前回、WandBでの実験管理方法について投稿しました。
今回は本内容の続きで、WandBの機能の一部であるSweepsについてまとめていきたいと思います。
WandBの利用方法について知りたい方は以下前回記事の以下からご参照ください。
Sweepsとは?
W&B Sweepsを使用してハイパーパラメータの検索を自動化し、リッチでインタラクティブな実験管理を視覚化します。ベイズ法、グリッド検索、ランダム検索などの人気のある検索方法から選び、ハイパーパラメータ空間を検索します。複数のマシンに渡ってスケールし、並列化することができます。
個人的にはOptunaのようなイメージをしていて、加えて元々の機能であるログやダッシュボード機能を有してくれているものだと解釈しています。パラメタチューニングがWandBで完結できれば可視化で傾向も確認できるしmodule管理コスト削減(シンプル)にもなるよねーのモチベーションです。
実装
スクリプト、ノートブックの中でwandbをインポート、ログインが完了している前提で進めます。
こちらよく分からない方は前回記事をご参照ください。
https://qiita.com/eikichi838/items/11df5117b823eab5e2a8
まず、sweepのconfigを作成していきます。
# sweep_configを作成
sweep_config = {
"method": "bayes" # random, grid, bayesから選択
}
metric = {
"name": "score",
"goal": "maximize" # minimize, maximizeから選択
}
parameters = {
"num_leaves": {"values": [10, 20, 30, 40, 50]}
}
sweep_config["metric"] = metric
sweep_config["parameters"] = parameters
sweep_configを徐々に構成する書き方をしています。もちろん最初からsweep_configにmetricやparametersを書いても構いません。
methodではパラメータを最適化する手法を選択します。bayesの他にはrandom, gridが存在します。
metricでは今回ターゲットにするlossの名称をname、そのlossを最大にするのか最小にするのかの設定をgoalで行います。
parametersでは今回調整を行うハイパーパラメータを格納します。keyにハイパラ名を、valueにはさらにネストしたものを設定します。今回は離散型の探索を試してみるため、keyにはvalues、 valueにはリスト型で要素を格納しています。
次にsweep_idをwandbのsweep関数から取得します。
# sweep_idを作成
project = "<project名>"
sweep_id = wandb.sweep(sweep_config, project=project)
のちに出てくるwandbのagent関数の引数に使用します。
続いて今回ハイパラチューニングを行いたいモデルとパラメータを関数にて定義します。こちらもagent関数の引数に使用します。
def study(config=None):
with wandb.init(config=config):
# If called by wandb.agent, as below,
# this config will be set by Sweep Controller
config = wandb.config
params["num_leaves"] = config.num_leaves
model = lgb.train(
params,
lgb_train,
valid_sets=[lgb_train, lgb_valid],
valid_names=['train', 'valid'],
num_boost_round=20000,
callbacks=[
lgb.early_stopping(stopping_rounds=100, verbose=True),
lgb.log_evaluation(100),
]
)
# バリデーションデータに対する予測値を格納
preds_valid = model.predict(X_valid, num_iteration=model.best_iteration)
score = root_mean_squared_error(y_valid, preds_valid)
wandb.log({'score': score})
上記の実装に少し手を加えてまとめます。
# 必要ライブラリは事前にインポート済み
# X, yはpolarsデータフレーム
# X, yには説明変数と目的変数、train_idx, valid_idxにはtrain/validのインデックスが格納
# 学習モデルをlightgbm, 評価指標はrmse
def study(config=None):
with wandb.init(config=config):
# If called by wandb.agent, as below,
# this config will be set by Sweep Controller
config = wandb.config
params["num_leaves"] = config.num_leaves
model = lgb.train(
params,
lgb_train,
valid_sets=[lgb_train, lgb_valid],
valid_names=['train', 'valid'],
num_boost_round=20000,
callbacks=[
lgb.early_stopping(stopping_rounds=100, verbose=True),
lgb.log_evaluation(100),
wandb_callback(),
]
)
# バリデーションデータに対する予測値を格納
preds_valid = model.predict(X_valid, num_iteration=model.best_iteration)
score = root_mean_squared_error(y_valid, preds_valid)
wandb.log({'score': score})
# ハイパラ設定を変数へ格納
params = {
"objective": "regression",
"boosting": "gbdt",
"learning_rate": 0.02,
"metric": "rmse",
}
# sweep_configを作成
sweep_config = {
"method": "bayes" # random, grid, bayesから選択
}
metric = {
"name": "score",
"goal": "minimize" # minimize, maximizeから選択
}
parameters = {
"num_leaves": {"values": [10, 20, 30, 40, 50]}
}
sweep_config["metric"] = metric
sweep_config["parameters"] = parameters
# sweep_idを作成
project = "sweep_practice"
sweep_id = wandb.sweep(sweep_config, project=project)
# 予測値を格納する配列
preds_valid = np.zeros(len(train))
preds_test = np.zeros(len(X_test))
# 学習データ分割
# to_pandas()でpandasデータフレームに変換
X_train = X[train_idx].to_pandas()
y_train = y[train_idx].to_pandas()
X_valid = X[valid_idx].to_pandas()
y_valid = y[valid_idx].to_pandas()
# lightgbm専用のデータ形式に変換
lgb_train = lgb.Dataset(X_train, y_train)
lgb_valid = lgb.Dataset(X_valid, y_valid)
wandb.agent(sweep_id, study, count=5)
実行結果を確認するため、WandBサイトを確認します。
ログイン後、プロフィール画面からProjectsタブを選択すると先程作成したprojectが作成されています。
Workspaceでは記録したデータの可視化がされたページです。
Nameですが{wandbのランダム命名}-{count}で自動命名されます。今回はwandb.agent()でcount=5を指定したので5つの実験が記録されています。

Chartsでは学習時のcallbackにwandb_callback()を使用したのでvalid_rmseなど、wandb.log()で明示しなくとも記録してくれています。

Runsでは記録したデータの一覧表が確認できます。
こちらもwandb_callback()の恩恵を受けていて記録してくれたログ列が表示されています。

最後にSweepsです。
Sweepsではsweep_id単位で記録が作成されます。

確認したいSweepをクリックすると、選択したSweepのダッシュボードが表示されます。
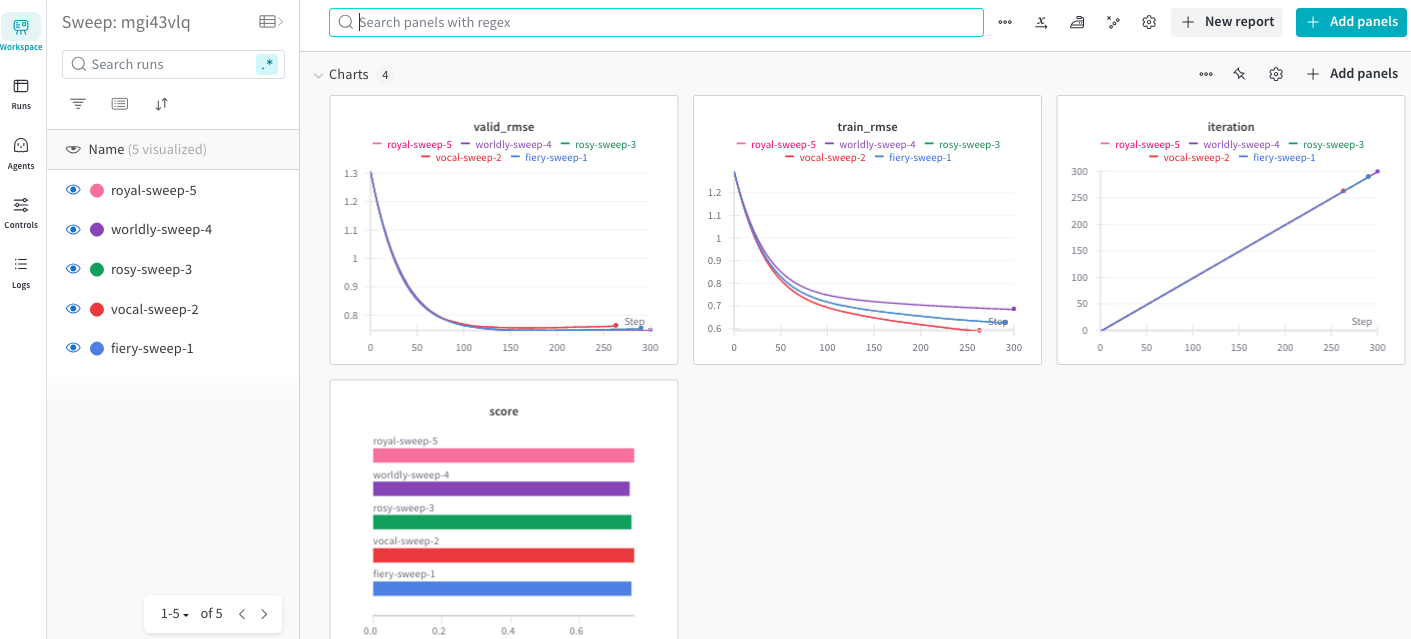
ここではsweep処理で実行した記録のみが表示されます。今回はsweep処理しか実行していないため、本画面については先ほどのWorkspaceと同じ画面になっています。
以下がSweeps特有のチャートです。

左上の散布図の点はsweep処理で実験したプロットです。折線は改善傾向となったプロットのみを繋げているようです。
右上のバーはsweepにて実験したパラメータ重要度を表示しています。今回はnum_leavesしかパラメータを設定してないので1つだけとなっています。
最後の図は設定したパラメータの組み合わせとスコアの関係性を示したグラフです。こちらも今回はnum_leavesしか設定していないためパラメタが1つしか現れてないのですが、1つ追加してみたいと思います。
# 必要ライブラリは事前にインポート済み
# X, yはpolarsデータフレーム
# X, yには説明変数と目的変数、train_idx, valid_idxにはtrain/validのインデックスが格納
# 学習モデルをlightgbm, 評価指標はrmse
def study(config=None):
with wandb.init(config=config):
# If called by wandb.agent, as below,
# this config will be set by Sweep Controller
config = wandb.config
# 学習率を追加
params["learning_rate"] = config.learning_rate
params["num_leaves"] = config.num_leaves
model = lgb.train(
params,
lgb_train,
valid_sets=[lgb_train, lgb_valid],
valid_names=['train', 'valid'],
num_boost_round=20000,
callbacks=[
lgb.early_stopping(stopping_rounds=100, verbose=True),
lgb.log_evaluation(100),
wandb_callback(),
]
)
# バリデーションデータに対する予測値を格納
preds_valid = model.predict(X_valid, num_iteration=model.best_iteration)
score = root_mean_squared_error(y_valid, preds_valid)
wandb.log({'score': score})
# ハイパラ設定を変数へ格納
params = {
"objective": "regression",
"boosting": "gbdt",
"metric": "rmse",
}
# sweep_configを作成
sweep_config = {
"method": "bayes" # random, grid, bayesから選択
}
metric = {
"name": "score",
"goal": "minimize" # minimize, maximizeから選択
}
# ハイパラを追加
parameters = {
# 学習率を追加
"learning_rate": {"distribution": "uniform", "min": 0.01, "max": 0.1},
"num_leaves": {"values": [10, 20, 30, 40, 50]},
}
sweep_config["metric"] = metric
sweep_config["parameters"] = parameters
# sweep_idを作成
project = "sweep_practice"
sweep_id = wandb.sweep(sweep_config, project=project)
# 予測値を格納する配列
preds_valid = np.zeros(len(train))
preds_test = np.zeros(len(X_test))
# 学習データ分割
X_train = X[train_idx].to_pandas()
y_train = y[train_idx].to_pandas()
X_valid = X[valid_idx].to_pandas()
y_valid = y[valid_idx].to_pandas()
# lightgbm専用のデータ形式に変換
lgb_train = lgb.Dataset(X_train, y_train)
lgb_valid = lgb.Dataset(X_valid, y_valid)
wandb.agent(sweep_id, study, count=10)
wandb.finish()

このケースでは学習率を追加してみました。
num_leavesでは離散値設定をしましたが、学習率では連続値として探索する設定としました。定義する分布(今回は一様分布を設定)と探索範囲をminとmaxで設定します。
施行回数10回の範囲では学習率約0.08、num_leaves10の場合のケースが一番スコアが良いということがわかりました。
まとめ
WandBのSweeps機能についてまとめてみました。今回はNotebookでまるっとSweep実行を行いました。他にもconfig.yamlファイルで設定値を管理してCLIで呼び出す方法もあります。
Add W&B to your Python code
こちらも試してみたい。