Clouderaの「CCA Spark and Hadoop Developer Exam (CCA175)」に合格しましましたので、勉強方法を共有したいと思います。
学習期間はhadoop・spark関連の技術の学習を含めると1.5ヶ月ほど、純粋に試験準備のみでは約2週間です。
英語のみの試験ということもあり、環境設定や学習方法、実際の試験の際に必要なことなど、本記事執筆時点では日本語で参考になる情報が知る限り全くありませんでしたので、今後hadoop関連技術・sparkを学習したい方に参考にしていただければと思い書きました。
■目次
1.試験CCA175について
2.私の受験前の情報と受験の動機
3.レンタルオフィスは必要?
4.試験前と試験中の注意事項
5.英語が喋れる必要ある?
6.Udemy講座の受講と模擬試験
7.学習の進め方と環境設定について
8.hadoop ecosystemの関連学習
9.試験テクニック・直前対策的なところ
10.サンプルコード紹介
最後に
試験について
CCA175は、hadoop関連システムの主要なディストリビューターの一つであるClouderaが提供するhadoop・spark開発者向け資格です。hadoop関連のクラウドサービスではAWSのAmazon EMR、GCPのDataprocが知られています。

CCA175は主にsparkを使ったHDFSデータの読み込み・データ変換・加工・データ格納や、sparkSQL・hiveによるSQL分析の能力を問うもので、hadoop関連技術の知識やデータアーキテクチャのコンサル能力を問うものではないため、この点はあわせて関連知識の学習をすることをおすすめします(後で紹介します)。
CCA175基本情報
- 言語:英語のみ
- 試験時間:120分
- 合格水準:70%以上で合格
- 価格:295USドル(日本円で約3万円)
試験はこちらから購入・申込できます。
https://www.cloudera.com/about/training/certification/cca-spark.html
購入後、別途案内されるPSIオンラインテストサイトで試験のスケジュール設定・受験を行います
※日本のクレジットカードで問題なく決済可能です(決済はクレジットカードのみ)。私の場合はPC版ではキャッシュの問題か、うまくいかなかったためスマホで試したところ購入できました。
再受験ポリシー・FAQ・合格通知
FAQはこちら
https://www.cloudera.com/about/training/certification/faq.html
-
再受験は何度でも可能ですが、30日の期間を空ける必要があります
-
合格通知はUSビジネスデイで3日ほどのようです。私の場合は土曜夕方受験、火曜早朝に連絡が来ました。
-
1週間ほどでデジタル証明書が発行されます
※添付があるため迷惑フォルダに入ってる場合もあります。なかなか来ないときは迷惑フォルダ内を確認してください。
補足
・テストセンターは提供されておらず、個人のPCからPSI経由でClouderaのリモート環境にアクセスして受験します。問題文はブラウザ上に表示され、リモートデスクトップ上のターミナルを起動してそこでspark-shellで起動し、HDFSやhive metastoreに格納されているデータを使って試験の要件どおりデータ処理を行うというものです。
-
試験は全9問で、処理したデータを指定した形式でHDFSやhive metastoreに格納した結果で評価されます。部分採点もあると思いますが、私の場合は7問正解でpass(合格)でした。問題ごとに点数が違う可能性もありはっきりとはいえませんが6問正解だと66.7%のため不合格となると思われ、不正解は2問までと思った方がいいです。
-
2時間程度ですがリモート環境のためやや重たく、またクラスター処理の待ち時間などもあり1問10分程度の持ち時間は相当短く感じると思います。1~2分で終わるものと時間のかかるものとばらばらだったりします。
必要なもの・準備物
- 顔写真付き身分証明書1点(運転免許証でOK)
- マイク・カメラ付きPC
- 周囲に人のいない部屋・試験用の机
- 問題文を理解するレベルの英語読解力
- 試験監督官(モニタースタッフ)とのチャットができる簡易な英語力
難易度(所感)
内容自体は平易で範囲もspark、hive、sparkSQLのみのため広くなく簡単に見えると思いますが、短い時間で慣れないリモート環境で素早く対応する必要があり、選択式ではなく実際にデータ加工をするためコマンドは完ぺきに暗記しておく必要もあり、実際にやった感覚としてはやや高めの難易度という印象でした。焦らずに対応できれば、難しい部類ではありません。
私の受験前の情報と受験の動機
ビッグデータ分析スキルとして、RDBMS・DWH及びAWS/GCPクラウド関連の基本的な知識に加えて大規模分散処理技術で知られるNoSQLのhadoop関連技術を身に付けあわせて客観的な能力証明もしておきたいと思い受験しました。
過去にシステム開発経験はありますが、NoSQL・hadoop・spark関連技術の実務経験は特にありませんでした。受験資格の必要要件もないため、実務経験なくても試験自体は特に問題ありません。
レンタルオフィスは必要か
私の場合は自宅で受験しました。試験監督官にチャットで、カメラ付きPCを持ち上げて360度映すよう指示されますが、割と周りに本やらなにやらある状態でしたが、周囲に人さえいなければ問題ないようです。
気になる人はレンタルオフィスを使用するのがいいと思いますが、費用も掛かるため自宅でも十分と思います。
受験用のデスク周りは、PCマウス以外のものは(スマホや各種電子機器等)一切ない状態にしておく必要があります。
試験前と試験中の注意事項
-
直前に暗記しようかと思いましたが準備に手間取り意外と時間かかりました。15分前には試験サイトに進んで、試験開始定刻から15分後スタートがリミットなのでそこまでには終わるように早めに準備することをおすすめします
-
離席もできないため事前にトイレ・水分補給は必須です
-
おそらくイアピースで不正受験するのを防ぐ目的で、問題文を読み上げること・口元を隠すことが禁止されています。考えてるときに手を口元に持っていくとチャットで注意されます(すぐやめればOK)
不正を疑われるのを防ぐため、目線も画面から外さない方がいいです。考える時に上見たりするくらいでは何も言われませんでしたが一応
英語力について
問題文の読解、試験監督官のチャットの読み取りは当然できる必要がありますが、会話力は不要です。読んでわかったらチャットでokとかyesとか返しておけばいいです。
- ここのボタンをおしてカメラオンにしてください
- 身分証明書をカメラに映してください
- 部屋とデスク周りを映してください
- 準備ができたら試験開始してください
言われるのはこのくらいです
オンライン講座と模擬試験
下記2つのUdemy講座の模擬試験の練習課題を何も見ずにコマンドを正確に書けるようになれば問題なく合格できると思います。そのうち1つには説明動画もついているので見てください。
価格は合計5,500円ほどです。Udemyは定期的に90%オフセールとかをやるので、間違っても2~3万円で買ったりしないようにしてください
①CCA 175 -Spark Developer Exam Preparation + Practice Tests by Navdeep Kaur
https://www.udemy.com/course/complete-cca-175-hadoop-spark-developer-with-practice-test/
②CCA 175 Spark Developer Practice Tests by Navdeep Kaur
https://www.udemy.com/course/cca175-hadoop-spark-developer-practice-test/

-
ネイティブではないため聴き取りづらく、字幕も不正確ですが画面上の資料を見れば内容理解とコマンドの確認する上では問題なく分かると思います。1.5倍速くらいにするのをおすすめします
-
CCA175は試験の形態が変わっており、以前はflume等含まれていたところ除外され、spark中心になっています。上記講座は本記事執筆時点では唯一きちんと最新の試験範囲に更新している講座のようです。
類似のものは一部古い前提で、追加で取り組みたいときや試験範囲外でも学習しておきたいときに利用するのがいいと思います
講座の内容紹介
- GCP上での環境設定
- sparkとは、RDD、DAG
- fileterやjoinなど基本的なデータ加工方法
- データフレームについて、jsonやavroなどデータフォーマット変換
- sparkSQL(Windows関数含む)
- ①模擬試験2題+②模擬試験3題
※模擬試験は8問ずつですが、実際の試験は9問構成でした。難易度的には本試験の方がシンプルで易しめでした
※scala自体はしっかり学習しようと思うと別の書籍等でかなりの時間必要ですが、本試験で必要なspark scalaの理解程度であれば本講座で紹介されているレベルで十分です
学習の進め方と環境設定
一定以上のハイスペックPCを持っているなら、本試験と同じclouderaVMを使ってローカルPCで試すのが一番いいと思いますが、クラウド環境でのspark処理構築の学習にもなるためGCPを使った方法をおすすめします。
この方法は上記Udemy講座で詳細に説明されているので(コマンドも添付されている)、そのとおりやれば問題なくできます。
GCPについて(クラスター環境設定)
- アカウント作成・クレジットカード登録が必要です
- 費用は、私の場合は3,000円弱かかりました。クラスタを稼働させていると費用が掛かるため、終わったらクラスタを毎回忘れずに削除し、翌日にはお支払い(Billing)で請求金額を確認しておきましょう
・Udemy講座ではテストデータをsqoopで登録する方法も案内されていますが、上手くできなかったので手動でcsv等を作成しました。avro, json等はformat(“avro”)、format(“json”)などその辺共通のやり方を覚えればいいだけなのでデータはできなくても問題ないと思います
学習環境(GCP利用例)
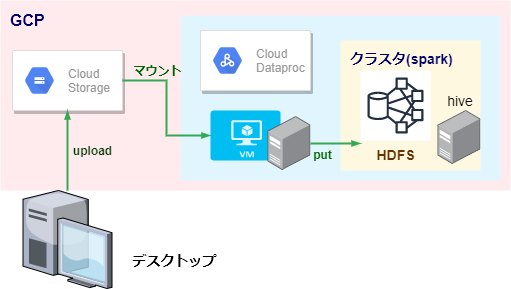
-
Cloud Dataprocでクラスターを作成し、**Virtual Machine(VMインスタンス)**のSSHでターミナル起動→spark-shellコマンドでspark起動、という流れです
-
クラスターを削除するとデータも消えるため、図の通りデータはデスクトップに作成し、Cloud Storageにファイルアプロードし、Cloud StorageとCloud DataprocのVM(virtual machine)のローカルフォルダをGCSFUSEでマウントし、VMローカルフォルダからHDFSの指定フォルダにPUT(hdfs dfs -putコマンド)することでデータ準備ができます。この辺の手順も講座の説明通りやれば問題なくできます。
一部紹介すると下記
// GCSFUSEインストール(コマンドは一部のみ抜粋)
export GCSFUSE_REPO=gcsfuse-lsb_release -c -s
// VMローカルにGoogle Storageマウントポイント用フォルダ作成
mkdir ~/spark-dataset
// GCP画面上で、Cloud Storageにデータアップロード用フォルダ作成 spark-dataframe
// Cloud StorageとVMローカルフォルダをマウント
gcsfuse spark-dataframe ~/spark-dataset
// VMローカルのフォルダにCloud Storageのフォルダ内容が表示されることを確認
cd ./spark-dataset
ls
// hdfsに作業用フォルダ作成
hdfs dfs -mkdir /user/testdata
// VMローカルフォルダ(Cloud Storageとマウント済み)の配下データ全部をhdfs作業フォルダにコピー(put)
hdfs dfs -put ~/spark-dataset/* /user/testdata
// hdfsのファイル確認(正しくデータが準備されていること)
hdfs dfs -ls /user/testdata
avroについて
avro環境は外部パッケージのimportが必要ですが、私の場合上手くいきませんでした。本試験環境ではすでにセットアップされているため意識する必要はありませんが、方法が分かる人がいれば教えてもらいたいです
学習する上ではformat(“json”)がformat(“avro”)になるくらいの違いしかないため特に問題なしです(avroになぜ変換するのか、効率的なのかなどその辺は自分で調べて理解しておいた方がいいですが)
おすすめの勉強法
-
最初は模擬試験の回答もはじめから全部見て、全問でなくてもいいので一部は自分でコマンドを打ち込んでデータ操作できる感覚を掴む
-
回答のコマンドはすべて1度は打ち込んで手で覚える(データは無しでもいいのでキーボード叩いて覚える)
-
新しい情報がでてくるたびにポイントを取り出して分類し、githubに.mdファイルで自分なりの辞書を作る
例)
case class
join
filter
hive
write format
など
→ 知識の定着になるほか、ヘッダ付きcsvのloadをしたいときはこのページを見ればわかる、という風に後から実務でも使えるものが残ると思います
関連知識の学習
CCA175はspark・sparkSQLのデータエンジニアリングスキルがメインのため、hadoop関連技術知識を得るには、あわせて別で学習する必要があります。以下をおすすめとして紹介します
The Ultimate Hands-On Hadoop – Tame your Big Data!
https://www.udemy.com/course/the-ultimate-hands-on-hadoop-tame-your-big-data/

元Amazonのシニアエンジニアということです。ビッグデータ処理や機械学習に詳しく、多数の講座を配信しています。内容も信頼性があります
特に7.Overview of the Hadoop Ecosystemだけでも見ておいた方がいいです
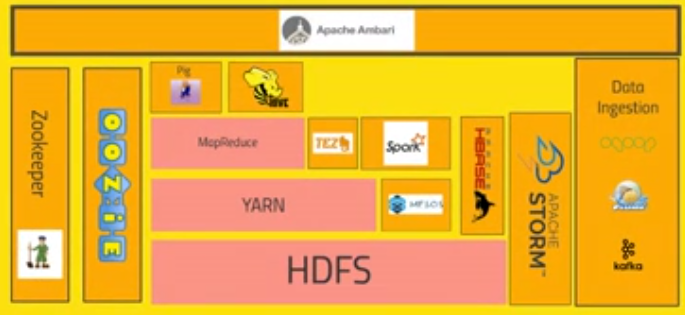
この辺のビッグデータバズワードについて、違いなど用語の理解ができるようになると思います
Apache Ambari、YARN、MESOS、HBASE
MapReduce、TEZ、Spark、Pigs、Hive
HBASE、Apache Storm、
Oozie、Zookeeper、sqoop、flume、kafka
mongoDB、cassandra、MySQL
Apache Drill、HIVE、Apache Phoenix、
Presto、Apache Zeppelin
試験のテクニックや直前対策的なところ
本試験は、PSIオンラインテストサイトからブラウザで画面共有をして、リモートでClouderaのバーチャルデスクトップにアクセスして受講します。
下図のようなイメージです。
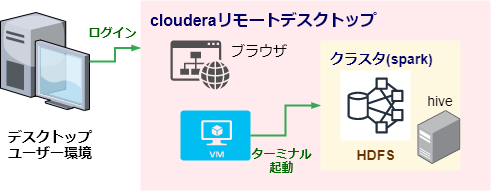
まず落ち着くために【事前準備編】
不正防止の監視のため、こちらの目線やマウスストロークはモニターされます。その副作用と思いますが、常に謎の電波音がうわんうわん・・・と延々と鳴り続け、こちらの操作に合わせて音が鳴ります。
これが一人で部屋で受験しているとかなりの精神電波攻撃になるので、これは事前にそういうのがあると知っておくだけで落ち着けると思います(音下げるなり対策を)
ブラウザは試験画面だけにする必要があるため、事前にブラウザの他のタブは全て閉じて、ブックマークバーも決して全画面表示にする用意をしておきましょう。タスクバーも隠せるよう設定を変えておきましょう
まず落ち着くために【試験開始後編】
- リモート環境のため重たい水中環境ですが、問題文表示のブラウザを右に寄せる
- ターミナルを起動し、ウィンドウサイズを調整して左に寄せる。(問題文とターミナルを横に並べて見れるように)
- とりあえず1問やれば落ち着くので、まずは下記を打ち込んで操作できる自信を掴むことが大事です。感覚を掴めば、課題自体はシンプルなので後はどんどん進むと思います
// 起動
spark-shell
// 以下、scalaプロンプト(パスは問題文記載の入力データ用パス)
// とりあえずざっくりロード
val datadf = spark.read.textFile("/aaaaa/bbbb/xxxfile")
// 中身を見る(タブ区切りなら1列に出てくる)
datadf.show(5)
datadf.printSchema()
※注意:3,000万件のデータです、など大規模データであることの注釈の入っている場合は時間がかかるので避けてください。1問目はその可能性はかなり低いですが
hadoop fs(hdfs dfs)コマンドが使えない?
私の場合なぜか本試験環境ではhadoop fs、hdfs dfsコマンドが使えず、
catコマンドでデータ状況確認しようかなと思っていましたができずに焦りました。なんとかなりましたが、もしやり方分かる人がいたら教えてください。試験だけの特殊な状況かもしれませんが
試験を受けた所感(模擬試験との違い)
模擬試験の練習版では意識してなかった点が若干ありましたので以下に記載しておきます。
- 大規模データ(3,000万件ほど)を処理するケース
途中で変数に格納せず、loadからwriteまで一気通貫でやると処理時間も高速になります。
変数に入れると確実ですが、大きいデータの場合その分時間がかかるので
// 変数に入れるパターン(dataDF経由)
val dataDF = spark.read.option("sep","\t").csv("/user/xxx/inputfile").
select($"_c0",$"_c1")
dataDF.map(x => x.mkString("|").
write.format("text").save("/user/output")
// 変数に入れずに処理するパターン(loadしてそのままwrite)
spark.read.option("sep","\t").csv("/user/xxx/inputfile").
select($"_c0",$"_c1").map(x => x.mkString("|").
write.format("text").save("/user/output")
- 見たことない圧縮形式・ファイル形式
模擬試験ではあんまり出てこなかった、orcファイル形式、snappy compression形式が頻繁に問われました。ただ、option(“compression”,”gzip”)の“gzip”を”snappy”に変えるだけとかなので、特に焦る必要はありません
直前に暗記復習したほうがいいもの
基本的な操作を理解していても、細かいところは直前に暗記しておかないと出てこないものもあるので、私は下記をやりました。実際には全然問題に出てこなかったので、それは一応括弧で補足しています
sequence (出なかった)
xml (出なかった)
hive, partition(partitionは出なかった)
dense_rank(出なかった)
arg sum(出なかった)
unixtime変換(出なかった)
chmod(出なかった)
**全然でてない。**hive、meta store tableの読み書きはしっかりやった方がいいです
ただ、hiveテーブルのcreate(defaultではなく、個別データベース配下)が練習ではできていたのに本試験ではまったくうまくいきませんでした(不正解の2問のうち1つがこれで、もう一つがjoin)
最新版のUdemy講座を参照すれば、上手くできるように反映されているかもしれません。
spark-shellコマンドのポイント
データ操作には複数の方法があり、全てできるに越したことはないですが、1つだけ確実にできていればなんとかなるので、まずはそこを確実におさえることからやる方がいいです。
-
case classでschema定義しておく→データフレームやsparkSQL操作ができるので
※inferSchemaの方法もおさえておいた方がいい -
模擬試験の回答とは違い、一つデータ加工するごとに val datadfxx = xxxxと変数に格納して datadfxx.show(5)などで確認しつつ確実に進める方がいいです。ミスも減らせるので。ただし、数千万件のデータ、と注意が入っているときは避ける必要があります。試験時間が無くなるので
-
問題「jsonファイルで格納してください。ファイルは圧縮しておいてください」は、圧縮してからjsonで保存するという順番で加工することに注意してください
// 方法①
dataFile.select("aaa","aaaa").write.option("compression","gzip").
json("/user/output")
// 方法②
dataFile.write.mode("overwrite").option("compression","gzip").
format("json").save("/user/output")
- joinのデフォルトがInner Joinであることを理解。joinはほぼ確実に問われます
※join left-antiも使える方がいいです
例
◆①user_id
A
B
C
◆②order_id,user_id
1,A
2,A
3,A
4,C
// ①+②join結果
①.join(②,"user_id")
結果:
1
3
※Inner Joinがデフォルトのため、②に存在するA・Bだけが残ります
※出力単位も、左テーブルの①のuser_idユニークでデータが残ることに注意 joinは、結合keyが同じパターンと名称が違うパターンがあり、それぞれ書き方を知っておくのと、カラムをどんどん増やしていく方法あたりをしっかり理解しておくことをおすすめします
サンプルコード紹介
最後に、CCA175で取り組む課題は例えばこんな感じ、というのをいくつか紹介して終わりとしたいと思います。
▼要件1
- avroファイルをgzip圧縮してparquet形式で格納してください
- 出力ファイルはfname,state列だけにしてください
val datadf = spark.read.format("avro").load("/user/avrofile")
datadf.select("fname","state").write.option("compression","gzip").parquet("/user/output")
▼要件2
- パイプ区切りテキストファイルをgzip圧縮されたparquet形式で「customer_m」という名前でmeta storeに書き込みしてください
- fname(名前)にMを含む行だけにして、stateごとのユーザー件数をカウントしてください
spark.read.option("sep","|").csv("/user/tab").
select(col("_c1").as("fname"),col("_c2").as("state").
where("fname like '%M%'").
groupBy("state").count.
write.mode("overwrite").option("compression","gzip").
option("fileFormat","parquet").
format("hive").saveAsTable("customer_m")
▼要件3
- HDFS(/user/infile)にあるparquet形式のファイルから、2020年3月のpending中の注文数を日別にカウントしてjson形式でHDFS(/user/output)に格納してください
- 注文日はunixタイム形式です
spark.read.format("parquet").load("/user/infile").
withColumn("order_date",to_date(from_unixtime($"order_date"/1000))).
filter("order_date LIKE '2020-03%' and order_status='PENDING'").
groupBy($"order_date").count.write.mode("overwrite").
format("json").save("/user/output")
▼要件4
- case classを使用してspark.sqlでデータ処理する例
- プロダクトid別の注文数トップ10を集計
// 1.case classでスキーマ定義
case class Products(pId:Integer,name:String)
case class Orders(prodId:Integer,order_total:Float)
// 2.カンマ区切りcsvファイルを定義したスキーマで格納。
// floatなどデータ形式もここで変換
val prodDF = spark.read.textFile("/user/testdata/xxxx/").
map(x => x.split(",")).map(c => Products(c(0).toInt,c(2)))
val ordDF = spark.read.textFile("/user/testdata/xxxx/").
map(x => x.split(",")).map(c => Orders(o(0).toInt,o(4).toFloat))
// 3.テーブルをjoinし、meta storeに一時テーブルを作成し、spark.sqlでパイプ区切りデータを作成
ordDF.join(prodDF,ordDF("prodId")===prodDF("pId")).
createOrReplaceTempView("joined")
val filtDF = spark.sql("select concat(prodId,'|',sum(order_total))
from joined group by prodId order by sum(order_total) desc limit 10")
// 4.textファイル形式でHDFSに書き込み
filtDF.write.mode("overwrite").format("text").save("/user/output")
最後に
日本人のエンジニアでCCA175を受験したい人はどれくらいいるんでしょうか?
日本語の情報がなくてもろもろハードルがあり挑戦する人が少ないのではと思っていますが、今後CCA175を受験してSpark・hadoopを学習したい方、開発能力を証明したい方にとって本記事が参考になれば幸いです。