はじめに
こんにちは。@emadurandalです。泣く子も黙るQiitaポエマーを生業としております。
WebGL界隈でひたすら自作ライブラリを作り続けているちょっと変わった人間です。
もう恒例となりましたが、年一回の報告ということで、今年はどうなったのかシェアしたいと思います。
ちなみに昨年の報告記事はこちらです。
WebGLライブラリを開発する際の心構え (WebGL Advent Calendar 2019)
WebGLのアドベントカレンダーがなくなってしまって、ちょっと寂しいですね……。
GLBoostから新ライブラリ「Rhodonite」へ
一昨年あたりからすでに開発していたのですが、まだお披露目できる段階に達していないということでOSS化を避けていました。
しかし、数ヶ月前についに水面下で開発していた新ライブラリをひっそりとOSSリリースしております。
ライブラリ名は「Rhodonite」です。読み方はロードナイト。
……厨二ちゃうんや。「バラ輝石」っていう、鉱物の名前から取ったんやで(´ ・∀・`)

Rhodonite Github Repository
Rhodonite npm Repository
GLBoostではGithubからしか入手できませんでしたが、Rhodoniteではnpmから以下のようにインストールが可能です。
$ npm install rhodonite
Rhodonite Editor
GUIで試せる環境もあります。glTFファイルやVRMファイルを3Dビューの中に放り込んでみてください。
Rhodonite Editor
DamagedHelmet表示デモ
Editorと行っておきながら、まだまだ編集できることはそう多くありません。限りなくViewerに近いです。
- 基礎的なPhysically-based Rendering (IBL)
- glTFサポート
- VRMサポート(全モーフターゲットのブレンディングと物理揺れボーンをサポート)
- glTF/VRMアニメーションサポート
VRMの再生をサポートするサービスは多いですが、Three.jsなどの有名ライブラリをベースにしているものが多いと思います。自作ライブラリベースで対応しているものは珍しいかもしれません。
Rhodoniteの特徴を生かして、VRMのモーフデータなどは頂点データではなく、浮動小数点テクスチャにロードしています。
VRMについては40個近い全てのモーフターゲットの頂点変位データをGPUに読み込んでいるので若干ロードに時間かかります。
こっそり公開になった理由
最大の理由は、「自信を持って出せる」という状態に惜しくもまだ至っていないからです。
設計思想的にはかなり頑張ったつもりなのですが、プロダクトの良し悪しは思想だけでは決まらず、それを活かせるだけの優れた実装や開発スピードを維持できることが重要です。
また、Three.jsやBabylonJSなどと比べるとどうしてもマンパワー的に同等の機能を搭載していくことはできないので、同じ土俵で比べられても困ってしまう、という部分もあります。
ですので興味を持たれた方は、そこら変に留意した上でお試しください。
もちろん、Rhodoniteには他のライブラリが挑戦していない優れた部分もあります。「ほーん、そういう工夫があるのね」という知見ももしかしたら得られるかもしれないので、
気になる方はぜひ触ったりコードを見たりしてください。
すでに IZUNAさんなど、数名の方がトライしてくださっているようで、ありがたい限りです。
Rhodoniteで遊んでみる (IZUN∀☆TEC)
cx20さんによるglTFファイル対応比較表gltf-testにもすでに載っています。なかなかガチライブラリ勢に追いつくのツライ(´ ・∀・`)
Rhodoniteの設計思想
GLBoostに比べると、かなりまともになりました。特にデータ構造やデータの受け渡しについて様々な工夫を凝らしています。
コンポーネント指向
Unityゲームエンジンなどにもみられるコンポーネント指向設計を採用しています。3D空間上における実体であるエンティティに各種コンポーネントを搭載させることにより、「物体」に機能をもたせます。
コンポーネントは「物体」に能力を与える、各種機能の最小限の単位であり、TypeScirptのクラスで表されます。
機能の単位であるコンポーネントを、入れ物であるエンティティに搭載させることで機能を増やすこのアプローチは、古典的なクラス継承プログラミングよりも柔軟性やコードメンテナンス性においてより優れています。今日のゲームエンジンで主流の設計アプローチです。
コンポーネントの例
Transformコンポーネント
平行移動(translate)、回転(rotate)、スケール(scale)の設定値を元に、物体の姿勢を示す変換行列を内部的に生成するコンポーネントです。
SceneGraphコンポーネント
物体の親子関係(シーングラフ)を形成するコンポーネントです。Transformコンポーネントが持つ姿勢の変換行列を積算してワールド行列を生成します。
Meshコンポーネント
ポリゴンメッシュのデータを保持するコンポーネントです。
MeshRendererコンポーネント
Meshコンポーネントからメッシュデータを受け取り、WebGLなどの3DAPIを用いてメッシュの描画を行うコンポーネントです。
Skeletalコンポーネント
スキニング処理を行うコンポーネントです。
Cameraコンポーネント
カメラの機能を担うコンポーネントです。
Lightコンポーネント
ライトの機能を担うコンポーネントです。現在はポイントライト、ディレクショナルライト、スポットライトをサポートします。
Effekseerコンポーネント
オープンソースエフェクトツールEffekseerのエフェクトを再生するためのコンポーネントです。
Effekseerは国産のオープンソースベースのリアルタイムエフェクトツールであり、ランタイムライブラリです。商業利用も増えており、今後も要注目です。バーチャルキャストでも動くってすごいですね。
Physicsコンポーネント
物理処理を担当するコンポーネントです。
Rhodoniteは ECS (Entity Component System)ベースか?
近年のUnityなどに見られるECSは、旧来型コンポーネントシステムに比べて以下のような特徴を持っています。
- コンポーネントがClass(処理とデータが癒着)ベースでなく、構造体(Component)とそれに対する処理(システム)に明確に分離されている。
- データ部分はメモリ的に連続であり、システムが高速に処理できるための様々な工夫が凝らされている(CPUキャッシュを最大限に活かす、など)
- プログラマ視点では、プログラミング作法としてとっつきづらくなる(これについてはUnity社も改善に取り組んでいます)
Rhodoniteではどうなっているかというと、ECSのSystemに相当する部分はまだなく、Classベースです。
つまり、コードの観点からはComponentクラスのメンバ変数としてデータが記述されています。
しかし、データとしては分離されています。
どういうことかというと、Componentクラスの外部に巨大なメモリプールをArrayBufferとして確保しており、そこからComponentクラスの各メンバのメンバ変数データ(Float32Arrayベースの独自ベクトルクラス)に確保済みメモリをアサインしているのです。
そして、元となるメモリプールはメモリ的に連続です。つまり、各メンバ変数のデータについて、エンティティ間でメモリ連続である(他のメモリレイアウトを取ることも潜在的には可能です)ということです。これはCPUのキャッシュメモリのヒット率向上に貢献しています。
Rhodoniteにはメモリを階層的に管理する仕組みとして、それぞれBuffer、BufferView, Accessorという3つのクラスがあります。glTFのバッファ管理の仕組みを参考にしており、まさにglTFのBuffer、BufferView, Accessorと同じです。Rhodonite内に存在するSceneGraphComponent(3Dソフトでいうグループノードのようなもの)というComponentを例に上げると、このComponentが持つworldMatrix(ワールド行列)のデータは、下図に示されるように、GPU転送用Buffer内にあるBufferView、その中の一つのAccessorクラスが管理し、そのAccessorではSceneGraphComponentを持つ全てのEntity分、メモリが連続しており、担当Accessorによって次々とアクセスすることができます。
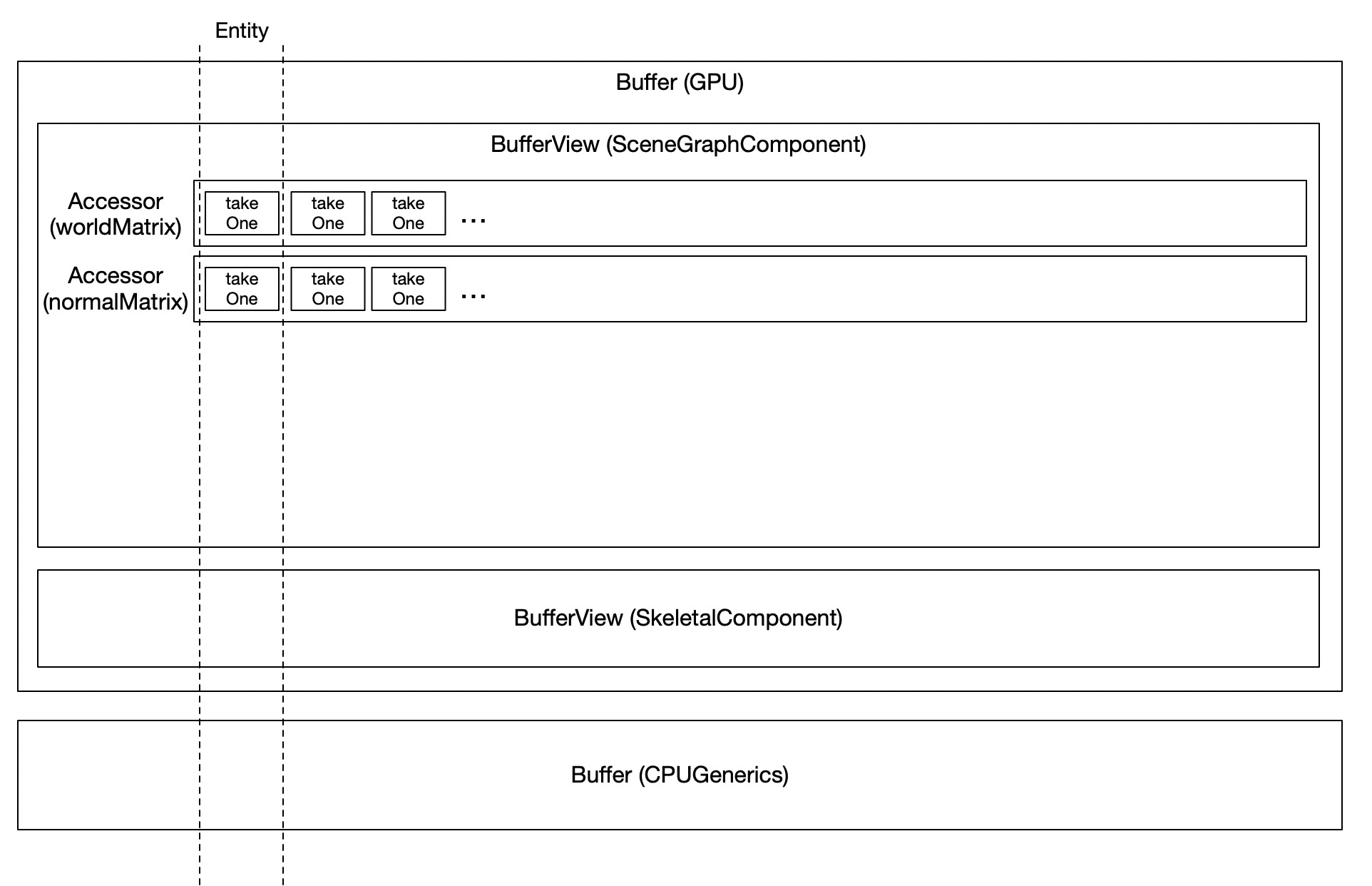
これは、将来WorkerスレッドやSharedArrayBuffer化などを駆使することで、ECSと同様に並列コアを活用してコンポーネント処理を高速化できる余地があることを意味します。
そのため、Rhodoniteのコンポーネントシステムは、ある意味ECSであるともいえるし、ないともいえます。
今後うまく発展させられれば、GameObject時代のUnityのような、クラスベースのとっつきやすさのまま、ECSの性能の高さを実現するという良いとこ取りができるの道もあるかもしれませんが、さてどうなりますか……。
そて、Rhodoniteのこのメモリレイアウト方式は後述する「ブリッタブルメモリアーキテクチャ」にも話が繋がっています。
ブリッタブルメモリアーキテクチャ(Blittable Memory Architecture)
オレ造語です(´ ・∀・`)
前述の通り、Rhodoniteのコンポーネントクラスの各フィールドメンバー(メンバ変数)は、メモリ的に連続しています。これは実はGPUに対してデータを送る際に役立ちます。
WebGLを使ったことのある方なら、gl.uniformf4などのUniform変数の設定関数を使ったことがあるでしょう。これらのパラメータ設定関数はかなり低速です。1
Rhodoniteではこの問題に対策を打ちました。Rhodoniteでは各コンポーネントのデータやマテリアルのシェーダーパラメータデータは、実際には最初に確保した巨大なメモリプール上に存在します。コンポーネントのデータ(Transformの姿勢行列など)がCPU内で更新されたとき、普通の発想であれば、これをコンポーネント(3D空間上のオブジェクト)毎にuniform4fvを呼んで設定しなければならず、これはかなりのAPI呼び出しボトルネックになります。仮にこれらのパラメータ設定関数自体が高速に動作したとしても、元あるデータ位置からパラメーターデータのコピーが都度発生することは避けられません。
しかしRhodoniteでは、各コンポーネントのデータやらマテリアルデータやら、ほとんどのデータがこの巨大なメモリプール(先程の図でいうGPU転送用Bufferクラスが保持する巨大なArrayBuffer)上に始めから配置されています。
コンポーネントの更新処理が終わったら、それでデータ準備は完了。これらをGPU側に渡すためにわざわざ別のメモリ位置に一つ一つデータコピーする必要はありません。この大元の巨大なメモリプールをGPUにテクスチャとして一気に送信(Blit)してしまうのです。
これなら細々としたデータの多数コピーでなく、大きなメモリデータの一回きりのコピーで(論理的には)済みます。どちらが高速かは想像がつくと思います。
そして、各メッシュは頂点データの一部にインスタンス番号(コンポーネントID)を保持しており2、頂点/フラグメントシェーダーではそれを元に、転送された浮動小数点テクスチャ(RhodoniteではDataTextureと呼んでいます)に対し的確なメモリ位置からデータをフェッチして計算に用いるのです。コンポーネントデータだけでなく、マテリアルのシェーダーパラメータも同様です。
Blittable Memory Architecture + インスタンス描画 = 描画めちゃくちゃ速い(はず)!
この仕組みは、シェーダーで大容量データを使えるという以外にも素晴らしい利点が加わります。設計的には描画処理を著しく高速化できるのです。
基本的にすべての描画はインスタンス描画にしてしまいます。
各インスタンスはコンポーネントシステム上のエンティティに相当すると考えてください。
普通の描画方法では、一つ一つ描画するたびに、world行列などエンティティ固有の情報と、そしてマテリアルが異なっていたらマテリアルパラメータをuniform送信しなくてはなりません。WebGL2でUBOが使えれば送ったデータは揮発化しませんが、UBOは容量が心もとないです。
一方、浮動小数点テクスチャであれば、アプリケーション内で必要となる全てのエンティティ群のコンポーネント情報と、利用しているマテリアル情報を全て収めることが可能です。
勘の良い方はもうお気づきでしょう。誤解を恐れずに言うと、このBlittable Memory Architectureとインスタンス描画をうまく組み合わせれば、CPU側で必要なドローコールはごく僅かな回数のインスタンス描画命令だけで済みます。
全てのエンティティのWorld行列などのデータはすでにテクスチャ内に存在するためです。
エンティティやマテリアル毎にGPUへパラメータ送信する都度にGPUを待たせる必要はありません。一度gl.drawElementsInstanced()を呼べば1000個でも10000個でも、異なる位置や属性で大量の3Dオブジェクトをシーンに一気に描画することができます。
(GPUのステート変更の必要性が間に挟まってしまう場合はドローコールを分ける必要があります)
これが実現できれば、WebGLでも大量物量シーンの超高速描画が実現できます。
懸念点
テクスチャアクセスはGPUにおいて比較的重いデータアクセスです。そのため、描画されるピクセル数が大量であったりデータフェッチする回数が多すぎる場合は、描画上のボトルネックになる場合があります。
その場合は、通常のレンダリングアプローチを併用する必要も考えられます。しかし、WebGLにおいてはほとんどのケースにおいて、CPU側(JavaScriptやWebGLAPIの処理)がボトルネックの主原因となります。
実際に、テクスチャアクセスボトルネックが表面化する局面には今まであまり遭遇していません。
本当に実装できた!
当初、このアイデアを本当に実現できるのか不安でしたが、意外にもかなりうまくいきました。IE11でも動作したくらいです。
fp32浮動小数点テクスチャであればスキニング処理やブレンドシェイプ処理なども含め、全く問題なく動作します。精度がそれほど必要ないデータ(スタティックオブジェクトの座標変換や色パラメータなど)であれば、fp16でも行けるでしょう。
iOSデバイスの場合、iOS13まではuniformベクタ数が128個までしか使えなかった中で、VRMフォーマットのキャラクターなどの大量のボーン数や表情ブレンドシェイプデータがあっても、WebGL1で問題なく動作させることができています。これはかつては競合ライブラリが持ち得ない、Rhodoniteの決定的な強みでした。
しかし今やThree.jsやBabylon.jsでもWebGL2でUBOとか(Rhodoniteほど全フリしてないけど)部分的に浮動小数点テクスチャを利用したりして、かつて彼等ができなかったこうした処理も今は部分的に追いつかれてしまいましたね(´ ・∀・`)
(※でもVRMの全モーフターゲットを同時にすべてブレンドできるのはまだRhodoniteだけかもしれない。どうなんでしょう? 他にできるライブラリあれば教えて下さい。)
DataTextureへの的確なデータアクセスをどう実現しているか
DataTextureはRhodonite側のメモリプールのデータをそのまま転送しているので、もう本当に任意の一次元データメモリ領域という感じです。それに対して、的確な位置をテクスチャ座標でうまく指定してデータを読み込まなくてはなりません。
しかもWebGL1でも動かさなければならなかったので、それはもう大変でした。
この実装にあたっては、@YVT さんのこちらの記事に大変助けられました。
この記事を知らなかったらそもそもこの仕組みを作ろうとは当時思わなかったかもしれません。YVTさんありがとうございます。
最近はこうした優秀な若人さんたちから多くの知見や助けをいただきつつ、僕はCG/WebGLの研鑽やライブラリ開発を行っております。ありがたい限りです。日々精進あるのみですね。
さて、フェッチ自体はこれで良いとしても、問題はアクセスしなければならないパラメータがたくさんある場合です。論理的には巨大な一次元メモリーに対してアクセスするのですから、そのパラメータのデータ位置に相当する「テクスチャ上におけるオフセット情報」が必要です。
これはどう渡せばいいのでしょうか。
uniform変数で送る? → そもそもuniform変数の設定を避けたかったんじゃないのか?
いや、各パラメータのデータサイズを固定長にすれば、オフセットはシェーダー内で計算できるぞ → データ領域に無駄が生じる
ということで悩んだ末たどり着いたのが、**「オフセット整数値をシェーダーコード内に直接書き込んでしまおう」**というものでした。
これならば、扱うデータパラメータの数がかなり多くても、データサイズがそれぞれ異なっていても、ほぼ問題ありません。
注意点
とはいえ、この方法にも問題はあります。シェーダーパラメータの数分、フェッチのための接着剤のようなコードが生成されてしまうため、シェーダーコードの複雑さを招いてしまうことです。これはシェーダーコンパイル時間の増大や処理パフォーマンス上の懸念があります。今のところ後者についてはほぼ問題になっていませんが、GPUパワーをとことん使い倒すネイティブゲームなどでは要検証かもしれません(そもそもテクスチャフェッチ自体がGPUコアにとっては遠いアクセスですし)。
あとは、同様の試みをしたい方へのアドバイスとして、メモリアライメントに気をつけてください。FP32の浮動小数点テクスチャの場合、一つのテクセル(RGBA)で16Bytesあります。CPU側のメモリプールで各データを配置したい場合、各データパラメータのデータ配置は16Bytesのアライメントに従うようにしましょう。こうすることでフェッチの際に微妙にバイト位置がずれてデータを正しく取り出せないといった不具合をなくせますし、取り出したいvec4データが複数のテクセルにまたがって配置されてしまう可能性もなくすことができます。
余談:ネイティブOpenGLなどのより自由度の高い3DAPIではAPI側でVRAMベース/Textureベースのストレージ機能が存在する。
実は、ネイティブOpenGLにはBuffer Textureという、まさにTextureをストレージとして利用するための機能がAPIとして提供されています。さらに、SSBO (Shader Storage Buffer Object)もストレージとしてはVRAM上のメモリとして置かれているはずなので、これらの糖衣構文的な、類似のものと言えなくもないでしょう。
私も、WebGL1/2でこれらのAPI機能が使えていたら、これらを使って実装していたと思います。
glTexSubImageによるデータ更新では、DataTexture上のデータ更新の対象領域で矩形としてしか指定してできない(データ更新関数というより、本来はテクスチャの更新関数ですからね)ため、実際には更新する必要のないデータ部分まで(現状のデータで)更新せざるをえないというデメリットがあります。あまりスマートじゃないですね。
WebGL2ではUBOも活用するようにした
最近の開発で、WebGL2ではUBOも利用するようになりました。メモリプールの最初の方のデータはUBOに、それ以外のデータ分はDataTextureに転送されます。
シェーダーでのデータフェッチ関数で、UBOとDataTextureどちらにアクセスすべきか吸収しているので、シェーダープログラマはUBOとDataTextureの境目を意識する必要はありません。
UBOはBlockという16~64KB程度のサイズの細かい領域単位でしか本来アクセスできないのですが、複数のブロックは実は単一のUBOにマッピングすることができます。Uniform Block同士のメモリアライン(大抵は256KB)にさえ気をつければ、複数のUniform Blocksをピッタリくっつけて、DataTextureのように大きなメモリ領域として利用することが可能です。
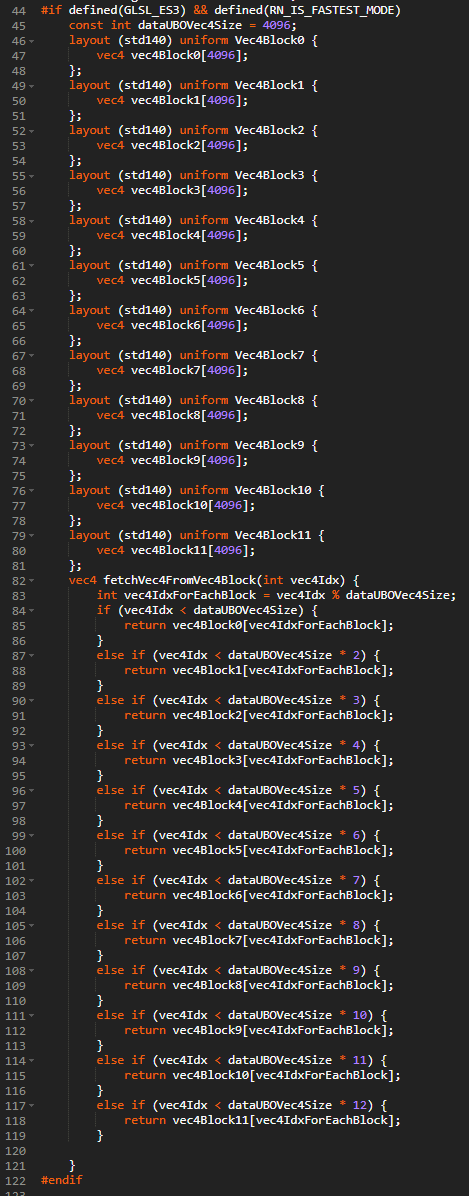
しかし、上の画像のようにUBO Blockもあまり大きなサイズ(64KBなど)や多数のBlockを一気に使ってしまうと、シェーダーのコンパイル時間がなぜか膨れ上がったり、描画時のシェーダーからのUBOアクセスが遅くなってしまうことがあります。
UBOのデータはハードウェア的には、GPUコアに比較的近いシェアードメモリと呼ばれる領域にデータがロードされますが、容量が限られているために、しょっちゅうVRAMとの間でデータを入れたり出したりしています。
アクセスするデータ位置がランダムすぎると、このデータの入れ替えがどうも頻発してしまうようですね。
このUBOを広域メモリとして使う機能は最近実装したばかりなので、しばらくは適切なサイズとBlock数の調整が必要と考えています。
UBO(定数バッファ)でバイトオフセットを指定できるようになったのは比較的最近?
※ちなみにDirect3DでUBOに対応する機能は定数バッファと呼ばれます。WebGL InsightによるとDirect3DでUBOと同様にバイトオフセットを指定できるようになったのはVSSetConstantBuffers1メソッドが追加されたDirect3D 11.1からだそうです。つまり、WebGLを実行するGPUスペック、Webブラウザの中間レイヤーの実装次第によっては、同等のネイティブ関数を呼ぶようになっておらず、ソフトウェア的にバイトオフセットを解決する可能性があるということです。つまり、低速に実行される懸念があるということですね。ここらへんはもう少し現実的な落とし所のリサーチが必要そうです。
こうしたシェーダー向け大容量データストレージの課題点
Rhodoniteが追求するこうしたシェーダーから利用する大容量データストレージの実現アプローチは、その大容量を生かして従来のWebGLでは難しかったリッチな表現を可能とします。
例えば、ブレンドシェイプであれば、頂点データとして頂点変位データを入れるやり方では、せいぜい4ブレンドターゲットくらいしか同時には扱えませんでした。しかし、Rhodoniteでは、それこそVRMのキャラクターが持っているような多数のブレンドデータ(表情)を同時に扱って操作することができます。
反面、ネイティブゲームなど、シェーダーパフォーマンスを極限まで引き出したい場合は、こうした広域データアプローチは不利な点があります。極めて一般的な一次元データとしてテクスチャにデータを並べているので、GPU内のテクスチャキャッシュのヒット率があまりよくない点です。Rhodoniteのコンポーネントの連続データレイアウトはCPUにとっては都合が良いのですが、GPUのテクスチャアクセスという事情には合いません。テクスチャアクセスは本来当然ながらテクスチャリングに使われるものなので、近傍同士のテクセルが頻繁にアクセスされることを想定しており、近傍エリアのテクセルがテクスチャキャッシュに乗るのです。データアクセスの局所性として、この両者はマッチしませんね。ここらへん、うまく改善できればよいのですが、何か知見をお持ちの方はぜひご教示ください。
泣き所
ここまで読むとすごい感じがするのですが。残念ながらまだ実装が理想までいっておらず、
この仕組みによって大容量データをシェーダーで使えるという点以外にも素晴らしい利点が加わります。設計的には描画処理を著しく高速化できるのです。
をきちんと実証できるような、高速インスタンス描画システムがまだ作りきれていません。インスタンス描画で一度に扱える頂点数の制限や、プリミティブタイプが変わったりその他GPUステートの変更が挟まると、さすがにドローコールを分けなければならず、そこらへんをうまく調停するための制御システムの開発がけっこう大変なのです。
しかも開発当時はまだWebGL2の普及度がいまいちで、WebGL1で動作することを至上としたために、実装上の制約にかなり苦しんでしまったのですね。
とはいえ、これを実現できればかなりの優位性があることは確かです。今やMac/iOSでもWebGL2がデフォルト有効になりそうなので、今がラストチャンスかも知れません。3
ちなみにWebGPUやネイティブAPIではさらにIndirect描画も使えるので、将来はそれらの活用も鑑みないといけないですね。考えることは多い……。
Rhodonite使い方
JavaScriptでの例です。TypeScriptで開発しているので、もちろんTypeScriptで記述することも可能です。
async function main() {
// WebGLモジュールをロード
await Rn.ModuleManager.getInstance().loadModule('webgl');
// Systemインスタンスの取得と、描画処理方法(今回はUniformWebGL1)と描画先canvasを指定
const system = Rn.System.getInstance();
const gl = system.setProcessApproachAndCanvas(Rn.ProcessApproach.UniformWebGL1, document.getElementById('world'));
// Component搭載済みEntityの作成
function generateEntity() {
const repo = EntityRepository.getInstance();
const entity = repo.createEntity([TransformComponent, SceneGraphComponent, MeshComponent, MeshRendererComponent]);
return entity;
}
const firstEntity = generateEntity();
// 頂点データの作成
const indices = new Float32Array([
0, 1, 3, 3, 1, 2
]);
const positions = new Float32Array([
-1.5, -0.5, 0.0,
-0.5, -0.5, 0.0,
-0.5, 0.5, 0.0,
-1.5, 0.5, 0.0
]);
const colors = new Float32Array([
0.0, 1.0, 1.0,
1.0, 1.0, 0.0,
1.0, 0.0, 0.0,
0.0, 0.0, 1.0
]);
// 頂点データを指定してPrimitiveオブジェクトを作成。Primitiveクラスの設計はglTF2フォーマットに概念的に合うように設計されています。
const primitive = Primitive.createPrimitive({
indices: indices,
attributeCompositionTypes: [CompositionType.Vec3, CompositionType.Vec3],
attributeSemantics: [VertexAttribute.Position, VertexAttribute.Color0],
attributes: [positions, colors],
material: void 0,
primitiveMode: PrimitiveMode.Triangles
});
// EntityのMeshコンポーネントにPrimitiveを追加
const meshComponent = firstEntity.getComponent(MeshComponent);
meshComponent.addPrimitive(primitive);
// 描画する。
// Entityの存在は作成した時点でRhodoniteが内部的に把握しているため、プログラマが明示的にシステムにEntityを登録する必要はありません。
const draw = function(time) {
system.process();
requestAnimationFrame(draw);
}
draw();
}
現在開発中の機能
Shaderity
Shaderityという補助ライブラリを作りました。Rhodoniteの開発過程でできたものですが、単体でも利用可能です。
リアルタイム系のレンダリングライブラリを作る上での悩みどころは、マテリアルやシェーダーをどうスマートに管理・運用する仕組みを作るかです。
Rhodoniteも初期はGLBoost時代とそう変わらず、シェーダーごとにTypeScriptのクラスを定義してその中に文字列リテラルとしてシェーダーコードを書き込むという方法でやっていましたが、これはかなりメンテナンス性や可読性が悪いものでした。
これを解決するためにShaderityを開発しました。これはglslifyに似たもので、シェーダーファイル同士のinclude機能に加え、様々な便利機能を搭載しています。
Shaderityには次のような機能があります。
- 独自のインクルード文による、GLSLシェーダーファイル(.glsl/.vert/.frag)間のIncludeを実現(glslifyと似た構文)
- GLSL ES 1.0とGLSL ES 3.0の間の相互変換
- WebPack Loader対応版(shaderity-loader)による、GLSLシェーダーファイルのTypeScript/JavaScriptへの埋め込み機能
- Include文による静的なインクルードだけでなく、JavaScript実行時にシェーダーコード内の指定箇所への動的な文字列埋め込みも可能。
- glslifyとの併用も可能
最近のRhodoniteではシェーダー開発をShaderityベースに移行し始めており、glslifyのように、単独のシェーダーファイルを組み合わせることで大きなシェーダーを開発できるようになりました。個々のファイルはglslの文法に従っているので、VSCodeなどでコードハイライティングが適用され、コーディング時の快適性も向上しました。
たまにShaderityというネーミングについて「Utilityをもじったんですよね?Shaderlityにすべきじゃないのw」とか煽られるんですが、ちがうんだヨ。UtilityじゃなくてIntegrityをもじったんだヨ(´ ・∀・`)
ノードベースシェーダーエディタ
Shaderityにより、だいぶシェーダーコーディングの快適性は向上したのですが。さらに以前からずっとやってみたいことがありました。
みんな大好き、ノードベース編集です。まだ荒削りですが、Rhodoniteでもすでに実装しており、RhodoniteEditor上で試すことができます。
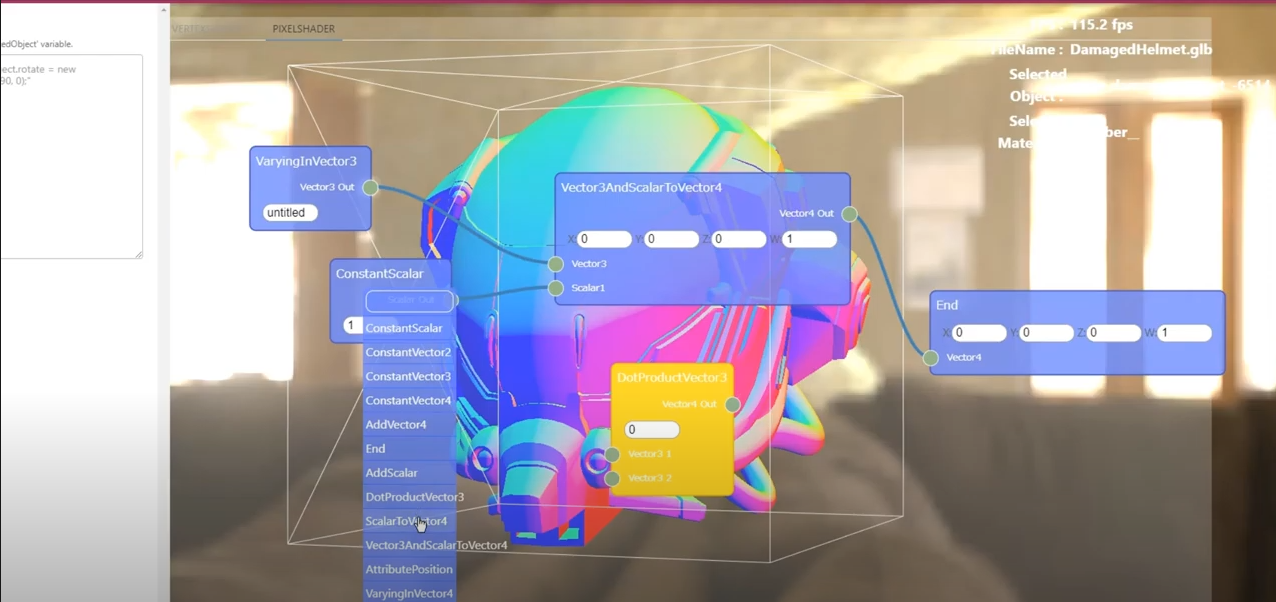
ノードベースの環境ってどうやってつくるの? と思われた方も多いと思います。方法は一つではないと思いますが、私がやっているやり方をお伝えします。
(以下は、わかりやすく説明するためにプログラムの些細な詳細手順については曖昧にしています)
ノードベースなエディタの作り方
例えば、次のようなノード接続関係を例にとって見ていきましょう。
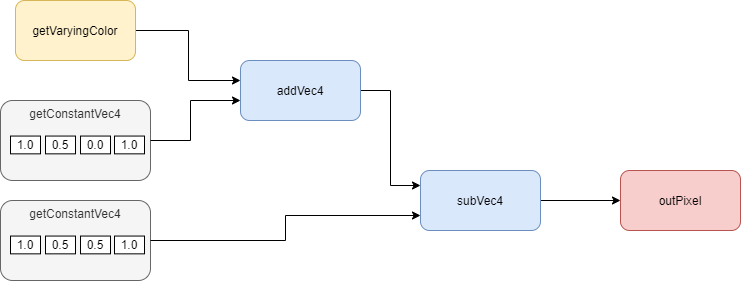
-
各ノードに対応する処理(シェーダーエディタなら一つのシェーダー関数に相当)を考え、それを一つの関数として定義をノードにもたせます。
各ノードのシェーダー関数には、ノードの入力に対応するin仮引数と、ノードの出力に対応するout仮引数があります。void addVec4(in vec4 lhs, in vec4 rhs, out vec4 oVec) { oVec = lhs + rhs; }GLSLは関数オーバーロードができるので、応用として関数名をaddにして型ごとに関数を複数定義してもよいでしょう。
-
ノードライブラリ(私はrete.jsを使っています)を使ってノードエディタとしてのUIを開発します。組んだノードの連結情報は一般的にJSONなどに出力して利用することができます。
-
ノードの連結情報を元に、全ノードをトポロジカルソートによって一次元に順番付けします。
-
使用されている各ノードが持つシェーダー関数を(重複を取り除いた上で)シェーダーコードに含ませます(シェーダーコード文字列に追記)。必要なvarying変数やmain関数なども用意します。
#version 300 es in v_color; // from vertex shader color layout(location = 0) out vec4 outColor; // It's the same as gl_FragColor in WebGL1. // Add functions of nodes void getVaryingColor(out vec4 oVec) { oVec = v_color; } void getConstantVec4(in vec4 val, out vec4 oVec) { oVec = val; } void addVec4(in vec4 lhs, in vec4 rhs, out vec4 oVec) { oVec = lhs + rhs; } void subVec4(in vec4 lhs, in vec4 rhs, out vec4 oVec) { oVec = lhs - rhs; } void outPixel(in vec4 color) { outColor = color; } void main() { } -
トポロジカルソート後の順序に従って各ノードを取り出し、完成版シェーダーコードのmain関数内に各ノード関数の呼び出しコードを(ソート順に)追記していきます。同じ種類のノードであっても複数箇所で使われているなら、その使われている数だけのノードがソート済み配列に入っています。そのため、同じ関数の呼び出しが何度も追記されることは当然ありえます。
#version 300 es in v_color; layout(location = 0) out vec4 outColor; void getVaryingColor(out vec4 oVec) { oVec = v_color; } void getConstantVec4(in vec4 val, out vec4 oVec) { oVec = val; } void addVec4(in vec4 lhs, in vec4 rhs, out vec4 oVec) { oVec = lhs + rhs; } void subVec4(in vec4 lhs, in vec4 rhs, out vec4 oVec) { oVec = lhs - rhs; } void outPixel(in vec4 color) { outColor = color; } void main() { getVaryingColor(); getConstantVec4(); getConstantVec4(); addVec4(); subVec4(); outPixel(); } -
各ノード関数の呼び出しに与える引数のための各一時変数を、main関数の最初の位置に変数定義しておきます。この一時変数を介してデータが(各ノードに対応する)各関数に繋がって行きます。この繋がりがノード間で配線したデータの流れということになります。
...(omited)... uniform vec4 u_constant_a; // a constant value specified by user. for example: vec4(1.0, 0.5, 0.0, 1.0) uniform vec4 u_constant_b; // a constant value specified by user. for example: vec4(1.0, 0.5, 0.5, 1.0) void main() { vec4 tmp_0 = vec4(0.0); // for getting v_color; vec4 tmp_1 = u_constant_a; // for a constant value specified by user. vec4 tmp_2 = vec4(0.0); // vec4 tmp_3 = u_constant_b; // for a constant value specified by user. vec4 tmp_4 = vec4(0.0); vec4 tmp_5 = vec4(0.0); getVaryingColor(tmp_0); getConstantVec4(tmp_1, tmp_2); getConstantVec4(tmp_3, tmp_4); addVec4(tmp_0, tmp_2, tmp_3); subVec4(tmp_3, tmp_4, tmp_5); outPixel(tmp_5); }ノードの接続情報をチェックし、ノード関数の引数の数や対応関係を適時調整します。
ノードベースシステムでは大抵、複数のノードから多くの入力を受けたり、自分のノードから多数のノードへ出力を出したりできます。そのため、線の接続個数に応じて引数の数を調整する必要があります。そのため、ステップ1での関数定義では、接続状況に応じて引数の数が異なるバージョンをそれぞれ用意してあげる必要があります(配列を使ってうまく抽象化しても良いかもしれませんが。GLSLだとちょっと難しいかな)。getConstantVec4は定数ノードなので、この例では一時変数の初期化時にuniform変数を利用しています。これでノードエディタ上で定数ノードの値をリアルタイムにビジュアル調整することもできるでしょう。
一時変数をいくつ置けばいいのか。それらを適切にデータがつながるように、それぞれの関数呼び出しのin仮引数とout仮引数にうまく渡るよう、各関数呼び出し引数にどう並べれば良いのか、という部分については、かなり細かい話になりますので割愛させてください。私の場合は、もう愚直にデバッグしながら試行錯誤しつつ処理を作りました。ここらへんは時間をかけて頑張ればなんとかなると思います。
-
以上の処理でシェーダーコードが完成です。しかし、コードとしてはかなり非効率であるため、glsl-optimizer(Emscripten版があります)などで最適化をかけましょう。npmなどで導入すれば、ランタイム時にコード最適化をかけられるでしょう。
まとめると、**ノードベースの表現をコードに落とし込む処理のキモは、「接続されたノードの処理順番をトポロジカルソートでシーケンシャル化すること」と「各ノードに対応する関数間のデータ受け渡しをどう実現するか」**であるということを覚えておきましょう。
関数のデータ連結ではRhodoniteではひとまずmain関数内に定義した一時変数を媒介としましたが、これだと生成されるコードは非効率になりがちで、コード最適化ツールの併用は必須になります。おそらくもっと良いやり方がありそうな気がします。
Rhodoniteの今後のシェーダー開発はいずれこのノードベース主体に移行しようと考えています。ノードベースで構築されたシェーダーコードは更にShaderityによって変換が加えられることで、RhodoniteのBlittable Memory Architechtureに最適化された最終的なシェーダーコードになります。
このやり方って、シェーダー編集だけに留まらないのでは
この考え方は、ノードベースなら何でも適用できます。シェーダーエディターだけでなく、Unreal EngineのBluePrint(CPU側のゲームロジックをノードベースで編集できる)やUnityのVisual Effect Graph(ノードベースのパーティクルエフェクト編集)のようなものも作れるでしょう。
要は、ノードとノードに対応させたい汎用的な単体処理の関数をたくさん作り、シーケンシャルに並べて、関数同士をデータ的に紐付ければよいわけです。
CPU側の処理をBluePrintのようにノードでやりたいなら、一つ例を上げましょう。
例えばthree.jsのよくある処理を独立性の高い(いわゆる状態を持たないImmutableな)関数に包み、それらをノードとして表現し、rete.jsなどのノードUIでユーザーに繋がせ、それらを前述のようなやり方でコード変換したらどうなるでしょうか。
あっという間(?)にthree.js製ノードベース3Dエディタの出来上がりです。ね、簡単でしょ?(´ ・∀・`) 4
Rhodoniteでもそのうちやってみたいですね。BluePrintみたいなかっこいいやつ。
振り返ってみて
GLBoost時代を一言でいうと「とりあえずちょろっとCGをかじってきた青二才が、イキって自作ライブラリを作ってみた」ということに尽きると思います。
それでも、いくつかの商用案件で採用いただいた、という意味では上々の成功と言っていいかもしれません(人との縁のおかげも多分にありましたが)。
一方、今のRhodoniteを一言で言えば「2作目で意欲的な試みができるようになったが、思い描いた理想の実現までいま一歩。ライブラリプロジェクトの運営としては前作よりもだいぶ改善できた」となるかと思います。
設計上の試みとしては前述したとおりで、開発体制としては以下の点であきらかにGLBoostより改善を果たせました。
- TypeScriptによる型ベースの開発
- 画像キャプチャベースのE2EテストとGithub Actionでの自動実行
- npm公開とそれにともなうセマンティックバージョニング
- 複数人での開発体制(プルリクベース)の構築
更に次世代はRustとElixirで作ります!?
もともとRhodoniteはRust言語で作ろうとしていましたが、当時のRustはまだ今ほど扱いやすくはありませんでした。
様々な実験を手軽にできるよう、まずはTypeScriptでコンセプト実験してみようと始めた見たら、こちらの開発で手一杯になりこのまま来てしまった感じがあります。
しかし、次は本当にRustで作ることでしょう。wgpu-rsというライブラリを使えば、大半のネイティブプラットフォームとWebブラウザどちらもWebGPUのAPI体系で開発することが可能な状況になりつつあります。
そして、去年からずっと注目しているもう一つ素晴らしい言語があります。Elixirです。「エリクサー」ですって? ワクワクする名前ですよね!
Elixirについては、こちらのfukuoka.exという日本国内のElixerコミュニティでのアドベントカレンダーにも記事を書かせていただいております。みんな、Rustだけじゃないぞ。Elixirもいいぞ。
自作3Dライブラリ次回作の新しい武器を探してたらElixirに出会いました
メイン部分をRustで作り、Elixirも対応プラットフォームによってうまく組み合わせるという、錬金術というか黒魔術みたいなことを考えているのですが、さてどうなりますか……。
最後
自分はあまり器用な人間ではないので、ここまでくるのに公私ともにさまざまな経験に揉まれ、時には道を見失い、時間をたくさん溶かしてしまうことも多かったです。
でもなんだかんだでまた再挑戦するあたり、「下手の横好き」という性質もずっと貫けばいずれは何かが花開くのかもしれませんね。みなさん、学び続けることを諦めてはいけませんよ。