その1では2022年版はきちんと見れたので、これと比較しましょう。
何が違うか、わかりますか?
これだけを見て分かった人は鋭い眼をお持ちですね。
私は初めてこういうファイルに出会ったとき、すぐに見抜くことはできません。
なので、何がおかしいのか、make_df関数をばらして、確認していきましょう。
data = pd.read_excel('example\\2018\\mitsumori_201801.xls')
data1 = data.iloc[12:, :5]
data2 = data1.reset_index(drop=True)
data2

んんん???

1列ずれている・・・・
なので、改めてエクセルファイルを見てみると、

おいー、フォーマット変わってるやん!
しかも、行もおかしくないか?

という事が、現場では多々あります。
しかも、こういうのって、見た目ではわかりにくい。
今は事例として、ファイル数が極小なのでおかしなファイルの原本はアーカイブして、別のフォルダにコピーして修正、抽出という事もできますが、現場ではそうはいかない。
という事で、make_df関数をもっと汎用性高くする必要がありますね。
抽出個所をここdata1 = data.iloc[12:, :5]で規定しているので、ここに汎用性をもたらすことが解決になりそうです。
さて修正
「品名」のセル位置を取得したらよいので、下記の様に変えました。
必要な前処理も忘れずにします。品と名の間の空白も除去しておきましょう。
まずは関数に組み込む前に、上記思考が正しいかを確認します。
data = pd.read_excel('example\\2018\\mitsumori_201801.xls')
#不要な半角空白を除去
data = data.replace('\s', '', regex=True)
#不要な全角空白を除去(もしかしたら全角空白もあるかもしれない)
data = data.replace(' ', '', regex=True)
#※必要であると感じたら、\tや\nの除去も追加しましょう。
col_name = data.columns
#品名のセルを見つける
#フォーマットがどれだけ違っても、5列以上ずれていることはないと仮定。
#現場ではある程度確認してから決め打ちしたほうが良いかも。
for c in range(5):
print(c)
target = data[data[col_name[c]].isin(['品名'])]
if len(target) != 0:
#何列目かを記憶させておく
col = c
#何行目かを記憶させておく
ind = target.index[0]
#辞書として行・列を格納
keys = ['index', 'column']
values = [ind, col]
ind_col_dic = dict(zip(keys, values))
idx2 = ind_col_dic['index']
col2 = ind_col_dic['column']
data1 = data.iloc[idx2:, col2:col2+5]
data2 = data1.reset_index(drop=True)
nan_idx = data2[data2.iloc[:, 0].isnull()==True].index.tolist()
data3 = data2.iloc[:nan_idx[0], :]
data3
できました。

よさそうですね。
納入先名もずれているので、同様に修正しましょう。「様」が目印になりそうです。
data = pd.read_excel('example\\2018\\mitsumori_201801.xls')
#不要な半角空白を除去
data = data.replace('\s', '', regex=True)
#不要な全角空白を除去(もしかしたら全角空白もあるかもしれない)
data = data.replace(' ', '', regex=True)
#※必要であると感じたら、\tや\nの除去も追加しましょう。
col_name = data.columns
#品名のセルを見つける
#フォーマットがどれだけ違っても、5列以上ずれていることはないと仮定。
#現場ではある程度確認してから決め打ちしたほうが良いかも。
for c in range(5):
target = data[data[col_name[c]].isin(['様'])]
if len(target) != 0:
#何列目かを記憶させておく
col = c
#何行目かを記憶させておく
ind = target.index[0]
#辞書として行・列を格納
keys = ['index', 'column']
values = [ind, col]
ind_col_dic = dict(zip(keys, values))
idx2 = ind_col_dic['index']
col2 = ind_col_dic['column']
delivery = data.iloc[idx2, col2-1]
delivery
'''
出力結果は'株式会社〇×▽'となります。
'''
スライスに必要なind, colは繰り返し使ったので、別で関数を作ってmake_df関数に組込むと良さそうですね。
では、最後に日付取得の実験をします。
今回は、4行目より上にあると決め打ちで行きます。(ここは現物に即して臨機応変に)
import re
#とりあえず実験のため、3行目より上に絞ってデータフレームを加工
data_str = data.iloc[:3, :].dropna(how='all', axis=1).dropna(how='all', axis=0).astype(str)
#リスト化して取り出す
df_str_l = data_str.values.tolist()[0]
#-を含み、かつ数字から始まるものを抽出
d_time = [s for s in df_str_l if ('-' in s) and (re.match('[0-9]' , s))][0]
d_time
'''
主力結果は'2018-01-10'なります。
'''
これで準備は整いましたので、make_df関数を修正していきましょう。
def search_cell(data, target_str):
'''
特定の文字列の場所を取得して辞書にする関数。
<input>
data : 対象のデータフレーム(DF)
target_str : 探したい文字列(str)
<output>
ind_col_dic : 探したい文字列があるセル番地(dict)
'''
col_name = data.columns
#品名のセルを見つける
for c in range(len(col_name)):
try:
target = data[data[col_name[c]].isin([target_str])]
if len(target) != 0:
#何列目かを記憶させておく
col = c
#何行目かを記憶させておく
ind = target.index[0]
#辞書として行・列を格納
keys = ['index', 'column']
values = [ind, col]
ind_col_dic = dict(zip(keys, values))
except:
continue
return ind_col_dic
#ファイル読み込みからデータフレーム成型まで一連の処理を関数にする。
def make_df(path):
'''
見積書を読込み、データフレームを成型する。
<input>
path : 読込みたいエクセルファイルのパス(str)
<output>
df_summary : 必要事項のみを抽出したデータフレーム(DataFrame)
'''
data = pd.read_excel(path)
# data = pd.read_excel(path, engine="openpyxl")
#不要な半角空白を除去
data = data.replace('\s', '', regex=True)
#不要な全角空白を除去(もしかしたら全角空白もあるかもしれない)
data = data.replace(' ', '', regex=True)
#※必要であると感じたら、\tや\nの除去も追加しましょう。
#「品名」のセルを見つける
cell_partsname = search_cell(data, '品名')
#「様」のセルを見つける
cell_sama = search_cell(data, '様')
idx_partsname = cell_partsname['index']
col_partsname = cell_partsname['column']
data1 = data.iloc[idx_partsname:, col_partsname:col_partsname+5]
data2 = data1.reset_index(drop=True)
nan_idx = data2[data2.iloc[:, 0].isnull()==True].index.tolist()
data3 = data2.iloc[:nan_idx[0], :]
#カラムに入れたい0番目の値をリストに格納し、カラムとして定義する。
cols = data3.iloc[0, :].tolist()
data3.columns = cols
#0番目の行は不要なのでスライスで除去
data4 = data3.iloc[1:, :]
#納入先の取得
supplier = data.iloc[cell_sama['index'], cell_sama['column']-1]
#購入日の取得
data_str = data.iloc[:3, :].dropna(how='all', axis=1).dropna(how='all', axis=0).astype(str)
df_str_l = data_str.values.tolist()[0]
#-を含み、かつ数字から始まるものを抽出
buy_date = [s for s in df_str_l if ('-' in s) and (re.match('[0-9]' , s))][0]
# buy_date = data.iloc[cell_sama['index'], cell_sama['column']]
#データフレームへの追加
data4['購入日'] = buy_date
data4['納入先'] = supplier
#並べ替えの方法はいくつかあるが、ここでは購入日より右、左でデータフレームを分割し、再度結合する方法をとる。
data4_r = data4.iloc[:, 5:]
data4_l = data4.iloc[:, :5]
#データフレームの結合
data5 = pd.concat([data4_r, data4_l], axis=1)
return data5
さて、これを使ってexampleフォルダ配下にある全てのエクセルファイルからデータを集計し、1つのデータフレームに変換していきます。
#exampleフォルダ配下の最下層にあるエクセルファイルのパスをすべて取得
file_list = glob.glob('example/*/*.xl*')
#すべてのファイルから必要なものを抽出してDFに成形
for i in range(len(file_list)):
if i == 0:
df = make_df(file_list[0])
else:
dfx = make_df(file_list[i])
df = pd.concat([df, dfx], axis=0)
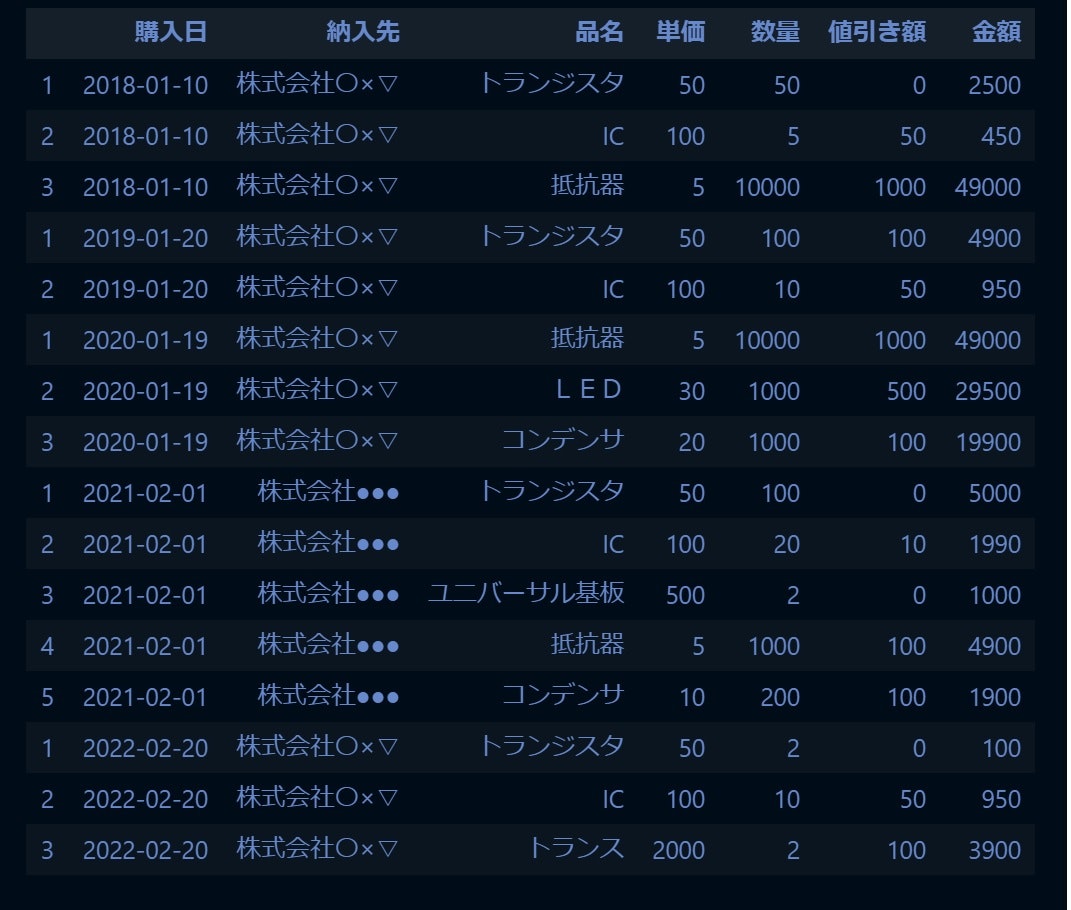
df
できました。
終わりに
長々と書いてきましたが、いかがだったでしょうか?
1列、1行記入欄が異なるだけで、こんなことをしなければいけなくなります。
人間の目と脳って改めてすごいですねー(棒)
今回は非常に簡単な例で紹介したのですが、これで済むならどれだけいいか!と思いながら自分の経験を詰め込みました。
私はこれ以上に汚い、もう見たくもないデータに半年近くまみれておりました。
エッセンスはある程度この記事で提示したので、みなさんが現在直面しているデータに対してどういうアプローチができるか?のヒントとなれば幸いです。
現実ではこの記事のように簡単にはいかないでしょう。膨大なエクセルファイルから少しサンプルを抜き出し、仮説を立て、実装して成形という工程の繰り返しです。
ですが、仮説が1つですべて解決するとは思わないほうがいいです。
サンプルから仮説立案して実装、成形、データ保存⇒仮説に当てはまらないものは、別フォルダで保管
⇒別フォルダに保管したものからサンプルを抜き出して仮説立案・・・この仮説に当てはまらないファイルは別フォルダで保管
⇒別フォルダに保管し・・・以下略)
というサイクルを回す必要性に迫られているはずです。
これは大変大きな苦痛を伴います。
その苦しみから抜けるためには、「きちんとした形で」データを保存する必要があります。
きちんとって何や?という方はこちらをご覧ください。
●総務省「統計表における機械判読可能なデータの表記方法の統一ルールの策定」https://www.soumu.go.jp/menu_news/s-news/01toukatsu01_02000186.html
●この資料のまとめブログ
https://excel-design-dr.com/date-entry-rule/
これからの時代、DX化の波が衰退することも、DXという言葉が生まれる前の時代に巻き戻ることもないことは、だれの目で見ても自明だと思います。その時代の中でここに手を付けられなくなるほど、取り残されていくことを意味します。
DXについてだれも関心のない時代につくられたエクセル帳票は仕方ないですが、これから新たに帳票を起こしてデータを蓄積していきたいのであれば、是非上記のルールに則ったものを作ってください。
できなければDX時代の負の遺産になります。
(何が「負の遺産」だ、小倅が!と言いたくなる人もいるかもしれませんが、冷静に考えて下さい。自分のライバル会社がDXで成功していって、
利益が増していっている状況で、自社はデータ成形に勤しんでいる。現実はこの記事よりもデータ成形が難しいものであふれています。それを使える状態にするのにどれだけコストと時間がかかるか?これを負と言わずして何と言いましょうか?)
尤も、今後もデータを活用するつもりのない帳票も存在すると思いますが、それならば現状維持でいいでしょう。ただし、後々「このデータ何かに使えんか?」となったときに苦労します。
データは「人間ファーストからコンピューターファースト(印刷して人間がデータを読む⇒コンピューター自身がデータを読む)」時代に変わりつつあります。
それを実現するためには総務省の資料にあるように、データの形を整える必要があります。そして、整えるだけではなく、いつでも使える状態にしておく必要があります。
そこから初めてデータ利活用というフェーズに進めます。
この記事が不要になったとき、初めて次のフェーズに進めていることになっているでしょう。
この記事のソースはgitにあるので、ご参考に。https://github.com/tutti-tsuyoshi/excel2df.git
ここまで読んでくださった方、ありがとうございました。