Google音声入力APIを使ってDialogflowでの口語会話の実現を目指します
1. Google音声認識APIを試してみる
- CLOUD SPEECH APIでサインアップして、音声認識を試してみます
- 試してみて、使えそうであれば、次はプログラムからこの機能を呼び出し(API)て使用してみます。次項へどうぞ。
2. Google Cloud Speech APIを使用可能にします
-Google Cloud Speech クイックスタートなどを参照し、Google Cloud PlatformコンソールでCloud Speech APIを使用するプロジェクトを用意し、Cloud Speech APIを有効化します
3. Google Cloud Speech APIの認証
- [Google Cloud Speech API に対する認証](https://cloud.google.com/speech/docs/auth?authuser=1&hl=ja)の「サービスアカウントの使用」を参照し、Google Cloud Platformコンソールで前項で準備したプロジェクトが選択されていることを確認し、画面左上の三本線から「APIとサービス」を選択します

- 「APIとサービス」画面で「認証情報」を選択します
- 「認証情報」の画面で「サービスアカウントキー」を作成します
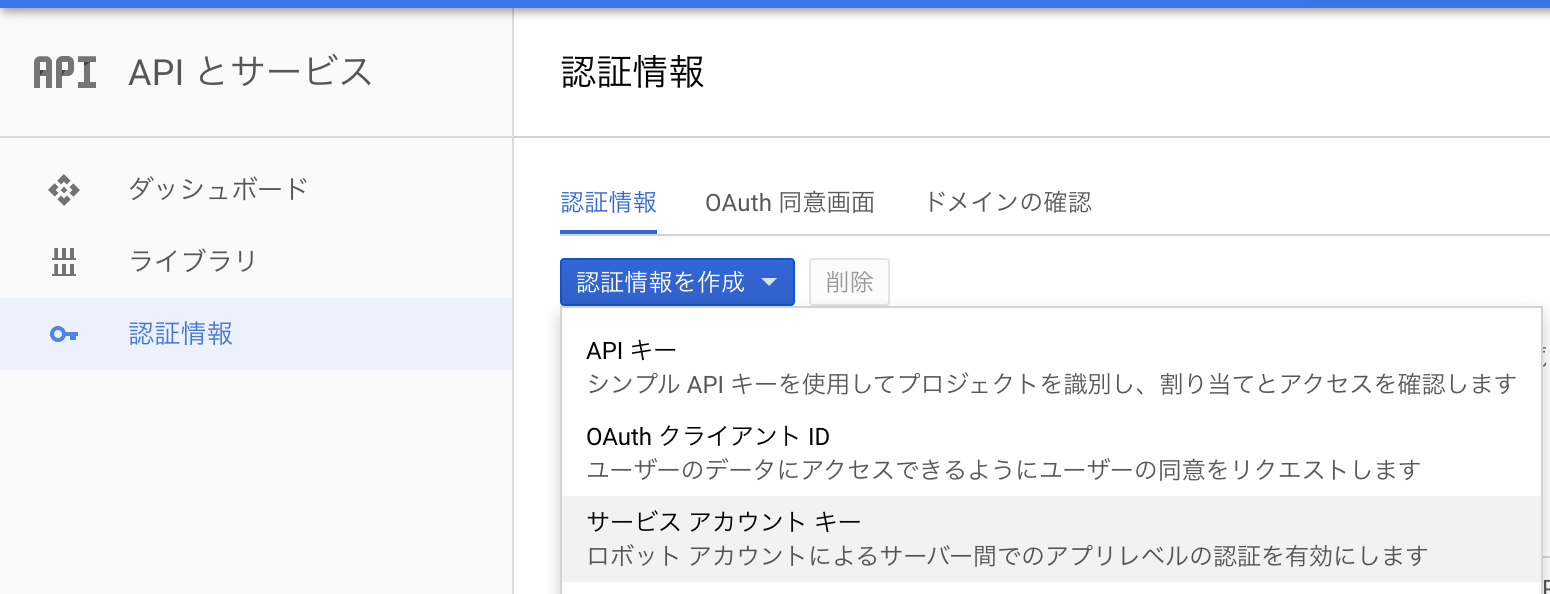
- 「サービスアカウントキーの作成」画面で、サービスアカウントを選択もしくは新規作成し、「JSON」形式でキーファイルを生成し、ダウンロードします。
プロジェクト名-xxxxx.jsonファイルがダウンロードされます

4. サンプルアプリを用意します
-
Google Cloud Speech API - ドキュメント サンプル・アプリケーション のPython 非ストリーミングおよびストリーミング音声認識サンプル - GoogleCloudPlatform/python-docs-samples
を参照し、GoogleCloudPlatform/python-docs-samplesのページからサンプルプログラムを含むzipファイルをダウンロード(緑色のボタン)もしくはgit cloneします。 - このデモで使用するのはGoogleCloudPlatform/
python-docs-samples/speech/cloud-client/transcribe.py
です
5. 実行環境を準備します
- 下記のコマンドで環境変数として前々項でダウンロードしたjsonファイルを指定して認証情報を設定します
export GOOGLE_APPLICATION_CREDENTIALS=XXXXX-XXXXXXXXXXXX.json
- ターミナルを開き、上記のファイルをダウンロード/解凍したフォルダへ移動し、
pip install -r requirements.txt
で必要な道具をインストールします
- 下記のコマンドを実行し、サンプルファイル(
audio.raw)に含まれる言葉を文字にしてみます
cd python-docs-samples-master/speech/cloud-client
python transcribe.py resources/audio.raw
下記の結果が得られることを確認します。
Transcript: how old is the Brooklyn Bridge
6. 日本語で録音した音声ファイルを用意します
- 末尾の参考情報2. WAVでの録音 - mattdiamond/Recorderjs
または3. FLACでの録音 - mmig/speech-to-flacを参照して日本語で録音した音声ファイルを用意します
7. 日本語用プログラムを用意し、実行してみます
- 上記の
transcribe.pyをコピーして日本語用のプログラムを用意します
cp transcribe.py transcribe_jp.py
- 上記のプログラムをatomなどで開き、下記の箇所を編集します
transcribe_jp.py
def transcribe_file(speech_file):
:
config = types.RecognitionConfig(
encoding=enums.RecognitionConfig.AudioEncoding.FLAC,
sample_rate_hertz=44100,
language_code='ja-JP')
-
RecognitionConfig.AudioEncodingは音声ファイルが FLACであればFLAC、WAVファイルであればLINEAR16に設定します -
sample_rate_hertzは録音した際の録音レート(周波数)に設定します -
language_codeはja-JPに設定します(日本語であれば。) サポートされている言語はGoogle Cloud Speech API - 言語のサポートで確認できます -
実行してみます
python transcribe_jp.py resources/myaudio.flac
うまくいきました。
Transcript: こんにちは
8. 音声で入力した文字列をデータベースに格納する
- 音声情報が取得できたら、Google音声認識APIを使って文字列への変換を試みます。Google音声認識APIはPOST https://speech.googleapis.com/v1/speech:recognize?key=YOUR_API_KEYの形式で送付します
- Node-REDからのAPI呼び出しはNode-RED - API呼び出ししてみる(ぐるなび)Node-RED - API呼び出ししてみる(Zoho)などが参考になります
9. Dialogflowと連携します
- Dialogflowでチャットボットをつくってみるなどを参照してDialogflowのフローを用意します
- APIを確認します
- API呼び出しで前項で入手した日本語文字列をDialogflowへ渡します
- 返却されるchatの答えをGoogle HomeやPepperなどで喋らせてみます