一番最初に。
この記事ちらかってますので、一番最初に以下のことをことわっておきます。
- self-attentionというのは、1種類ではないです。transformerのが有名かもしれませんが。
- self-attentionが、単語のembeddingを掛け算して、似たものを反応させていると思われている方がいるかもしれませんが、直接の掛け算は、していない。少なくとも、重みも込みで掛け算しているので、似たものが。。。というような作用はあまり残っていないはず(※1)。また、self-attentionの中でも、かけるものもあれば、かけないものもある。
(※1)
反例。。。ですが、(その19)Self-Attention Generative Adversarial Networks
にて、まさに、似た部分に作用の例を追加しました。2022/01/20。だから、重みがあっても、めちゃくちゃにはならないのかな。。。
概要の前に
-
 (4連発)印のところ(今、下の方に、1か所)は、価値があるかも。
(4連発)印のところ(今、下の方に、1か所)は、価値があるかも。
(注:全体に浅い理解で情報を集めているので、リンク先を、ばしばし覗いて、有意義がどうかは、ご自分で判断頂くのがいいと思います。)
- その15の「Coursera, Sequence Models(Self-Attention)」は、注目かも。
概要
表題のとおり。(尚、この記事の自分での活用履歴を最近記事に残しはじめました。ココ。)
Self-Attentionを理解したいと思ったが、なかなか、うまく頭に入らない。
わかりやすいと思った記事を紹介する。
前提となるattentionの記事も含みます。(BERTやTransformerも含みます。)
まとめに記載していますが、
一発の記事を読んで理解するのは、厳しいと理解しました。(再掲)
のとおりであり、下地がない人(ワタシとか)には、理解に時間がかかると思います。
以下は、注目です。お勧め順。順番、適当です。順番、極めて、適当です。![]()
![]()
(※企業関連が多い。。。がっかり、、、いや、見る分にはいいのでは。伝えるテクニックを感じますね。。。)
-
その20のVisualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention) Jay Alammar さん。説明の完成形?。transformer以前のモデルですが。
-
その7の『How to get meaning from text with language model BERT | AI Explained(Peltarion) Youtube』
( https://www.youtube.com/watch?v=-9vVhYEXeyQ ) -
その1の『《日経Robo》自己注意機構:Self-Attention、画像生成や機械翻訳など多くの問題で最高精度』
-
その2の『記事(その2)論文解説 Attention Is All You Need (Transformer)』
-
その4の『機械学習におけるtransformer(by ライオンブリッジジャパン株式会社)』
-
その10の**『西尾泰和のScrapbox『注意機構』ほか』**



-
その8の『BERT Research - Ep. 5 - Inner Workings II - Self-Attention』ChrisMcCormickAIのYoutube
-
その5の『Illustrated: Self-Attention』
-
その3の『Deep Learning入門:Attention(注意)[Neural Network Console のYoutube]』
-
その6の『(YDC Labコラム)分かった気になる自然言語AIの仕組み』
わかりやすいと思った記事(その1)
《日経Robo》自己注意機構:Self-Attention、画像生成や機械翻訳など多くの問題で最高精度
日経Robotics 有料購読者向けの過去記事(再掲載)
《日経Robo》自己注意機構:Self-Attention、画像生成や機械翻訳など多くの問題で最高精度
https://xtech.nikkei.com/atcl/nxt/mag/rob/18/00007/00006/
なぜ、わかりやすいか
- Preferred Networksの岡野原 殿による記事であり、よくわかっている人なんでしょう。
よって、記事がわかりやすい。
以下、該当ページからの引用
この記事は日経Robotics 有料購読者向けの過去記事(再掲載)ですが
『日経Robotics デジタル版(電子版)』のサービス開始を記念して、特別に誰でも閲覧できるようにしています。
- 表現が端的。
以下、一例。該当記事引用
畳み込みニューラルネットワーク(CNN)は、画像は近い位置にある情報が関係があるという事前知識を使って、近い位置にあるニューロン間のみをつなぐことで
- 画がない記事ですが、逆に?、わかりやすい。
注目すべきところ
以下の引用部は、注目。
この注意機構は、クエリとキーが似ているかどうかで、どの要素の値を読み込むかどうかを制御していることに注意されたい。もし、学習の結果、その要素から値を読み込んだ方がよければ対応するクエリとキーは近づくように更新され、もし読み込まない方が良ければクエリとキーは離れるように更新される。
わかりやすいと思った記事(その2)
論文解説 Attention Is All You Need (Transformer)
論文解説 Attention Is All You Need (Transformer)
http://deeplearning.hatenablog.com/entry/transformer
なぜ、わかりやすいか
- 図が抜群
注目すべきところ
以下の引用部、注目。
↓↓↓↓ この部分、引用です。(次の↑↑↑↑ まで)

↑↑↑↑
わかりやすいと思った記事(その3)
Deep Learning入門:Attention(注意)[Neural Network Console のYoutube]
Deep Learning入門:Attention(注意)
https://www.youtube.com/watch?v=g5DSLeJozdw
Self-Attentionというより、Attention全般の説明。Self-Attentionの説明もある。
なぜ、わかりやすいか
-
見て頂くとわかると思う。説明がものすごくうまい。
ものすごくです。
わかりやすいと思った記事(その4)
機械学習におけるtransformer(by ライオンブリッジジャパン株式会社)
機械学習におけるtransformer
https://lionbridge.ai/ja/articles/machine-learning-transformer/
Self-Attentionというより、Attention全般の説明。Self-Attentionの説明もある。
なぜ、わかりやすいか
- 最初の図からして、すばらしい
まず、以下の図から始まっているが。。。
この図は、ぐっと理解を促進すると思う。
(出典 https://lionbridge.ai/ja/articles/machine-learning-transformer/ )
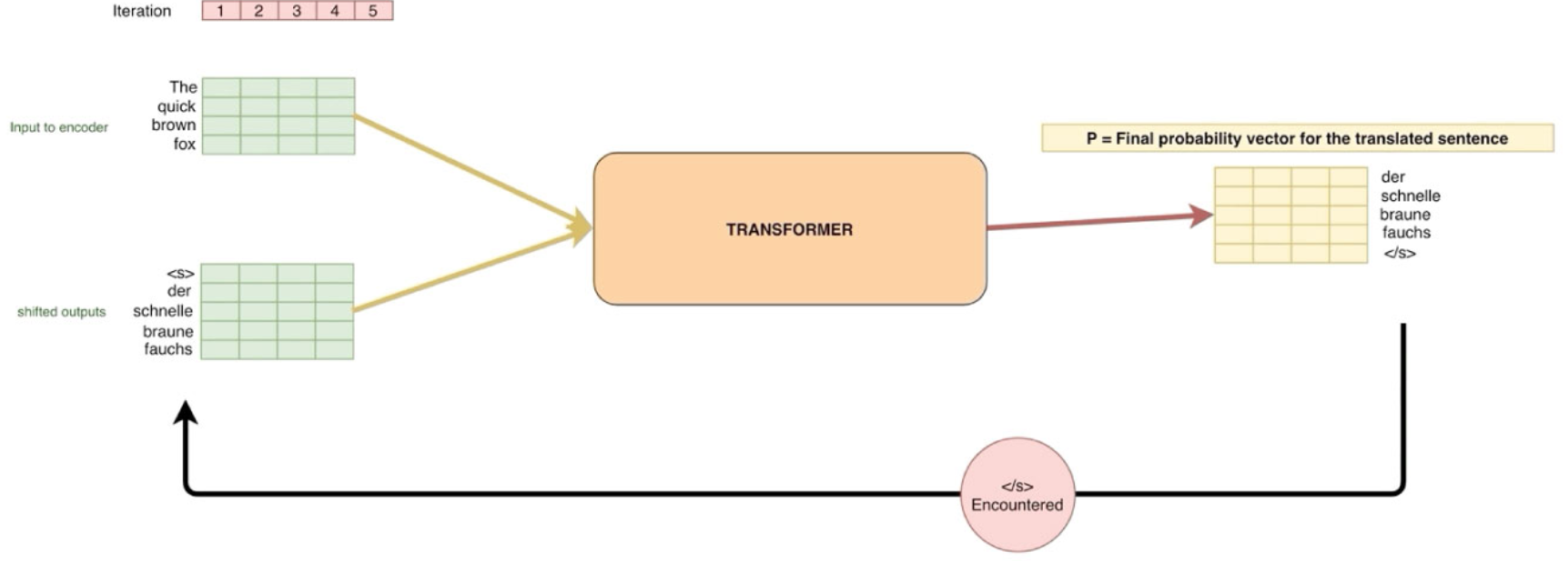
補足情報
- 図の「< /s> Encountered」は、< /s>に出会う(出る)?までの意。
- 元となるこの会社の英語の記事は、以下。
https://lionbridge.ai/articles/transformers-in-nlp-creating-a-translator-model-from-scratch/
わかりやすいと思った記事(その5)
Illustrated: Self-Attention
Step-by-step guide to self-attention with illustrations and code
key, query and value にフォーカスしている。
なぜ、わかりやすいか
- key, query and value にフォーカスしていて、ここが基礎?(第一関門のはず?)なので良い。
- シンプルなサンプルコードがある。まだ、試していない。
- 図(アニメ)がわかりやすい。↓
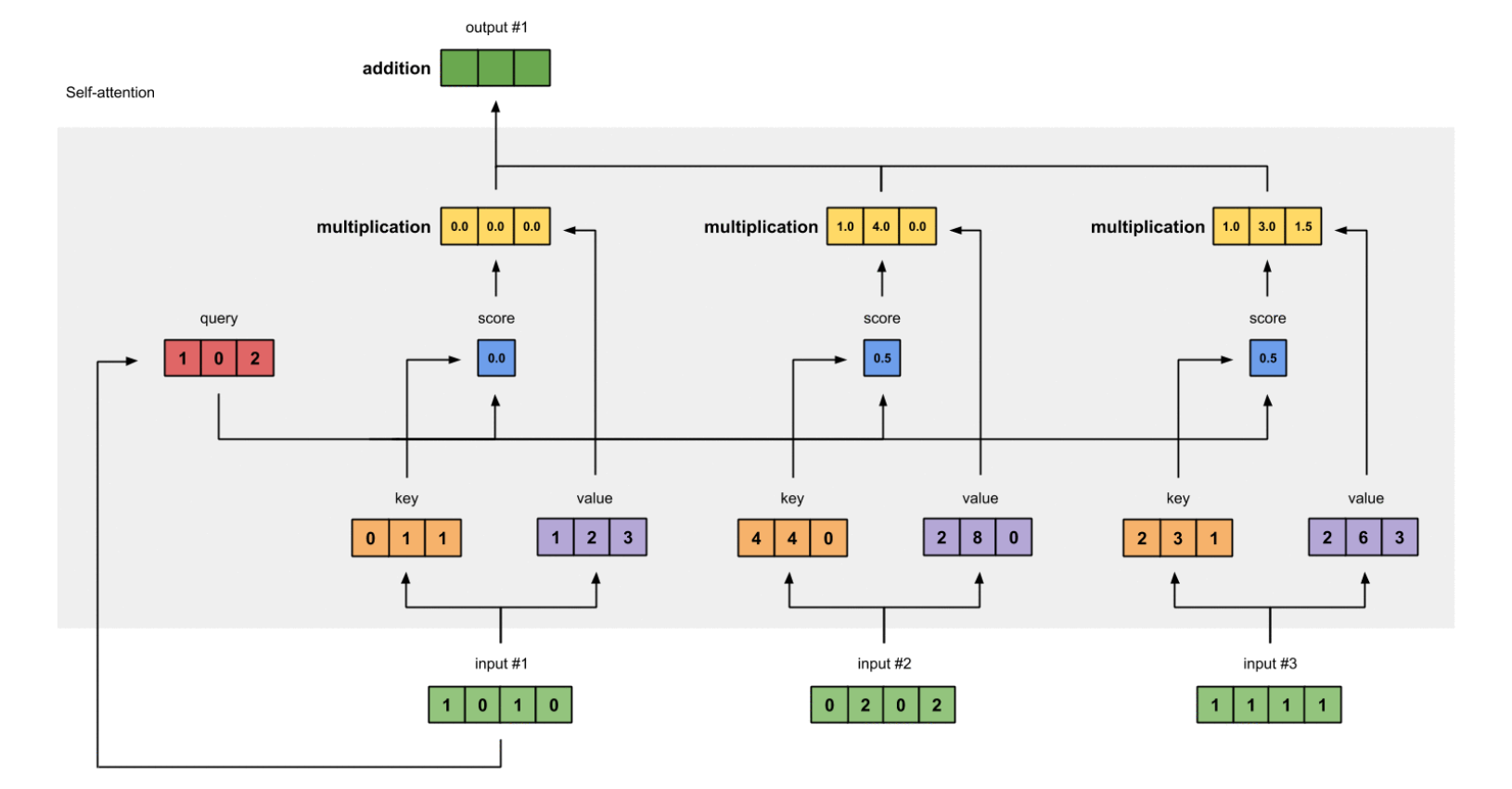
わかりやすいと思った記事(その6)
(YDC Labコラム)分かった気になる自然言語AIの仕組み
なぜ、わかりやすいか
| なぜ、わかりやすいか(1ポイント) |
|---|
| 前提として、単語がベクトル表現されることを、最初に、非常に具体的に示している。 |
導入がいい。(下記の図)
単語がベクトル表現されることを、まず、示している。
ここを、非常に具体的に示しているので、後が理解し易い。
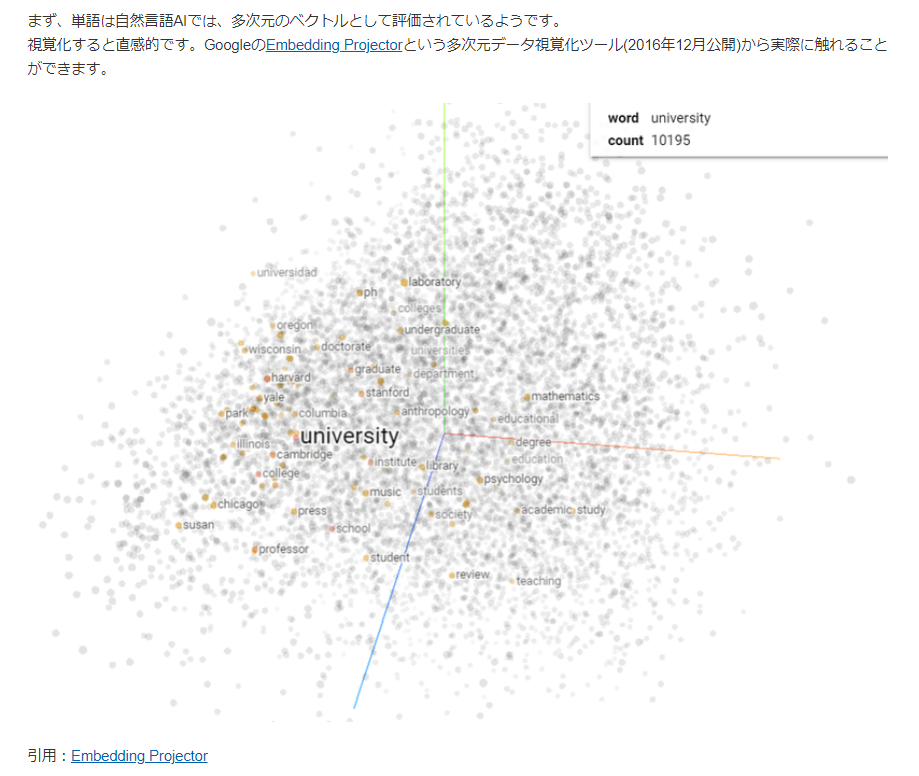
補足
self-attentionが、単語のベクトル表現どおしを内積して類似度を算出しているように読める可能性あり。実際はそれほど単純ではないことは、自明。
わかりやすいと思った記事(その7)
How to get meaning from text with language model BERT | AI Explained(Peltarion) Youtube

なぜ、わかりやすいか
| なぜ、わかりやすいか(1ポイント) |
|---|
| 3次元グラフィックスの動画による説明。3次元グラフィックスは、中味をあまり理解せずには作れないでしょうという信頼感。 |
英語だが、英語わからなくても、説明で理解できる部分あり。
また、濃淡で、値を示している部分などにおいて、
コンピュータグラフィックス ![]() なので、マジの値になっていると思える部分があり、
なので、マジの値になっていると思える部分があり、
単なる一枚の図においても、いろいろな情報が、読み取れる。
↓このYoutubeの画像引用。この画の濃淡から、なるほどね。。。と読み取れる内容がある。
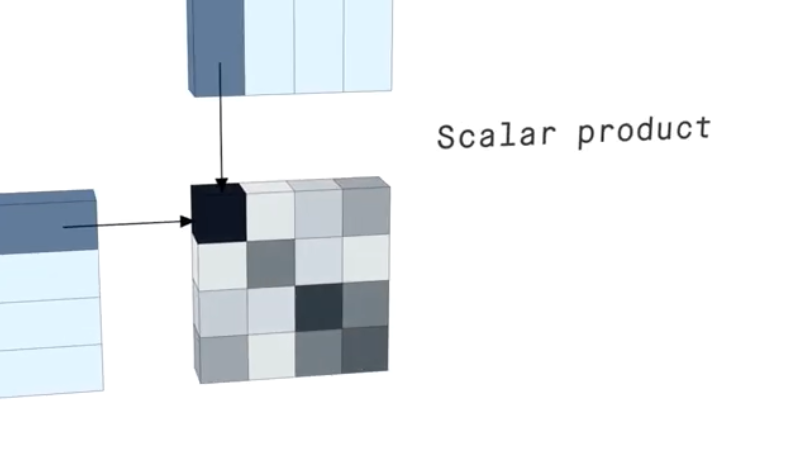
たしか、10分ぐらいの短い動画なので、5回ぐらい見られることを推奨。
わかりやすいと思った記事(その8)
BERT Research - Ep. 5 - Inner Workings II - Self-Attention(ChrisMcCormickAI,Youtube)
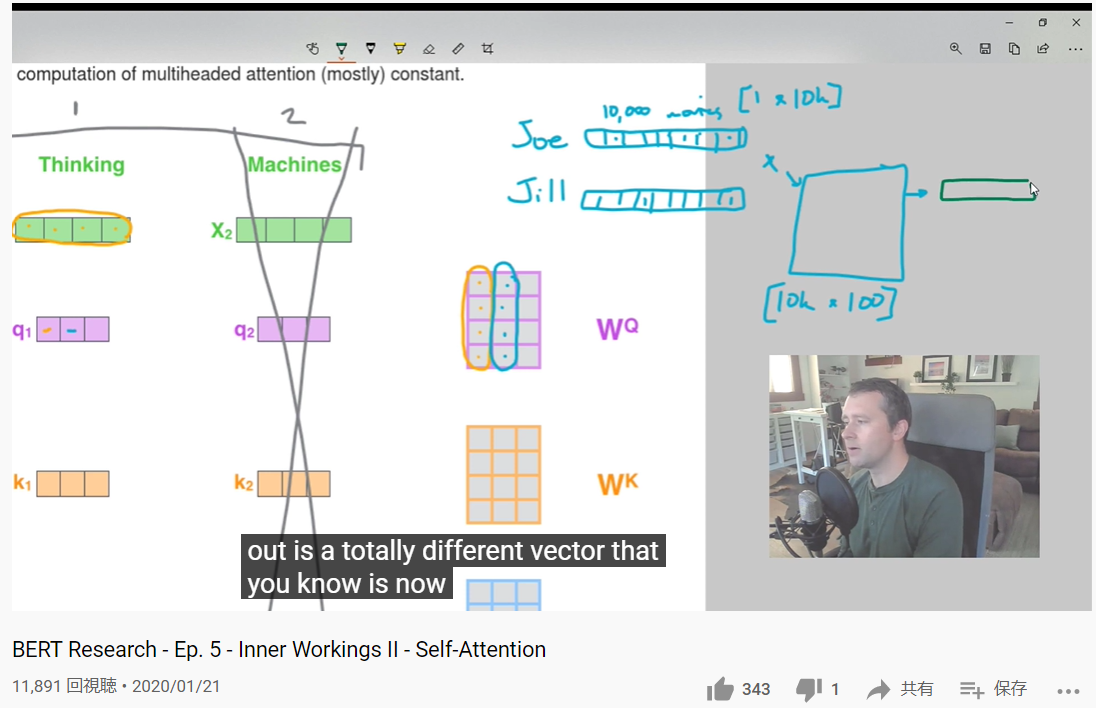
なぜ、わかりやすいか
| なぜ、わかりやすいか(1ポイント) |
|---|
| (実際にうまくいっている)BERTに関するものなので、一般論でなく、うまくいく技術が理解できるし、シリーズを通してしっかり学べる、2、3Hr。 |
これは、Ep.5であるが、全体を通してみる必要があると思う。(かなりの時間になる。2,3時間?)
わかりやすいと思った記事(その9)
Self Attention and Transformers(Towards Data Science)
※会員か何かしかアクセスできなくなっていると思います。。。。NGですね。

なぜ、わかりやすいか
| なぜ、わかりやすいか(1ポイント) |
|---|
| 図が省略が少なく、広い範囲を大きい図で詳細に書かれている。(省略されていないので、)さて、あの処理はどう入っている?とかいう疑問が発生しづらい。 |
わかりやすいと思った記事(その10)
西尾泰和のScrapbox『注意機構』ほか
↓ソースターゲット注意から自己注意への流れが面白い。以下のキャプチャは、該当ページのキャプチャ
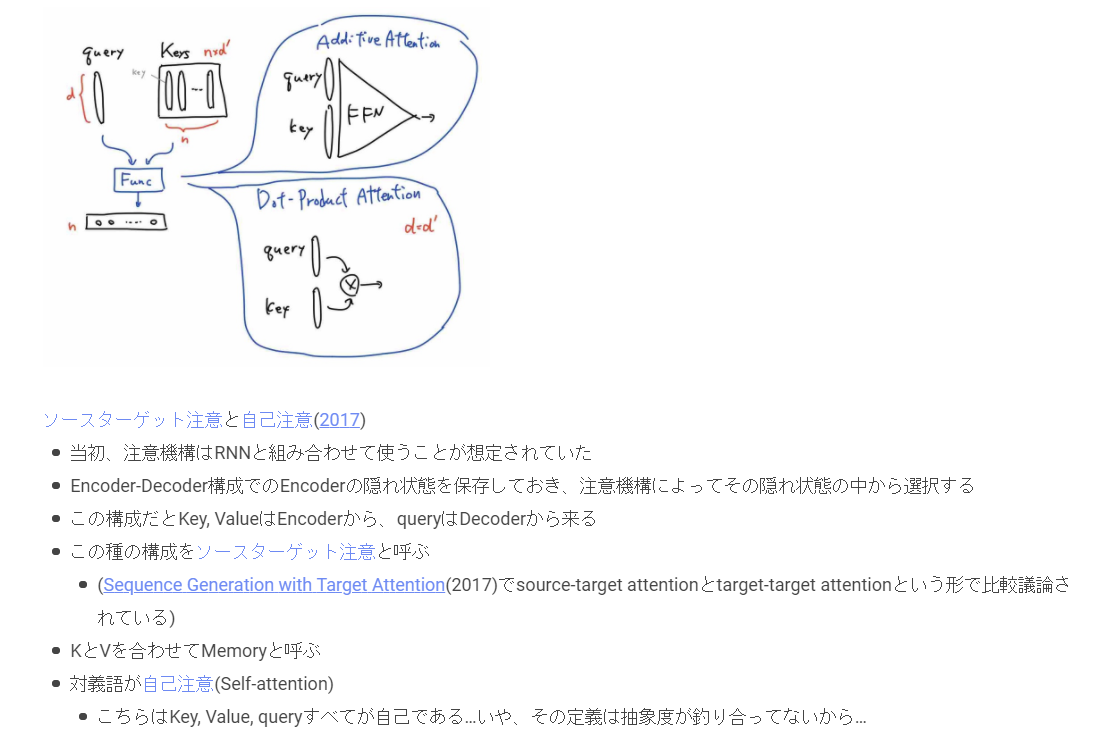
他にも、
「CNNと自己注意」
なぜ、わかりやすいか
| なぜ、わかりやすいか(1ポイント) |
|---|
| わかりやすいというよりは、考えがいろいろ示されていて、かなり、面白い。 |
| 他のサイトの記事などで、処理内容や、処理手順はわかるが、意味の説明がしっくりこない場合にこれらの記事は、役立つと思う。 |
わかりやすいと思った記事(その11)
Transformerを雰囲気で理解する
なぜ、わかりやすいか
| なぜ、わかりやすいか(1ポイント) |
|---|
| 時系列に説明されているため。Transformer以前のことを把握できるため。 |
わかりやすいと思った記事(その12)
本当は、これは、ものすごくいいはず。
いま、おなか一杯で、あまり、褒めてませんが、とにかく、すばらしいはず。
The Illustrated Transformer
↑↓ このサイトでは、以下の図がアニメで表示される。ものすごく、わかりやすいはず。

なぜ、わかりやすいか
| なぜ、わかりやすいか(1ポイント) |
|---|
| (その8)の人がすすめていた。 |
わかりやすいと思った記事(その13)
記事ではなく、まとめの論文ですが、、、
Attention in Natural Language Processing
Galassi, Andrea, Marco Lippi, and Paolo Torroni. "Attention in natural language processing." IEEE Transactions on Neural Networks and Learning Systems (2020).
要約を抜粋引用する(DeepL訳)
Attentionは、様々なニューラルアーキテクチャで使用されるメカニズムとして、ますます普及しています。このメカニズム自体も様々な形式で実現されている。しかし、この分野では急速な進歩を遂げているため、注意についての体系的な概要はまだ明らかになっていない。
・・・
このエキサイティングな分野の膨大な文献を初めて広範に分類した。
「General attention model」が提案されている。↓
⇒ いろんなのがあるから、整理されるのは、すばらしいと思う。
この論文( https://arxiv.org/abs/1902.02181 )から引用↓
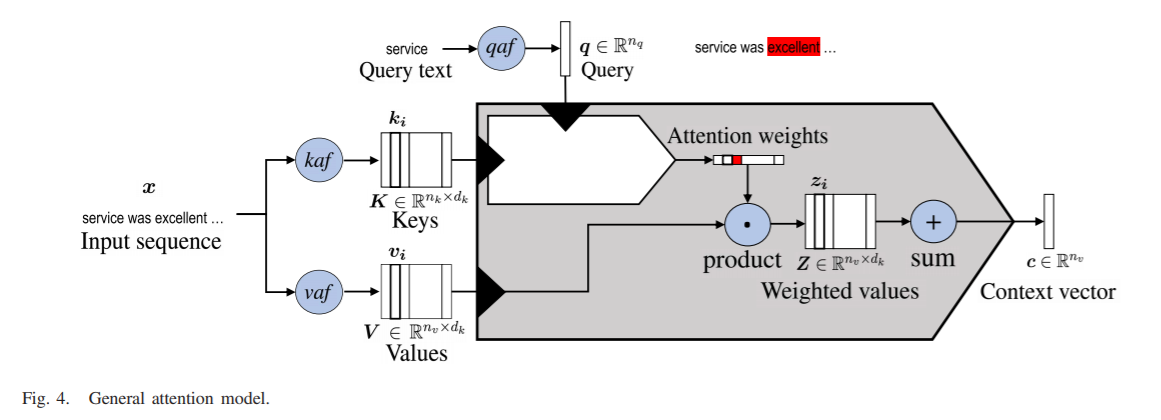
なぜ、わかりやすいか
| なぜ、わかりやすいか(1ポイント) |
|---|
| Attentionに関して、広範に分類、されているため |
【制約付き】わかりやすいと思った記事(その14)
【制約】画像に興味がある方限定。
(少し、言語系で煮詰まった場合に、いいかも。。。)
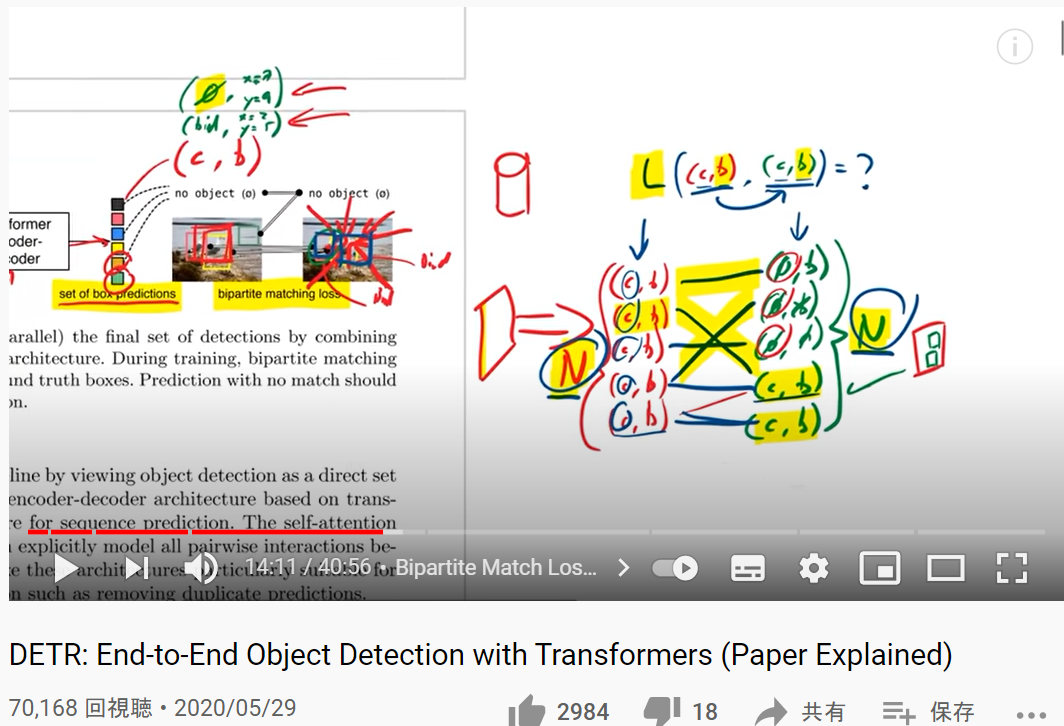
DETR: End-to-End Object Detection with Transformers (Paper Explained) [YouTube,Yannic Kilcher]
Youtube。Yannic Kilcherさんのチャンネル。たぶん、有名。
なぜ、わかりやすいか
| なぜ、わかりやすいか(1ポイント) |
|---|
| ロス関数のあたりの説明が詳しい。 |
(出典:このYouTube)
わかりやすいと思った記事(その15)
Coursera, Sequence Models(Self-Attention)
courseraのすごくしっかりしたもの。超有名なはず。
なぜ、わかりやすいか
| なぜ、わかりやすいか(1ポイント) |
|---|
| 文章の中の単語の関係が、self-attentionでわかる仕組みを実際の文章で説明してくれている。単語間の類似の考え方がわかる。馬とシマウマが類似するというだけでなく、Africaとvisitは、広い観点で類似する(関連がある)ということがわかる。 |
(出典:ここの動画)
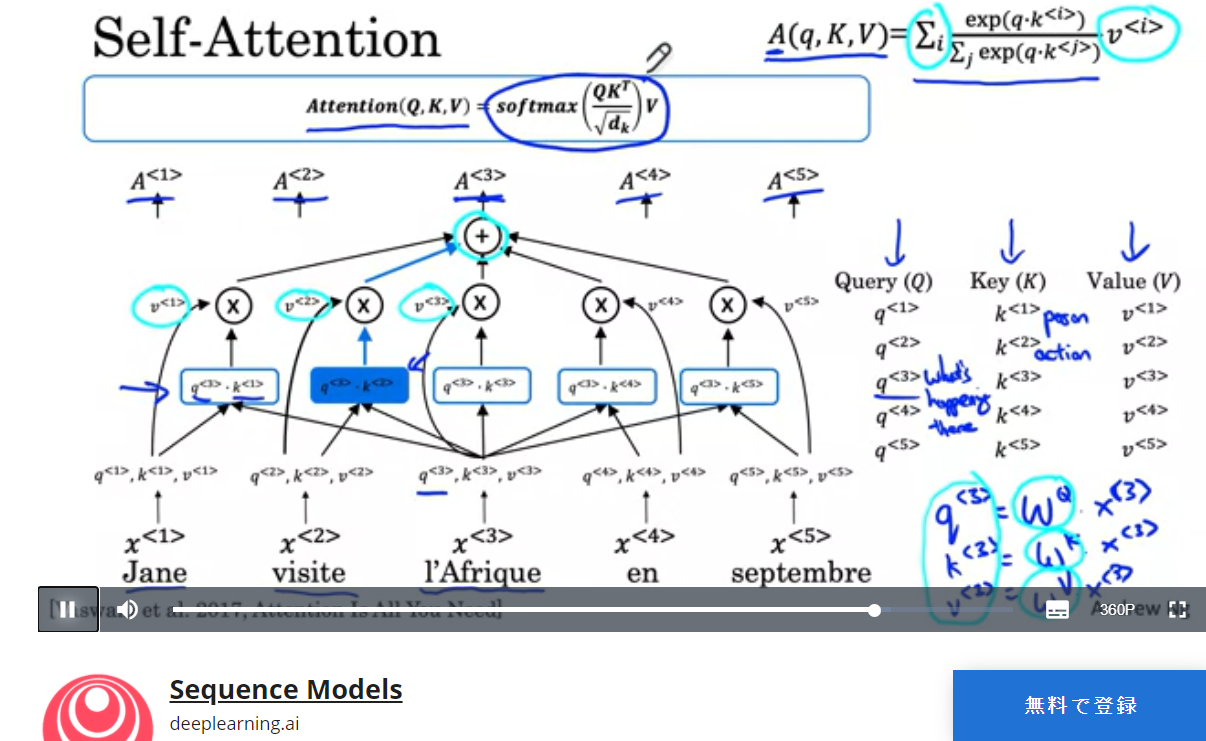
補足情報
- 「Jane visite l'Afrique en septembre.」(フランス語)は、見たままで、「Jane visits Africa in September.」の意です。
わかりやすいと思った記事(その16)
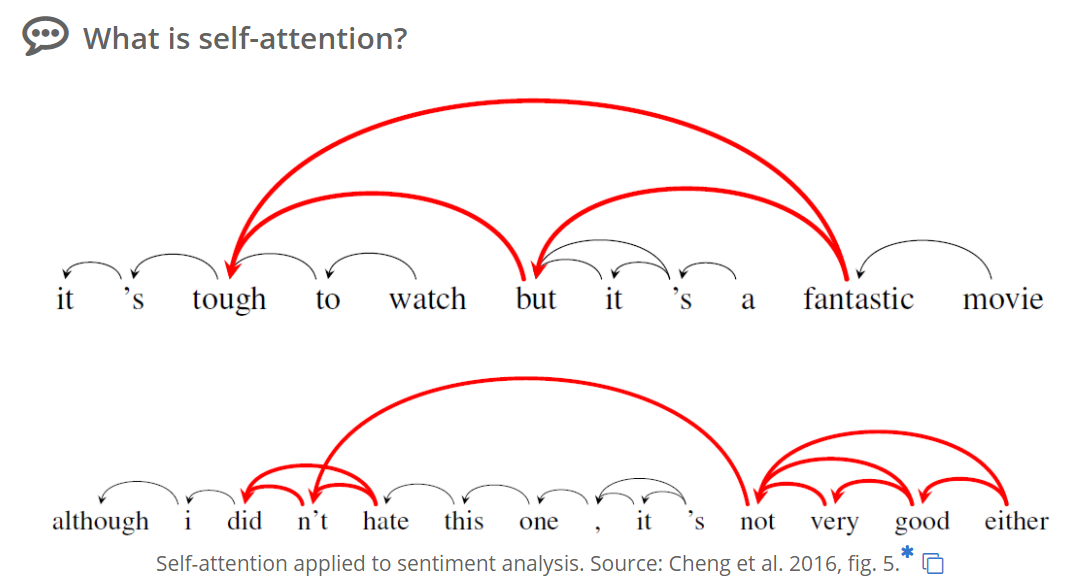
Attention Mechanism in Neural Networks(DEVOPEDIA)
DEVOPEDIAって、良さそう。
なぜ、わかりやすいか
| なぜ、わかりやすいか(1ポイント) |
|---|
| Self-attentionに関して、下図のような基本部分のことが書かれているため。 |
わかりやすいと思った記事(その17)
Transformer Neural Network Architecture(DEVOPEDIA)
DEVOPEDIAって、良さそう。
なぜ、わかりやすいか
| なぜ、わかりやすいか(1ポイント) |
|---|
| (すみません、あまり、まだ、内容見れていません。)良さそうと思うだけ。 |

わかりやすいと思った記事(その18)
Vision and Languageと分野を取り巻く深層学習手...
↓ 上記より引用
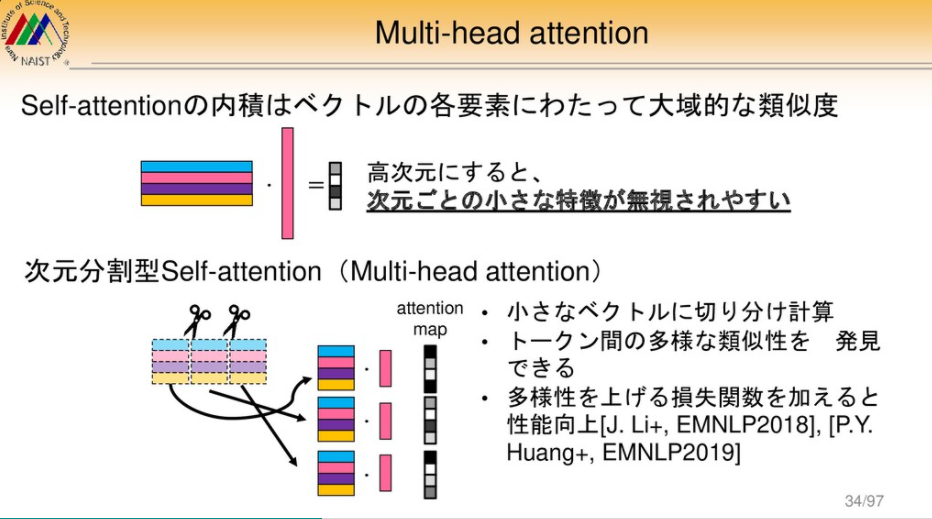
なぜ、わかりやすいか
| なぜ、わかりやすいか(1ポイント) |
|---|
| 広い範囲の技術を対象に、語っているから。 |
ちょっと、オシイところ(余計なお世話ですが、、、、)
self-attentionの作用は、こうじゃないでしょうね(笑)。まぜこぜになるのは正しいとして。インプットの画から変えて欲しい!(うまくかけると世界レベル???)
↓ 引用
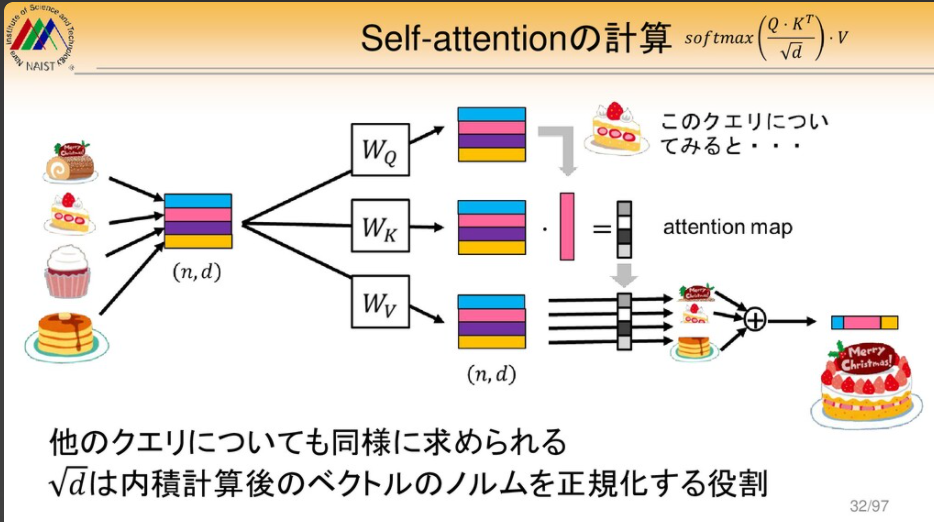
わかりやすいと思った記事(その19)
Self-Attention Generative Adversarial Networks
↓ 上記より引用

↑↑ この画、凄いーーー!(か、しょーもないか(この程度でどういう貢献になるのだろうの意。)、微妙ですが。。。)
なぜ、わかりやすいか
| なぜ、わかりやすいか(1ポイント) |
|---|
| (GANになっているんですが、)self-attentionで、画像の似たような部分を、積で、見つけ出してattentionにしている!! これよりわかり易い画があったら、紹介して欲しい。 それにしても、画像のself-attentionは、めちゃくちゃですね。。。 滅茶苦茶だけど、意味がある可能性があるとしてやっているのだと思う!!! |
補足
↓ qiitaのこの方の説明、わかり易い。
https://qiita.com/merry1221/items/3bc5da52520c5db867ba
引用
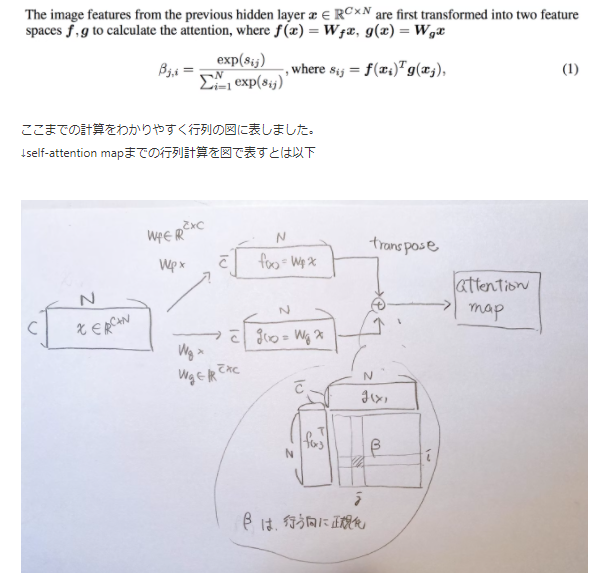
わかりやすいと思った記事(その20)
Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)
↓ 上記より引用
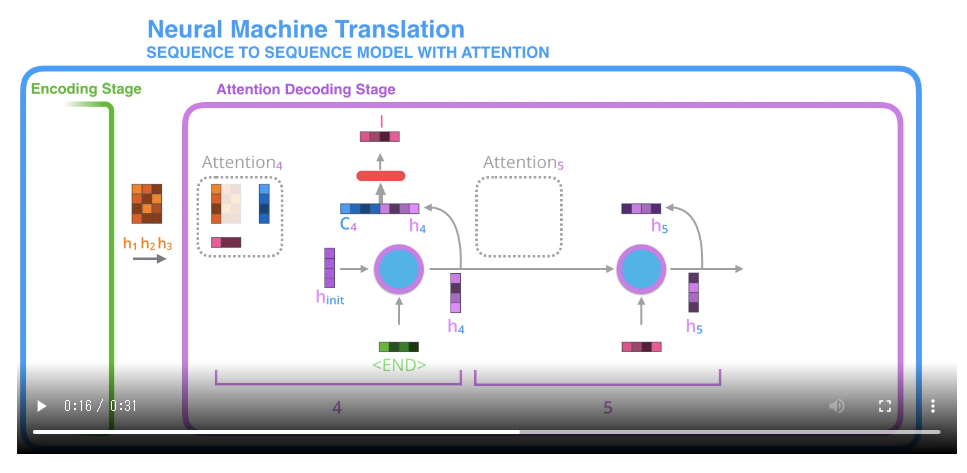
** transformer以前のモデルに関してです。でも、結局、ここが重要? **
なぜ、わかりやすいか
| なぜ、わかりやすいか(1ポイント) |
|---|
| 動画になっています。説明の完成形でしょうか!!!Jay Alammarです。 |
補足
翻訳あります。
https://tips-memo.com/translation-jayalmmar-attention
わかりやすいと思った記事(その21)
Peeking into the neural network architecture used for Google's Neural Machine Translation
↓ 上記より引用
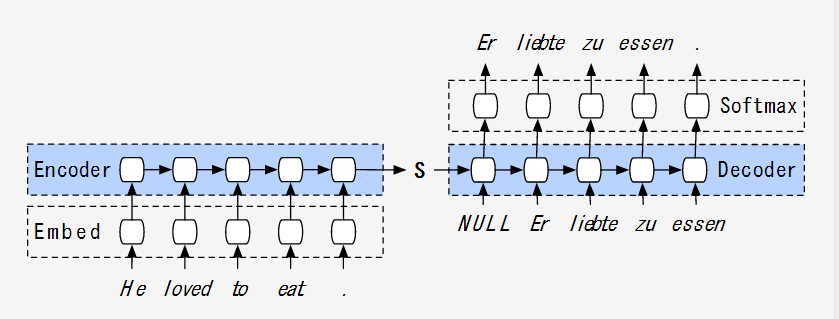
なぜ、わかりやすいか
| なぜ、わかりやすいか(1ポイント) |
|---|
| わかりやすいというか。。。『記事(その2)論文解説 Attention Is All You Need (Transformer)』の方とかが、参照、引用されていると思う記事のため、多分、重要。 |
実際に役立った部分
 01
01
『記事(その2)論文解説 Attention Is All You Need (Transformer)』の以下の図あたり
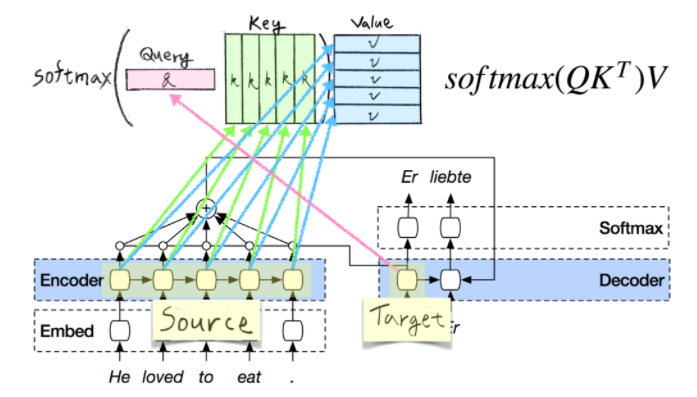
02
『記事(その4)機械学習におけるtransformer(by ライオンブリッジジャパン株式会社)』の以下の図もふくめ、全体。
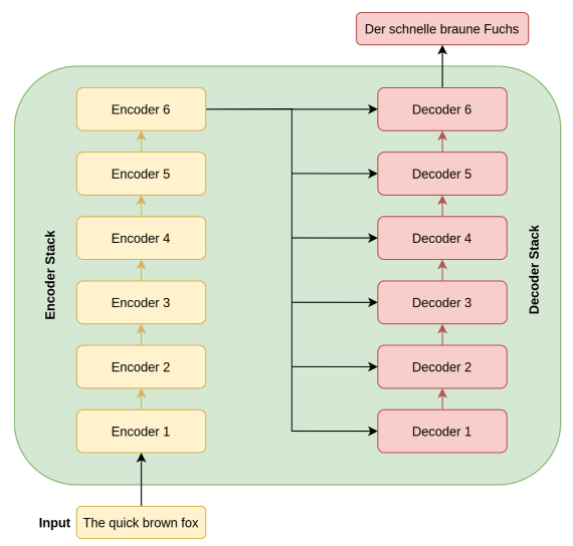
↑ たぶん、『Attention Is All You Need』の論文を理解するためには、例えば、この上記の引用記事を読まないと不可能な気がする。(別の同様の良い記事でも当然いいのだが。)
以下の引用で、D=512他の実際の数値、その数値がどこの値かが確認できる。

説明文、引用。↓
エンコーダ層は、下図のように入力がSxDの形状であることを想定しています。(Sはソース文、つまり英語文の長さを示し、Dは、ネットワークで重みを学習することができる埋め込みの次元を示します。)本記事では、Dにはデフォルトとして512を使用しますが、Sはバッチ内の文の最大長になります。そのため、通常、Sはバッチによって異なります。
⇒ ここで、Dが512で、Sはバッチ内の文の最大長、であることがわかる。
実は、よくわかっていない部分 
01 (2021/03/25) ⇒ Sloved(2022/09/24)
『記事(その2)論文解説 Attention Is All You Need (Transformer)』の
下図の赤丸をつけた線の作用(意味)がよくわかっていない。全く、わからない。
(↑ 実は、予想もつけられないほど、わかっていない。)
また、青丸をつけた矢印の作用、段取りもよくわかっていない。
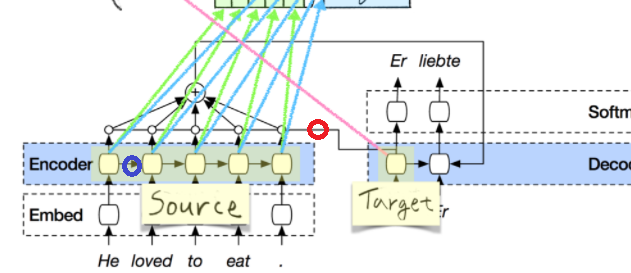
| 上記の不明点に対する回答 |
|---|
| (不明点を記載時に全く何もわかってなかったのがわかるが。。。) 赤丸は、普通のseq2seqにattentionを加えた場合のattention、青丸は普通のLSTM(RNN)。 |
02 (2021/04/04)
『記事(その2)論文解説 Attention Is All You Need (Transformer)』
の以下の抜粋部の説明。
Convolutionの場合、一発では届かない意か?何層かで、Maxpoolingとかも含めると届くのでは?(←画像を対象にした場合の話を混ぜてしまっている、ワタシ?)。あと、単なる画として、Self-attentionoの画をもっと幅広にしたほうが、差がわかり易い?。
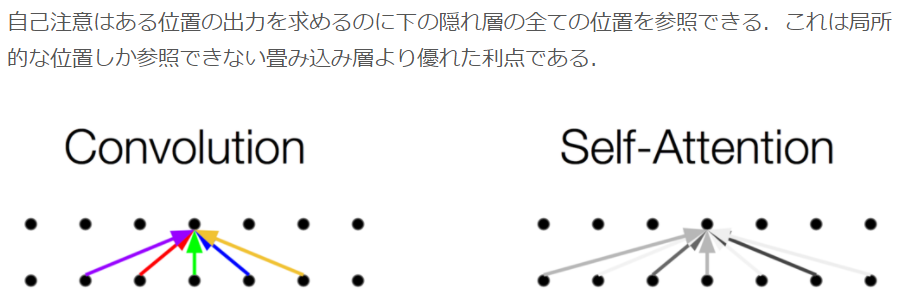
| 上記の不明点に対する回答 |
|---|
| <回答欄のみ準備> |
03 (2021/05/19)
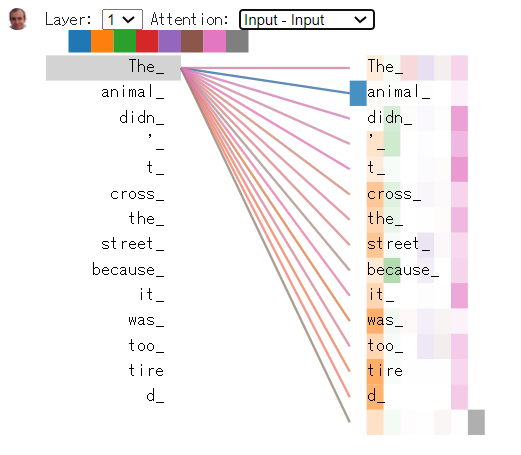
『記事(その12)のThe Illustrate3 Transformer』
のnootebookによる図(画面)↓↓で、「The」が「animal」だけにフォーカスできているが、
これがどうやればそうなるのかが、よくわからない。しかもレイヤ1で。
Word Enbeddingの値をもとに、例えば、Self-attentionと称して乗算とかするだけで、そうなるわけがないので、これは単なる学習の成果なんだろうと思うが、学習の仕方がよくわからない。
「Self-attentionの乗算」「Word Enbeddingの値」「学習」とあって、前者2つが強調されるので、なんか基本がよくわならなくなっている(とヤツあたり)。
冠詞や、代名詞や、接続詞の作用がわからない!!!
「Self-attentionの乗算」で、何か凄いことが起きるような説明は、ちょっと、ミスリーディングじゃないのかな。。。。(凄いことが起きるための1要素では当然あると思うが。。。)
| 上記の不明点に対する回答 |
|---|
| <回答欄のみ準備> |
まとめ
特にありません。
上記の記事(まだ9個ですが。。。)、読んでみることをお勧めします。
適宜、追加します。
ただ、正直、基地知識不足を感じています。一発の記事を読んで理解するのは、厳しいと理解しました。
以下の自分の記事とも、整合をとったり、融合したりしたい。
Attention Is All You Need の 『Attention』を、段階を踏んで、理解する手段
余談ですが、
詳しい方には、当たり前の内容だと思いますが、自分なりに理解が進んだと感じた内容を記事もの、以下。
Attention Is All You Need のQuery, Key, Valueは、Query, Query, Queryぐらいの解釈でも問題ない(と思う。)
以下は、余興。
BERTと、論文『Attention Is All You Need』に対する読解力を、競ってみた(全20問)。
くどいですが、以下なども関連記事。
論文『Attention is all you need』を読み間違わないコツN選(まだ、N=1)。
DETR(End-to-End Object Detection with Transformers)の解説でわかりやすいと思った記事N選(まだN=3)
余談
リンク先がなくなっていると、、、寂しい気分になりますね。(完全に余談です。。)
余談2
以下の記事で、引用?、紹介されていました。。。。役立った。。。
論文『Attention in natural language processing』は、Transformerとかを理解するためには、もっと、読まれてもいいのでは?