はじめに
AWS を触り始めたばかりの頃にやらかした初歩的なミスをまとめたアドベントカレンダー、題して「AWS初歩ミス図鑑」の 9 日目です。
今回は TargetGroup の成功コードの設定を間違えて正常なサーバーが疎通不可になった話を書いていきます。
やっていたこと
EC2 + ALB + AutoScaling という、たいへんにシンプルな構成のアプリケーションを作成していました。当時の私にとって AutoScaling は初見のサービスであったため、検証時やリリース手順を作成するときは主に、そちらの設定についての確認を重視していました。
加えて EC2 から TargetGroup までは会社で使用していた CloudFormation のテンプレートがすでに存在していたため、「実績のあるテンプレートを使用すれば安心だな」と、そちらに AutoScaling 部分を書き加えることでデプロイを行うことにしました。私が手を加えてしまった時点で、それはもう実績のあるテンプレートではなくなってしまったわけですが、もちろん気が付かないし、指摘をしてくれる人もいません。
とにかくあまりよく知らないサービスばかりを警戒して、慣れ親しんだサービスについてのパラメータはあまり見返さなかったのです。
結果
ステージング環境へアプリをリリースしてみたところ、正常に動作しているはずのサーバーがすべて Unhealthy 状態になり、AutoScaling が起動と停止を繰り返してコンソールが無限に騒がしくなるという事態が発生しました。
サーバー内の設定がおかしいのかな!?と思っても、ステータスチェックで異常と判断されたインスタンスは AutoScaling により即座に停止されてしまうため、サーバーへログインする時間もありません。
※ 実際には EC2 の削除保護や起動後に AutoScaling 管理下から外すことで対処が可能です。
たいへんに慌て散らかしていたところ、エラーログにこんな一文を見つけます。
Reason: Health checks failed with these codes: [200]
「200…?ステータスチェックに失敗…?この数字は一体どこから…」となったところですべてを察しました。その後、アプリケーションの正しい成功コードである 2xx を TargetGroup に設定したところ、問題なくインスタンスが起動するようになりました。
何を考えていたのか
実績あるテンプレートでは、ヘルスチェックの設定がすべてデフォルトでした。そもそもヘルスチェックの設定に必要なMatcherというプロパティが記載されていませんでした。
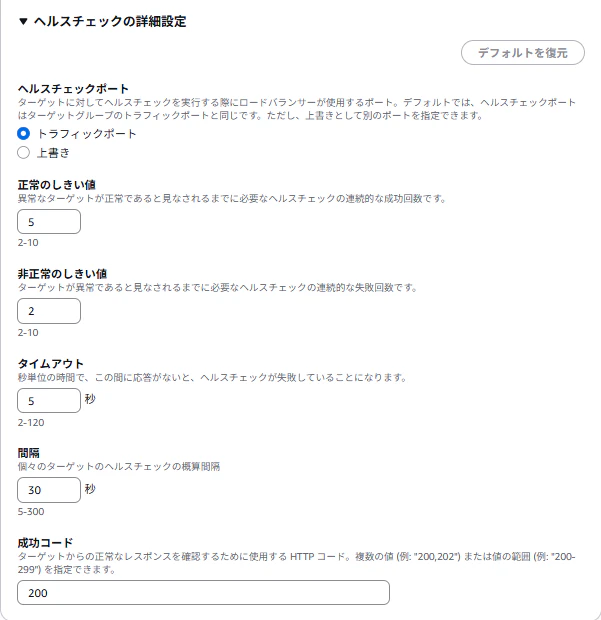
パラメータ云々の前に、ヘルスチェックを細かく設定できるようなテンプレートではなかったのです。そうとは知らず、成功コードの差異にも気が付かないままデプロイをしてしまい、今回のようなことになりました。
必須ではない、省略されたパラメータを重要ではないと判断して鑑みなかったこと、実績があるという安心のもと、テンプレートをよく読まなかったこと、想定される成功コードをきちんと確認しなかったことが今回のミスの原因です。多すぎる。
まとめ
AutoScaling のコンソールでインスタンスが次から次へと生まれて消えていく様子は、なかなか圧巻というか、もうこの世が終わるのでは?というくらいの悲壮感があります。できればもう見たくありません。
成功コードは複数指定することも可能で、200,204 のようにカンマ区切りができたり、200-209 といった範囲指定もできます。テンプレートで管理をする場合は、後々柔軟な設定ができるようにパラメータを工夫するのも一つの手かもしれません。大前提として、テンプレートの記載内容をよく読み込むのも大切です。