深層学習day2 レポート
Section1 勾配消失問題
1.要点
誤差逆伝播法が下位層に進めていくに連れて、勾配がどんどん緩やかになっていく。そのため、勾配降下法による、更新では下位層のパラメータはほとんど変わらず、訓練は最適値に収束しなくなる。
活性化関数のシグモイド関数は大きな値で出力の変化が微小なため、勾配消失問題を引き起こす事があった。
勾配
活性化関数の選択
重みの初期値設定
バッチ正規化
Xavier法(Glorot法)の初期値
重みの各要素は、前の層のノード数と後ろの層のノード数の和を分散をして、その平方根を標準偏差とする分布に従って初期化する、Sigmoid関数やTanh関数のように点対称で中央付近で線形関数としてみなせる活性化関数に向いている。
Var(W) = \frac{2}{n_{in} + n_{out}}
正規分布:
\begin{align}
& \sigma = \sqrt{\frac{2}{n_{\text{in}} + n_{\text{out}}}} \\
& W \sim \mathcal{N}(0, \sigma^2)
\end{align}
一様分布:
\begin{align}
& a = \sqrt{\frac{6}{n_{\text{in}} + n_{\text{out}}}} \\
& W \sim \mathcal{U}(-a, a)
\end{align}
He法(Kaiming法)の初期値
重みの各要素は、前の層のノード数の和を分散をして、その平方根を標準偏差とする分布に従って初期化する。ReLU関数を用いる場合に向いている
正規分布:
\begin{align}
& \sigma = \sqrt{\frac{2}{n_{in}}} \\
& W \sim \mathcal{N}(0, \sigma^2)
\end{align}
一様分布:
\begin{align}
& a = \sqrt{\frac{6}{n_{in}}} \\
& W \sim \mathcal{U}(-a, a)
\end{align}
XavierとHe初期化の式の由来
1.深いネットワーク勾配爆発と勾配消失問題解決したいために、順伝播と逆伝播の両方で分散を保ちたい
2.仮定
\begin{align}
& y = \sum_{i=1}^{n_{in}} Wx\\
& x_iは独立\\
& Wijは独立\\
& \mathbb{E}[x_i] = 0\\
& \mathbb{E}[W_{ij}] = 0
\end{align}
3.Xavier出力の分散と入力の分散を保ちたいと逆伝播は今の層の誤差の分散と次の層から来る誤差の分散を保ちたいです、tanhとsigma関数は中心対称の関数ので、分散は0ですだから適用できる。
順伝播:
\begin{align}
& Var(y) = Var(x) \\
& n_{in} \cdot Var(x) Var(w) = Var(x)\\
& Var(w) = \frac{1}{n_{in}}
\end{align}
逆伝播:
\begin{align}
& Var(\delta^l) = Var(\delta^{l+1})\\
& Var(\delta^l) = n_{out} Var((W) Var(\delta^i+1)\\
& n_{out} Var(W) = 1\\
& Var(W) = \frac{1}{n_{out}}
\end{align}
順伝播と逆伝播両方を満足するのは無理です、だからwの分散を平均値を設定する
Var(W) = \frac{2}{n_{in} + n_{out}}
4.Heは出力の分散と入力の分散保ちたいだけです、ReLU関数の分散は大体1/2ので、それを修正する感じ
\begin{align}
& \frac{1}{2}\cdot n \cdot Var(w) = 1\\
& Var(w) = \frac{2}{n_{in}}
\end{align}
5.区間対称な一様分布の分散を求める
\begin{align}
& X \sim \mathcal{U}(-a, a)\\
& \mathbb{E}[X] = 0\\
& f(x) =
\begin{cases}
\frac{1}{2a} & (-a \le x \le a)\\ 0 & (それ以外)
\end{cases}\\
& Var[X] = \mathbb{E}[X^2] - \mathbb{E}[X]^2 = E[X]^2\\
& \mathbb{E}[X^2] = \int_{-a}^{a} x^2 \cdot \frac{1}{2a} dx = \frac{1}{2a} \left[\frac{x^3}{3}\right]_{-a}^{a}=\frac{a^2}{3}\\
& \frac{a^2}{3}=\frac{2}{n_{in}}\\
& a = \sqrt{\frac{6}{n_{in}}}
\end{align}
正規分布の分散計算するのはまたわからないです、勉強すれば更新します。
バッチ正規化(Batch Normalization)
バッチ正規化とは、各チャンネルごとに バッチ全体 + 空間全体、正規化することです、CNNはよく使われています。
レイヤー正規化(Layer Normalization)
レイヤー正規化とは、各サンプルで チャンネルも含めてまとめて正規化
Transformerでよく使われています。
インスタンス正規化(Instance Normalization
インスタンスとは、サンブルとチャネルごとに正規化することです
グループ正規化(Group Normalization)
1サンプル内で複数のチャネルをグループ化して
バッチ正規化の逆伝播計算
先ずはバッチ正規化の順伝播
一つのチャンネルのデータです
\begin{align}
入力:\\
& x = \{x_1, x_2,...,x_n\}\\
平均・分散:\\
& \mu = \frac{1}{N}\sum_{i = 1}^Nx_i\\
& \sigma^2 = \frac{1}{N}\sum_{i = 1}^{N}(x_i - \mu)^2\\
正規化:\\
& \hat x_i = \frac{x_i - \mu}{\sqrt{\sigma^2 + \epsilon}}\\
スケール&シフト:\\
& y_i = \gamma \hat x_i + \beta
\end{align}
バッチ正規化の逆伝播
\begin{align}
&\text{入力:} \quad x = \{x_1, x_2, \dots, x_N\} \\[2mm]
&\text{平均・分散:} \quad
\mu = \frac{1}{N} \sum_{i=1}^{N} x_i, \quad
\sigma^2 = \frac{1}{N} \sum_{i=1}^{N} (x_i - \mu)^2 \\[1mm]
&\text{正規化:} \quad \hat{x}_i = \frac{x_i - \mu}{\sqrt{\sigma^2 + \epsilon}} \\[1mm]
&\text{スケール&シフト:} \quad y_i = \gamma \hat{x}_i + \beta \\[2mm]
&\text{上流勾配:} \quad \frac{\partial L}{\partial y_i} \\[1mm]
&\text{γ, β の勾配:} \quad
\frac{\partial L}{\partial \gamma} = \sum_{i=1}^{N} \frac{\partial L}{\partial y_i} \hat{x}_i, \quad
\frac{\partial L}{\partial \beta} = \sum_{i=1}^{N} \frac{\partial L}{\partial y_i} \\[1mm]
&\text{\(\hat{x}_i\) の勾配:} \quad
\frac{\partial L}{\partial \hat{x}_i} = \frac{\partial L}{\partial y_i} \cdot \gamma \\[1mm]
&\text{σ² の勾配:} \quad
\frac{\partial L}{\partial \sigma^2} = \sum_{j=1}^{N} \frac{\partial L}{\partial \hat{x}_j} \left(- \frac{x_j - \mu}{2 (\sigma^2 + \epsilon)^{3/2}} \right) \\[1mm]
&\text{μ の勾配:} \quad
\frac{\partial L}{\partial \mu} = \sum_{j=1}^{N} \frac{\partial L}{\partial \hat{x}_j} \left(-\frac{1}{\sqrt{\sigma^2 + \epsilon}}\right) + \frac{\partial L}{\partial \sigma^2} \sum_{j=1}^{N} \frac{-2 (x_j - \mu)}{N} \\[1mm]
&x_i\text{ に対する最終勾配:} \quad
\frac{\partial L}{\partial x_i} =
\frac{\partial L}{\partial \hat{x}_i} \frac{1}{\sqrt{\sigma^2 + \epsilon}}
- \frac{1}{N} \sum_{j=1}^{N} \frac{\partial L}{\partial \hat{x}_j} \frac{1}{\sqrt{\sigma^2 + \epsilon}}
- \frac{1}{N} \sum_{j=1}^{N} \frac{\partial L}{\partial \hat{x}_j} \frac{(x_j - \mu)(x_i - \mu)}{(\sigma^2 + \epsilon)^{3/2}}
\end{align}
2.実装演習
import math
from typing import Literal
from torch import Tensor
import torch
_FanMode = Literal["fan_in", "fan_out"]
_NonlinearityType = Literal[
"relu",
"leaky_relu",
]
# wの入力ノード数と出力ノード数計算する
def calculate_in_out(tensor: Tensor):
dimensions = tensor.dim()
if dimensions < 2:
raise ValueError("Tensor must have at least 2 dimensions")
fan_in = tensor.size(1)
fan_out = tensor.size(0)
return fan_in, fan_out
# wをXavier一様分布を初期化する
def xavier_uniform_(tensor: Tensor):
fan_in, fan_out = calculate_in_out(tensor)
bound = math.sqrt(6.0 / (fan_in + fan_out))
with torch.no_grad():
return tensor.uniform_(-bound, bound)
# wをXavier正規分布を初期化する
def xavier_normal_(tensor: Tensor):
fan_in, fan_out = calculate_in_out(tensor)
std = math.sqrt(2.0 / (fan_in + fan_out))
with torch.no_grad():
return tensor.normal_(0.0, std)
# wをHe一様分布を初期化する
def kaiming_uniform_(
tensor: Tensor,
a: float = 0,
mode: _FanMode = "fan_in",
nonlinearity: _NonlinearityType = "leaky_relu",
):
fan_in, fan_out = calculate_in_out(tensor)
fan = fan_in if mode == "fan_in" else fan_out
bound = (
math.sqrt(6.0 / fan)
if nonlinearity == "relu"
else math.sqrt(6.0 / (1 + a**2) / fan)
)
with torch.no_grad():
return tensor.uniform_(-bound, bound)
# wをHe正規分布を初期化する
def kaiming_normal_(
tensor: Tensor,
a: float = 0,
mode: _FanMode = "fan_in",
nonlinearity: _NonlinearityType = "leaky_relu",
):
fan_in, fan_out = calculate_in_out(tensor)
fan = fan_in if mode == "fan_in" else fan_out
std = (
math.sqrt(2 / fan)
if nonlinearity == "relu"
else math.sqrt(2.0 / (1 + a**2) / fan)
)
with torch.no_grad():
return tensor.normal_(0.0, std)
if __name__ == "__main__":
x1 = torch.tensor(
[
[1.0, 2.0, 3.0, 4.0, 5.0, 6.0],
[1.0, 2.0, 3.0, 4.0, 5.0, 6.0],
[1.0, 2.0, 3.0, 4.0, 5.0, 6.0],
]
)
x2 = torch.tensor(
[
[1.0, 2.0, 3.0, 4.0, 5.0, 6.0],
[1.0, 2.0, 3.0, 4.0, 5.0, 6.0],
[1.0, 2.0, 3.0, 4.0, 5.0, 6.0],
]
)
torch.manual_seed(42)
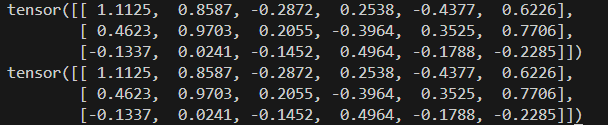
kaiming_normal_(x1, mode="fan_in", nonlinearity="leaky_relu")
torch.manual_seed(42)
torch.nn.init.kaiming_normal_(x2, mode="fan_in", nonlinearity="leaky_relu")
print(x1)
print(x2)
実行結果:
import torch
from torch.nn import Module, Parameter
from torch import Tensor, sqrt, zeros
class LazyBatchNorm1d(Module):
def __init__(self, eps=1e-5, momentum=0.1, affine=True, track_running_stats=True):
super().__init__()
self.eps = eps
self.momentum = momentum
self.affine = affine
self.track_running_stats = track_running_stats
self.initialized = False
def _init_params(self, C, device):
if self.affine:
# Conv1d / Linear 両対応のため (1, C, 1)
self.gamma = Parameter(torch.ones(1, C, 1, device=device))
self.beta = Parameter(torch.zeros(1, C, 1, device=device))
if self.track_running_stats:
self.register_buffer("running_mean", torch.zeros(1, C, 1, device=device))
self.register_buffer("running_var", torch.ones(1, C, 1, device=device))
self.initialized = True
def forward(self, x: Tensor):
if not self.initialized:
self._init_params(x.size(1), x.device)
# ===== Linear 用 (N, C) =====
if x.dim() == 2:
mu = x.mean(dim=0, keepdim=True) # (1, C)
var = x.var(dim=0, unbiased=False, keepdim=True)
if self.training or not self.track_running_stats:
if self.track_running_stats:
self.running_mean.squeeze(-1).mul_(1 - self.momentum).add_(
self.momentum * mu
)
self.running_var.squeeze(-1).mul_(1 - self.momentum).add_(
self.momentum * var
)
else:
mu = self.running_mean.squeeze(-1)
var = self.running_var.squeeze(-1)
x_hat = (x - mu) / torch.sqrt(var + self.eps)
if self.affine:
x_hat = self.gamma.squeeze(-1) * x_hat + self.beta.squeeze(-1)
return x_hat
# ===== Conv1d 用 (N, C, L) =====
elif x.dim() == 3:
mu = x.mean(dim=(0, 2), keepdim=True)
var = x.var(dim=(0, 2), unbiased=False, keepdim=True)
if self.training or not self.track_running_stats:
if self.track_running_stats:
self.running_mean.mul_(1 - self.momentum).add_(self.momentum * mu)
self.running_var.mul_(1 - self.momentum).add_(self.momentum * var)
else:
mu = self.running_mean
var = self.running_var
x_hat = (x - mu) / torch.sqrt(var + self.eps)
if self.affine:
x_hat = self.gamma * x_hat + self.beta
return x_hat
else:
raise ValueError("LazyBatchNorm1d expects 2D or 3D input")
if __name__ == "__main__":
x = torch.tensor(
[[[1, 2, 3], [4, 5, 6]], [[3, 2, 1], [6, 5, 4]]],
dtype=torch.float32,
requires_grad=True,
)
model = LazyBatchNorm1d()
result = model(x)
loss = result.sum()
loss.backward()
print(result)
print(x.grad)
x.grad = None
model2 = torch.nn.LazyBatchNorm1d()
result2 = model2(x)
loss2 = result2.sum()
loss2.backward()
print(result2)
print(x.grad)
実行結果:

3.確認テスト
として正しいものを選択肢から選べ。
(3分)
(1)0.15
(2)0.25
(3)0.35
(4)0.45
正解は2です
\begin{align}
sigmoid(0.5) &= 0.5\\
\frac{d}{dx}sigmoid(x) &= (1 - sigmoid(x)) * sigmoid(x)\\
&=(1 - 0.5)0.5\\
&= 0.25
\end{align}
Section2 学習率最適化手法
1. 要点
機械学習によって最適化を行う際に,最適化対象となるコスト関数の表面におけるくぼみ
が鋭く,最適化が困難になる(解探索経路が振動する)箇所がある
この箇所をPathological Curvatureという
• ミニバッチ学習SGD法などによって学習データ数を抑えると,外れ値(ノイズ)の影響を
受けやすいため,Pathological Curvatureにハマりやすいと言われている

Momentum 過去の勾配情報を利用して、パタメータの更新に慣性を持たせる最適化手法です。

\begin{align}
& g_t = \nabla_\theta L(\theta_t)\\
& v_{t + 1} = \mu v_{t} + g_t\\
& \theta_{t + 1} = \theta_t - \eta v_{t+1}\\
\end{align}
Nesterov Accelerated Gradient(NAG)
NAGは先読み付きMomentum、次の場所の勾配予測して更新するMomentumを改良した最適化手法です。
\begin{align}
& \tilde \theta = \theta_t - \eta \mu v_{t -1} \\
& g_t = \nabla_\theta L(\tilde \theta) \\
& v_t = \mu v_{t - 1} + g_t \\
& \theta_{t+ 1} = \theta_t - \eta v_t
\end{align}
実は、プログラムでは同じパラメータを2回更新することはできないので、実際の計算ではv_tの加算をもう一度実行しますだけです。
AdaGrad(Adaptive Gradient Algorithm)は、パタメータごとに学習率を適応的に調整する最適化アルゴリズムです、過去の勾配の二乗和を記録し、勾配が大きかったパタメータほど学習率小さくします。
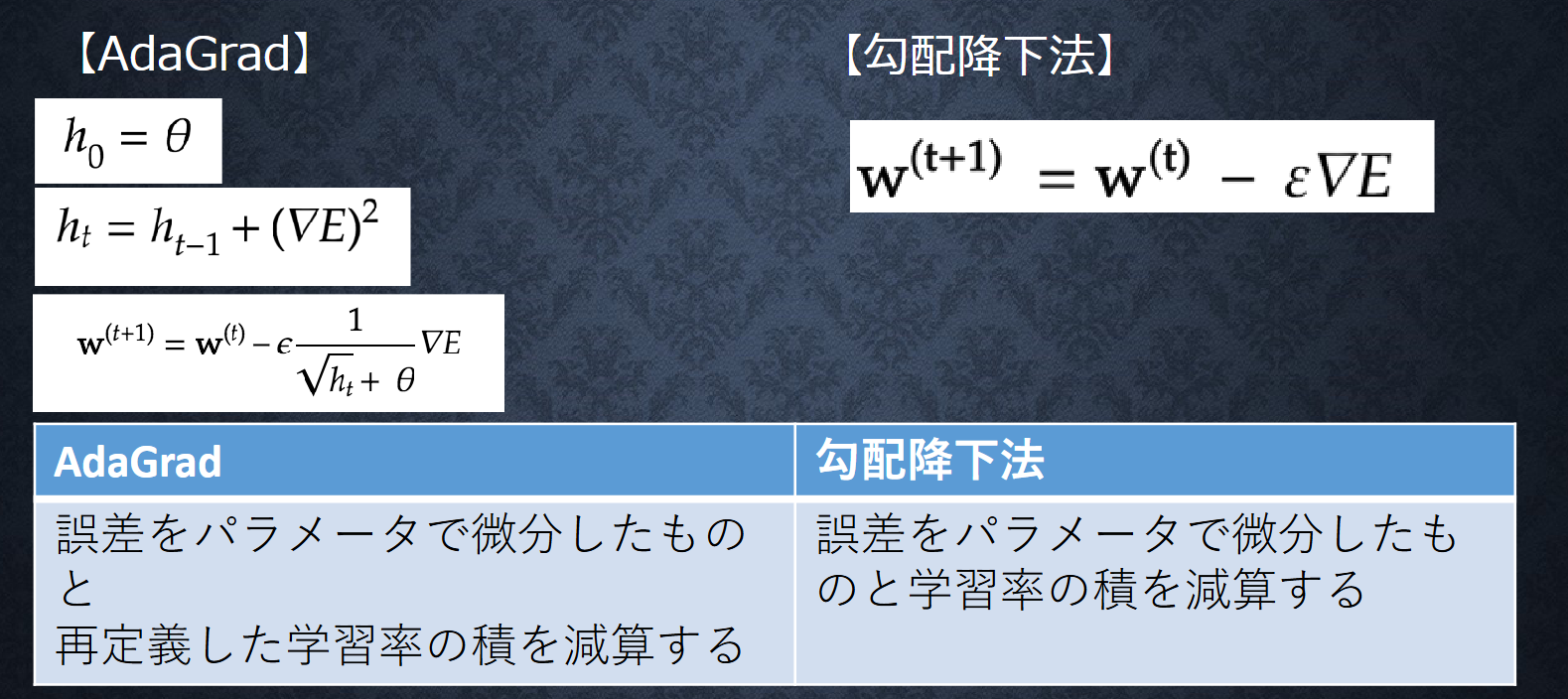
\begin{align}
& r_t = r_{t-1} + g_t^2 \\
& \theta_{t+1} = \theta_t - \frac{\eta}{\sqrt{r_t} + \epsilon}g_t
\end{align}
鞍点問題
馬の鞍みたな場所、ある次元からみると極大となるもの、学習の停滞が引き起こされる。
RMSProp(Root Mean Square Propagation)は 勾配の過去の情報を指数的に減衰させながら平均をとることで、学習率を自動調整する最適化アルゴリズムです。

AdaGradは$r_t$が単調増加し、学習率がどんどん小さくなるため、長期学習で止まりやすい。RMSPropは過去の勾配二乗を指数移動平均に置き換えました。
\begin{align}
& s_t = \alpha s_{t- 1} + (1 - \alpha)g_t^2\\
& \theta_{t+1} = \theta_{t} - \frac{\eta}{\sqrt{s_t} + \epsilon} g_t
\end{align}
AdamはRMSPropとMomentumを組み合わせた手法です。
SGDは単純で軽量だが、勾配のスケールが大きい場合や鞍点で収束が遅くなる
RMSPropは勾配の大きさに応じて学習率を自動調整
Momentumは過去の勾配の方向を考慮して更新を滑らかにする
Adamはこれらを統合し、学習率の自動調整と滑らかな収束の両方を実現します。
\begin{align}
一次モーメント\\
& m_t = \beta_1m_{t-1} + (1-\beta_1)g_t\\
& \hat m_t = \frac{m_t}{1-\beta_1^t}\\
二次モーメント\\
& v_t = \beta_2v_{t-1} + (1 - \beta_2)g_t^2\\
& \hat v_t = \frac{v_t}{1-\beta_2^t} \\
更新式\\
& \theta_{t+1}=\theta_{t}-\frac{\eta}{\sqrt{\hat v_t} + \epsilon}\hat m_t
\end{align}
$\beta_1^t$と$\beta_2^t$は$\beta_1$のt乗と$\beta_2$のt乗です
2.実装演習
import torch
class SGD:
def __init__(self, params, lr: float = 0.01, mome( ¥)
self.momentum = momentum # 普通なら0.9くらい大丈夫です
self.nesterov = nesterov
self.state = {}
def zero_grad(self):
for param in self.params:
if param.grad is not None:
param.grad.zero_()
def step(self):
with torch.no_grad():
for param in self.params:
if param.grad is None:
continue
grad = param.grad
if param not in self.state:
self.state[param] = torch.zeros_like(param)
# v_t = μ v_{t-1} + g_t
self.state[param] = self.momentum * self.state[param] + grad
if self.nesterov:
# θ ← θ − η ( g_t + μ v_t )
param -= self.lr * (grad + self.momentum * self.state[param])
else:
# θ ← θ − η v_t
param -= self.lr * self.state[param]
import torch
class Adagrad:
def __init__(self, params, lr: float = 0.01, eps: float = 1e-10):
self.params = list(params)
self.lr = lr
self.eps = eps
self.state = {} # 勾配二乗累積 r_t
def zero_grad(self):
for param in self.params:
if param.grad is not None:
param.grad.zero_()
def step(self):
with torch.no_grad():
for param in self.params:
if param.grad is None:
continue
grad = param.grad
if param not in self.state:
self.state[param] = torch.zeros_like(param)
# r_t = r_{t-1} + g_t^2
self.state[param] += grad**2
# θ ← θ − η / (sqrt(r_t) + eps) * g_t
param -= self.lr / (torch.sqrt(self.state[param]) + self.eps) * grad
import torch
class RMSprop:
def __init__(
self, params, lr: float = 0.01, alpha: float = 0.99, eps: float = 1e-8
):
self.params = list(params)
self.lr = lr
self.alpha = alpha
self.eps = eps
self.state = {} # 勾配二乗累積 s_t
def zero_grad(self):
for param in self.params:
if param.grad is not None:
param.grad.zero_()
def step(self):
with torch.no_grad():
for param in self.params:
if param.grad is None:
continue
grad = param.grad
if param not in self.state:
self.state[param] = torch.zeros_like(param)
# s_t = a * s_{t-1} + (1 - a) * g_t^2
self.state[param] = self.alpha * self.state[param] + (
1 - self.alpha
) * (grad**2)
# θ ← θ − η / (sqrt(s_t) + eps) * g_t
param -= self.lr / (torch.sqrt(self.state[param]) + self.eps) * grad
import torch
from torch import Tensor
class Adam:
def __init__(
self,
params,
lr: float = 0.01,
betas: tuple[float | Tensor, float | Tensor] = (0.9, 0.999),
eps: float = 1e-8,
):
self.params = list(params)
self.lr = lr
self.betas = betas
self.eps = eps
self.state_m = {}
self.state_v = {}
self.state_step = {}
def zero_grad(self):
for param in self.params:
if param.grad is not None:
param.grad.zero_()
def step(self):
with torch.no_grad():
for param in self.params:
if param.grad is None:
continue
grad = param.grad
if param not in self.state_m:
self.state_m[param] = torch.zeros_like(param)
self.state_v[param] = torch.zeros_like(param)
self.state_step[param] = 0
self.state_step[param] += 1
t = self.state_step[param]
# m_t = b0 * m_{t-1} + (1 - b0) * m_t
self.state_m[param] = (
self.betas[0] * self.state_m[param] + (1 - self.betas[0]) * grad
)
# v_t = b1 * v_{t-1} + (1 - b1) * v_t^2
self.state_v[param] = self.betas[1] * self.state_v[param] + (
1 - self.betas[1]
) * (grad**2)
# ^m_t = m_t / 1 - b0t
# ^v_t = v_t / 1 - b1t
m_hat = self.state_m[param] / (1 - self.betas[0] ** t)
v_hat = self.state_v[param] / (1 - self.betas[1] ** t)
# θ ← θ − η / (sqrt(^v_t) + eps) * ^m_t
param -= self.lr / (torch.sqrt(v_hat) + self.eps) * m_hat
3.確認テスト
モメンタムは、比率をかけた過去の勾配更新量を加算してパラメータを更新する手法です。更新スピードが速いです。
AdaGradは、累積した過去の勾配の二乗でパラメータの更新量を調整する手法です。累積勾配二乗が単調増加し、学習率がどんどん小さくなるため、長期学習で止まりやすいです。
RMSPropは過去の勾配二乗の累積を指数移動平均に置き換えました。
Section3 過学習を抑制する方法
訓練サンプルにだけ適合した学習をした結果、本来の目的である汎化性能が得られない。
過学習が起きる原因の例:
パラメータの数が多すぎる
パラメータの値が偏っている
ノードが多すぎる
学習データが不足している
学習データが偏っている
...
pytorchの最適化にはweight_decayというパタメータがあります、これがL2正則化に相当します。
import torch
import torch.nn as nn
import torch.optim as optim
# ダミーのモデル
model = nn.Linear(10, 1)
# L2正則化付きの最適化関数
optimizer = optim.SGD(model.parameters(), lr=0.01, weight_decay=0.1)
L1 ペナルティにより、重要でないモデルパラメータの多くが 0 になり、重要なパラメータのみが保持される。

理論上の公式:
\begin{align}
& L = L_0 + \lambda\sum_i|w_i|\\
& L = L_0 + \lambda \sum_i|w_i|^2
\end{align}
Weight Decay を実装する場合、ペナルティ項は SGD などのオプティマイザ内で加える。PyTorch は L2 正則化は weight_decay で実装できるが、L1 正則化は標準ではサポートされていない。実装の公式は:
\begin{align}
R(w) &= \frac{\lambda}{2} \sum_i w_i^2 \\
\frac{\partial R}{\partial w_i} &= \lambda w_i \\
\frac{\partial L}{\partial w_i} &= \frac{\partial L_0}{\partial w_i} + \lambda w_i
\end{align}
ドロップアウト(dropout)とは、層のユニットの出力を一定の割合でマスクする(0に設定する)
順伝播:
バッチごとにユニットを確率pで選ぶ(実装上は0/1のマスクをランダムにサンプルしてかける)、1-pがドロップアウトの割合
逆伝播:
選ばれたサブネットワーク上で逆伝播
推論時:全部のユニットを使うが、出力スケールをあわせる
ドロップコネクト(DropConnect)とは。ドロップアウトと異なり、ノードでなく重みを一定の割合でますくする(0に設定する)
推論は全結合層の出力(活性化関数の前)のサンプリングに基づいて行う
ドロップアウト/ドロップコネクトの利点
利点1:巨大なNNの過学習を抑制できる
利点2:擬似的にアンサンブル学習しているとみなせる
早期終了
一定のルールを満たせば学習を終了させるという方法
過学習を抑える効果がある
検証誤差が悪化し始めたら学習を止める
悪化前に停止=正則化の効果
バッチサイズ
バッチサイズが大きくすると、局所に過学習解への収束を防ぐ
平坦な最小値(汎化性能が高い)に収束しやすい
大きいバッチサイズ = 正則化効果
学習率の調整
大きい学習率は鋭い最小値に入りにくくなる
大きめ学習率 = 正則化効果
2.実装演習
import torch
class SGD:
def __init__(
self,
params,
lr: float = 0.01,
momentum: float = 0,
nesterov=True,
weight_decay: float = 0,
):
self.params = list(params) # ここはlistしないと更新できない
self.lr = lr
self.momentum = momentum # 普通なら0.9くらい大丈夫です
self.nesterov = nesterov
self.weight_decay = weight_decay
self.state = {}
def zero_grad(self):
for param in self.params:
if param.grad is not None:
param.grad.zero_()
def step(self):
with torch.no_grad():
for param in self.params:
if param.grad is None:
continue
grad = param.grad
# L2正則化 を勾配に追加 dR / dwi = λwi
if self.weight_decay != 0:
grad = grad + self.weight_decay * param
if param not in self.state:
self.state[param] = torch.zeros_like(param)
# v_t = μ v_{t-1} + g_t
self.state[param] = self.momentum * self.state[param] + grad
if self.nesterov:
# θ ← θ − η ( g_t + μ v_t )
param -= self.lr * (grad + self.momentum * self.state[param])
else:
# θ ← θ − η v_t
param -= self.lr * self.state[param]
import torch
from torch.nn import Module
from torch import Tensor, tensor
class Dropout(Module):
def __init__(self, p: float = 0.5):
super().__init__()
self.p = p
def forward(self, x: Tensor):
if self.training:
assert 0.0 <= self.p < 1.0
mask = (torch.rand_like(x) > self.p).float()
return x * mask / (1 - self.p)
else:
return x
if __name__ == "__main__":
torch.manual_seed(42)
dp = Dropout(0.8)
x = tensor([[0.1, 0.2, 0.3, 0.4, 0.5, 0.6], [1.1, 1.2, 1.3, 0.9, 0.8, 0.7]])
y = dp(x)
print(y)
torch.manual_seed(42)
dp2 = torch.nn.Dropout(0.8)
y = dp2(x)
print(y)
実行結果:

3.確認テスト

答えは2です
Section4 畳み込みニューラルネットワークの概念
1.要点
受容野とはある刺激が特定の神経細胞や受容野によって感知される範囲のことを指します。
受容野一文というならその細胞が見ている範囲
全部は見ていない、担当範囲だけ見る、深くなるほど広く見る特性があります。
単純型細胞と複雑型細胞とは、脳の視覚野内の細胞であり、視野の特定の位置に、特定の方向、太さの線分が提示された時のみ選択的に反応します。
単純型細胞(simple cell)は特定の位置・方向・位相に反応、明暗の配置に敏感、エッジやバーを検出
複雑型細胞(complex cell)は同じ方向・周波数の刺激に反応、位置や位相が多少ずれても反応、単純型細胞の出力を統合
| 視覚理論 | CNN |
|---|---|
| Simple cell | Conv + ReLU |
| Complex cell | Pooling |
| 視覚階層 | 深いCNN |
特徴マップ(Feature Map)
一言というと、畳み込み演算によって抽出された画像の特徴量を示すデータ構造であり、通常は行列とテンソルとして表現さんれる
フィルタ/カーネル(Filter/Kernel)
入力画像(または特徴マップ)の一部を見て、特定のパターンにどれだけ一致するか計算するための学習可能な重みの重合
パディング(Padding)
入力画像(特徴マップ)の周りに値(通常は0)を追加する操作、
画像の端っこもちゃんと見るために、周りに余白をつける。
画像サイズが小さくなりすぎるのを防ぐ。
ストライド(Stride)
カーネルを入力上で動かす時の移動幅。
CNNとは、畳み込みとプーリング層を用いたニューラルネットワーク、主に画像認識に使われる

画像の局所パターンを検出する、同じ検出器を画像全体に適用する(重み共有)
入力
X \in \mathbb{R}^{C_{in} \times H \times W}
カーネル(フィルタ)
W \in \mathbb{R}^{C_{out} \times C_{in} \times kH \times kW }
出力
Y \in \mathbb{R}^{C{out} \times H_{out} \times W_{out}}
畳み込みの順伝播時:出力チャネルcの位置(i, j)は:
Y_{c, i, j} = \sum_{c'= 1}^{C_{in}}\sum_{u = 1}^{kH}\sum_{v = 1}^{kW}W_{c, c',u,v} \cdot X_{c',i+u,j+v} + b_c
$W$と$b$はパラメータです、$c'$入力のチャンネルのこと
H_{out} = \left[ \frac{H + 2P - kH}{S} \right] + 1
im2colは畳み込み演算を効率的に行うためのアルゴリズム。
畳み込み演算を普通に計算しようとするとfor文が何重にもなる。im2colを用いると、for文が行列計算に置き換わり、演算が効率的になる。

columns to imageの略称で、im2colの逆操作として定義
im2colが順伝播計算、逆伝播計算の時にそれぞれ使用される
im2colと同じくスライスによって効率的に実装可能
Point-wise畳み込み(1x1畳み込み)
定義
カーネルサイズが1x1の畳み込み。空間方向は見ないで、チャネル方向だけを混ぜる。
チャネル数の増減、特徴の再結合、計算量の削減(次元圧縮)
定義
各チャネルごとに独立して畳み込みを行う、チャネル間は混ぜない。
直観
R/G/Bを別にフィルタ処理する感じ、空間処理専用
計算量が大幅に減る、表現力は低下
定義
チャネルを複数グループに分け、グループごとに畳み込みを行う。
アップサンプリング(Upsampling)
特徴マップの空間サイズを大きくする操作。
パタメータない、安定が表現力は低い。
逆畳み込み(Trasposed Convolution)
定義
畳み込みの形を逆にした学習可能な拡大操作。
小さい特徴を広げる、学習できるアップサンプリング。
ある範囲の平均や最大値をとることによって、要素を集約する処理のことをプーリング演算という。
マックスプーリングや平均プーリングなどがある。
畳み込み演算と異なり、学習する重みはない。
一番強く反応した特徴だけ残す、エッジ、角、模様など存在検出型の特徴抽出。
強い特徴を強調、でも情報損失が大きい
計算が軽い、でも勾配が不安定
順伝播:
入力の特徴マップ:
x \in \mathbb{R}^{C \times H \times W}
プーリング領域Ω(例: 2x2)に対して
y = \max_{i \in \Omega} x_i
逆伝播:(重要)
\frac{\partial y}{\partial x_i} =
\begin{cases}
1 & (x_i = \max \Omega)\\
2 &それ以外
\end{cases}
順伝播:
各チャネルごとに全空間平均:
y_c = \frac{1}{HW}\sum_{h=1}^{H}\sum_{w=1}^{W}x_{c, h, w}
逆伝播:
\frac{\partial y_c}{\partial x_{c, h, w}}=\frac{1}{HW}
順伝播:
y = \left(\frac{1}{|\Omega|}\sum_{i \in \Omega}|x_i|^p \right)^{\frac{1}{p}}
p = 1ときAerage Pooling
p = 2ときはL2 Pooling
p → $\infty$ときは Max Poolingに相当する
逆伝播:
\frac{\partial y}{\partial x_i} = \frac{|x_i|^{p-1}sign(x_i)}{(\sum|x_j|^p)^{1 - \frac{1}{p}}}
全要素に勾配が流れる
大きな値ほど勾配が大きい
Max Poolより学習が安定
2.実装演習
from torch.autograd import Function
from torch.autograd.function import FunctionCtx
from torch import Tensor
import torch.nn.functional as F
import torch
import math
def im2col(input: Tensor, kernel_size: tuple[int, int], stride=1, padding=0):
"""
(N,C,H,W)
->
(N* out_h* out_w, c* kH* KW)
"""
KH, KW = kernel_size
input_pad = F.pad(input, [padding, padding, padding, padding])
N, C, H, W = input_pad.size()
out_h = (H - KH) // stride + 1
out_w = (W - KW) // stride + 1
col = torch.zeros((N, C, KH, KW, out_h, out_w), device=input.device)
for y in range(KH):
y_max = y + stride * out_h
for x in range(KW):
x_max = x + stride * out_w
col[:, :, y, x, :, :] = input_pad[:, :, y:y_max:stride, x:x_max:stride]
# (N, out_h, out_w, c, KH, KW) -> (N*out_h*out_w, c*kH *KW)
col = col.permute(0, 4, 5, 1, 2, 3).reshape(N * out_h * out_w, -1)
return col
def col2im(
input: Tensor,
output_size: tuple[int, int, int, int],
kernel_size: tuple[int, int],
stride=1,
padding=0,
):
"""
(N* out_h* out_w, c* kH* KW)
->
(N, C, H, W)
"""
N, C, H, W = output_size
KH, KW = kernel_size
H_pad = H + 2 * padding
W_pad = W + 2 * padding
out_h = (H_pad - KH) // stride + 1
out_w = (W_pad - KW) // stride + 1
input = input.view(N, out_h, out_w, C, KH, KW)
input = input.permute(0, 3, 4, 5, 1, 2)
img = torch.zeros((N, C, H_pad, W_pad), device=input.device)
for y in range(KH):
y_max = y + stride * out_h
for x in range(KW):
x_max = x + stride * out_w
img[:, :, y:y_max:stride, x:x_max:stride] += input[:, :, y, x, :, :]
img = img[:, :, padding : H + padding, padding : W + padding]
return img
class Conv2d_(Function):
@staticmethod
def forward(
ctx: FunctionCtx,
input: Tensor,
w: Tensor,
b: Tensor | None,
stride=1,
padding=0,
):
"""
(N, C_out, out_h, out_w)
"""
N, C_in, H, W = input.shape
C_out, C_in, KH, KW = w.shape
# col: (N*out_h*out_w, C*KH*KW)
col = im2col(input, (KH, KW), stride, padding)
# (C*KH*KW, C_out)
w_col = w.reshape(C_out, -1).T
# (N*out_h*out_w, C_out)
out = torch.matmul(col, w_col)
if b is not None:
out += b
out_h = (H + 2 * padding - KH) // stride + 1
out_w = (W + 2 * padding - KW) // stride + 1
# (N, C_out, out_h, out_w)
out = out.reshape(N, out_h, out_w, C_out).permute(0, 3, 1, 2)
ctx.save_for_backward(input, w, col, w_col)
ctx.stride = stride # pyright: ignore[reportAttributeAccessIssue]
ctx.padding = padding # pyright: ignore[reportAttributeAccessIssue]
return out
@staticmethod
def backward(ctx: FunctionCtx, *grad_outputs: Tensor):
input, w, col, w_col = ctx.saved_tensors # type: ignore
stride: int = ctx.stride # pyright: ignore[reportAttributeAccessIssue]
padding: int = ctx.padding # pyright: ignore[reportAttributeAccessIssue]
grad_output = grad_outputs[0]
N, C_out, out_h, out_w = grad_output.shape
# grad_output (N*out_h*out_w, C_out)
grad_output = grad_output.permute(0, 2, 3, 1).reshape(-1, C_out)
dB = grad_output.sum(dim=0)
dW = col.T @ grad_output
dW = dW.T.reshape(w.shape)
dcol = grad_output @ w_col.T
dx = col2im(
dcol, input.shape, (w.shape[2], w.shape[3]), stride, padding
) # pyright: ignore[reportArgumentType]
return dx, dW, dB, None, None
class MaxPool2d_(Function):
@staticmethod
def forward(
ctx: FunctionCtx,
input: Tensor,
kernel_size: tuple[int, int],
stride=None,
padding=0,
):
if stride is None:
stride = kernel_size[0]
KH, KW = kernel_size
N, C, H, W = input.shape
# (N*out_h*out_w, C*KH*KW)
col = im2col(input, (KH, KW), stride, padding)
out_h = (H + 2 * padding - KH) // stride + 1
out_w = (W + 2 * padding - KW) // stride + 1
# (N*out_h*out_w, C, KH*KW)
col = col.reshape(N * out_h * out_w, C, KH * KW)
# pooling
max_val, max_idx = col.max(dim=2)
# (N, C, out_h, out_w)
out = max_val.reshape(N, out_h, out_w, C).permute(0, 3, 1, 2)
ctx.save_for_backward(max_idx)
ctx.input_shape = input.shape
ctx.kernel_size = kernel_size
ctx.stride = stride
ctx.padding = padding
return out
@staticmethod
def backward(ctx: FunctionCtx, *grad_outputs: Tensor):
(max_idx,) = ctx.saved_tensors
N, C, H, W = ctx.input_shape
KH, KW = ctx.kernel_size
stride = ctx.stride
padding = ctx.padding
grad_out = grad_outputs[0] # (N, C, out_h, out_w)
out_h = (H + 2 * padding - KH) // stride + 1
out_w = (W + 2 * padding - KW) // stride + 1
# (N*out_h*out_w, C)
grad_out = grad_out.permute(0, 2, 3, 1).reshape(-1, C)
# (N*out_h*out_w, C, KH*KW)
dcol = torch.zeros(
(grad_out.size(0), C, KH * KW),
device=grad_out.device,
dtype=grad_out.dtype,
)
# scatter 勾配
dcol.scatter_(
2,
max_idx.unsqueeze(2),
grad_out.unsqueeze(2),
)
# (N*out_h*out_w, C*KH*KW)
dcol = dcol.reshape(-1, C * KH * KW)
# (N, C, H, W)
dx = col2im(dcol, (N, C, H, W), (KH, KW), stride, padding)
return dx, None, None, None
if __name__ == "__main__":
torch.manual_seed(42)
input = torch.randint(0, 5, (1, 1, 3, 3)).float()
print(input)
print("------------")
col = im2col(input=input, kernel_size=(2, 2), padding=1, stride=1)
print(col)
print("--------------")
img = col2im(
col, input.shape, kernel_size=(2, 2), padding=1, stride=1
) # pyright: ignore[reportArgumentType]
print(img)
from torch.nn import Module
from torch import Tensor
from ..functional import MaxPool2d_
class MaxPool2d(Module):
def __init__(
self,
kernel_size: tuple[int, int],
stride=None,
padding=0,
):
super().__init__()
self.kernel_size = kernel_size
self.stride = kernel_size[0] if stride is None else stride
self.padding = padding
def forward(self, input: Tensor):
return MaxPool2d_.apply(input, self.kernel_size, self.stride, self.padding)
import torch
from torch.nn import Parameter, Module
from torch import Tensor
from ..functional import Conv2d_
class Conv2d(Module):
def __init__(
self,
in_channels: int,
out_channels: int,
kernel_size: tuple[int, int],
stride: int = 1,
padding: int = 0,
bias=True,
):
super().__init__()
self.w = Parameter(torch.randn(out_channels, in_channels, *kernel_size) * 0.01)
self.b = (
Parameter(
torch.zeros(
out_channels,
)
)
if bias
else None
)
self.stride = stride
self.padding = padding
def forward(self, input: Tensor):
return Conv2d_.apply(input, self.w, self.b, self.stride, self.padding)
# %%
import torch
from torch import Tensor, device
# 乱数を固定する(別にしなくても大丈夫です)
def set_seed(seed: int):
torch.manual_seed(seed)
set_seed(42)
# 今の実行環境を表示する
current_device = device("cuda" if torch.cuda.is_available() else "cpu")
print(current_device)
# %%
# データをダウンロードし、 ToTensorで[0,1]の範囲に正規化してdataディレクトリに保存する
from torchvision import datasets, transforms
data_transforms = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(0, 1)
])
train_dataset = datasets.MNIST(
root="./data",
train=True,
transform=data_transforms,
download=True
)
test_dataset = datasets.MNIST(
root="./data",
train=False,
transform=data_transforms,
download=True
)
# %%
# DataLoaderを使ってダウンロードしたデータをメモリに読み込ませる
batch_size = 64
from torch.utils.data import DataLoader
train_loader = DataLoader(
train_dataset,
batch_size=batch_size,
shuffle=False
)
test_loader = DataLoader(
test_dataset,
batch_size=batch_size,
shuffle=False
)
# %%
# データを可視化する
import matplotlib.pyplot as plt
from matplotlib.axes import Axes
import math
imgs: Tensor
labels: Tensor
imgs, labels = next(iter(train_loader))
sqrt_bs = int(math.sqrt(batch_size))
figure = plt.figure(figsize=(1.25 * sqrt_bs, 1.5 * sqrt_bs))
axes: list[Axes] = figure.subplots(sqrt_bs , sqrt_bs).flatten()
for i, ax in enumerate(axes):
ax.imshow(imgs[i].squeeze(), cmap="gray")
ax.set_title(f"label={labels[i].item()}")
ax.axis("off")
plt.tight_layout()
plt.show()
# %%
# 自分で書いたModelパーツを使って最小VGGを組み込んでみよう
from etorch import nn
from torch.nn import Module
from torch import Tensor
torch.nn.Dropout()
class MnistVGG(Module):
def __init__(self):
super().__init__()
self.features = torch.nn.Sequential(
nn.Conv2d(1, 32, (3, 3), stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d((2, 2), 2),
nn.Conv2d(32, 64, (3, 3), stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2d((2, 2), 2)
)
self.classifier = torch.nn.Sequential(
nn.Linear(64 * 7 * 7, 128),
nn.ReLU(),
nn.Linear(128, 10)
)
def forward(self, input: Tensor):
input = self.features(input)
input = input.reshape(input.size(0), -1)
input = self.classifier(input)
return input
# %%
# MnistNetとクロスエントロピー誤差をインスタンスする
import etorch.optim as optim
model = MnistVGG()
model = model.to(current_device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(),lr=0.01, momentum=0.9, weight_decay=0.0001)
print(model)
# %%
# モデルを訓練そして訓練の誤差と正解率を出力する
import etorch.nn.functional as F
def train(model: MnistVGG, train_loader: DataLoader, cross_entropy_loss: nn.CrossEntropyLoss, optimizer: optim.SGD, epochs: int):
model.train() # モデルを訓練モードに設定する
for epoch in range(epochs):
total_loss = 0
correct = 0
total = 0
for imgs, labels in train_loader:
imgs = imgs.to(current_device)
labels = labels.to(current_device)
optimizer.zero_grad()
outputs = model(imgs)
one_hots_labels = F.one_hot(labels, 10)
loss = cross_entropy_loss(outputs, one_hots_labels)
loss.backward()
optimizer.step()
total_loss += loss.item()
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
avg_loss = total_loss / len(train_loader)
accuracy = 100 * correct / total
print(f"Epoch [{epoch+1}/{epochs}], Loss: {avg_loss:.4f}, TrainAccuracy: {accuracy:.2f}%")
train(model, train_loader, criterion, optimizer, 50)
# %%
# テストデータを使ってモデルを評価する
def evaluate(model: Module, test_loader: DataLoader):
model.eval() # 評価モードに設定する
correct = 0
total = 0
with torch.no_grad():
for imgs, labels in test_loader:
imgs = imgs.to(current_device)
labels = labels.to(current_device)
outputs = model(imgs)
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = 100 * correct / total
print(f"TestAccuracy: {accuracy:.2f}%")
return accuracy
evaluate(model, test_loader)
# %%
# 予測結果を可視化
model.eval()
imgs, labels = list(test_loader)[2]
with torch.no_grad():
imgs: Tensor = imgs.to(current_device)
# print(imgs.size())
outputs = model(imgs)
_, predicted = torch.max(outputs, 1)
figure = plt.figure(figsize=(sqrt_bs * 1.4, sqrt_bs *1.6))
axes: list[Axes] = figure.subplots(sqrt_bs , sqrt_bs).flatten()
for i, ax in enumerate(axes):
ax.imshow(imgs[i].squeeze().cpu(), cmap="gray")
true_label = labels[i].item()
pred_label = predicted[i].item()
# 正解なら緑、不正解なら赤
color = 'green' if true_label == pred_label else 'red'
ax.set_title(f"True: {true_label}, Pred: {pred_label}", color=color)
ax.axis("off")
plt.tight_layout()
plt.show()
実行結果(一部)


3.確認テスト
サイズ6x6の入力画像を、サイズ2x2のフィルタで畳み込んだ時の出力画像のサイズを答えよ。なおストライドとパディングは1とする。
\frac {6 - 2 + 2 \times 1}{1} + 1 = 7
答えは7x7です
Section5 最新のCNN
1.要点
2012年にILSVRC(ImageNetを用いた世界的な画像認識コンペ)で非Deepな手法を圧倒したモデル。
基本的には畳み込みx5、全結合x3の合計8層
活性化はReLUを利用、ドロップアウトを利用
ZCA白色化
GPU複数枚に分割(メモリが当時はすくなかったため)

【参考文献】
<< 書籍 >>
1.機械学習(1), Tatsuro Fukuda (日本電子専門学校 2025)
2.ディープラーニングE資格精選問題集、小林範久、小林寛幸
3.Skillupディープラーニング基礎講座