Outline
本コンテンツは、これからテスト自動化を始める人向けに作成するコンテンツ。
筆者のこれまでの経験を元に作成しているので、教科書と異なる場合があります。
今回は、テスト自動化の実装にあたって、どのようにプログラムを組むとよいかの設計に関することを記載する。
尚、開発言語に依存しないレイヤーである、概念について記述する。
前回に引き続き、テスト自動化設計に関して執筆する
Test automation design view point
1.Data driven
2.Data normalization
3.Keyword driven
4.Robust & Sensitive
5.Scenario independency
6.Scenario size
7.Setup & Teardown
8.Analyzable report
9.Repeatability
10.Break flaky
11.Flexible trap
3.Keyword driven
キーワード駆動の定義は、Syllabusの中で以下のように定義されている
The keyword-driven scripting technique builds on the data-driven scripting technique.
There are two main differences:
(1) the data files are now called ‘test definition’ files or something similar (e.g.,
action word files);
(2) there is only one control script.
from Advanced Level Syllabus – Test Automation Engineer
正直、わからないw。
端的にいうと、キーワード駆動とは、readableなscriptingである。
細かい(プログラムレベル)操作をキーワードで隠蔽し、利用者はそのキーワードを組み立てることで自動化のスクリプトを編集できるようにする。
抽象化するレベルも、どのように運用するかで決める必要がある
Low Levelのキーワード駆動


利用者は、実際のプログラム(Java等)の処理をしらなくても、"Set Value"等のキーワードを記述することで、自動化の処理を記述することができる。
抽象度がHigh Levelのキーワード駆動

すこし極端な例かもしれませんが、ログイン、購入処理等といった機能レベルをキーワードとして処理を隠蔽化して、利用者側は自動化の処理を簡単に記述することができる。
4. Robust & Sensitive
テスト自動化で、どのレベルまでvalidation処理を加えるかの程度を考えるものである。
Robust
- 限られたポイントをチェックする
- テスト自動化のscripting工数は抑えられる
- 少しのUI変更が生じても、テスト自動化は失敗しない
- 失敗時の原因分析に時間がかかることがある
- False Negative になりうる
- テストの実行時間は短い
Robust Validation Example
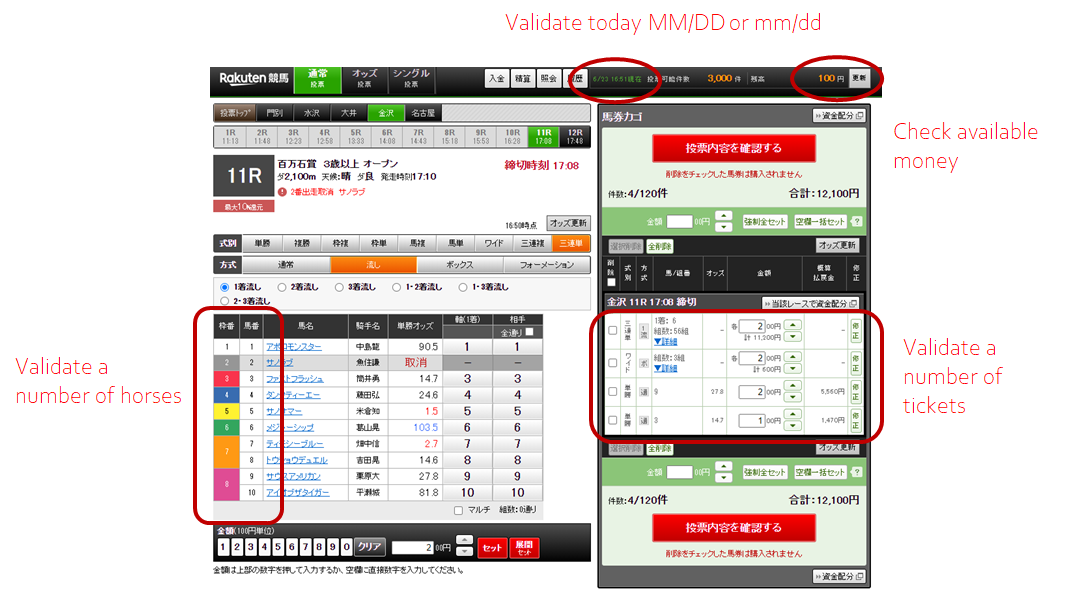
Sensitive
- 数多くのポイントをチェックする
- データのフォーマット等(例 日付は0埋めMM/DD形式)、細かいレベルのチェックする
- テスト自動化のscripting工数が大きくなる
- 変化に対してテスト自動化の影響が受けやすく、修正が発生しやすい
- テストの実行時間が長くなる
Sensitive Validation Example

テスト自動化の目的に応じて、このRobust & Sensitiveの感度を決める必要がある。
主要な処理ステップが正しく動くことを常に確認したい場合、Robustにしたほうが良い。
あまりプロダクトの変更がなく、UI含めて常に厳しいチェックを行いたいのであれば、Sensitiveにしたほうが良い。
5.Scenario independency
1つのテスト自動化の実行単位をシナリオと定義する。
このシナリオは、単体で実行可能(独立性)であることが望ましい。
事前シナリオの実行前提を意識せずにテストを実行できるためである。
テスト自動化のシナリオが多くなれば、この依存性が大きいと実行順序をドキュメント化する等の運用に大きな障害が出てくる。
ただ、独立性を意識しすぎて、一つ一つのシナリオが肥大化するのも、テスト実行時間が長くなり、また同じテストを複数のシナリオで重複して実施することになるため、バランスが求められる。
例えば、Eコマースを例にする。
ユーザーはログインを行い、欲しい商品を選択し、かごの中に入れる。
最後に精算処理を行い、購入完了するプロダクトを考える。
一つ目の例は以下の図の通りである。
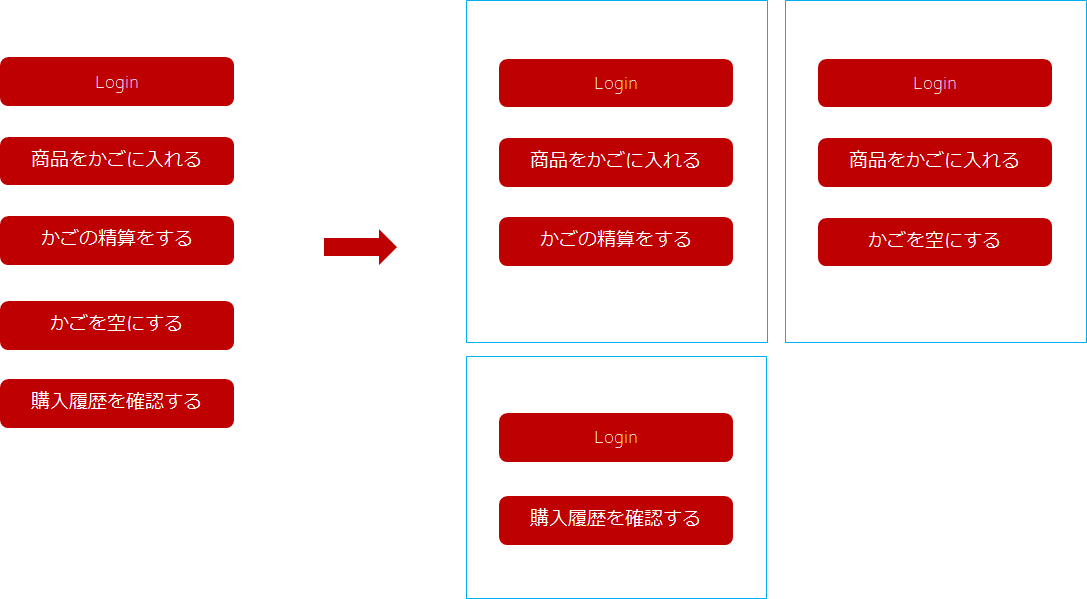
左側に各機能単位のテストがある。
機能単位で、最小限のテストを行う場合、左側のテストシナリオが良いかもしれません。
ただ、かごに入れる、かごを精算するというシナリオは、一連の手順に行われる必要があり(依存)右のように3つのシナリオにしたほうが良い。
ログインや商品をかごに入れる処理は、複数のシナリオで重複して行われますが、それぞれのシナリオは前提処理を気にせずに実行できるため、利用上の負荷はなくなる。
もう一つの例を示す。
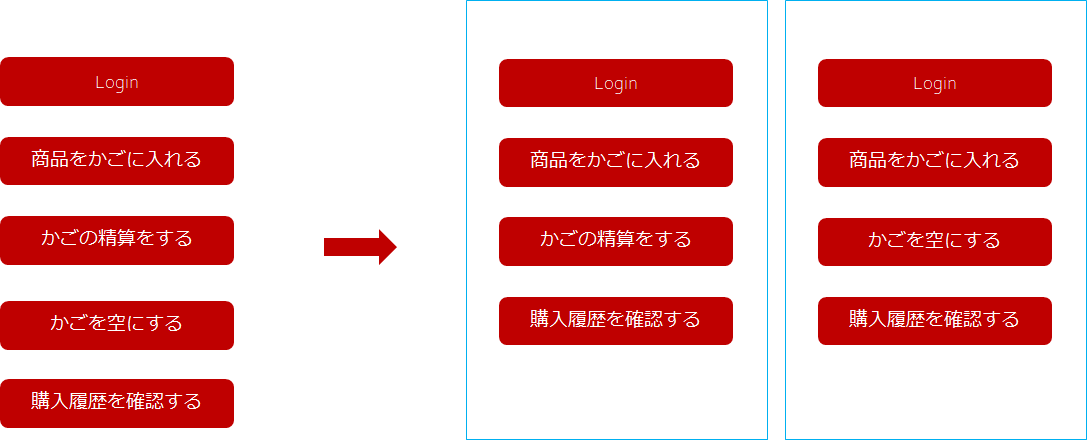
この例では、購入履歴をセットにしている。
ひとつめのシナリオは、購入を行い、それが購入履歴に反映しているかの確認をする。
もうひとつのシナリオは、購入を途中でやめて、購入履歴にデータが反映しないことを確認する。
最初の例に比べると、シナリオの長さが長くなる(テスト時間が多くなる)。ただし、購入履歴の機能まで正しく確認することができる。
最初の例の場合、ログインして購入履歴を確認する処理のため、テスト前提のテストデータを保証する必要がある。
つまり、ログインするユーザーがXXXの商品をXX/XXに購入したというデータを持った状態をキープし、その前提で”ログイン⇒購入履歴を確認する”のシナリオを実施する必要がある。
このように、依存性を減らすと、単体でシナリオを実施できるため、利用時の負担は少ない。
ただし、実行時間が長くなり、同じ機能のテストを複数のシナリオで実施されるため、無駄なテストリソースを消費する。
テスト自動化の運用に応じて、この依存性を決めてシナリオを作成する必要がある。
6.Scenario size
これは、5.Scenario independencyと併せて考える必要がある。
シナリオのサイズは、大きいと実行完了するまでの時間が長くなる。
実行時間が長くなっても、常にテストが成功する前提であれば、問題がないのかもしれません。
もし、テストが失敗したらどうするでしょうか?
たぶん、以下のオペレーションを行うでしょう
- エラーのログをもとに、失敗原因を調査
- 失敗原因を復旧
- 再実行し、成功を確認
そのため、一つのシナリオが大きいと、調査時間や再実行完了し成功を確認するまでの時間が大きくなる。

これとは別に、多くの機能を一つのシナリオに入れた場合を考える。
プロダクトの改修の影響範囲を鑑みて、影響受ける機能のみリグレッションテストしたい場合、絞り込んでテストを実施できない。そのため、実行時間が長くなってしまう。

5.Scenario independency は、シナリオの依存を減らすために、いくつかの機能をまとめてテストすることを述べた。
一方、6.Scenario size は、最低限のシナリオに絞るべきと述べている。
この双方バランスを考えながら、シナリオを構成する必要がある。
Finaly
次は7月3日(金)頃配信予定です。
引き続き、Code Design vol.03 を予定しています
reference
- A Journey through Test Automation Patterns (Book)
- Advanced Level Syllabus – Test Automation Engineer