機械学習にてモデル性能を確認するため、手元にあるデータセットを分割、そのデータで評価を行います。
評価をするために実験記録が必要ですが、結果やハイパーパラメータなどなど実験管理に手間がかかる。。。
そんな課題へのソリューションの一つに、実験の結果やメトリクスを手軽に管理・可視化できるWandBがあります。WandBを利用しはじめてグッと管理コストが減ったので記録として残そうと思います。
本内容は私の解釈、手法の説明ですのでその点ご了承ください。
WandBについて
WandBは、機械学習プロジェクトの全過程を追跡・可視化するツールで、以下のような機能を提供しています
- モデルの学習記録
- 実験結果の可視化
- モデル・データセットのバージョン管理
記録するための実装もシンプルで極論5行で実験管理のコードをかけたりします。
ChatGPTでお馴染みのOpenAIがLLMモデル評価で採用してもいます。
また、LLMモデルの日本語能力を評価、公開してくださっていたり。
Nejumi LLMリーダーボード
そんなWandBが個人開発/小規模プロジェクトでは 無料 で利用できます。ありがたや。
そのためか分析コンペの公開ノートブックでもWandBの実装コードをよく見かけますね。
WandBの使い方
登録からAPIキーの取得
以下のホームページへアクセスし、右上のサインアップから登録します。
Weights & Biases - 機械学習開発者のためのコラボレーションプラットフォーム
サインアップ後、ログインが完了したら右上の自分のアイコン > User settings と進み、下の方にスクロールするとDanger zone配下のRevealをクリックしてAPIキーを表示させ、コピーしておきます。

このAPIキーは外部環境からWandBにアクセスする際の認証に必要となります。
APIキーは秘密情報なので公開notebookなどにアップロードしないよう注意してください。
WandBのインストール
uvなどパッケージ管理ツールなどを介してインストールします。以下はpipの例です。
pip install wandb
実装
スクリプト、ノートブックの中で以下のよう書くことでwandbをインポート、ログインができます。
import wandb
wandb.login(key="<APIキー>")
<APIキー>の部分は事前に取得したAPIキーに差し替えてください。
GitHubなどリモートリポジトリで管理する場合はAPIキーをそのままプッシュするなどしないように注意してください
学習開始の前に以下を実行してwandbの記録をする箱を作成します。
wandb.init(
project="<project名>",
name="<実験名>",
notes="<実験メモ>",
config = <ハイパーパラメータ設定内容など>
)
projectは実験管理する箱の名前になります。ここからはプロジェクトと呼びます。
nameはプロジェクトの下の階層で管理される実験名、notesはその実験名に紐づくメモ、そしてconfigはハイパーパラメータ設定など実験時に使用した値を格納できます。
具体例を書くと私の場合はこのような書き方をしています。
wandb.init(
project="hogeコンペ",
name="exp001",
notes="hoge説明変数を作成",
config = {
"objective": "binary:logistic",
"boosting": "gbtree",
"learning_rate": 0.02,
"eval_metric": "auc",
}
)
projectに参加コンペ名、nameには実験連番、notesに実験内容、configにはハイパーパラメータの設定を書いています。
モデルの学習をし、評価データを使って評価指標の出力値をscoreに格納したとします。そのスコアを記録する場合、以下のように書きます。
wandb.log({"score": score})
辞書のキーの文字列("score"部分)がWandBで格納される列に該当します。そうすることでログがWandBに記録されます。
全て完了したら以下実行で記録が終了します。
wandb.finish()
上記の実装に少し手を加えてまとめると以下のようになります。
# 必要ライブラリは事前にインポート済み
# X, yには説明変数と目的変数、train_idx, valid_idxにはtrain/validのインデックスが格納
# 学習モデルをxgboost, 評価指標はauc
# ハイパラ設定を変数へ格納
params = {
"objective": "binary:logistic",
"boosting": "gbtree",
"learning_rate": 0.02,
"eval_metric": "auc",
}
# wandb初期化
wandb.init(
project="hogeコンペ",
name="exp001",
notes="hoge説明変数を作成",
config = params
)
# 学習データ分割
X_train = X.iloc[train_idx, :]
y_train = y.iloc[train_idx]
X_valid = X.iloc[valid_idx, :]
y_valid = y.iloc[valid_idx]
# xgboost専用のデータ形式に変換
dtrain = xgb.DMatrix(X_train, label=y_train, enable_categorical=True)
dvalid = xgb.DMatrix(X_valid, label=y_valid, enable_categorical=True)
model = xgb.train(cfg.params,
dtrain,
num_boost_round=20000,
evals=[(dtrain, "train"), (dvalid, "valid")],
early_stopping_rounds=100,
verbose_eval=100
)
# バリデーションデータに対する予測値を格納
preds_valid = model.predict(dvalid)
# aucをscoreに格納
score = auc(y_valid, preds_valid)
wandb.log({"score": score})
wandb.finish()
実行結果を確認するため、WandBのサイトを確認します。
ログイン後、プロフィール画面からProjectsタブを選択すると、先ほどnameで指定したprojectが作成されています。
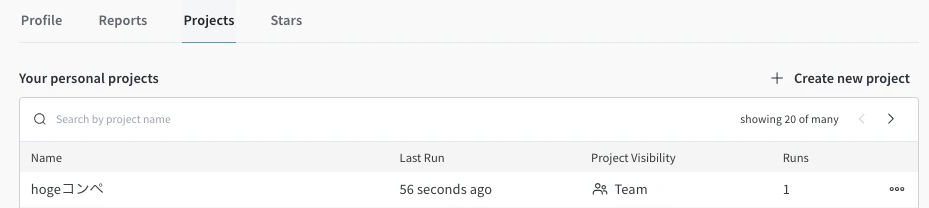
Workspaceでは記録したデータの可視化がされたページです。初期からデータから推測された形でグラフ化がされています。右上のAdd panelから手動追加も可能です。
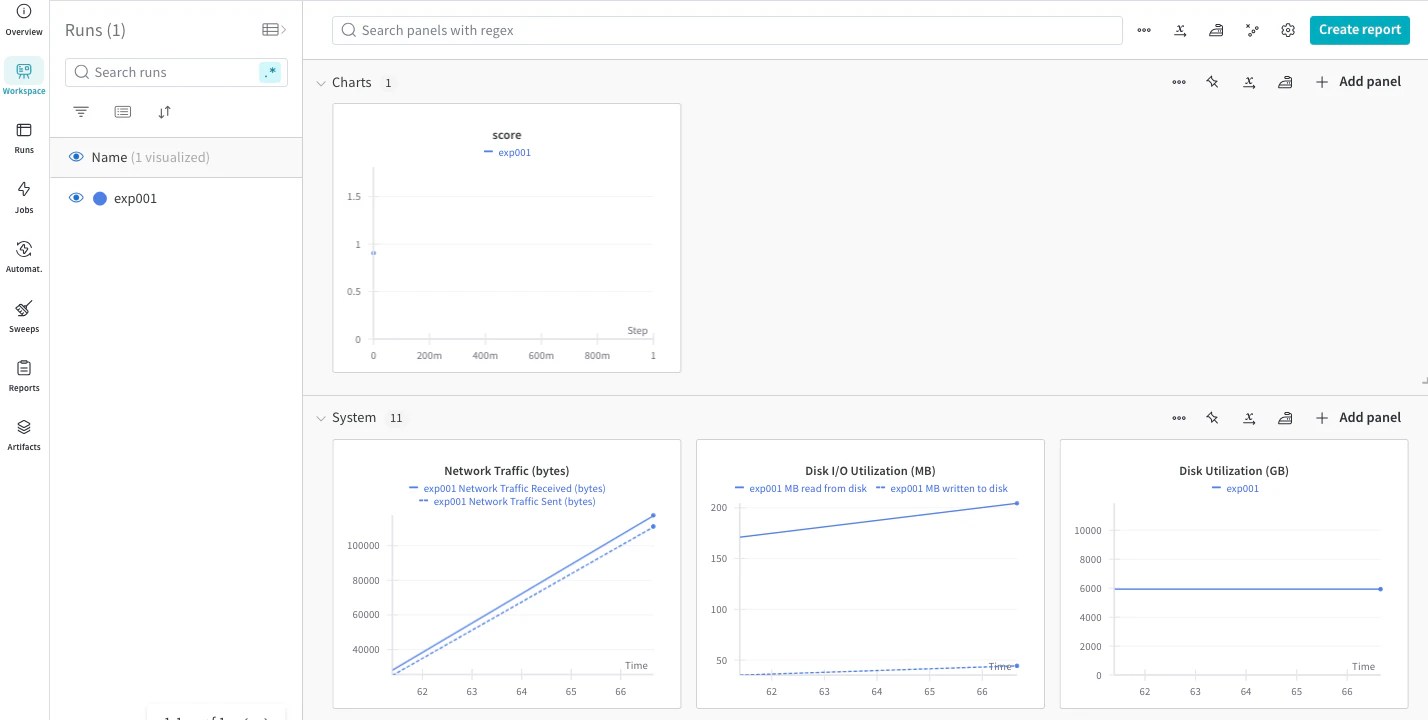
Runsでは記録したデータの一覧表が確認ができます。RuntimeなどWandBのデフォルトの列も複数存在しています。こちらも右上のColumnsから列の選択が可能で自分が見たい指標に絞って確認することも可能です。

学習モデルがLightGBMの場合、wandbライブラリでLightGBM専用のcallbackを持っているため、以下のように組み入れることができます。
# 必要ライブラリは事前にインポート済み
# X, yには説明変数と目的変数、train_idx, valid_idxにはtrain/validのインデックスが格納
# 学習モデルをlightgbm, 評価指標はauc
# lightgbm専用callback
from wandb.integration.lightgbm import wandb_callback
# ハイパラ設定を変数へ格納
params = {
"objective": "binary:logistic",
"boosting": "gbtree",
"learning_rate": 0.02,
"eval_metric": "auc",
}
# wandb初期化
wandb.init(
project="hogeコンペ",
name="exp002",
notes="lightgbm callback",
config = params
)
# 学習データ分割
X_train = X.iloc[train_idx, :]
y_train = y.iloc[train_idx]
X_valid = X.iloc[valid_idx, :]
y_valid = y.iloc[valid_idx]
# lightgbm専用のデータ形式に変換
lgb_train = lgb.Dataset(X_train, y_train)
lgb_valid = lgb.Dataset(X_valid, y_valid)
# lgbを学習
model = lgb.train(
params,
lgb_train,
valid_sets=[lgb_train, lgb_valid],
valid_names=["train", "valid"],
num_boost_round=20000,
callbacks=[
lgb.early_stopping(stopping_rounds=100, verbose=True),
lgb.log_evaluation(100),
wandb_callback()
]
)
# バリデーションデータに対する予測値を格納
preds_valid = model.predict(X_valid, num_iteration=model.best_iteration)
# aucをscoreに格納
score = auc(y_valid, preds_valid)
wandb.log({"score": score})
wandb.finish()
lgb.trainメソッドのcallbacks引数にwandb_callback()を追加しています。

wandb_callback()関数の中で学習中のメトリクスが自動的にログされます。この表からも分かるようにwandb.log()関数でscoreを記録せずとも、best_score.valid.auc列で自動的にscoreを記録してくれています。
最後に、交差検証のfold毎のログの記録をしたい場合は以下のように書けます。
# 必要ライブラリは事前にインポート済み
# X, yには説明変数と目的変数、train_idx, valid_idxにはtrain/validのインデックスが格納
# 学習モデルをlightgbm, 評価指標はauc
# kfは5foldのKFold
project = "hogeコンペ"
exp_name = "exp003"
notes = "交差検証"
for val_fold, (train_idx, valid_idx) in enumerate(kf.split(X, y)):
wandb.init(
project=project,
group=exp_name,
name=f"{exp_name}-fold{val_fold}",
notes=notes,
config = cfg.params
)
# 学習データ分割
X_train = X.iloc[train_idx, :]
y_train = y.iloc[train_idx]
X_valid = X.iloc[valid_idx, :]
y_valid = y.iloc[valid_idx]
# lightgbm専用のデータ形式に変換
lgb_train = lgb.Dataset(X_train, y_train)
lgb_valid = lgb.Dataset(X_valid, y_valid)
# lgbを学習
model = lgb.train(
params,
lgb_train,
valid_sets=[lgb_train, lgb_valid],
valid_names=["train", "valid"],
num_boost_round=20000,
callbacks=[
lgb.early_stopping(stopping_rounds=100, verbose=True),
lgb.log_evaluation(100),
wandb_callback()
]
)
# バリデーションデータに対する予測値を格納
preds_valid[valid_idx] = model.predict(X_valid, num_iteration=model.best_iteration)
score = auc(y_valid, preds_valid[valid_idx])
vl_scores.append(score)
print(f"ROC-AUC(fold{val_fold}): {score:.4f}")
wandb.log({"score": score})
wandb.finish()
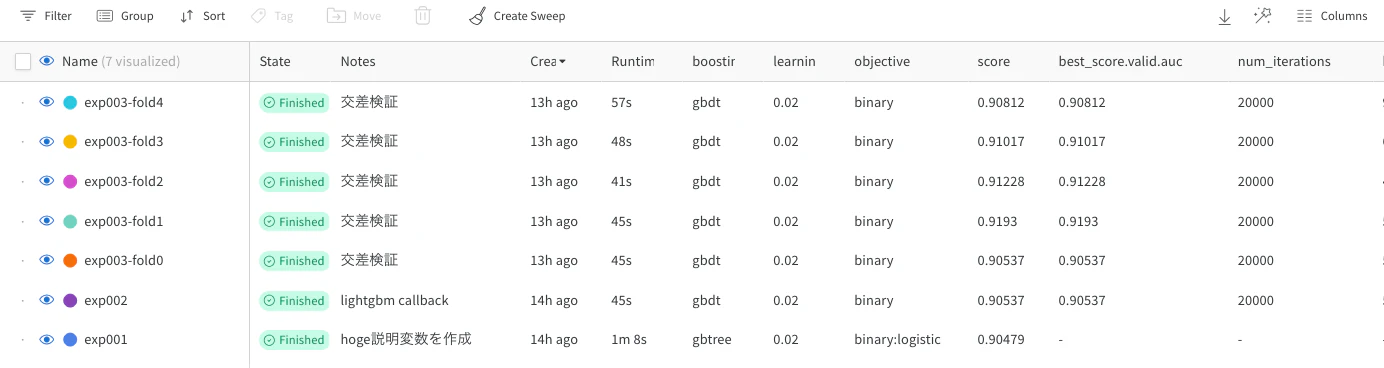
こうすることでfold毎に実験を管理することができます。
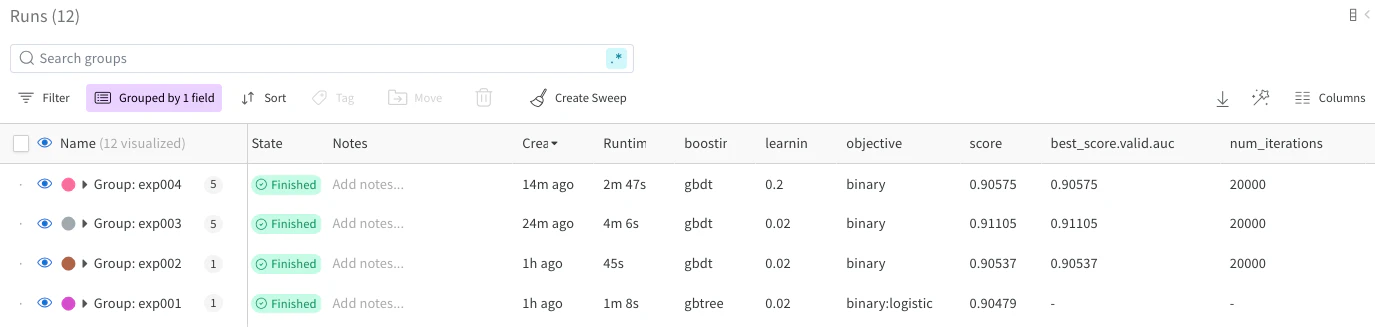
例えば実験を跨いだfold毎で学習を比較したい場合、上記のSearch runsで内容を絞って確認すると見やすくなります。

Workspaceのグラフも同様に絞って確認することができます。
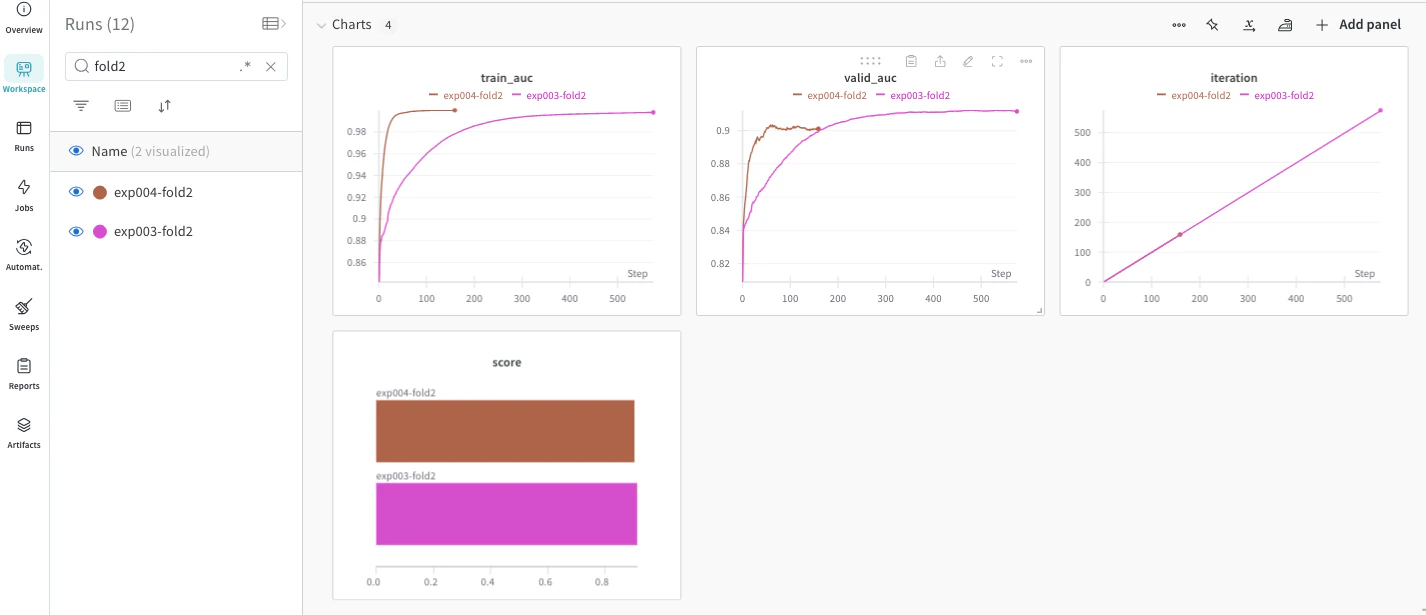
また今回の実装ではwandb.init()関数の引数に新しくgroup引数を追加しています。
wandb.init(
project=project,
group=exp_name,
name=f"{exp_name}-fold{val_fold}",
notes=notes,
config = params
)
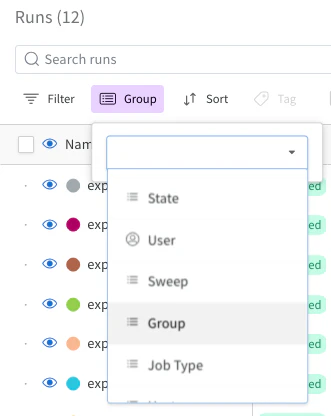
この引数を追加し、Groupを選択することでWandBの評価確認時にgroupで括ることができます。
そうすることで全foldがそのgroup単位で一つとして確認することができます。表示されている値は全foldの平均が表示されます。
まとめ
いつも使っているWandBについてまとめてみました。他にもArtifactsやSweepsなど便利機能はまだありますがまだ使いこなせてないので次回にでも。
Pytorch LightningやYoloなどにもcallbackが準備されていたりしていて使ってますが今後もますます利用することが多くなりそうです。
「私はこんな使い方してるよー」など皆さんの使い方も教えてもらえると嬉しいです。