初めに
機械学習の基礎である「回帰」アルゴリズムを用いて、不動産の賃貸価格を予測するプロセスを解説します。データの読み込みから予測まで、実務で使えるステップ順に学んでいきましょう。
Step1. データの観察
まずは学習用データとなる realestate_train.csv を読み込み、中身を確認します。
今回の目的(ターゲット変数)は rent_price(賃貸価格) の予測です。
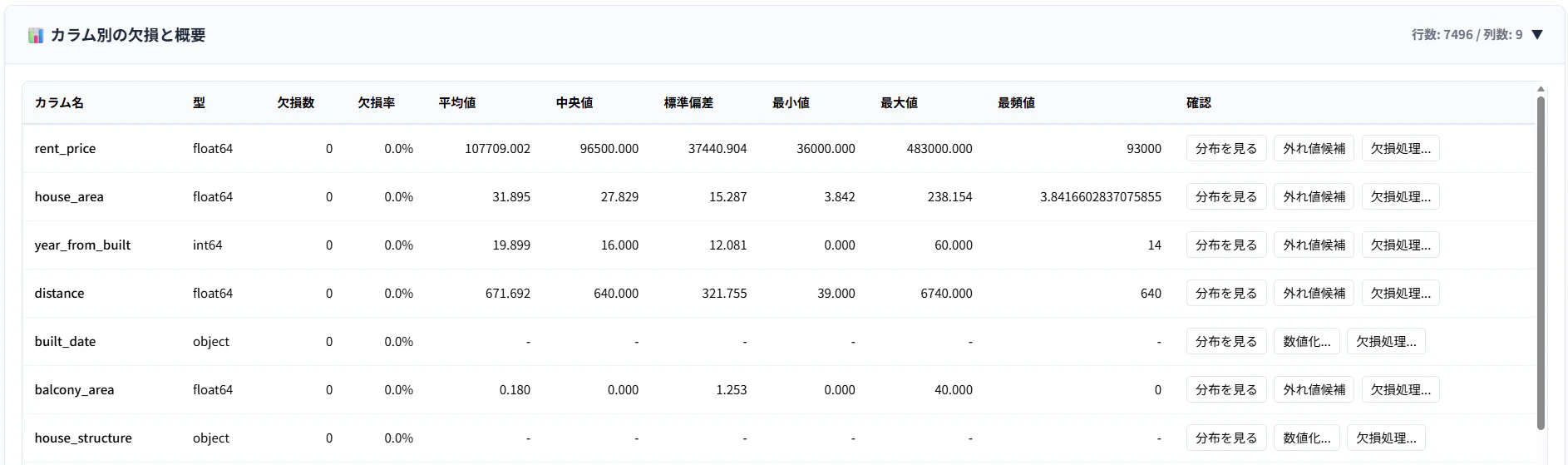


データセットには価格以外にも、広さや築年数など様々な情報が含まれています。
Step2. 特徴量エンジニアリング
予測のヒントとなる「特徴量」を選定します。今回はシンプルかつ影響度の高い以下の2つを使用します。
- house_area:広さ(m2)
- distance:駅からの距離(m)

Step3. アルゴリズムの選定と訓練
今回は Ridge Regression(リッジ回帰) を使用します。
リッジ回帰は、線形回帰に「過学習(学習データに過剰に適合しすぎること)」を抑える仕組みを加えたアルゴリズムです。

モデルを定義したら、訓練データを用いて学習を実行します。

Step4. 機械学習モデルの評価
作成したモデルがどの程度の精度を持っているか確認します。
今回は評価指標として MAE(Mean Absolute Error, 平均絶対値誤差) を採用します。
MAEとは?
予測値と実際の値の差(誤差)の絶対値を平均したものです。「平均して何円くらいのズレがあるか」を直感的に把握できる指標です。

Step5. 機械学習モデルを使った予測
いよいよ学習済みモデルを使って新しい物件の価格を予測します。
注意点として、学習時と同じ順番・同じ種類の特徴量をモデルに渡す必要があります。

まとめ
おめでとうございます!これで無事に新しい物件の賃貸価格を予測することができました。
機械学習の流れ(データの観察 → 特徴量選定 → 学習 → 評価 → 予測)は、どんなに複雑なモデルでも基本は同じです。今回のステップをベースに、他の特徴量を加えたりアルゴリズムを変更したりして、さらに精度を高めてみてください。
次にやってみること:
- 築年数(house_age)を特徴量に加えて精度が上がるか試してみる
- Ridge以外のアルゴリズム(LassoやRandomForestなど)を試してみる