Outline
本コンテンツは、これからテスト自動化を始める人向けに作成するコンテンツ。
筆者のこれまでの経験を元に作成しているので、教科書と異なる場合があります。
今回は、テスト自動化の実装にあたって、どのようにプログラムを組むとよいかの設計に関することを記載する。
尚、開発言語に依存しないレイヤーである、概念について記述する。
ボリュームが大きいため、数回に分けて執筆する
Condition
テスト自動化のコード設計の話をする前に、テスト自動化をどのように使うかの前提が重要になる。
どのようにテスト自動化を使うかによって、設計の視点が変わるからである
Target Application
筆者はWEBサービスのテストエンジニアである。
そのため、WEBサービスの開発を前提としたテスト自動化の話になる。
Test Layer
End to End のテスト自動化とする
How to use automation
WEBの機能のリグレッションテストとして利用する。
以下のような運用を想定する
・機能毎にテストシナリオを作成し、テスト自動化のスクリプトを作成
・JENKINSでテスト実行を行う
・各テストシナリオを基本的に毎日実施
・毎日JENKINSのステータスを確認し、失敗したスクリプトがあれば調査し、問題解決後再実施し成功にする
Test automation design view point
1.Data driven
2.Data normalization
3.Keyword driven
4.Robust & Sensitive
5.Scenario independency
6.Scenario size
7.Setup & Teardown
8.Analyzable report
9.Repeatability
10.Break flaky
11.Flexible trap
尚、プログラミング視点のポイントは省略する。
再利用性、クラス設計、コーディングルール等には触れず、テスト自動化に特化してコーディング設計で重要なポイントを取り上げる。
今週は1,2を取り上げる
1.Data driven
Data driven(データ駆動)とは、簡単に言うと"ScriptとDataを切り離して設計"すること。
Scriptはテスト自動化のアクション等を定義するプログラムのこと(当たり前のこと言ってます)。
Dataとは、入力や検証するためのパラメータのこと(当たり前のこと言ってます)。
テスト自動化では、scriptとdata(excelやRDBMS,CSV等)に完全に切り離して実装する。
以下に、Capture & Replayのtoolでテスト自動化のプログラムを、”ログインする処理”に対して実装した例を示す。

この利点は以下の通り
保守性が上がる
パラメータの変更(上記例では、ユーザーのpasswordが変更になる)が発生した時、scriptは変更なく、dataの修正だけで済む。
データを複数のScriptに流用できる
例えば、予約、予約した情報のキャンセルのテストシナリオを考える。
予約するデータとキャンセルさせる予約情報(店舗名等)は同じである。
この場合、ひとつのdataに対して、予約、キャンセルのそれぞれのscriptが利用することで、最小限のdata定義することができ、dataの保守性が上がる。

Dataを軸に、繰り返し処理ができる
例えば、大量のテストユーザーを作成するシナリオを考える。
テストユーザーを作成するscriptはdataに関係なく、1つになる。
そのscriptに対して、5つのテストユーザーのdataを用意する。
テストユーザー作成のscriptに対して、この5つのdataを実行させることで、最小限のscriptで5つのテストユーザーを作成することができる

2.Data normalization
データ正規化、そのなかでも一般的によく使う第1正規化~第3正規化がある。
Data drivenにおいて、データ正規化が重要になる。
データ正規化とはなにか?に関して詳細はここでは説明しない。
例として、Data Drivenでつかった予約処理を考える。
ユーザー作成、予約処理のシナリオのために、2つのテーブルが考えられる
- ユーザーを定義する User Table
- 予約内容を定義する Booking Table

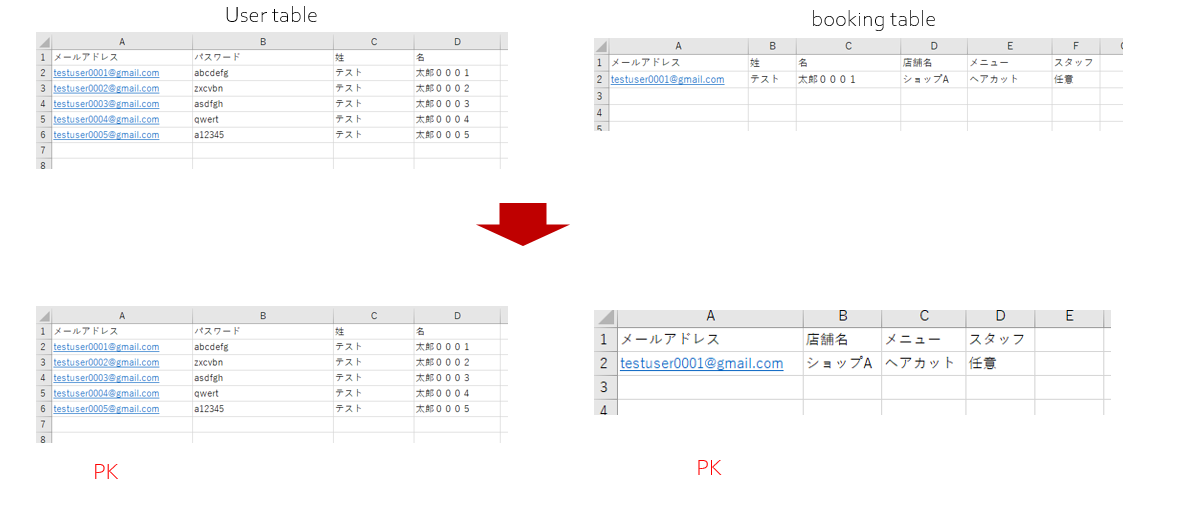
これを、データ正規化(第2)を行うと、一般的に以下のようなテーブルになる。
ユーザーの情報の冗長を取り除き、予約処理では User tableとbooking tableをメールアドレスを主キーとして結合して使う。
ただ、テスト自動化では、このやり方だと運用上問題が発生する。
例えば、
- 予約のシナリオで、ユーザーをtestuser0002@gmail.comに変更したい時どうするか?
- User tableにある5ユーザすべてで同じbookingの処理を行わせたい時どうするか?
- もしくは、別のUser Setを使いたい場合どうするか?
その場合、booking tableのメールアドレスを変更する必要がおきる。
これらを想定して、例えば、以下のようにデータ設計を行う。

下記のようにプログラムとデータを設計する。
ログイン処理、予約処理は、データの行数だけループすることを示している。

具体的に以下のように処理が行われる
1-1. testuser0001@gmail.com でログインする
1-2. testuser0001@gmail.com でショップAの予約を行う
1-3. testuser0001@gmail.com でショップBの予約を行う
2-1. testuser0002@gmail.com でログインする
2-2. testuser0002@gmail.com でショップAの予約を行う
2-3. testuser0002@gmail.com でショップBの予約を行う
:
この仕組みで、先ほどの運用変更はどうなるか?
「予約のシナリオで、ユーザーをtestuser0002@gmail.comに変更したい時どうするか?」
⇒ログイン処理で2行目だけを実施するように設定する
「User tableにある5ユーザすべてで同じbookingの処理を行わせたい時どうするか?」
⇒実現できる
「もしくは、別のUser Setを使いたい場合どうするか?」
⇒User tableを差し替える
テストではいろいろなデータパターンに差し替えて実施することが多々ある。
そのため、差し替える可能性を想定して、主キーをjoinするというRDBMSの考え方ではなく、データを掛け合わせ、必要な行数だけを実行させることを考えると、運用が楽になる。
Finaly
次は6月26日(金)頃配信予定です。
引き続き、Code Design vol.02 を予定しています
reference
- A Journey through Test Automation Patterns (Book)