Google Cloud Vision APIで画像内の文字の認識を目指します
1. Google Cloud Vision APIを使用可能にします
-Google Cloud Vision API を有効にする を参照し、Google Cloud PlatformコンソールでCloud Vision APIを使用するプロジェクトを用意し、Cloud Vision APIを有効化します
2. Google Cloud Vision APIの認証
- [Google Cloud Vision API に対する認証](https://cloud.google.com/vision/docs/auth?authuser=1&hl=ja)の「サービスアカウントの使用」を参照し、Google Cloud Platformコンソールで前項で準備したプロジェクトが選択されていることを確認し、画面左上の三本線から「APIとサービス」を選択します

- 「APIとサービス」画面で「認証情報」を選択します
- 「認証情報」の画面で「サービスアカウントキー」を作成します
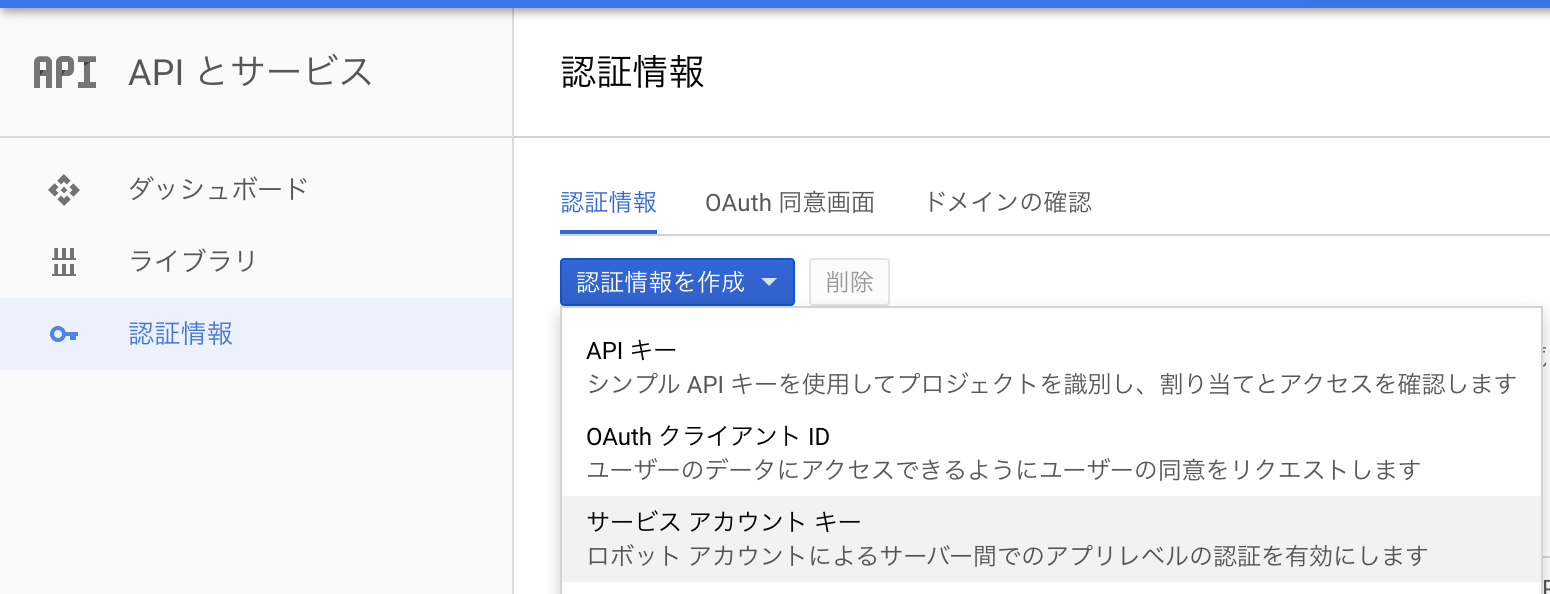
- 「サービスアカウントキーの作成」画面で、サービスアカウントを選択もしくは新規作成し、「JSON」形式でキーファイルを生成し、ダウンロードします。
プロジェクト名-xxxxx.jsonファイルがダウンロードされます

3. サンプルアプリを用意します
-
Google Cloud Vision API - ドキュメント テキスト検出のサンプル を参照し、GoogleCloudPlatform/python-docs-samplesのページからサンプルプログラムを含むzipファイルをダウンロード(緑色のボタン)もしくは
git cloneします。 - このデモで使用するのはGoogleCloudPlatform/
python-docs-samples/vision/cloud-client/detect/detect.py
です
4. 実行環境を準備します
- 下記のコマンドで環境変数として前々項でダウンロードしたjsonファイルを指定して認証情報を設定します
export GOOGLE_APPLICATION_CREDENTIALS=XXXXX-XXXXXXXXXXXX.json
- ターミナルを開き、上記のファイルをダウンロード/解凍したフォルダへ移動し、
pip install -r requirements.txt
で必要な道具をインストールします
- 下記のコマンドを実行し、対象画像ファイルに含まれる文字列を取り出します
python python-docs-samples-master/vision/cloud-client/detect/detect.py text 対象画像ファイル名
Texts:
どれみ
ふぁそら
しど
: