テキスト分類における前処理
自然言語処理の基本について、GoogleのMachine Learning Guidesを参考にまとめました。
今回は以下の図で左側、語彙に対するサンプル数が1500以下の場合でMLPモデルを構築するフローを説明します。
なお、今回はサンプルコードなどは省略し、pytorchやsklearnでのアプローチにも適用できる考え方として記述していきます。
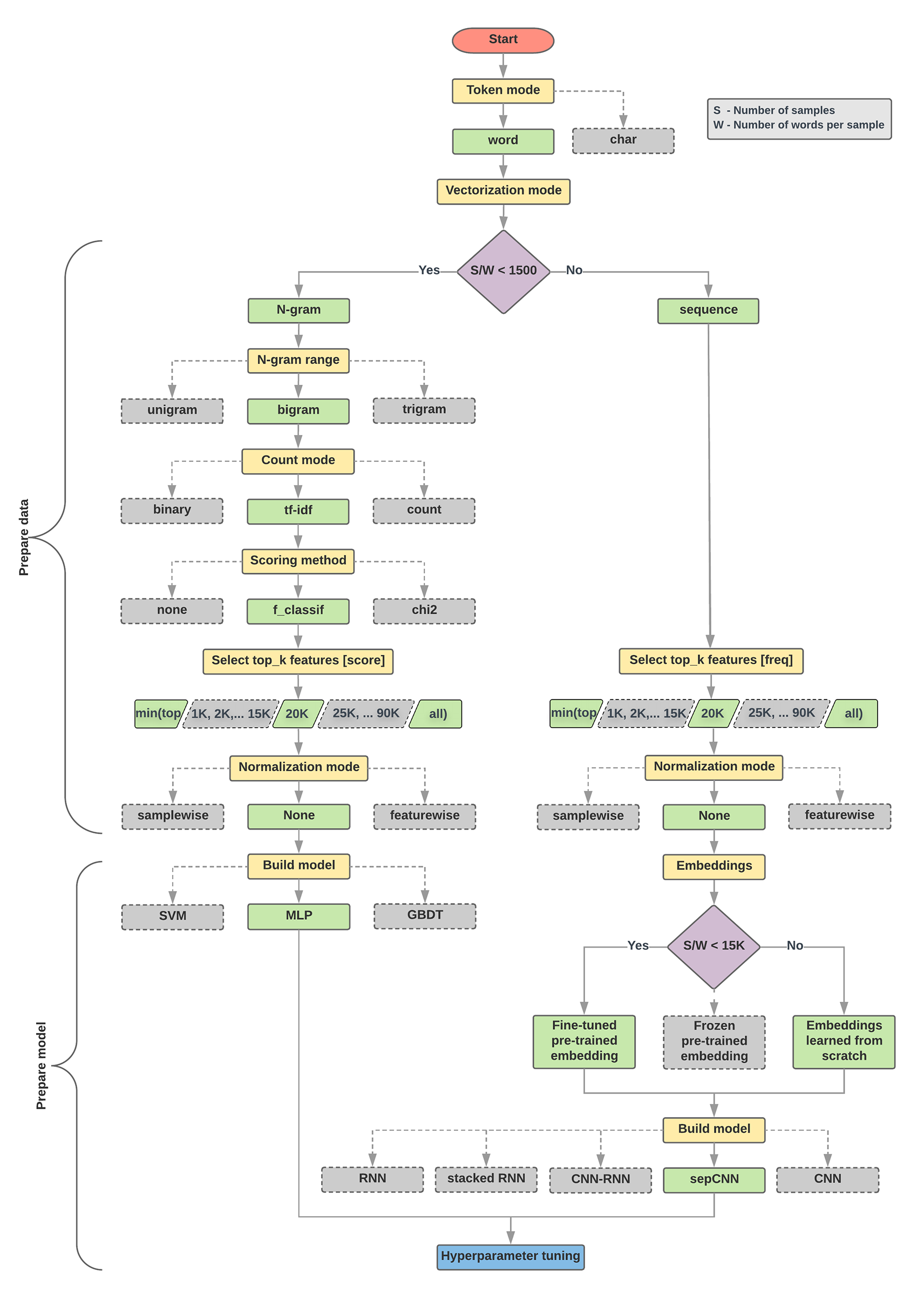
前処理のステップ
- N-gramで分かち書き
- TF-IDFでベクトル化
- 特徴選択で学習に適したデータ次元数に
N-gram
N-gramとは、テキストをN個の文字あるいは単語で分割した言語モデルを指します。

分割した文字列片の共起頻度を計算することにより、直前(N-1個)の単語から次の単語を予測することができます。
つまり、Iの後はamが来やすいだとか、いいの後には天気が来やすいということが、文章を集めてくるとわかってくるので、そこから予測を立てられるわけです。
日本語でN-gramを使う際の注意点
N-gramは辞書を使わず機械的に分けるため、「辞書に依存しない」というメリットがあります。
なお、日本語ではスペースで区切られていないため、単語ではなく文字数で分けることになります。(上図参照)
一方で、「データが肥大化する」「ノイズが多い」というデメリットがあります。
ノイズが含まれる例として、以下のようなものがあります。

これでは、本来の文脈では含まれない京都という単語も共起状態になってしまいます。
このように、辞書を使用しないN-gramでは、単語のかたまりを考慮した分かち書きはできません。
日本語を処理する際にはこうしたノイズに注意しなければいけません。
N-gramとMecabの併用
この問題に対し、Googleが日本語でN-gramデータを作成した際は、MeCabによる形態素解析と組み合わされました。参照:Google Japan Blog
実際の案件で、文字数で機械的に切る方法と、形態素にしてからBoWを作成する方法とでは、以下のように精度に大幅な差が見られました。
| 1-gram | 2-gram | 3-gram | 1,2-gram | 2,3-gram | 1,3-gram | |
|---|---|---|---|---|---|---|
| 文字 | 32% | 25% | 19% | 32% | 25% | 32% |
| 形態素 | 62% | 56% | 47% | 63% | 57% | 63% |
辞書に依存しないメリットは失われてしまいますが、英語のようにBoWの共起状態を見るためには、形態素解析を用いるのが現実的でしょう。
TF-IDF
そして、分かち書きした単語をベクトル化します。
分かち書きしてTF-IDFでベクトル化するというのは、もはや1の次は2というくらい当たり前の話になっている気がするのですが、
そもそもなぜ分散表現を使うのかについては、One-hot表現を知っているとより理解できると思います。
One-hot表現
One-hot表現とは「ある要素のみが1でその他の要素が0」であるような表現方法のことです。
出現単語の数だけ次元を用意し、該当の単語があれば1を入れていきます。
たとえば、'The mouse ran up the clock' と 'The mouse ran down'という2つのテキストがあったとします。この2つのテキストをOne-hotで表すと以下の表のようになります。
| the | mouse | ran | up | down | clock | |
|---|---|---|---|---|---|---|
| The mouse ran up the clock | 1 | 1 | 1 | 1 | 0 | 1 |
| The mouse ran down | 1 | 1 | 1 | 0 | 1 | 0 |
しかし、One-hot表現には、テキスト分類で重要な類似度の計算において、重大な欠陥があります。
単語間で類似度を計算するために、内積を取るとしましょう。
すると、異なる単語は別の箇所に1が立っていてその他の要素は0なので、内積を取った結果は0になってしまいます。
これでは、異なる単語間の類似度を表すことはできません。
また、1単語に1次元を割り当てるので、単語数が増えると非常に高次元になってしまいます。
次元数は機械学習において重要ですので、その点でもOne-hot表現は使いにくいわけです。
分散表現で類似度を表す
さて、One-hotで0,1の表現にしたままでは具合が悪いことがわかりました。
それでは、ここから類似度の計算がしやすい実数値にしていきます。
そこで使えるのが、分散表現です。
TF-IDFは、テキストにおける単語の特徴量を表す方法です。
tf = 文書Aにおける単語Xの出現頻度 / 文書Aにおける全単語の出現頻度の和
idf = log( 全文書数 / 単語Xを含む文書数 )
つまり、
tfidf = (単語の出現頻度) ∗ (各単語のレア度)
これで各テキストに対する単語の特徴量が求められ、特徴量によって単語同士の類似度を表せるようになります。
先ほどの例で、uni-gramとbi-gramのbowを作成しました。そのTF-IDFを計算すると以下のようになります。
これで特徴量を実数で表すことができました。
| the | the clock | the mouse | mouse | mouse ran | ran | ran down | ran up | up | up the | clock | down | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| The mouse ran up the clock | 0.47 | 0.33 | 0.23 | 0.23 | 0.23 | 0.23 | 0 | 0.33 | 0.33 | 0.33 | 0.33 | 0 |
本当はTF-IDFって使いづらい?
ところが、実際の案件ではTF-IDFでは処理が重すぎたたため、類似度ではなく単に単語の出現回数を算出するCountVectorizerを使いました。
TF-IDFを使うときになにが問題だったのでしょう。
まず計算処理ですが、サンプル数が多いほど類似度の計算には時間がかかることになります。
自然言語分野では語彙のサンプル数がものを言うので、悩ましいところです。やはりマシンスペックは必要ですね。
また、今回は似通ったトピックが集まっているデータだったので、TF-IDFの力があまり期待できませんでした。
TF-IDFは、ニュースサイトなどのトピックがばらけているデータに対して使ったほうが効果が期待できるかもしれません。
特徴選択
精度のために特徴量を減らす
さて、語彙に対して特徴量を付けたところで、次元数を2万まで削減します(ここでは単語数=次元数です)
高次元のデータでは、次元数を減らすことで精度が上がることが知られています。
その理由が次元の呪いです。
次元の呪いとは、「次元数の増加に伴い、任意の点からの最近傍点と最遠傍点との差が0に近づく現象」です。
参照:球面集中現象 - 具体例で学ぶ数学
これをテキスト分類の話に当てはめると、
テキスト内の単語数が多ければ多いほど、各単語のテキストに対する特徴は失われる
ということになります。
なので、一定以上の特徴量を持つものだけに限定しないと、精度が上がりません。
このように、特徴選択は精度の向上につながる重要な作業なのです。
説明変数と目的変数の関係性にもとづいて選択する
特徴選択で次元数を減らすことの意義について説明したところで、次はその方法について説明していきます。
特徴選択の手法は大きく分けて2つ。
機械学習の手法とは関係なく、機械的に特徴量の上位を選択するFilter Methodと、
実際に学習させてみてパフォーマンスの良い特徴を選択するWrapper Methodです。
お察しの通りWrapper Methodは計算量が膨大になるので、ここではFilter Methodを取り上げます。
Filter Methodにおいては、説明変数と目的変数の関係性から特徴量のランキングをつけます。
主に使われるのが下の2つ。
-
ANOVA
sklearn.feature_selection.SelectKBestでデフォルトになっているのが、分散分析(ANOVA)です。
分散分析は、「選択肢を変えると予測値が有意に変わるか」を分析するものです。
説明変数: カテゴリー
目的変数: 連続 -
カイ二乗
カイ二乗検定は、検定統計量が(近似的に)カイ二乗分布に従うような仮説検定手法で、二つの変数に関連が言えるのか否かを判断するための「独立性の検定」の1つです。
説明変数: カテゴリー
目的変数: カテゴリー
特徴量をいくつにするか
Googleのドキュメントでは、特徴量を2万にする根拠として以下の結果が示されています。

多くのデータセットでは、2万以上に設定しても精度は横ばいになるから、2万でいいと。
なお、お気づきの通り、実際は2万のかなり手前で精度はピークに達しています。
それに、2万の次元数でTF-IDFを計算するなら相応のマシンスペックが要求されます。
なので、特徴量は実際に学習を回して、精度を見ながら決めていくのがいいと思います。
先ほど説明した通り、高次元なら精度が上がるというわけでもないので、次元数が少なくて精度が高いならそれに越したことはないです。
最後に、BoWと前処理の威力
そして特徴選択を行うと、次はモデル構築となります。
MLP構築は使うフレームワークにより異なりますので、ここでは言及しません。
最後に、BoWを作るときの前処理で効果的だったものを紹介します。
-
品詞を限定する
副詞、名詞(なかでも数字や人名)は、テキストの特徴にならないことが多いので、除外すると効果的です。 -
動詞は原形に直す
「来る」「来た」のように、動詞の活用形によってばらけるのを避けます -
ストップワードを除く
「あそこ、いくら」などの語彙もテキストの特徴にならないことが多いです。 -
頻度の高すぎる語彙を除く
頻度が高すぎる語彙は、文章全体におしなべてあるということですから、各テキストの特徴をより見つけやすくするためには除外したほうがいいです。
自然言語の前処理で重要なこと
お読みいただいた中で、次元数と特徴量というのが頻繁に出てきたと思います。
自然言語は高次元データが多くなりがちなので、この次元数を適切にできるかが学習の質に関わるためです。
精度を上げるためには次元数の他にも、BoWの質にも気をつける必要があります。
いかに価値のある語彙を抽出できるか、それを適切な次元数にすることができるか、これらが自然言語を学習させるときに重要なことです。
実際に私はモデル構築の調整をしていたけれど上がらず、前処理を見直したら精度が一気に向上したこともありました。
この経験をもとに、前処理の重要ポイントを、ナレッジに今までの所見を交えて紹介いたしました。
最後までお読みいただきありがとうございました。
参考
Google Machine Learning Guides - Text Classification
Modeling Natural Language with N-Gram Models
第6回 N-gramと形態素解析との比較:検索エンジンを作る|gihyo.jp
Google Japan Blog - 大規模日本語 n-gram データの公開
カテゴリカル変数のEncoding手法のまとめ | かれぶろ
なぜ自然言語処理にとって単語の分散表現は重要なのか?
sklearn.feature_selection.SelectKBest
変数選択(Feature Selection)手法のまとめ