はじめに
TensorFlow 2.x での時系列データに対する多変量LSTMを実装する際の解説記事があまり見つからなかったので書きます。
この記事は以下のような人にオススメです。
- TensorFlowで時系列データに対する(多変量)LSTMを実装したい人
- LSTMに入力するデータの形式と前処理を知りたい人
用いるコードとデータはGitHubのレポジトリ上に公開してあります。コードはJupyter Notebook形式で、Colab上でもすぐに動かせるようになっているため参考にして下さい(良かったらスターもお願いします)。
今回取り組むタスク
今回は、気温などの気象データから、東京の**「平均雲量の予測」**を行ってみようと思います。
データ
今回は予測に用いるデータとして気象庁のHPから過去10年分の東京の7日間の**「平均気温、平均相対湿度、合計日照時間、平均風速、平均雲量」**をダウンロードしました。このデータもGitHubのレポジトリに置いてあります。
データを読み込むためのコードは以下のとおりです。
# ライブラリのインポート
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
%matplotlib inline
import seaborn as sns
import time
# データ読み込み
df = pd.read_csv('data/tokyo_weather.csv')
df['date'] = pd.to_datetime(df['date'])
# df.set_index('date', inplace=True) # index を date にする場合
df
実際にデータを見てみると以下のようになっています。当然ながら全て数値データですね。次にこのデータを処理していきます。
データの前処理
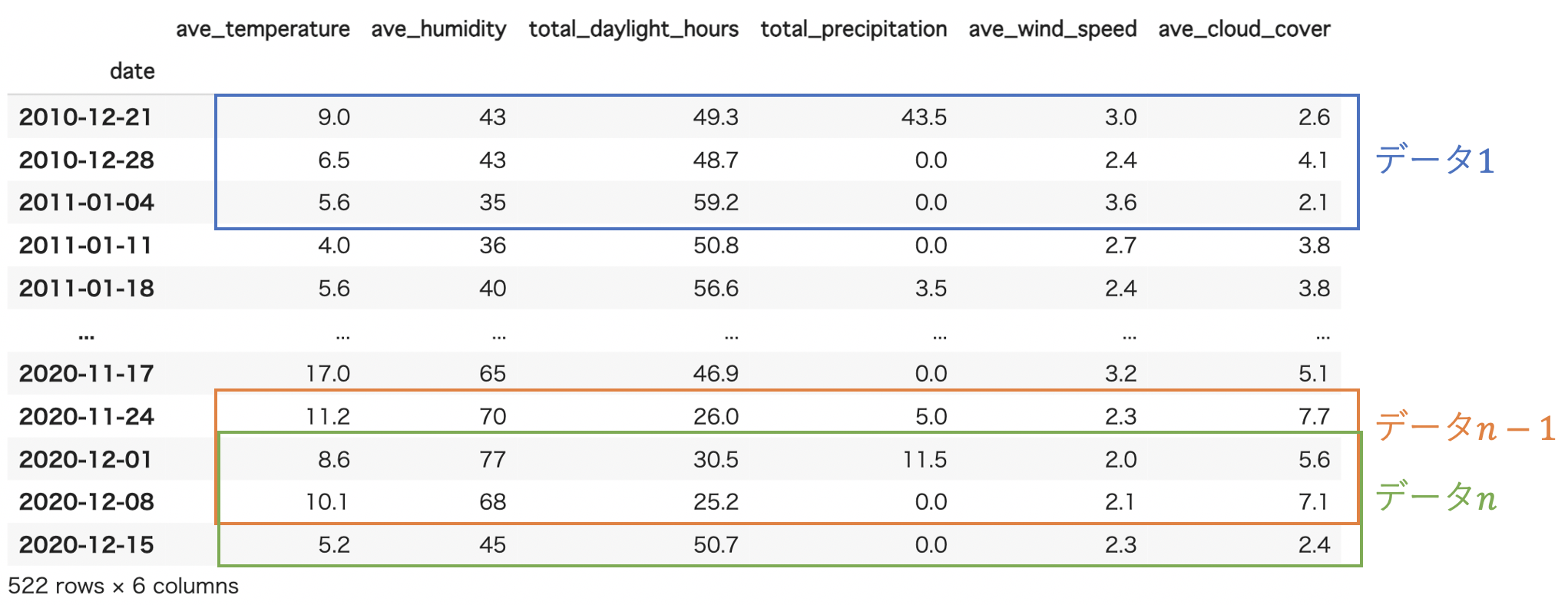
LSTMを多変量データで学習させるとき、データは [サンプル数, ルックバック数, 変数数] という形式でないといけません(超重要!)。
ここで、ルックバック数とは**「過去何回分のデータを1つのデータとするか」を意味します。
例えば、以下の図だとルックバック数は「3」**となります(3週分のデータを1つのデータとするため)。
実際にデータセットを作成するコードは以下のようになります。
# ルックバック数
look_back = 25
# データ数
sample_size = len(df) - look_back
# 予測に用いる期間
past_size = int(sample_size*0.8)
future_size = sample_size - past_size +1
# データセットを作る関数
def make_dataset(raw_data, look_back=25):
_X = []
_y = []
for i in range(len(raw_data) - look_back):
_X.append(raw_data[i : i + look_back])
_y.append(raw_data[i + look_back])
_X = np.array(_X).reshape(len(_X), look_back, 1)
_y = np.array(_y).reshape(len(_y), 1)
return _X, _y
作成した関数を用いてデータセットを作成します。また、データの正規化も行います。
今回は風速データは用いませんでした。
from sklearn import preprocessing
columns = list(df.columns)
del columns[0]
# 最小0、最大1に正規化
Xs = []
for i in range(len(columns)):
Xs.append(preprocessing.minmax_scale(df[columns[i]]))
Xs = np.array(Xs)
# 各数値データを作成
X_tmpr, y_tmpr = make_dataset(Xs[0], look_back=look_back)
X_humid, y_humid = make_dataset(Xs[1], look_back=look_back)
X_dlh, y_dlh = make_dataset(Xs[2], look_back=look_back)
X_prec, y_prec = make_dataset(Xs[3], look_back=look_back)
X_cloud, y_cloud = make_dataset(Xs[4], look_back=look_back)
# 多変量LSTMに対応するために各データを結合
X_con = np.concatenate([X_tmpr, X_humid, X_dlh, X_prec, X_cloud], axis=2)
X = X_con
y = y_cloud
# データを過去分(訓練に用いる分)と未来分(未来の予測に用いる分)に分割
X_past = X[:past_size]
X_future = X[past_size-1:]
y_past = y[:past_size]
y_future = y[past_size-1:]
# 訓練データを定義
X_train = X_past
y_train = y_past
多変量LSTMモデル
それでは、作成したデータを用いて実際にLSTMで学習と予測を行います。
モデルの作成
LSTMモデルを作ります。関数で定義すると学習済みモデルの読み込みをする際などでも便利です。慣れている方はクラスを使っても良いと思います。
import tensorflow as tf
from tensorflow.keras.layers import Input, LSTM, Dense, BatchNormalization
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import SGD, Adam
# LSTMモデルを作成する関数
def create_LSTM_model():
input = Input(shape=(np.array(X_train).shape[1], np.array(X_train).shape[2]))
x = LSTM(64, return_sequences=True)(input)
x = BatchNormalization()(x)
x = LSTM(64)(x)
output = Dense(1, activation='relu')(x)
model = Model(input, output)
return model
model = create_LSTM_model()
model.summary()
model.compile(optimizer=Adam(learning_rate=0.0001), loss='mean_squared_error')
モデルの学習
それでは、実際にモデルを学習させましょう。
history = model.fit(X_train, y_train, epochs=200, batch_size=64, verbose=1)
予測結果の確認
学習が終わったらモデルに予測させます。
predictions = model.predict(X_past)
future_predictions = model.predict(X_future)
予測結果を表示しましょう。
plt.figure(figsize=(18, 9))
plt.plot(df['date'][look_back:], y, color="b", label="true_cloud_cover")
plt.plot(df['date'][look_back:look_back + past_size], predictions, color="r", linestyle="dashed", label="prediction")
plt.plot(df['date'][-future_size:], future_predictions, color="g", linestyle="dashed", label="future_predisction")
plt.legend()
plt.show()
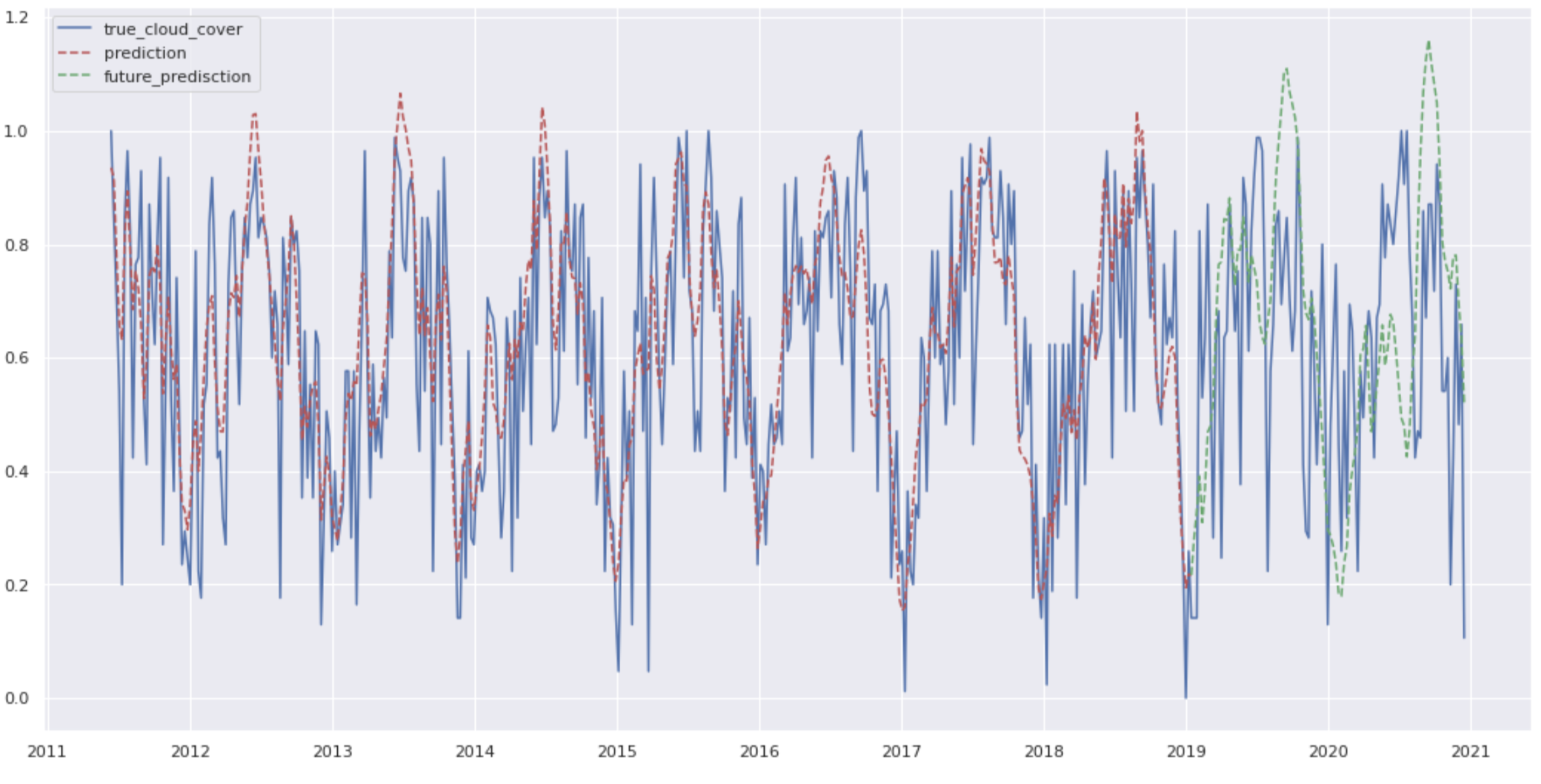
以下が予測結果の図です。やはり訓練に使用していない未来の予測部分(緑色の線)はそこそこの精度で終わってしまっているようですね……。まあ、今回はこんなところで許してやりましょう。
おわりに
TensorFlow 2.x での時系列データに対する多変量LSTMの実装と解説を行いました。訓練データとテストデータを分けていなかったりとガバガバな部分もありますが、何かの参考になれば嬉しいです。