本エントリーはPostgreSQL Advent Calendar 2023のシリーズ2の11日目です
はじめに
PostgreSQL Advent Calendarへの投稿、5年目になりました
今年は本業がかなり忙しく、PostgreSQLアンカンファレンスにもなかなか参加できず、ましてや何かをOUTPUTする時間の確保も難しい状況でした
PostgreSQL Conference Japan 2023 には参加しようと段取りしてましたが、急遽体調不良でキャンセルすることに![]()
![]()
体調管理は大事です!いつどこで何が起きるか?はわからないものです。
継続は力なり。でアドベントカレンダーには投稿しよう!と思ったのも遅く、すでに満席状態。シリーズ2を作って頂きこの度の投稿に至ります。
今年のトピックのAlloyDB AI や pgVectorについては多くの方が投稿されていますので、初心に帰り、Cloud SQL を起動してみます。
本記事のテーマ
Google Cloud コンソールのSQLサービスのメニューに遷移すると、「ご利用開始の手順」が記載されています。
その手順に従って、進めて行きます。
前回の投稿(2020/12/17)からの差分をピックアップしていきたいと思います。
※2023/12/09時点の記事です
本題
ご利用開始の手順
- インスタンスの作成
データベース エンジンと初期構成を選択する - ネットワークを設定して接続する
Cloud SQL Proxy などのネットワーク セキュリティ オプションを確認します。次に、クラウド サービスまたはローカルマシンに接続します。

今回はプライベートIPのみ設定します - データを取り込む
Cloud Storage からインポートするか、データベースの移行を使用します。
今回はデータインポートは行わないです
調理します!
- インスタンスの作成
「インスタンスを作成」ボタンをポチります。
日本語ドキュメントだと、利用できるバージョンは次のとおりです
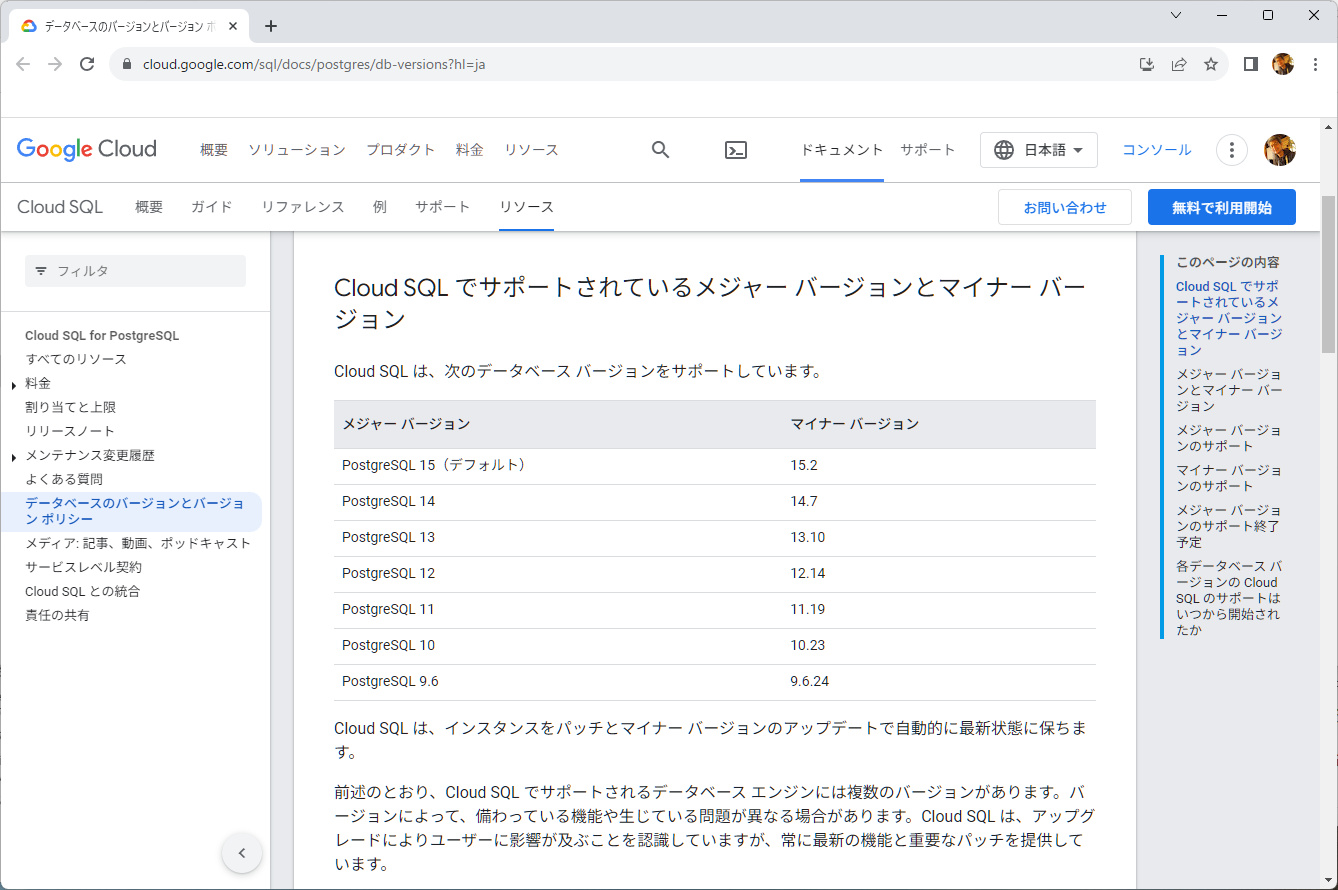
また、各バージョンの利用開始日は次の通りです
| CloudSQLの利用開始日 | PostgreSQLのリリース日 | |
|---|---|---|
| PostgreSQL 16 | 2023-09-14 | |
| PostgreSQL 15 | 2023/05/24 | 2022-10-13 |
| PostgreSQL 14 | 2021/11/11 | 2021-09-30 |
| PostgreSQL 13 | 2020/11/05 | 2020-09-24 |
| PostgreSQL 12 | 2020/05/21 | 2019-10-03 |
| PostgreSQL 11 | 2019/09/27 | 2018-10-18 |
| PostgreSQL 10 | 2020/03/27 | 2017-10-05 |
| PostgreSQL 9.6 | 2018/04/01 | 2016-09-29 |
データベース エンジンの選択は、「PostgreSQL を選択」し、PostgreSQL インスタンスの作成画面に移ります

- インスタンスID
- 管理ユーザ postgres のパスワード
- データベースのバージョン
を設定します
前回の投稿では、エディションはありませんでした。
Cloud SQL のエディションによって、選択できるデータベースのバージョンが変わります

Enterprise PLUSは最新版から2バージョンが選択できます

Enterprise は、利用できるすべてのバージョンが選択できます

エディションごとにプリセットが選択できるようになっています
本番環境プリセットを比較してみました。

今回は(課金も怖いので)Enterprise エディションで、サンドボックスプリセットを選択します。
- リージョンとゾーンを設定します。
アイオワから東京に変更します


以前から日本は割高ですが、円安もあって更に割高感がマシマシ
- 可用性
シングルゾーンにします - インスタンスのカスタマイズ
マシンの構成、ストレージタイプは、そのままにします - 接続設定
パブリックIPは割り当てず、VPC内のみで確認しようと思います

- データの保護
- メンテナンス
- フラグ(データベースパラメータ)
は、標準設定とします

インスタンス作成前に費用内訳(概算)が確認できます

ん~
サンドボックスと言いながらも、1日650円位かかる。
もたもた1週間かけてると、4,550円。個人で負担するには高いなぁ。
インスタンス作成ボタンを押します
デプロイされます
利用できる拡張機能ですが、このあたりのドキュメント
から確認できます
その他の拡張機能
にいました! pgVector !!!
0.5.0が使用できる見たいです

デプロイされました。7分くらいかかりました


実食!お味はいかが?(接続確認)
プライベートIP構成だと、CLOUD SHELLから簡単には利用できないです![]()
Cloud SQL のプライベートIP と パブリックIPの違い
今回の検証期間で、公式ドキュメントを見つけられなかったのですが、
- パブリックIPは、外部アクセスできる(グローバルIPをマッピングできる)VPC内のIPアドレス
- プライベートIPは、プロジェクト内に定義されるVPCとは別のGoogle Cloud が管理するVPC内のIPアドレス
のようです。
確認環境構築
今回の接続確認では、プロジェクト内VPCでGCEを1インスタンス立ち上げて確認します
CloudSQLへプライベートIPでアクセスできるように、VPCネットワークの設定で、VPCネットワークピアリングとプライベートサービスアクセスの設定を行っておきます。
接続確認用なので、GCEインスタンスは可能な限り小さなインスタンスにします(課金!)

デプロイが終わったら、ブラウザSSHでサーバ接続します
psqlクライアントをインストールします
sudo apt install -y postgresql-client
tail /var/log/apt/history.log
psql のバージョン確認
psql --version

事前検証時にpsqlは導入済みなんですけどね
検証作業
psql "host=xx.xx.xx.xx user=postgres"
で接続します。
アドレスは、Cloud SQL インスタンス情報に表示されている プライベートIPアドレス を指定します

\l でデータベース一覧を確認(ページャが入っちゃうので別画面コピー)

接続できました!![]()
デザートをお付けします(追加の確認作業)
旬なものが必要ですよね
Google Cloud blog (2023年7月13日) が気になっていたんですよね。
合間を見つけてはpgVectorが何者なのか?をググったり、chatGPTってみたり、google bard先生にご指南を受けたりしてましたが、全然理解できない。。。ポンコツです
環境作ったので、とりあえずコピペで実行してみます
word2vecとかでサンプルデータを作っても良かったのですが、vector型の確認が目的ですので、それらしいデータで確認します
こちらのjwsan-2145を利用させていただきました
テーブル定義
CREATE TABLE vitem (
pairid text PRIMARY KEY,
word1 text,
word2 text,
embedding vector(6)
)
特にエラーは出ませんでした

1件だけ追加し検索してみて、特に問題はなさそうですので、再作成して全件登録してみます

色々エラーは出てますが、リアリティがあるのでそのまま添付します
テストデータをINSERTします
確認方法ですが
心地よい+楽しいのベクトルデータ?を指定してCOS類似値(<=>)で検索しました
SELECT * FROM vitem WHERE pairid = 'p0107';
pairid | word1 | word2 | embedding
--------+----------+--------+-------------------------
p0107 | 心地良い | 楽しい | [3,3.44,4.48,180,130,0]
(1 row)
なんか結果が返却されましたので、動作としては問題なさそうです
postgres=> SELECT *, embedding <-> '[3,3.44,4.48,180,130,0]' as cossim
FROM vitem
ORDER BY embedding <-> '[3,3.44,4.48,180,130,0]'
LIMIT 5;
pairid | word1 | word2 | embedding | cossim
--------+----------+------------+-------------------------+--------------------
p0107 | 心地良い | 楽しい | [3,3.44,4.48,180,130,0] | 0
p0493 | 入れる | 差し込む | [2,3.77,4.38,180,130,0] | 1.0577806679290358
p0152 | 煩い | 騒々しい | [3,2.94,3.7,180,130,1] | 1.3632314066259898
p0137 | 尊い | 恐れ多い | [3,2.67,3.86,180,130,1] | 1.4061650568420978
p0289 | 交ぜる | 掻き混ぜる | [2,3.69,4.2,180,130,1] | 1.4631815113102964
(5 rows)
正しいのか?はデータの準備自体があっているのか?がわかっていなので、よくわかんないです。
期待したのは、心地よいと楽しいに類似するキーワードが出てくると思ってました(そんなに甘くない世界)
ベクトルとして指定する値がここじゃないのかもしれませんし、そもそも値が大きすぎる気もしますし。

最後に
- 環境構築は頻繁に行うものではないので、見ることも少ないと思いますが、提供サービスの変化によりポチる前の確認・検討事項も変化します。
- デプロイ直前でやめてしまえば、環境構築時に必要な情報は確認できそうです
- クライアント端末パソコンの性能価格比も向上し、クラウドのインスタンスを起動しなくても、dockerやpostgreSQL WASM で確認が行えるようになっています
pgVectorの使い方はよくわかんない(勉強不足)
- クラウド外部への通信料(データ可搬コスト)を低減させベクトル解析や近似検索を行えるようになる?
- 近似検索は膨大な量データになるとマシンスペックが必要になる?
最後までお読みいただき、ありがとうございます。少しでもお役に立てれば幸いです。