はじめに
2020年はCOVID-19の影響でリモートワークの機会が増え、Web会議も盛んに行われたことと思います。
私はWebカメラに写っている自分の顔に画像を合成し、ミーティング画面に出力することで、某キャラクターのように参加者の視界をハックするという遊びをやっていました。
(もちろんラフなミーティングの時だけ。)
今回はその方法ついて記載したいと思います。
環境
HW
- MacBook Pro 13inch
- MacOS Catalina 10.15.7
SW
- Python 3.6.10
- Zoom 5.1.0
- CamTwist 3.4.3
- 仮想カメラとして使用
使用する画像
検出した顔に合成する画像は以下のものを使用します。

どこかで見たことあるような気がするけど気にしない。
手順
まずWebカメラの画像をPythonで取り込み、画像内の顔を検出します。
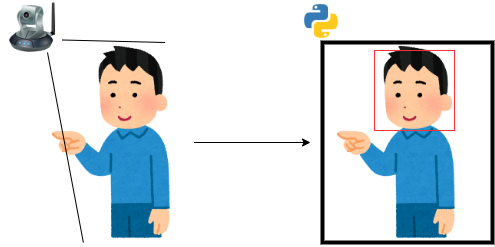
検出した顔の上に画像を合成し、ウィンドウに出力します。

上記の手順を繰り返すことによって映像としてウィンドウに出力し続けます。
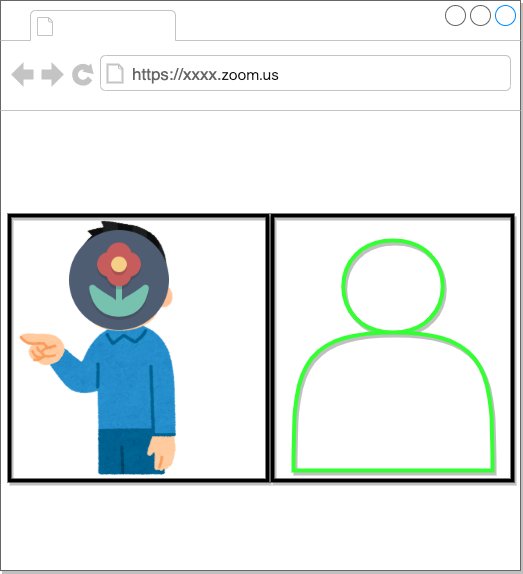
ウィンドウをCamTwistでVideo Sourceに指定し、zoomのカメラデバイスとしてCamTwistを指定します。
これでミーティング画面には合成処理を行なった映像が映ります。
コード
ソースコードはこちら。
ソースファイルと同じディレクトリにpng画像郡を配置したディレクトリを配置します。
(OpenCVでgif画像を読み込むときにアルファチャネルを読み込む方法がわからなかったので愚直にpngに分解しました。)
.
├─ laugh.py
└─ src
├─ laugh00.png
.
.
└─ laugh44.png
以下に主要部分の抜粋を記載します。
下準備
使用するライブラリをインポートします。
import cv2
import numpy as np
Webカメラの映像を取り込むためにデバイスを指定します。
今回はMacBook Proの内蔵カメラを使用します。
cap = cv2.VideoCapture(2)
画像内の顔を認識するために、Haar-like特徴ベースのCascade型分類器を使った検出方法を使用することにしました。
OpenCVでは上記の検出機能を提供しているので、XMLファイルから顔の識別器を読み込んでおきましょう。
cascade_path = "path/to/haarcascade_frontalface_alt.xml"
cascade = cv2.CascadeClassifier(cascade_path)
次に合成する画像ファイルを読み込みます。
取り込む画像ファイルのファイル名を指定し、cv2.imread()で画像データを取得します。
2つ目の引数の-1はアルファチャネルを読み込むためのもので、この返り値の画像データはBGRαの4チャネルとなります。
画像を読み込んだあとに、縦横の比率を維持したままリサイズ行い、リストに追加しています。
for i in range(0,image_number):
src = "src/laugh" + str(i).zfill(2) + ".png"
img = cv2.imread(src,-1)
rate = img.shape[0] / img.shape[1]
img = cv2.resize(img,(img_size,int(img_size*rate)))
img_list.append(img)
カメラ画像の取り込み
MacBook Proの内蔵カメラから画像を取得します。
cap.read()は画像の読み込みの成功を示すbool型retを返し、読み込みに成功した際には画像データframeを取得できます。
frameはnumpyのndarrayオブジェクトとなっています。
ret, frame = cap.read()
顔の検出
顔の検出にはHaar-like特徴を使用しています。
この特徴は顔の色の濃淡に基づくもので、例えば目は暗く頬は明るい、口は暗く顎は明るい、といった特徴などを用いています。
OpenCVはこの特徴を使用した検出方法を提供しており、引数によって検出精度と計算量が決まります。
処理が重くならないような値で調整しました。
下記の1行では「画像内で顔を検出した矩形領域の左上の座標と高さ、幅[x,y,h,w]を格納したリスト」のリストが返されます。
facerect = cascade.detectMultiScale(frame, scaleFactor=1.1, minNeighbors=2, minSize=(250,250))
画像の合成
合成のための準備として、合成用の画像のアルファチャネルだけをmaskとして抜き取り、残りの3チャネルBGRをimgに格納します。
アルファチャネルは色情報ではなく、0~255の値を取り、255の場合は透過せず、0に近づくに連れて透明になるといった情報です。
後にBGRの3チャネルと計算を行うため、アルファチャネルを1チャネルから3チャネルに拡張しておきます。
mask = img[:,:,3]
mask = cv2.cvtColor(mask,cv2.COLOR_GRAY2BGR)
img = img[:,:,:3]
背景画像の顔を検出した座標から、画像を合成する矩形領域の左上の座標を決定します。
背景画像内での顔の左上の座標と高さ、幅のリスト(下ではrect)は与えられているので、顔の中心座標と、合成する画像の高さ・幅から求めます。
x = int((rect[1] + rect[3] / 2) - (width / 2))
y = int((rect[0] + rect[2] / 2) - (height / 2))
合成する際はmaskを0~255の値から0~1.0の範囲に直し、合成する画像に掛けます。
背景画像には 1-mask を掛け、双方を足し合わせます。
try:
frame[x:x+width,y:y+height] = np.uint8(frame[x:x+width,y:y+height] * (1 - mask / 255.0))
frame[x:x+width,y:y+height] = frame[x:x+width,y:y+height] + np.uint8(img * (mask / 255.0))
except:
pass
ウインドウ出力
最後に合成した画像frameをウィンドウに出力します。
cv2.imshow('laugh',frame)
カメラ画像の取り込みからウィンドウ出力までを繰り返すことによって映像として出力することができます。
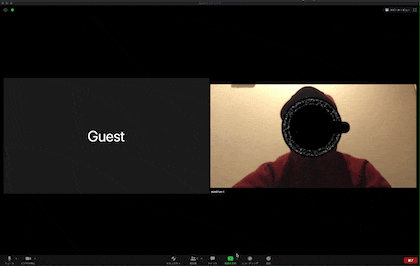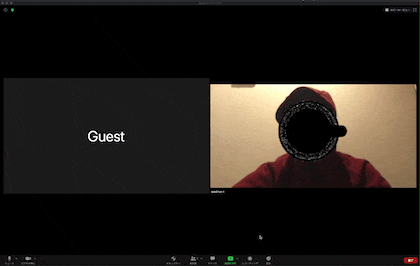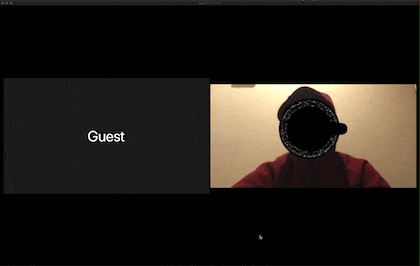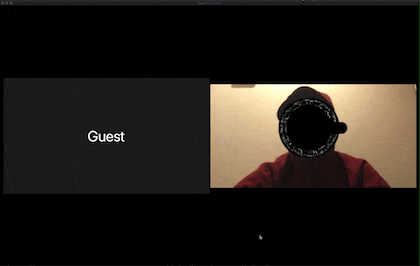
以下の画像が実際の出力結果です。

ミーティング画面にカメラ入力として渡す
CamTwistを起動し、Pythonのプロセスを動かしている状態でvideo sourcesからDesktop+を選択し、selectを押下します。
Confine to Application Windowにチェックボックスをつけてpythonのウィンドウを選択してから、Select capture areaで領域を調整します。
ここまで済ませたらzoomの設定でカメラを選択します。
プルダウンメニューでCamTwistと表示されているかと思います。
すると以下のように参加者の視界はハックされます。
最後に
「映っている顔に画像を合成する」ということがやりたかったのではなく、合成する画像のほうが重要でした。
ノリのいい人は、俺の目を盗みやがったな!!とか言ってくれそうです。
ちなみにこれを使って遊んでたのは4月頃で、当時はWebexで使用していました。
ただ、今は仮想カメラの使用ができないようになっています。