DirectX や OpenGL、及び WebGL でプログラミングを行う際、CPU から受け取った配列の要素をシェーダから参照したいことが時々あります。Constant Buffer (DirectX) や Uniform Buffer (OpenGL) を使用すればシェーダに配列を渡せますが、この方法で渡すとデータは GPU のローカルメモリを経由して渡されるため、サイズが64KB程度に制限されます。古い GPU や WebGL 1.0 (Uniform Buffer がない) では制限がさらに厳しく、2KB程度しか渡せない場合さえあります (渡したいデータが他にもある場合、さらに減ります)。
このため、大容量のデータを渡すために、テクスチャを経由して渡すテクニックがよく用いられます。テクスチャの場合、データは GPU のグローバルメモリに格納されるため、VRAM が許す限りいくらでも大きなデータを格納することができます。
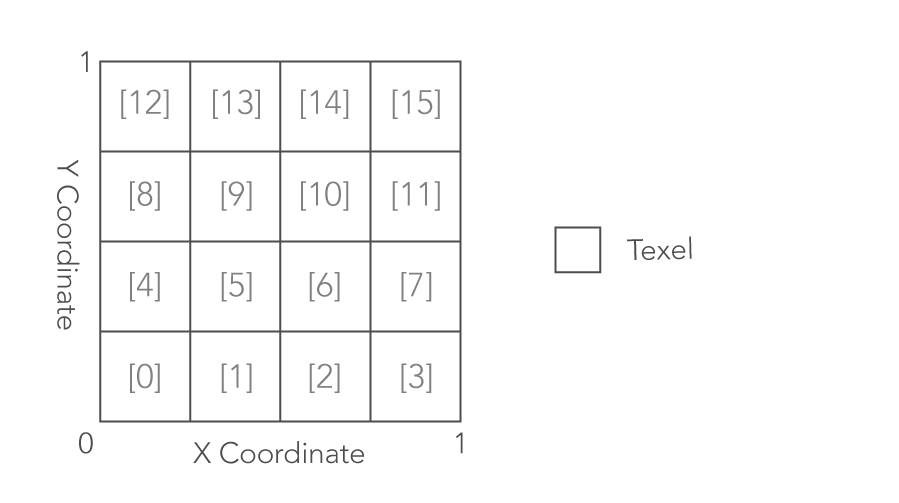
データをテクスチャにパックする方法は、上図で示しているように一番上 (または一番下) から順に詰めていくという方法が一般的に用いられます。シェーダからは以下に示すコードで要素を参照します (この例では GLSL を使用していますが、他のシェーダ言語でも同様です)。
vec4 fetchElement(sampler2D tex, float index, vec2 size)
{
float x = mod( index, size.x );
float y = floor( index / size.x );
x = (x + 0.5) / size.x;
y = (y + 0.5) / size.y;
return texture2D( tex, vec2(x, y) );
}
しかし、上のコードでは除算を行っており、ALU負荷が大きくなります。GPU (e.g. Intel HD Graphics) によってはダイ面積を節約する為に実行ユニット毎に独立した除算器を設けず、外部に設けた除算器を共有する形を取っており、この場合さらにサイクル数が増加します。そこで通常はもう少し最適化を行います。
/*
* invSize = 1. / size;
*/
vec4 fetchElement(sampler2D tex, float index, vec2 invSize)
{
float t = (index + 0.5) * invSize.x;
float x = fract(t);
float y = (floor(t) + 0.5) * invSize.y;
return texture2D( tex, vec2(x, y) );
}
size のかわりに、その逆数 invSize を受け取るようにすることで、除算が発生しないようにしています。この最適化の結果、2サイクル程度高速になります。
さらに最適化する
上のコードでも十分高速で、むしろテクスチャフェッチの遅延の方が問題になりそうな気もしますが、テクスチャのアクセスパターンによっては必ずしもそうとは限りません。例えば、インデックス値の空間的局所性が高い場合はキャッシュヒット率が高くなるので、テクスチャアクセスに費やす時間は短くなります。さらに、モバイル向けの非力なGPUでは、1サイクルの増加でさえ、無視できない程度の影響を与えると言われています (最近はそうでも無くなってきていますが…)。実は、ちょっとした工夫をすることで、さらに高速化することができます。
まず、X座標に着目すると、fract はテクスチャのラップアドレッシング (GL_WRAP) を利用すればいいので、不要になります。Y座標の floor も最近傍フィルタリング (GL_NEAREST) と同等です。index の値とテクスチャ座標の関係を図にすると、下図のようにすれば良いことが分かります。
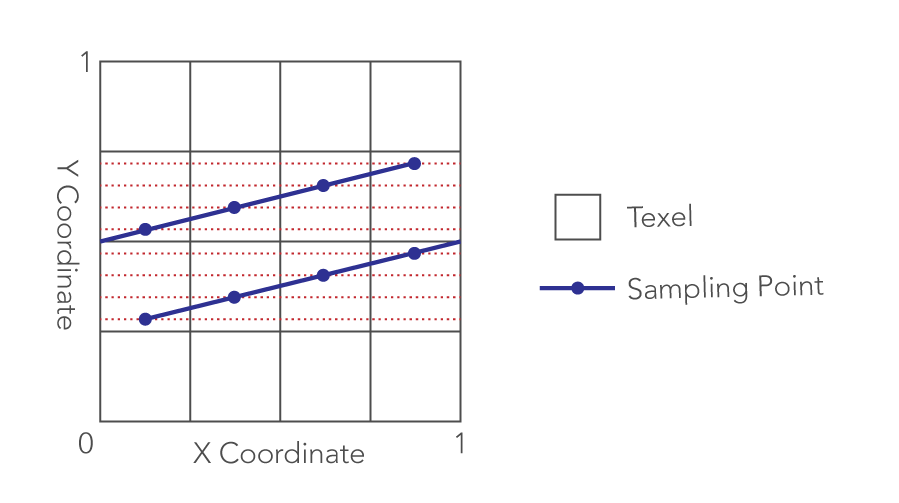
以上の点を考慮した上で最適化したシェーダを以下に示します。
/*
* arg = vec2(1. / size.x, 1. / size.x / size.y);
*/
vec4 fetchElement(sampler2D tex, float index, vec2 arg)
{
return texture2D( tex, arg * (index + 0.5) );
}
これにより、さらに2サイクル減らすことができます。
実装の注意点
座標/添字の精度について
WebGL や OpenGL ES で実装する場合、精度に関して注意が必要です。フラグメントシェーダでは mediump float を使用される方が多いと思いますが、mediump float では 1000 以下程度の整数しか正確に表現できません。このため、本記事の方法を実装する際には、highp float を使用してテクスチャ座標を計算することをお勧めします。
highp float (単精度浮動小数点数相当の精度) を使用した場合でも、正確に表現できる整数の範囲は 1600 万程度です。添字がこれより大きくなる場合、工夫が必要になると思われます。
値の精度
WebGL や OpenGL ES でよくあるミスの一つに、sampler2D の精度を省略してしまい、取得された値が lowp float になってしまうというものがあります。高精度な値が必要な時は、忘れずに highp sampler2D と定義しておきましょう。
OpenGL ES 3.0
WebGL 2.0 や OpenGL ES 3.0 は整数のサポートが改善されており、ビット演算ができるほか、整数で座標を指定してテクスチャフェッチを行う関数 (texelFetch) が追加されているので、こちらを使用した方が高速になるかもしれません。また、上記の精度の問題も発生しなくなります。
まとめ
本記事では、テクスチャを1次元配列のようにシェーダからアクセスする方法と、そのシェーダをさらに最適化する方法を示しました。
皆様が DirectX、OpenGL や WebGL 等を使用してプログラムを作成する際に、本記事の内容が参考になれば幸いです。