Redis のメモリが足りなくなった時にどうやってチューニングしたか
Redis は便利なのですが、メモリが半分しか使用出来ないという問題が有ります。
非同期でファイルの書き込みを行う際に、メモリのスナップショット(コピー)を取るために、その分の空きメモリが必要なのです。
[ここ] (http://qiita.com/eccyan/items/b44fee413c285907cd6c)に Redis のソースコードのコメントを翻訳したものを置いておきます。
今回、メモリの空きが足りなくなったのは、準永続的な情報用のサーバと利用している物で、簡単に消すことは出来ませんでした。
そこで Redis のメモリダンプを解析し、利用していないキーの削除やデータ型の変更を行うことにしました。
メモリの解析
メモリダンプはそのままでは人間には理解不能なので、ローカルにdump.rdbファイルをコピーし、 [Rdbtools] (https://github.com/sripathikrishnan/redis-rdb-tools) を利用してCSVに出力し、そこから必要なデータに整形しました。
$ rdb -c memory dump.rdb > redis_memory.csv
# バイトサイズとキーの個数と単位バイトサイズを出す
$ cat redis_memory.csv | sed -E "1d" | sed -E 's/:[0-9]+(:|")/:{id}\1/g' | cut -d ',' -f 3,4 | awk -F ',' '{ sum[$1] += $2; count[$1] += 1 } END { for (key in sum) print key, sum[key], count[key], sum[key] /count[key] }' > redis_memory_status.csv
user/123456/abc形式のキーなので、上記の様なコマンドで集計を取りました。
整形後にそれぞれの数値でソートし、チューニングを行うデータを割り出します。
今回の場合、未使用のキーが幾つかありましたが、それ以上に「投稿の履歴」が 9GB 位の容量を占めていました・・・。
チューニング
投稿の履歴は JSON で表すと、以下の様な配列形式でした。
[{ question_id: <INTEGER>
accessed_at: <STRING>
}
, // …
]
これが Ruby のハッシュをシリアライズした文字列で保存されており、それがユーザ単位毎に8MBも消費していたのです!
これではサーバを増築したとしても、とても身が持ちませんね・・・。
ところで、Redis にはメモリのエンコーディング方法が 2 種類があります。
skiplist と ziplist(intset) があり、後者だと圧縮展開を行う CPU コストとトレードオフで、メモリの圧縮を行ってくれます。 intset は Set の場合に使われるようです。
どのようなエンコードを行っているかは、以下のコマンドで確認が可能です。
redis> object encoding <KEY>
これらのエンコードを適用する条件設定は Redis のコンフィグで行う事が出来ます。
hash-max-zipmap-entries 64 (hash-max-ziplist-entries for Redis >= 2.6)
hash-max-zipmap-value 512 (hash-max-ziplist-value for Redis >= 2.6)
list-max-ziplist-entries 512
list-max-ziplist-value 64
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
set-max-intset-entries 512
これに収まるようにデータ型を変更すれば、メモリは相当圧縮出来るはずですね。
これらを踏まえて今回は先ほどの大食らいを 2 つのリストに分割し、さらに日付もタイムスタンプに変更しました。
この対応により、サイズは最大で 1/10 程度まで圧縮される予定です。
その経過が下図になります。
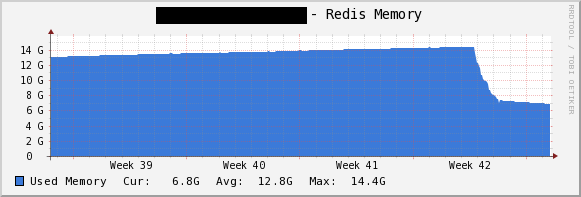
ガツンと下がっています。
ziplist(intset) は Hash/List/Set/SortedSet に使えますので Redis を活用している方はチューニングしてみてください。
Shared Memory
さて、上記で我々の Redis は救われましたが、ユーザの投稿内容やもっと莫大なリストを管理している方は手におえませんね。
しかし、解決策があります。
以下の記事の様にデータを複数分割して保存する方法があります。
http://mocobeta-backup.tumblr.com/post/84793291682/redis-set
もちろん、仕組みを用意しなければならなく、CPUコストは高くなりますが、メモリに困っていたら利用してみてはいかがでしょうか?
総括
そもそもこの対応、最初から横着せずにデータ型に注意を払っていればよかったという話。
参考
Special encoding of small aggregate data types
http://redis.io/topics/memory-optimization
Redis RDB Dump File Format
https://github.com/sripathikrishnan/redis-rdb-tools/wiki/Redis-RDB-Dump-File-Format