やったこと
2021年現在、__Google Cloud Platform (GCP)のAutoMLやClarifaiにおいて、「○○が映っているシーン」が取り扱う動画ファイルに含まれる場合、そのシーンが登場するフレームは、動画再生後、何分何秒後から何分何秒後までのフレームなのか__を、__動画を再生せずに確認__できる機能が提供されています。
この記事では、GCPやClarifaiが提供している、__このような機能の自作__を試みてみます。
本記事は、その最初の一歩です。
具体的には、YOLOv5に、動画MP4ファイルの物体検出をやらせたときに、Terminalに出力される解析ログを使います。
解析ログには、動画の何コマ目のフレームに、どのオブジェクトが物体検出されたのかが書かれています。
このログデータをTerminal上でテキストファイルにリダイレクト出力して、そのテキストファイルをテキスト解析することで、動画内の「○○が映っているシーン」が、何フレーム目(何コマ目)なのかを、検索してみました。
今後の課題としては、GCPやClarifaiのようなコンソールに、次のような画面を描画してみたいと思います。
- 特定の物体が、何フレーム目に登場するのかを時系列順に表示するバー
- 縦軸: 各物体の認識確信度(Confidence)の大きさを縦軸、横軸: 動画の各フレームのコマ番号(動画内でのコマの出現位置)の画面
それでは、まず最初に、GCPとClarifaiで提供されている、_「○○が映っているシーン」が動画ファイルのどのフレーム(コマ)に存在するのかを、動画を再生せずに確認__できる機能について、見ていきます。
Google Cloud Platform: AutoML Video Intelligence
GCPには、AutoMLとGoogle Cloud Video Intelligenceの2種類があります。
前者は、自前のデータセットで、任意の物体を画像認識(検出)できるように、動画解析モデルを学習させることができます。
後者は、Googleが事前に学習済みの動画解析モデルを利用(モデル推論)するだけの利用形態です。そのため、Googleが予めモデルに学習させた物体しか、認識(検出)することはできません。
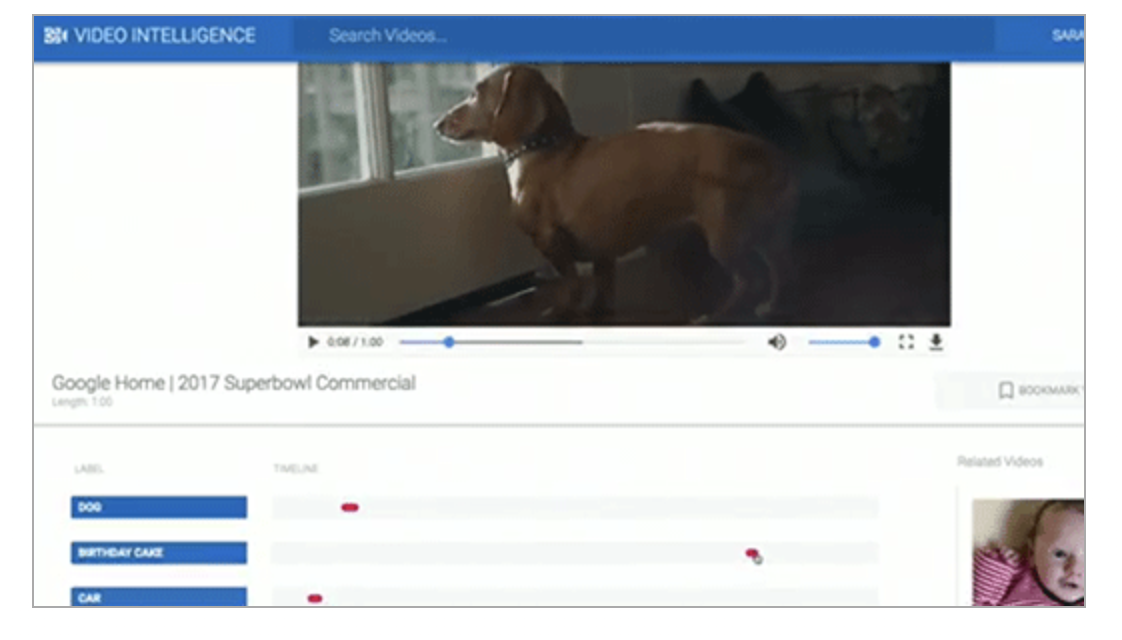
Video Intelligence APIのライブデモでは、家の部屋、街角、犬、車庫などさまざまなシーンが収められた1本の動画をVideo Intelligence APIで分析。動画のどのシーンに何が映っているのかが示されました。
この画面では、動画の下に並ぶ青地のバーに「DOG」「BIRTHDAY CAKE」「CAR」など、動画に映っているエンティティの名称が並び、その横の赤い印は、動画のなかのどの部分にそのエンティティが映っているかを示しています。
赤い部分をクリックすると、動画の該当部分が再生され、そのエンティティが映っているかどうかが確認できます。
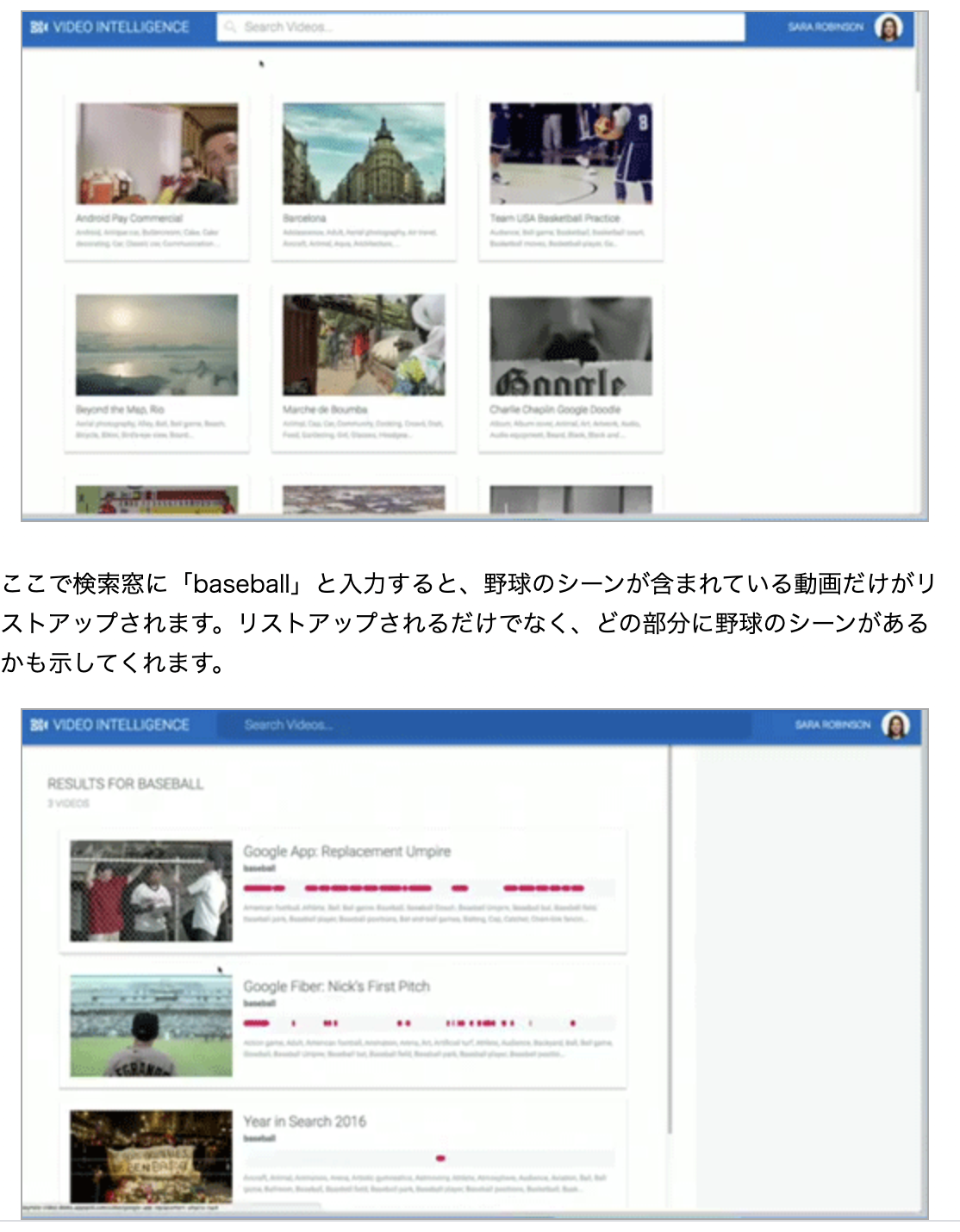
3本目に示された動画のように、全体のほんの一部にだけ野球のシーンがある動画もリストアップされます。いままで動画を何時間も見て人間が判断してきたことが、このAPIでわずか数秒でできるようになるのです。
Video Intelligence APIは今日から利用可能とのこと。
Clarifai
また、Clarifaiという企業が開放しているAPIでも、動画ファイルの中身を次のように可視化できるみたいです。
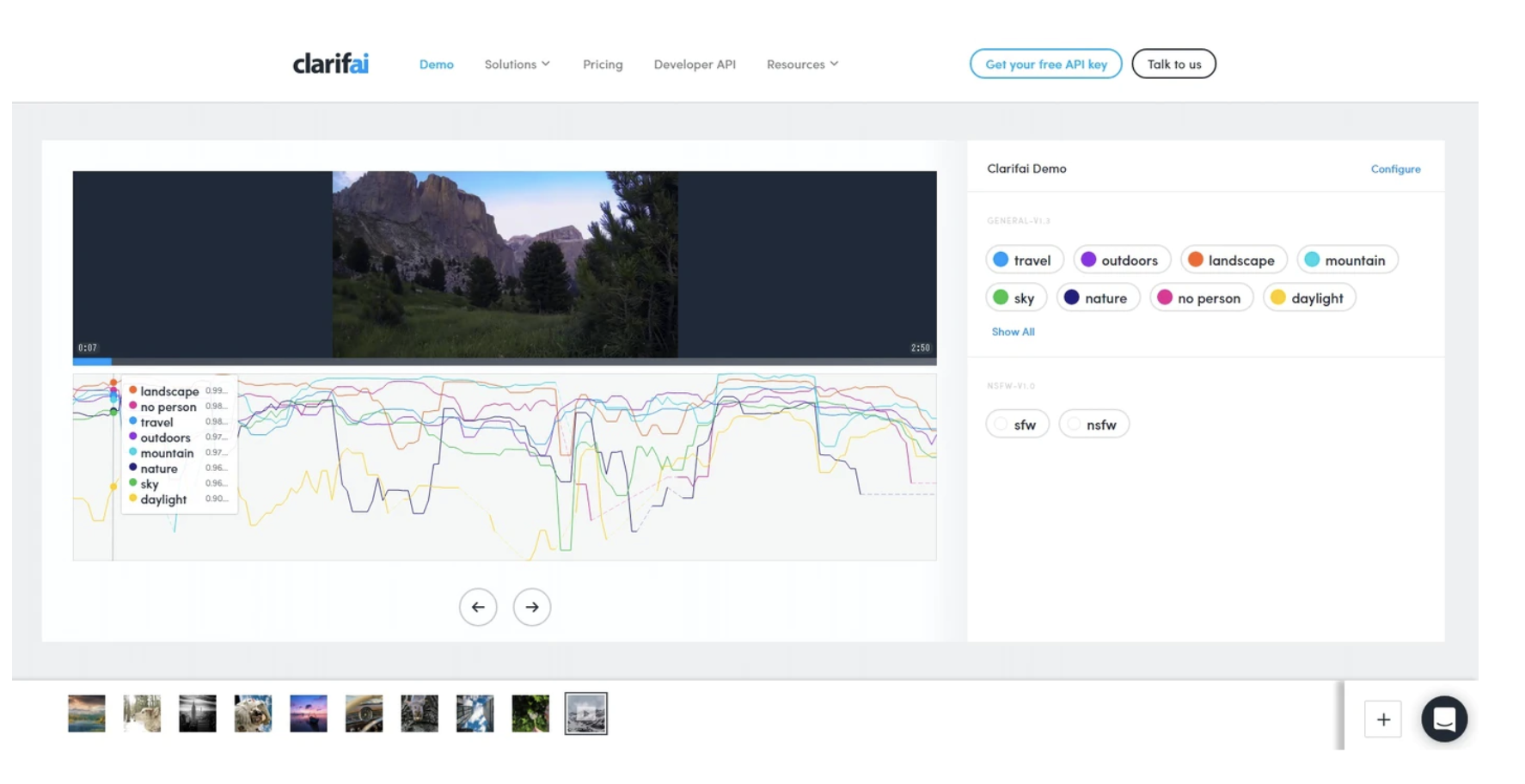
特定シーンの動画内検索: 商用ニーズはあるか?
視聴者が指定したキーワードに合致するシーンを動画内検索で探し出して、見つかったフレームから頭出し再生する機能は、10年前に商用化の事例がありました。
__2011年にPanasonicから販売された「MeMORA」__です。
しかし当時は、どのフレームにどのようなシーンが収められているのかを、フレームを人間が肉眼で見て、人力で手入力していたとか。ユーザは人力で作成されたデータベースに、検索クエリを発行する建付けだったみたいです。
MeMORAの最大の特徴は、非常に詳細な番組情報を用意し、これをDIGAの録画情報と紐づけることで、DIGA内の番組の、好みの場所から再生を開始させられる「再生指示」機能だ。同社では「最新のDIGAは4番組同時録画が可能になり、記録容量も増えるなど、以前に比べてHDDに大量の録画番組が蓄積される傾向が強まっている。録り貯めた番組の関連情報を提供することでテレビ番組の価値を向上させ、視聴につなげたい」と説明している。
パナソニックと提携した会社が、番組の「シーン情報」を人力で入力。本編なのかCMなのか、どのようなシーンか、誰が出ていたかといったデータを時間情報と組み合わせ、番組関連情報として蓄積していく。このデータをもとにして、録画した番組の詳細情報が一覧表示できるほか、任意の方法で検索することも可能。好みのシーンを一覧画面や検索結果から見つけたら、ウェブサイトからMeMORAのサーバを経由し、DIGAへ該当シーンから再生するよう指示を送ることができる。
シーン検索は「キーワード」「ジャンル」「検索対象が番組かCMか」といった項目のほか、検索対象の期間や「シーン名/シーン詳細/出演者」といった検索タイプも組み合わせて行うことができる。たとえば「音楽番組で放映された、AKB48が出ているCM」のみを検索したり、「録画番組全体から長友選手に関するシーンだけをピックアップする」といった使い方ができる。前述の再生指示と組み合わせると、検索結果から見たいシーンをすぐに視聴することも可能になる。
( 省略 )
シーン情報は人力で入力しているため、本編のシーン情報については番組放送後およそ2時間後に付与され、利用できるようになる。CM情報は放送後6時間を目安に付与される。
なお、番組関連情報検索などのためのデータベースは、録画後にパートナー企業が人力で分類、タグ付けなどを行なっているため、番組終了の2時間後ごろを目途に詳細データが利用可能になる。パートナー企業は非公開。
また、全番組に対応している放送局は首都圏のNHK総合と民放キー局で、その他の放送局は全国放送の番組にのみ対応する。CM情報に対応しているのは、首都圏の民放キー局のみ。
シーン登録ワード機能も搭載。事前にキーワードを登録しておくことで、DIGAで録画した番組の関連情報から登録したキーワードを含むシーンを自動で検索。メールアドレスを登録しておけば、メールで検索結果を通知してくれる。対応DIGAではメールに記されたURLをクリックしてミモーラにアクセスして、簡単にDIGAに再生指示が行なえる。
YOLOv5で動画のフレーム検索機能を自作してみる
それでは、GCPやClarifaiで提供されている、__「○○が映っているシーン」が動画ファイルのどのフレーム(コマ)に存在するのかを、動画を再生せずに確認__できる機能の__自作を試みて__みます。
本記事は、その最初の一歩です。
具体的には、YOLOv5に、動画MP4ファイルの物体検出をやらせたときに、Terminalに出力される解析ログを使います。
解析ログには、動画の何コマ目のフレームに、どのオブジェクトが物体検出されたのかが書かれています。
このログデータをTerminal上でテキストファイルにリダイレクト出力して、そのテキストファイルをテキスト解析することで、動画内の「○○が映っているシーン」が、何フレーム目(何コマ目)なのかを、検索してみました。
今後の課題としては、GCPやClarifaiのようなコンソールに、次のような画面を描画してみたいと思います。
- 特定の物体が、何フレーム目に登場するのかを時系列順に表示するバー
- 縦軸: 各物体の認識確信度(Confidence)の大きさを縦軸、横軸: 動画の各フレームのコマ番号(動画内でのコマの出現位置)の画面
それでは、YOLOv5を使って、次の課題に取り組んでみます。
「探している物体が、動画の何フレーム目に登場するのかを、調べる」
Step 1: YOLOv5の動画解析ログと、各フレームの物体認識結果を見てみる
( YOLOv5の出力メッセージ )
video 1/1 (2013/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 10 persons, 1 tie, 2 cups, 1 chair, Done. (0.308s)
video 1/1 (2013/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 10 persons, 1 tie, 2 cups, 1 chair, Done. (0.308s)
( YOLOv5が吐き出した動画の「2013」フレーム目 )
( 考察 )
YOLOv5が作成してくれた、検出物体(の矩形領域を)がオリジナルの画像の上に、重畳表示された動画を、肉眼で再生するまでもなく、YOLOv5が吐き出したメッセージを見ることで、2013フレーム目に、次の物体が登場することを知れることが、確認できました。
- 10 persons
- 1 tie
- 2 cups
- 1 chair
このログファイルをPython側で、jsonファイルに変換して、No-SQLのDBや、RDBMSのDBに格納することで、意中の「○○」が「映っているシーン」を、DBにクエリを発行して検索できるアプリケーションを、作ることができそうです。
ちなみに、2013フレーム目に登場する「マイク」を、YOLOv5は誤って「ネクタイ」と認識してしまっていますね。![]() このあたり、認識精度の向上が鍵になりそうです。
このあたり、認識精度の向上が鍵になりそうです。
まあ今回は、学習済みのモデルを、手元の学習データで追加学習することなく、そのまま使ってみましたので、あまり文句は言わないようにしておきましょう。
Step 2: 動画解析ログをテキスト検索して、任意の物体が検出されたフレームを探し出す
( ログファイルのテキスト解析を自動スクリプト化 )
スクリプトファイル名:logfile_analyzer.py
- 引数1: 探したい物体カテゴリ名
- 引数2: YOLOv5が吐き出したログファイルのパス
import argparse
import re
# ログファイル名をコマンドライン引数から受け取る
parser = argparse.ArgumentParser(description='') #
parser.add_argument('log_file_name')
parser.add_argument('seeking_object_name')
args = parser.parse_args()
log_file = args.log_file_name
seeking_object_name = movie_file = args.seeking_object_name
print('次のログファイルを解析します。 :' + log_file)
print('次の物体を探します。 :' + seeking_object_name)
f = open("trump_mp4_log.txt", "r", encoding="utf-8")
while True:
line = f.readline()
if line:
if seeking_object_name in line:
spanned_text = re.findall("(?<=\().+?(?=\))", line)
temp = str(spanned_text[0]).split(',')
frame_num = temp[0]
detected_objects = re.findall("(?<=640).+?(?=, Done)", line)
print("フレーム番号: " + str(frame_num))
print("検出された物: " + str(detected_objects))
print("\n-------------------------------------\n")
else:
pass
else:
break
( 実行結果 )
electron@diynoMacBook-Pro yolov5 % python3 logfile_analyzer.py trump_mp4_log.txt cup > result.txt
electron@diynoMacBook-Pro yolov5 %
electron@diynoMacBook-Pro yolov5 % wc -l result.txt
16682 result.txt
electron@diynoMacBook-Pro yolov5 %
electron@diynoMacBook-Pro yolov5 % head result.txt
次のログファイルを解析します。 :trump_mp4_log.txt
次の物体を探します。 :cup
フレーム番号: 240/12306
検出された物: [' 6 persons, 1 cup']
-------------------------------------
フレーム番号: 457/12306
検出された物: [' 6 persons, 1 tie, 1 cup']
electron@diynoMacBook-Pro yolov5 %
electron@diynoMacBook-Pro yolov5 % tail result.txt
フレーム番号: 12193/12306
検出された物: [' 1 person, 1 tie, 1 cup, 1 tv']
-------------------------------------
フレーム番号: 12194/12306
検出された物: [' 1 person, 1 tie, 1 cup, 1 tv']
-------------------------------------
electron@diynoMacBook-Pro yolov5 %
自動処理成功です。
以上がこの記事の概要と結論です。
それでは、以下、今回行ったことを記述していきます。
問題意識
次のサイトの公開者さんと同じ問題意識です。
そうです、興味を寄せている動画の中で、「○○が映っているシーン」を、SQLライクにクエリ検索したいんです。
YOLOv3では、やりたいことはほとんど標準のコマンドと引数で実現できますが、「もうちょっとこうしたいんだけどなぁ」という場面もあります。
今回のゴールは、「動画のフレーム番号に対応した、検出結果のログを取り出したい(=検索で使いたいから)」です。
そのためには、次のようなことが出来ないといけません。
####その2:動画検出のログファイル出力機能を追加する
方針:動画のフレーム番号(頭からの連番)と検出結果をjson形式のログに出力する。
・オプション"-prefix"か"-out_filename"を指定してるときだけjsonファイルを出力
・出力先は"-prefix"か"-out_filename"の指定先と同じ(両方指定しているときは"-prefix"の方に出>力)
・ファイル名は"result.json"で固定
・コマンドプロンプトへのログ出力で画像ファイル名(または連番)を表示する修正箇所:demo.c 206行目あたり~352行目まで
__前回の記事__で、動画ファイル(MP4)のリアルタイム物体認識を動かして成功しましたが、出力されるフレームの画像に書き込まれた次の情報を、コードのどの変数をprintしたら、標準出力やテキストファイルに描き出せるのかが、まだよくわかっていません。
- フレーム番号
- 動画再生後の経過時間(フレームレートによって異なる)
- 検出された物体のオブジェクト名(複数の場合あり)
- 各オブジェクトの認識確信度合
そこで今回は、YOLOv5の物体認識器に、動画ファイル(MP4)を食べさせたときに、Terminalに吐き出されるメッセージを使って、何フレーム目のシーンに、(YOLOv5を信じる限り)どの物体が映り込んでいるのかを、確認できるか試してみました。
YOLOv5がデフォルトで検出できる(学習済みの)物体は、次に限られています。
person, bicycle, car, motorbike, aeroplane, bus, train, truck, boat
traffic light, fire hydrant, stop sign, parking meter, bench
cat, dog, horse, sheep, cow, elephant, bear, zebra, giraffe
backpack, umbrella, handbag, tie, suitcase, frisbee, skis, snowboard, sports ball, kite, baseball bat, baseball glove, skateboard, surfboard, tennis racket
bottle, wine glass, cup, fork, knife, spoon, bowl
banana, apple, sandwich, orange, broccoli, carrot, hot dog, pizza, donut, cake
chair, sofa, pottedplant, bed, diningtable, toilet, tvmonitor, laptop, mouse, remote, keyboard, cell phone, microwave, oven, toaster, sink, refrigerator, book, clock, vase, scissors, teddy bear, hair drier, toothbrush
そのため、上述のlogfile_analyzer.pyに、次の行を追記する必要がありそうです。
yolov5_detection_obj_list = [person, bicycle, car, motorbike, aeroplane, bus, train, truck, boat
traffic light, fire hydrant, stop sign, parking meter, bench
cat, dog, horse, sheep, cow, elephant, bear, zebra, giraffe
backpack, umbrella, handbag, tie, suitcase, frisbee, skis, snowboard, sports ball, kite, baseball bat, baseball glove, skateboard, surfboard, tennis racket
bottle, wine glass, cup, fork, knife, spoon, bowl
banana, apple, sandwich, orange, broccoli, carrot, hot dog, pizza, donut, cake
chair, sofa, pottedplant, bed, diningtable, toilet, tvmonitor, laptop, mouse, remote, keyboard, cell phone, microwave, oven, toaster, sink, refrigerator, book, clock, vase, scissors, teddy bear, hair drier, toothbrush]
if seeking_object_name not in yolov5_detection_obj_list:
print("¥nその物体は検出できません。YOLOv5の追加学習が必要です。¥n")
break
else:
YOLOv5は、比較的容易に、自分が認識させたい物体を学習データとして与えて、物体検出器に、その物体を認識するよう学ばせることができます。
動画から検出したいと思う物体の画像をたくさん学ばせると、用途に即したYOLOv5モデルが手元に出来上がるのではないでしょうか。
例えば今回は、人物は一律、__"Person"__というカテゴリ名で検出されましたが、贔屓にしている俳優や著名人を認識できるようにYOLOv5を追加学習すると、ドラマや映画の動画の中で、その人物が登場するシーンだけを、静止画ファイルとして切り出すことができるはずです。
さらに、自分の子供の画像を学習させれば、学校の運動会を撮影した動画ファイルから、我が子が映っているシーンだけを要領よく見て、家族で楽しむ、なんてこともできるかもしれません。
解析対象の動画ファイル
__前回の記事__同様に、今回も、YouTubeにある次の動画を、題材に選びました。
動画ファイル(MP4ファイル)のフレーム数を確認
electron@diynoMacBook-Pro yolov5 % python3
Python 3.9.6 (default, Jun 29 2021, 06:20:32)
[Clang 12.0.0 (clang-1200.0.32.29)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import cv2
>>> import os
>>>
>>> cap = cv2.VideoCapture('trump.mp4')
>>> number = len(str(int(cap.get(cv2.CAP_PROP_FRAME_COUNT))))
>>> print(number)
5
>>> number = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
>>> print(number)
12306
>>>
( 参考 )
YOLOv5で、動画ファイルの物体検出を実行!
electron@diynoMacBook-Pro yolov5 % python3 detect.py --source trump.mp4
detect: weights=yolov5s.pt, source=trump.mp4, imgsz=640, conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs/detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False
YOLOv5 🚀 v5.0-288-g8ee9fd1 torch 1.9.0 CPU
Downloading https://github.com/ultralytics/yolov5/releases/download/v5.0/yolov5s.pt to yolov5s.pt...
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 14.1M/14.1M [00:00<00:00, 18.8MB/s]
Fusing layers...
/usr/local/lib/python3.9/site-packages/torch/nn/functional.py:718: UserWarning: Named tensors and all their associated APIs are an experimental feature and subject to change. Please do not use them for anything important until they are released as stable. (Triggered internally at ../c10/core/TensorImpl.h:1156.)
return torch.max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode)
Model Summary: 224 layers, 7266973 parameters, 0 gradients
video 1/1 (1/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 2 persons, Done. (0.222s)
video 1/1 (2/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 2 persons, Done. (0.198s)
video 1/1 (3/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 2 persons, Done. (0.198s)
video 1/1 (4/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 2 persons, Done. (0.200s)
video 1/1 (5/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 2 persons, Done. (0.203s)
video 1/1 (6/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 2 persons, Done. (0.197s)
video 1/1 (7/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 2 persons, Done. (0.203s)
^Z
zsh: suspended python3 detect.py --source trump.mp4
```
#### ログの出力先をTerminal(標準出力)ではなく、テキストファイルに向ける。
```
electron@diynoMacBook-Pro yolov5 % python3 detect.py --source trump.mp4 > trump_mp4_log.txt
YOLOv5 🚀 v5.0-288-g8ee9fd1 torch 1.9.0 CPU
Fusing layers...
/usr/local/lib/python3.9/site-packages/torch/nn/functional.py:718: UserWarning: Named tensors and all their associated APIs are an experimental feature and subject to change. Please do not use them for anything important until they are released as stable. (Triggered internally at ../c10/core/TensorImpl.h:1156.)
return torch.max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode)
Model Summary: 224 layers, 7266973 parameters, 0 gradients
electron@diynoMacBook-Pro yolov5 %
```
#### 別のTerminalを立ち上げて、定期的に、trump_mp4_log.txtの中身をチェック
```
electron@diynoMacBook-Pro ~ % cd Desktop/yolov5
electron@diynoMacBook-Pro yolov5 % ls
CONTRIBUTING.md README.md doraemon.mp4 models test.py trump_mp4_log.txt yolov5m.pt
Dockerfile data export.py requirements.txt train.py tutorial.ipynb yolov5s.pt
LICENSE detect.py hubconf.py runs trump.mp4 utils
electron@diynoMacBook-Pro yolov5 %
electron@diynoMacBook-Pro yolov5 % wc -l trump_mp4_log.txt
170 trump_mp4_log.txt
electron@diynoMacBook-Pro yolov5 %
electron@diynoMacBook-Pro yolov5 % wc -l trump_mp4_log.txt
254 trump_mp4_log.txt
electron@diynoMacBook-Pro yolov5 %
electron@diynoMacBook-Pro yolov5 % wc -l trump_mp4_log.txt
496 trump_mp4_log.txt
electron@diynoMacBook-Pro yolov5 %
electron@diynoMacBook-Pro yolov5 % head trump_mp4_log.txt
detect: weights=yolov5s.pt, source=trump.mp4, imgsz=640, conf_thres=0.25, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs/detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False
video 1/1 (1/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 2 persons, Done. (0.221s)
video 1/1 (2/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 2 persons, Done. (0.195s)
video 1/1 (3/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 2 persons, Done. (0.196s)
video 1/1 (4/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 2 persons, Done. (0.201s)
video 1/1 (5/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 2 persons, Done. (0.204s)
video 1/1 (6/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 2 persons, Done. (0.197s)
video 1/1 (7/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 2 persons, Done. (0.203s)
video 1/1 (8/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 2 persons, Done. (0.197s)
video 1/1 (9/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 2 persons, Done. (0.203s)
electron@diynoMacBook-Pro yolov5 %
```
```
electron@diynoMacBook-Pro yolov5 % tail trump_mp4_log.txt
video 1/1 (563/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 8 persons, 1 sports ball, 1 cell phone, Done. (0.208s)
video 1/1 (564/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 8 persons, 1 sports ball, 1 cell phone, Done. (0.196s)
video 1/1 (565/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 7 persons, 1 sports ball, 1 cell phone, Done. (0.205s)
video 1/1 (566/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 6 persons, 1 cell phone, Done. (0.196s)
video 1/1 (567/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 6 persons, 1 cell phone, Done. (0.199s)
video 1/1 (568/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 6 persons, 1 sports ball, 1 cell phone, Done. (0.195s)
video 1/1 (569/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 7 persons, 1 sports ball, 1 cell phone, Done. (0.201s)
video 1/1 (570/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 7 persons, 1 handbag, 1 sports ball, 2 cell phones, Done. (0.196s)
video 1/1 (571/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 7 persons, 1 handbag, 1 sports ball, 2 cell phones, Done. (0.200s)
video 1/1 (572/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 7 persons, 1 handbag, 2 cell phones, Done. (0.197s)
electron@diynoMacBook-Pro yolov5 %
```
```
electron@diynoMacBook-Pro yolov5 % tail trump_mp4_log.txt
video 1/1 (1554/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 7 persons, Done. (0.203s)
video 1/1 (1555/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 7 persons, Done. (0.208s)
video 1/1 (1556/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 9 persons, Done. (0.193s)
video 1/1 (1557/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 9 persons, Done. (0.199s)
video 1/1 (1558/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 8 persons, Done. (0.193s)
video 1/1 (1559/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 9 persons, Done. (0.201s)
video 1/1 (1560/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 9 persons, Done. (0.195s)
video 1/1 (1561/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 8 persons, Done. (0.206s)
video 1/1 (1562/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 8 persons, Done. (0.206s)
video 1/1 (1563/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 6 persons, Done. (0.212s)
electron@diynoMacBook-Pro yolov5 %
```
#### ( ログファイルに記録された情報 )
```
electron@diynoMacBook-Pro yolov5 % tail trump_mp4_log.txt
video 1/1 (2013/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 10 persons, 1 tie, 2 cups, 1 chair, Done. (0.308s)
video 1/1 (2014/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 9 persons, 1 tie, 2 cups, 1 chair, Done. (0.298s)
video 1/1 (2015/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 9 persons, 1 tie, 2 cups, 1 chair, Done. (0.311s)
video 1/1 (2016/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 10 persons, 1 tie, 2 cups, 1 chair, Done. (0.300s)
video 1/1 (2017/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 9 persons, 1 tie, 2 cups, 1 chair, Done. (0.307s)
video 1/1 (2018/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 9 persons, 1 tie, 2 cups, 1 chair, Done. (0.297s)
video 1/1 (2019/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 9 persons, 1 tie, 2 cups, 1 chair, Done. (0.307s)
video 1/1 (2020/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 9 persons, 1 tie, 2 cups, 1 chair, Done. (0.295s)
video 1/1 (2021/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 9 persons, 1 tie, 2 cups, 1 chair, 2 cell phones, Done. (0.304s)
video 1/1 (2022/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 9 persons, 2 cups, 1 chair, Done. (0.298s)
electron@diynoMacBook-Pro yolov5 %
```
```
electron@diynoMacBook-Pro yolov5 % wc -l trump_mp4_log.txt
11974 trump_mp4_log.txt
electron@diynoMacBook-Pro yolov5 % wc -l trump_mp4_log.txt
12059 trump_mp4_log.txt
electron@diynoMacBook-Pro yolov5 % wc -l trump_mp4_log.txt
12059 trump_mp4_log.txt
electron@diynoMacBook-Pro yolov5 % wc -l trump_mp4_log.txt
12059 trump_mp4_log.txt
electron@diynoMacBook-Pro yolov5 % wc -l trump_mp4_log.txt
12150 trump_mp4_log.txt
electron@diynoMacBook-Pro yolov5 % tail trump_mp4_log.txt
video 1/1 (12140/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 1 person, 1 tie, Done. (0.186s)
video 1/1 (12141/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 1 person, 1 tie, Done. (0.193s)
video 1/1 (12142/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 1 person, 1 tie, Done. (0.189s)
video 1/1 (12143/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 1 person, 1 tie, Done. (0.192s)
video 1/1 (12144/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 1 person, 1 tie, Done. (0.188s)
video 1/1 (12145/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 1 person, 1 tie, Done. (0.192s)
video 1/1 (12146/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 1 person, 1 tie, Done. (0.187s)
video 1/1 (12147/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 1 person, 1 tie, Done. (0.191s)
video 1/1 (12148/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 1 person, 1 tie, Done. (0.186s)
video 1/1 (12149/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 1 person, 1 tie, Done. (0.192s)
electron@diynoMacBook-Pro yolov5 %
```
```
lectron@diynoMacBook-Pro yolov5 % tail trump_mp4_log.txt
video 1/1 (12299/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 Done. (0.191s)
video 1/1 (12300/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 Done. (0.185s)
video 1/1 (12301/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 Done. (0.189s)
video 1/1 (12302/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 Done. (0.184s)
video 1/1 (12303/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 Done. (0.190s)
video 1/1 (12304/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 Done. (0.186s)
video 1/1 (12305/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 Done. (0.191s)
video 1/1 (12306/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 Done. (0.184s)
Results saved to runs/detect/exp3
Done. (4101.654s)
electron@diynoMacBook-Pro yolov5 %
```
### ログファイルと、動画の該当フレームとの内容照合
##### __( 参考 )__
- [Python, OpenCVで動画ファイルからフレームを切り出して保存](https://note.nkmk.me/python-opencv-video-to-still-image/)
上のサイトから、指定したフレーム番地(コマ番地)を、動画から静止画として切り出すPythonメソッドを拝借。
> ####任意の範囲のフレームを指定
>
>任意の範囲のフレームを静止画の画像ファイルとして切り出して保存するサンプルコード。
```Python:frame_extract_from_video.py
import cv2, os
def save_frame_range(video_path, start_frame, stop_frame, step_frame,
dir_path, basename, ext='jpg'):
cap = cv2.VideoCapture(video_path)
if not cap.isOpened():
return
os.makedirs(dir_path, exist_ok=True)
base_path = os.path.join(dir_path, basename)
digit = len(str(int(cap.get(cv2.CAP_PROP_FRAME_COUNT))))
for n in range(start_frame, stop_frame, step_frame):
cap.set(cv2.CAP_PROP_POS_FRAMES, n)
ret, frame = cap.read()
if ret:
cv2.imwrite('{}_{}.{}'.format(base_path, str(n).zfill(digit), ext), frame)
else:
return
```
__( 使い方 )__
```
save_frame_range('data/temp/sample_video.mp4', 200, 300, 10, 'data/temp/result_range', 'sample_video_img')
```
``` bash*Terminal
electron@diynoMacBook-Pro yolov5 % python3
Python 3.9.6 (default, Jun 29 2021, 06:20:32)
[Clang 12.0.0 (clang-1200.0.32.29)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> from frame_extract_from_video import *
>>>
>>> save_frame_range('trump.mp4', 2012, 2030, 1, 'frame_jpg/scene/', 'scene')
>>> quit()
electron@diynoMacBook-Pro yolov5 % ls
CONTRIBUTING.md data frame_jpg test.py utils
Dockerfile detect.py hubconf.py train.py yolov5m.pt
LICENSE doraemon.mp4 models trump.mp4 yolov5s.pt
README.md export.py requirements.txt trump_mp4_log.txt
__pycache__ frame_extract_from_video.py runs tutorial.ipynb
electron@diynoMacBook-Pro yolov5 % ls frame_jpg
scene
electron@diynoMacBook-Pro yolov5 % ls frame_jpg/scene
scene_02012.jpg scene_02014.jpg scene_02016.jpg scene_02018.jpg scene_02020.jpg scene_02022.jpg scene_02024.jpg scene_02026.jpg scene_02028.jpg
scene_02013.jpg scene_02015.jpg scene_02017.jpg scene_02019.jpg scene_02021.jpg scene_02023.jpg scene_02025.jpg scene_02027.jpg scene_02029.jpg
electron@diynoMacBook-Pro yolov5 %
```
##### 切り出された2012フレーム〜2030フレーム目までの画像

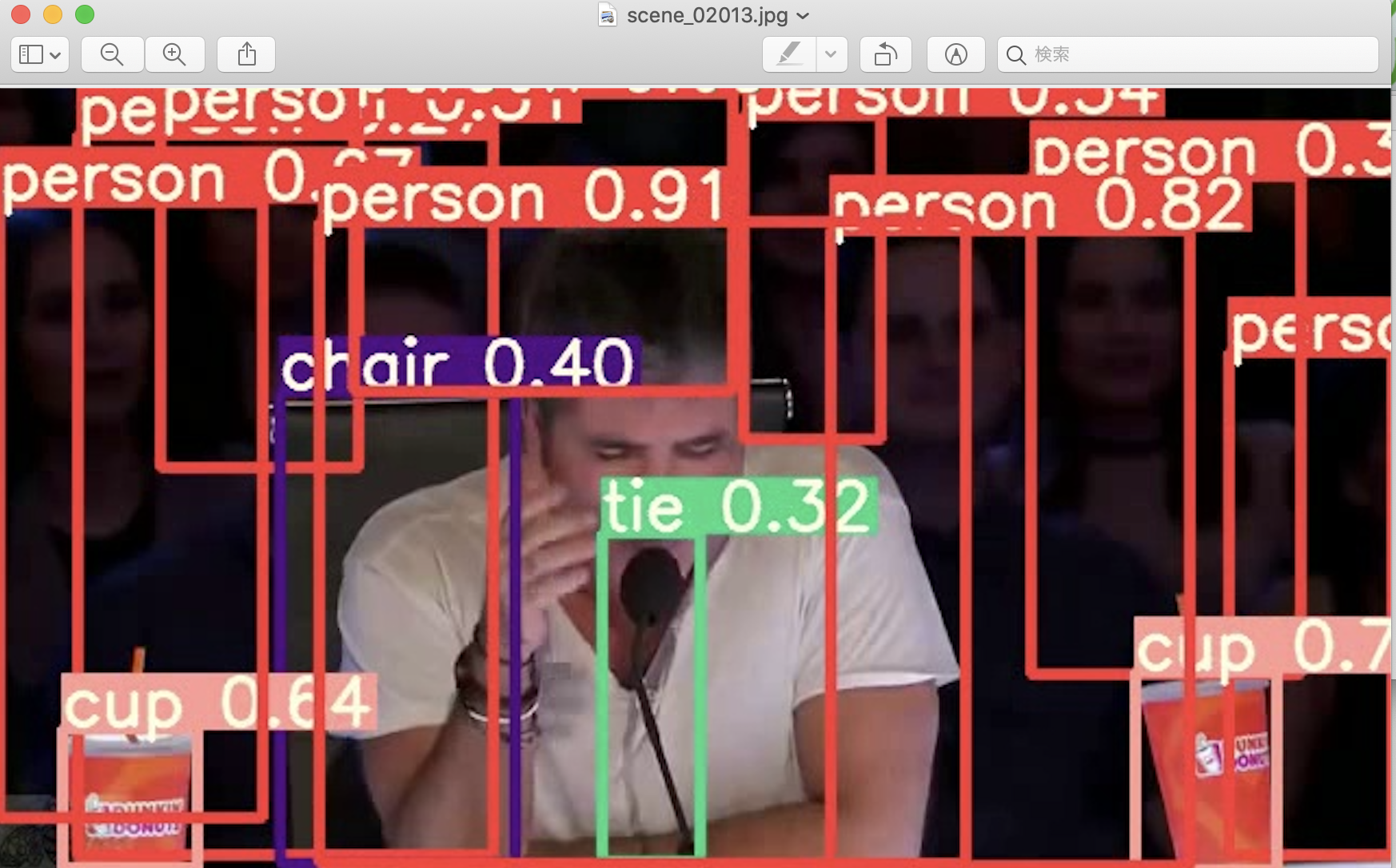
さて、ログファイルによると、2013フレーム(コマ)目のシーン(画像)には、次の物体が検出されたと、YOLOv5は言っています。
```text:trump_mp4_log.txt
electron@diynoMacBook-Pro yolov5 % tail trump_mp4_log.txt
video 1/1 (2013/12306) /Users/electron/Desktop/yolov5/trump.mp4: 384x640 10 persons, 1 tie, 2 cups, 1 chair, Done. (0.308s)
```
実際に切り出された2013フレーム目の画像を見てみましょう。

さて、どうでしょうか。
正面手前に1人の人物が大きく映り込んでいる他、背景に複数人の人物がいます。合計10名もいるでしょうか。
他に、ログファイルが語るように、次の物体の存在を認めることができます。
- __2 cups__
- __1 chair__
なお、この記事ですでに言及したように、以下は、マイクと取り違えていたようです。
- __1 tie__
### YOLOv5が出力した解析結果の動画ファイルをみてみる
```bash:Terminal
electron@diynoMacBook-Pro yolov5 % ls runs/detect/exp3
trump.mp4
electron@diynoMacBook-Pro yolov5 %
```



それぞれのフレームの中に、大人数の人物が検出されています。
それでは、今度はこの動画ファイルから、先ほどの2013フレーム目の画像を切り出してみます。
```
electron@diynoMacBook-Pro yolov5 % cp ../../../frame_extract_from_video.py ./
electron@diynoMacBook-Pro exp3 % ls
frame_extract_from_video.py trump.mp4
electron@diynoMacBook-Pro exp3 % python3
Python 3.9.6 (default, Jun 29 2021, 06:20:32)
[Clang 12.0.0 (clang-1200.0.32.29)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> from frame_extract_from_video import *
>>>
>>> save_frame_range('trump.mp4', 2012, 2030, 1, 'frame_jpg/scene/', 'scene')
>>> quit()
electron@diynoMacBook-Pro exp3 %
electron@diynoMacBook-Pro exp3 % ls frame_jpg/scene
scene_02012.jpg scene_02014.jpg scene_02016.jpg scene_02018.jpg scene_02020.jpg scene_02022.jpg scene_02024.jpg scene_02026.jpg scene_02028.jpg
scene_02013.jpg scene_02015.jpg scene_02017.jpg scene_02019.jpg scene_02021.jpg scene_02023.jpg scene_02025.jpg scene_02027.jpg scene_02029.jpg
electron@diynoMacBook-Pro exp3 %
```

##### __矩形抽出された*"person"*の(人)数を数えてみると、確かに、10個(人)、物体(人物)検出されているように見えます。"person"が折り重なっっているため、8〜10人のうち、どの数字が正しいのかは肉眼では判然としませんが。。。__

___
## 環境構築
ここからは、MacbookにYOLOv5を入れたときに行った、環境構築の様子を記載します。
```bash:Terminal
electron@diynoMacBook-Pro ~ % cd Desktop
electron@diynoMacBook-Pro Desktop % git clone
```
取得した資材のディレクトリ構成をみる。
```bash:Terminal
electron@diynoMacBook-Pro Desktop % cd yolov5
electron@diynoMacBook-Pro yolov5 % ls
CONTRIBUTING.md LICENSE data export.py models test.py tutorial.ipynb
Dockerfile README.md detect.py hubconf.py requirements.txt train.py utils
electron@diynoMacBook-Pro yolov5 %
```
今回使うMacbookは、Pythonはデフォルトで2.7系になる
```bash:Terminal
electron@diynoMacBook-Pro yolov5 % python --version
Python 2.7.16
electron@diynoMacBook-Pro yolov5 %
```
Python3と打ち込むと、Python3.9.6が起動する
```bash:Terminal
electron@diynoMacBook-Pro yolov5 % python3 --version
Python 3.9.6
electron@diynoMacBook-Pro yolov5 %
```
pip3 installして、requirements.txtに列挙されたPythonのモジュールを入れる
```bash:Terminal
electron@diynoMacBook-Pro yolov5 % pip3 install -U -r requirements.txt
・・・
Installing collected packages: opencv-python-headless
Successfully installed opencv-python-headless-4.5.3.56
electron@diynoMacBook-Pro yolov5 %
```
WebカメラでYOLOv5の動作チェック
Python3で動かさないと文法エラーになる
```bash:Terminal
electron@diynoMacBook-Pro yolov5 % python detect.py --source 0
File "detect.py", line 119
p, s, im0, frame = path[i], f'{i}: ', im0s[i].copy(), dataset.count
^
SyntaxError: invalid syntax
electron@diynoMacBook-Pro yolov5 %
```
```bash:Terminal
electron@diynoMacBook-Pro yolov5 % python3 detect.py --source 0
^Z
zsh: suspended python3 detect.py --source 0
electron@diynoMacBook-Pro yolov5 %
```
YOLOv5の学習済みモデルを取得(wget)
```bash:Terminal
electron@diynoMacBook-Pro yolov5 % wget https://github.com/ultralytics/yolov5/releases/download/v3.0/yolov5m.pt
--2021-07-14 21:28:43-- https://github.com/ultralytics/yolov5/releases/download/v3.0/yolov5m.pt
github.com (github.com) をDNSに問いあわせています... 52.69.186.44
github.com (github.com)|52.69.186.44|:443 に接続しています... 接続しました。
HTTP による接続要求を送信しました、応答を待っています... 302 Found
・・・
に接続しています... 接続しました。
HTTP による接続要求を送信しました、応答を待っています... 200 OK
長さ: 43960949 (42M) [application/octet-stream]
`yolov5m.pt' に保存中
yolov5m.pt 100%[================================================================================================>] 41.92M 13.5MB/s 時間 3.1s
2021-07-14 21:28:47 (13.5 MB/s) - `yolov5m.pt' へ保存完了 [43960949/43960949]
electron@diynoMacBook-Pro yolov5 %
```
```bash:Terminal
electron@diynoMacBook-Pro yolov5 % ls
CONTRIBUTING.md README.md export.py requirements.txt tutorial.ipynb
Dockerfile data hubconf.py test.py utils
LICENSE detect.py models train.py yolov5m.pt
electron@diynoMacBook-Pro yolov5 %
```
# 補足
なお、2017年にGoogleから公式発表された「Cloud Video Intelligence API」のベータ版では、動画を再生せずに、どのフレーム(コマ)に何のオブジェクトが映っているのかを確認できる画面がお披露目されました。
しかし、その後、GCPでリリースされたGoogle Cloud Video Intelligence APIを見ると、動画の各フレーム(コマ)を再生しないと、どのフレーム(コマ)に何の物体が検出されたのかは、確認できないように見えます。
- [Google Cloud Video Intelligence API を試す。](https://qiita.com/kohei789/items/f96e04a920a04f15d0d2)
- [GoogleVideoIntelligence APIで動画の情報解析が『誰でもできる』時代へ](https://ledge.ai/google-video-intelligence-api/)

> 出力は『動画全体のラベル(lavels)』と『各シーン毎のラベル(Shots)』が以下のようなJSONで取得可能なようです。

これだと、GCPから出力されるjson形式などの動画解析結果のファイルを、この記事で試みたように、テキスト解析を行うスクリプトを書くか、次の記事で提案されているようなPythonスクプトファイルを書いて、GCPから解析結果のデータを取得するかなどして、手元で手を動かすことで、『2017年にGoogleから公式発表された「Cloud Video Intelligence API」のベータ版』の画面に類似した管理画面を作らないといけないかもしれません。
- [Video Intelligence APIで動画の物体検出をする](https://qiita.com/yoh_n/items/9a60d46e976e7884960f)
他方で、shot単位の物体認識結果とは別に、ある一定のフレーム帯の動画内容をオブジェクトのラベル名で表現する機能もあるみたいです。後者は、動画要約(movie summarization)のAIが裏側で動いているのかもしれません。
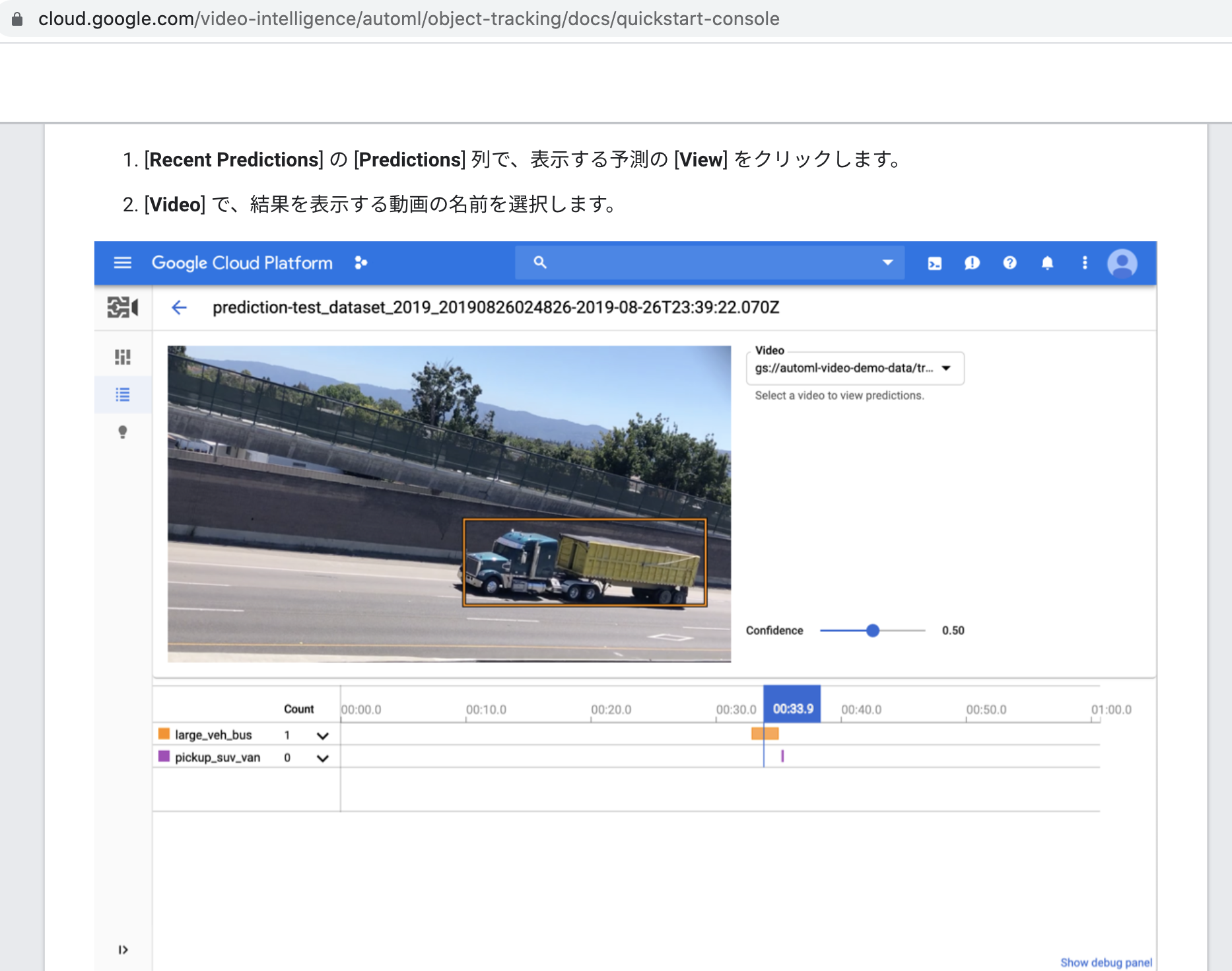
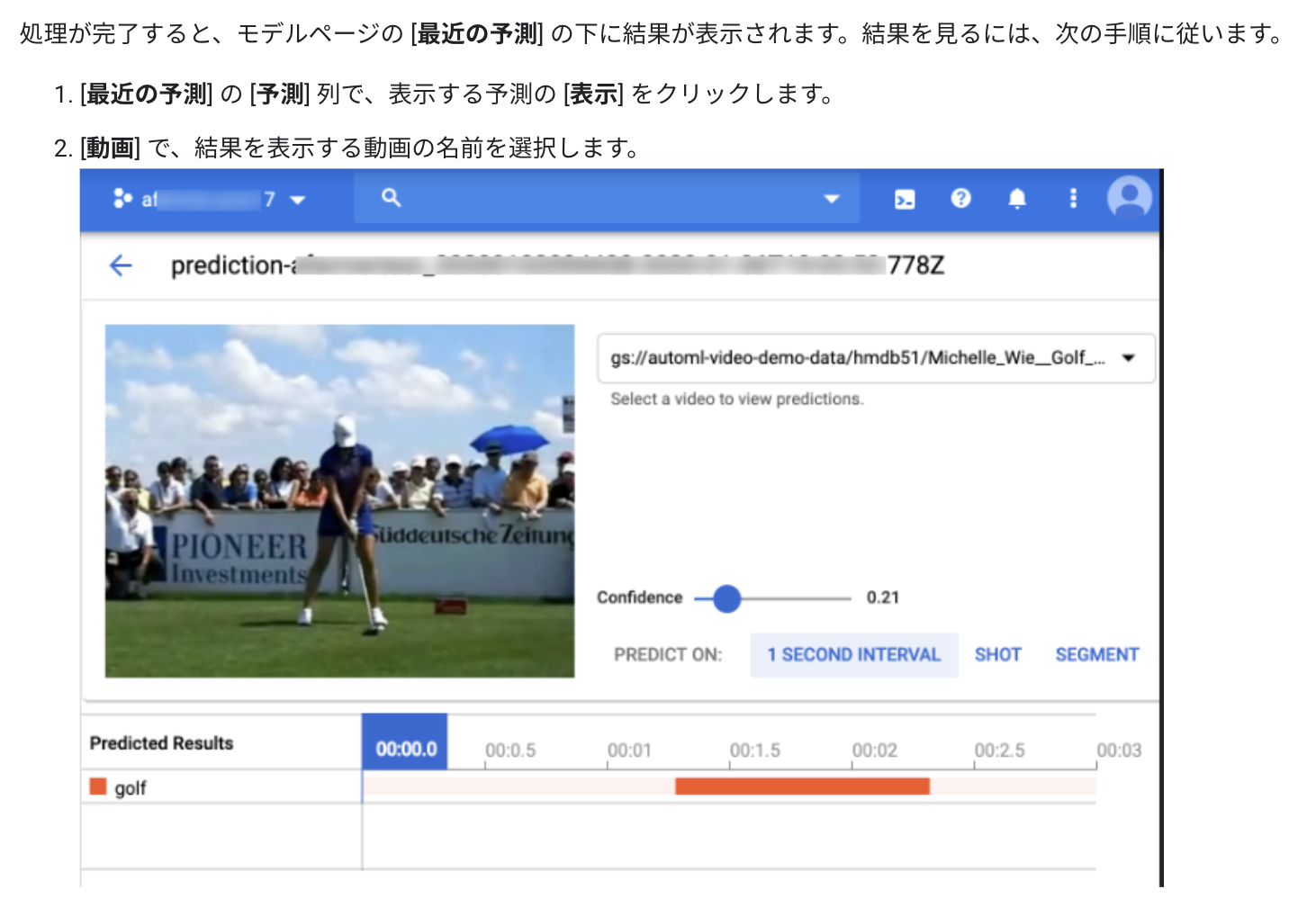
他方で、本記事の冒頭で述べたように、GCP AutoMLを使うと、動画の各フレーム(コマ)を再生せずに、動画のどの時間箇所に、何の物体が検出されたフレーム(コマ)が一発確認できる画面をみられるみたいです。
以下、再掲します。
- https://cloud.google.com/video-intelligence/automl/docs/quickstart-console?hl=ja

#### __( 動画モデルの学習方法 )__
公式マニュアルによると、AutoMLでは、手元の動画ファイルと、その動画の「どの時間フレーム」から「どの時間フレーム」までの時間帯に、何のラベル名のオブジェクトが映りこんでいるのかを記述した学習データを学ばせせて、動画の物体認識モデルを構築できます。
- https://cloud.google.com/video-intelligence/automl/object-tracking/docs/quickstart-console
- https://cloud.google.com/video-intelligence/automl/docs/prepare?hl=ja
> トレーニング、テスト、未割り当ての各ファイルには、アップロードするセット内の動画ごとに行が 1 つずつあり、各行に次の列があります。
>
> 分類またはアノテーション付けするコンテンツ。 このフィールドには、動画の Google Cloud Storage URI が含まれます。Google Cloud Storage URI では大文字と小文字が区別されます。
>
> 動画の分類方法を識別するラベル。. ラベルは文字で始まり、文字、数字、アンダースコア以外を含まないようにする必要があります。 動画に複数のラベルを指定するには、同じ動画セグメントを示す複数の行を CSV ファイルに追加し、各行に異なるラベルを指定します。
>
> 動画セグメントの開始時間と終了時間。 この 2 つのカンマ区切りフィールドでは、分析する動画セグメントの開始時間と終了時間を秒単位で指定します。開始時間は終了時間より前にする必要があります。どちらの値も負数でなく、動画の長さの範囲内である必要があります。 例: 0.09845,1.3600555動画のコンテンツ全体を使用するには、開始時間を 0、終了時間を動画の長さ全体または「inf」にします。例: 0,inf
>CSV データファイルの行の例をいくつか示します。
>
>単一ラベル:
>
> gs://<your-video-path>/vehicle.mp4,u-turn,0,5.4
> 同じ動画セグメントの複数ラベル:
> gs://<your-video-path>/vehicle.mp4,right-turn,0,8.285
> gs://<your-video-path>/vehicle.mp4,left-turn,0,8.285
> gs://<your-video-path>/vehicle.mp4,u-turn,0,8.285
> inf を使用して動画の終わりを示す場合:
>
> gs://<your-video-path>/vehicle.mp4,right-turn,0,inf
> 正確なモデルを作成して最良の結果を得るためには、ラベルごとに少なくとも数百件のトレーニング用動画セグメントを含める必要があります。この数は、データの複雑さによって異なる場合があります。
>
> ラベルを 1 つも指定せずに、CSV データファイルで動画を指定することもできます。この場合は、モデルをトレーニングする前に、AutoML Video UI を使用してデータにラベルを適用する必要があります。それには、動画の Cloud Storage URI の後に 3 つのカンマを続ければよいだけです。以下に例を示します。
> gs://<your-video-path>/vehicle.mp4,,,
>
> トレーニングされたモデルの結果の検証用データを指定する必要はありません。 AutoML Video は、トレーニング用として識別された行をトレーニング データと検証データに自動的に分割します。70% がトレーニングに、30% が検証に使用されます。
> コンテンツを CSV ファイルとして Google Cloud Storage バケットに保存します。
- https://cloud.google.com/video-intelligence/automl/docs/quickstart-console?hl=ja
- https://cloud.google.com/video-intelligence/automl/object-tracking/docs/best-practices?hl=ja
> 良好なモデルのトレーニングに必要なデータ量は、以下のようなさまざまな要因によって異なります。
>
> - クラスの数。クラスの種類が多いほど、クラスあたりに必要なサンプル数も多くなります。
> - ラベルごとに約 100 個のトレーニング用動画のフレームが必要です。各フレームには、対象となるラベルのすべてのオブジェクトにラベルを付ける必要があります。
> - クラスの複雑さ、または多様性。ニューラル ネットワークでは、ネコと鳥をすばやく区別できますが、30 種類の鳥を正しく分類するには、さらに多くのサンプルが必要です。
> - 1,024 × 1,024 ピクセルを超える動画フレームの解像度の場合、フレームの正規化処理中に画質が低下する可能性があります。
(比較)GCOで静止画像(動画ではない)の物体検出モデルを、独自データで学習する方法
- https://note.com/mug_cup/n/ncf12655972b8#AooDd
- https://dev.classmethod.jp/articles/gcp-automl-vision-object-detection/