概要
日本語(活字)が縦書きで書かれた画像から、文字起こしを行う効率のよい方法を模索し、Googleドキュメントの機能を使う方法を確立した。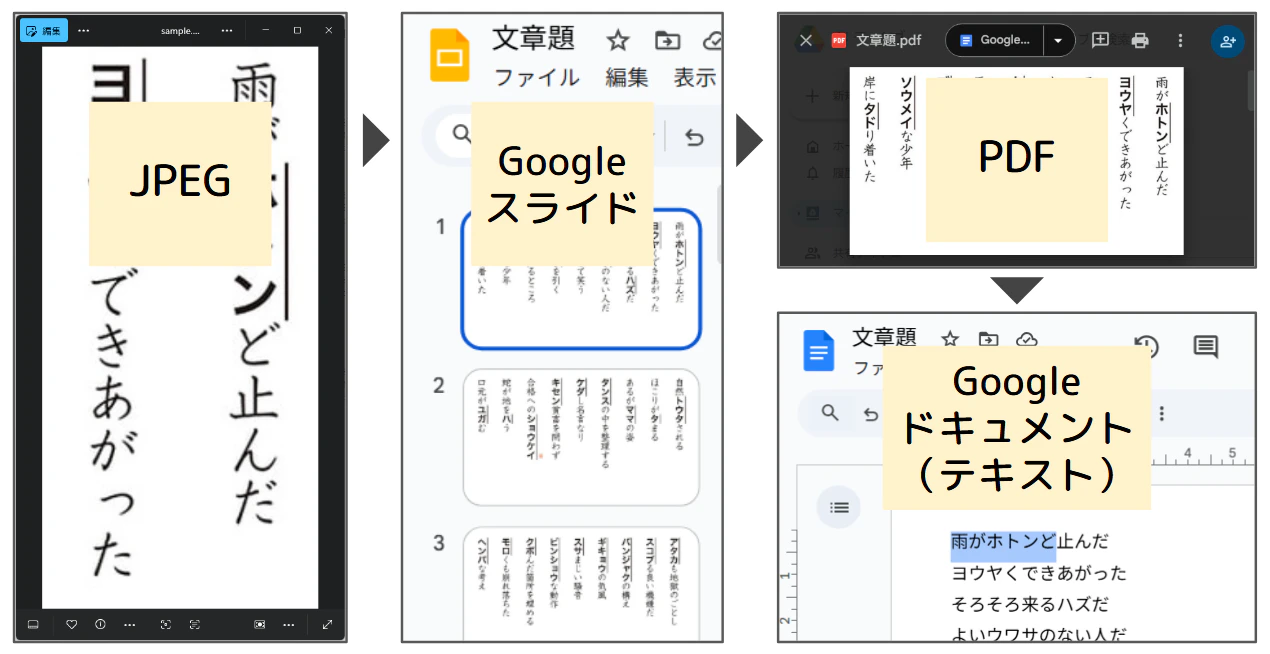
背景
画像やPDFのデータにおいて、日本語の横書きテキストのOCRを行うソフトや機能は多くあるが、縦書きテキストについては精度の高いものが少ないようである。
今回私は、漢字検定の問題集を暗記カードアプリに取り込むため、文字起こしをする必要に迫られた。しかし、いろいろな方法を考えたが、どれも現実的ではなかった(詳細は後述)。
没になった案
- ココナラ等のサービスで外注
- PDFのOCRを行うツール
- Kindle版で文字をコピー
- 自分で入力する
方法
ゴールの確認
ゴール
- JPEG画像から、テキストを取得する
- 100%の精度は目指さず、最後は手動で修正する
手順
- スキャン(もしくはスクショ)で画像を用意する
- 画像をGoogleスライドに貼り付ける
- スライドをPDFでエクスポートする
- PDFをGoogleドライブへアップロードする
- PDFをGoogleドキュメントで開く
- データを整形する
必要なもの
- Googleアカウント
1. スキャン(もしくはスクショ)で画像を用意する
画像でなくてPDFなどでも構わない。段組みがなく、行がはっきりしていることが一番のポイントである。Kindleのスクショを自動化するノウハウなんかもあるらしいが、電子書籍のスクショを取る場合には、利用規約的に問題がないかの確認も必要そうである。
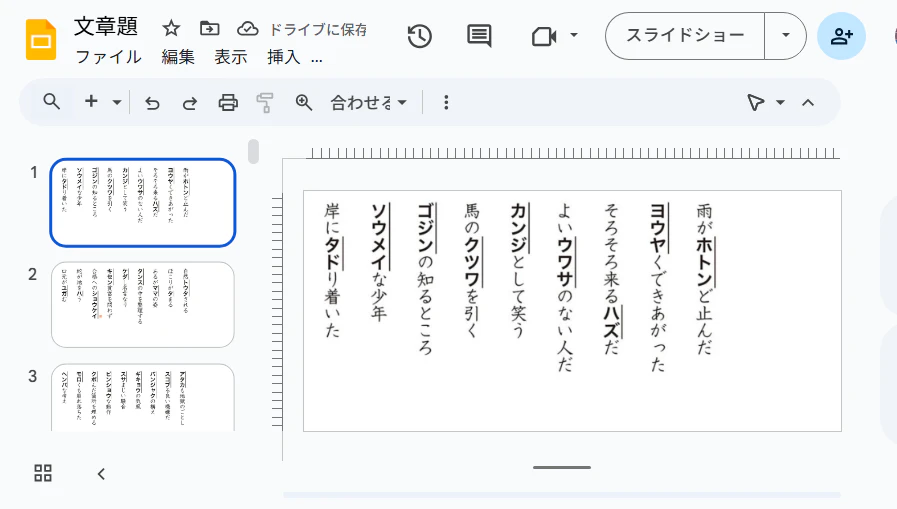
2. 画像をGoogleスライドに貼り付ける
この作業は、段組みをなくし、複数の画像ファイルを正しい順序で一つのファイルにまとめるために行う。原稿画像が2段組みの場合、認識される順序は上の1行目→下の1行目→上の2行目→下の2行目……となってしまう。そこで、段ごとに別のスライドに分けることで段組みをなくす。別に画像自体をトリミングするのでもよいが、順序の入れ替えなども含めいろいろな小手先のテクニックが使えることから、スライドを使った。
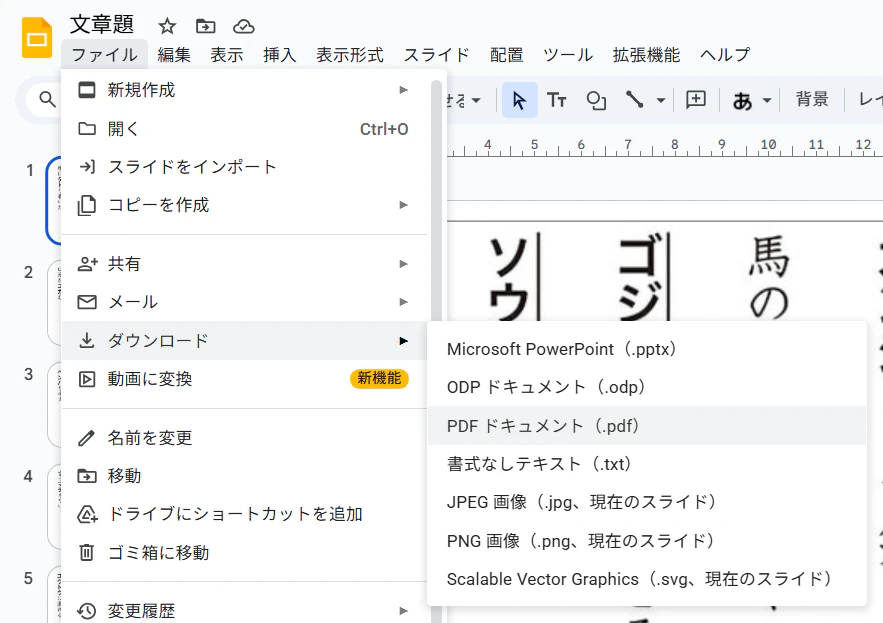
3. スライドをPDFでエクスポートする
「メニューバー > ファイル > ダウンロード > PDF ドキュメント (.pdf)」
からPDFでエクスポートする。
4. PDFをGoogleドライブへアップロードする
Googleスライドのエクスポートはダウンロードになってしまうので、再びGoogleドライブへアップロードする。
5. PDFをGoogleドキュメントで開く
アップロードしたPDFをGoogleドライブ上で開く。次に、画面上部のメニューから、これをGoogleドキュメントで開く。これがこの方法の一番のポイントである。
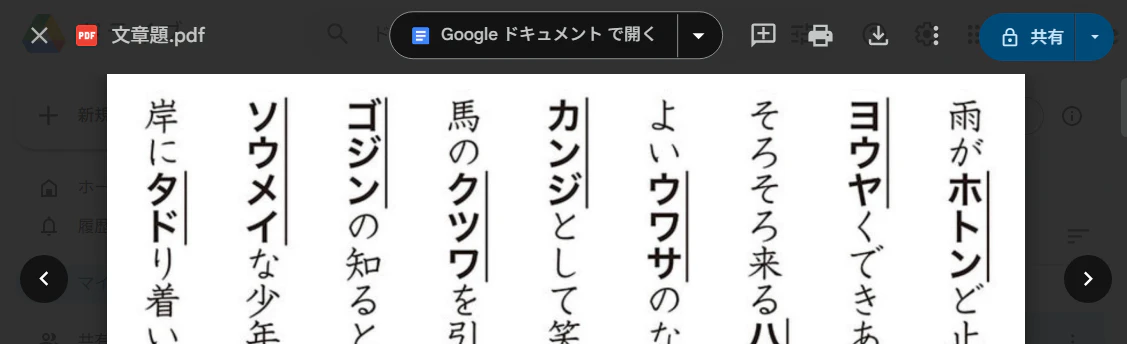
ここで、OCRが働き、PDFに含まれた文字がテキストデータに変換される。ドキュメントで開かれた直後は書式がめちゃくちゃで読みづらい状態になっていたりするので、すべて選択して「標準テキスト」のスタイルを適用するなどする。これで、文字起こしが完了する。
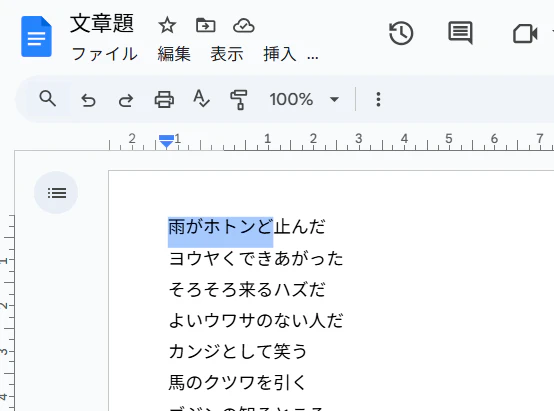
6. データを整形する
文字起こし直後のデータは、空白が含まれていたり、改行の有無が不規則だったりする。最終的な細かい修正は目視・手動になるが、ある程度は置換等で処理できる。
まず、こういう場面で出てくる空白には大きく2種類あり、普通の半角スペース「 」(U+0020)と、ノーブレークスペース 「 」(U+00A0)である。これらを置換で除いたり、連続しているものを1つだけにしたりする。また、改行(\n)を除くこともできる。ただし、逆に「改行に置換」することはGoogleドキュメントではできないため、そのあたりを細かく処理したいときはWordなどに移行したほうがよい。
以上により、全体的にはかなり精度よく、ほかの方法に比べて速く文字起こしすることができた。
今後の課題
一方で、特定の場合において顕著にうまくいかなかったパターンがあった。それは、1~2文字しかないような行が続いた場合だ。これがうまく縦書きとして認識されず、横書きの判定になってしまった。そのせいで、行の順序が入れ替わったり、飛んだり、文字がばらばらになったりすることが不規則に起きてしまった。
あとがき
こうして、無事問題集をテキスト化することができた。丸々1冊を暗記カード(ankiアプリのインポート用データ)にするところまで含めて、全体で数十時間かかっているので、時給換算したらココナラも料金的には妥当な額なのかもしれない(でもかけたくはない)。
最後に、没になった案たちを紹介するぜ!
没になった案
ココナラ等のサービスで外注
数週間かかるうえに少なく見積もって数万円かかりそう。テキストには「繫」と書いてあるのに「繋」とかで納品されて、修正依頼をして(もしくは自分で修正して)、なんてのを想像したら、コスパが悪すぎると思った。
PDFのOCRを行うツール
有料ソフトの体験版も含め無料で使えるものをいくつか試したが、どれも精度が悪すぎた。そもそも縦書きに対応したものがほとんどないうえに自分でそれらを修正するとなると、自分で入力したほうが早い。「し」→「レ」とか、やってられない。さらに、認識された文字を選択してみると、文章が細切れになって、変な順番で選択されたりする。やってられない。
Kindle版で文字をコピー
普通に紙版で使っていたテキストだったが、わざわざKindle版も追加で購入してみた。テキストの選択はできなかった。
自分で入力する
もちろんこれも考えた。Qiitaなんて使っているくらいだから、文字入力は遅くはないと思っている。しかし、漢検準1級で出る漢字や熟語は、普通に変換しても出てこないものが多い。「春蛙秋蟬」と入力したくて「しゅんあしゅうぜん」と打っても変換では出ないので、一字ずつ「はる」「かえる」「あき」「せみ」と入力して、「春蛙秋蝉」ああ、こっちじゃなくて正字のほうの「蟬」で、とか、そんな具合になる。到底普通の漢字かな交じり文を入力する速度にはならない。