はじめに
2026/4/7、AWSから新サービス「Amazon S3 Files」が発表されました!これはS3バケットをファイルシステムとしてマウントできるようになるサービスで、接続部分はAmazon EFSという特殊な構造になっています。
私は昔から「CloudShellの1GB制限のせいで terraform init ができない問題」に困っていました。そこで「もしS3 FilesがCloudShellでマウントできれば、容量問題が一発解決するのでは?」と思いつき、実際に検証してみました。
結論から先に言うと、マウント自体は条件付きで成功し、terraform initまで完走できました。ただし、当初の目的(CloudShellの容量制限突破)については想定外の肩透かしオチが待っていたので、その経緯と道中で得た学びを記録として残しておきます。
本記事の検証は Amazon Linux 2023 ベースの CloudShell(VPC外モード・VPC内モード両方)で実施しています。
結論
- VPC外CloudShellからS3 Filesはマウント不可能(ユーザーVPCのENIに到達できない、設計上の壁)
- VPC内CloudShellからS3 Filesはマウント可能!ただし以下の回避策が必要
- fsnameにフルFQDNを渡してIMDS呼び出しをバイパス
- CloudShellの認証情報を
/root/.aws/credentialsに書き込み - 15分ごとに認証情報を再取得して再マウントが必要(efs-proxyがIAMを継続使用するため)
-
terraform initはS3 Files上で完走成功(.terraform=675MB、/home消費ゼロ)
そしてこの記事の最大のオチ
当初の目的(CloudShellの1GB制限回避)は、VPC内CloudShellを使うだけで自動的に達成されてしまう。。。
後述しますがVPC外CloudShellの「1GB制限」の正体は/dev/loop0というループバックファイルで、VPC内モードにはこのループバックが存在せず、/homeの16GBがそのまま使えます。つまり「S3 Filesで容量問題を解決しようとしたら、S3 Filesを使うまでもなく問題が消えていた」という壮大な肩透かしオチでした。
とはいえ寄り道の中で、S3 Filesの内部構造、mount.s3filesの実装、CloudShellの認証情報の仕組みなど、いろいろと面白い発見があったので、そのあたりを本編としてまとめていきます。
S3 Filesとは
公式ドキュメントによると、S3 Filesは以下の特徴を持ちます
- 中身はAmazon EFS:「Built using Amazon EFS」と明記されている
- NFS v4.1+ プロトコルでマウント可能
- マウントターゲットをユーザーVPC内のサブネットに作成し、ENI経由でアクセス ←今回はこの仕様に負けました。
- 対応コンピュートは EC2 / ECS / EKS / Lambda(CloudShellは実は公式対象外)
- ファイル操作はバックエンドのS3バケットに自動同期される
- 高性能ストレージ層にホットデータをキャッシュ
つまり「S3バケットの皮を被ったEFSのようなもの」と理解するとわかりやすそうです。
CloudShellのストレージ事情を再確認
検証前に、CloudShellの2モードでストレージ構成がどう違うかを df -Th で確認しています。
VPC外モード(通常CloudShell)
~ $ df -Th
Filesystem Type Size Used Avail Use% Mounted on
overlay overlay 16G 5.9G 9.0G 40% /
tmpfs tmpfs 64M 0 64M 0% /dev
shm tmpfs 64M 0 64M 0% /dev/shm
/dev/nvme1n1 ext4 16G 5.9G 9.0G 40% /home
/dev/loop0 ext4 974M 208K 907M 1% /home/cloudshell-user
/dev/nvme0n1p1 xfs 30G 4.8G 26G 16% /aws/mde/mde
VPC内モード
~ $ df -Th
Filesystem Type Size Used Avail Use% Mounted on
overlay overlay 16G 5.9G 9.0G 40% /
tmpfs tmpfs 64M 0 64M 0% /dev
shm tmpfs 64M 0 64M 0% /dev/shm
/dev/nvme1n1 ext4 16G 5.9G 9.0G 40% /home
/dev/nvme0n1p1 xfs 30G 4.8G 26G 16% /aws/mde/mde
「1GB制限」の正体は、/home/cloudshell-user だけにマウントされている /dev/loop0 のループバックファイルでした。VPC内モードではこのループデバイスがそもそも存在しないので、/home の16GBがそのまま使えるという話のようです。
ループバックファイルって?
普通のファイル(例:1GBの.imgファイル)を、あたかもブロックデバイス(=ディスク)のように扱う仕組みのことです。losetupやmount -o loopで作れます。
CloudShell(VPC外モード)では、親の16GBストレージの中に974MBのループバックファイルを作って、それを/home/cloudshell-userにマウントしています。だから「ファイル実体は親ディスクにあるけど、ユーザーから見ると独立した974MBのファイルシステムに見える」という構造になっているようです。
この設計のメリットは、ユーザーごとの容量を厳格に区切れること(親ディスク全体ではなくループファイルのサイズが上限になる)。CloudShellの「1GB制限」はAWS側のクォータ制御ではなく、ループバックファイルのサイズそのものだったというわけです。
つまりVPC内モードにすれば容量問題は実は解決する、ただ今回は「VPC外モードでも何とかしたい」「S3 Filesの機能検証もしたい」という二兎を追って、両方のパターンで検証してみることにしました。
検証ストーリー:2パターンの対比
検証は以下の2パターンで実施しました
| パターン | 環境 | 期待 |
|---|---|---|
| パターン1 | VPC外CloudShell | おそらく失敗するが、その理由を見届ける |
| パターン2 | VPC内CloudShell | 本命。マウント成功 → terraform init成功まで持っていく |
事前準備:S3 Filesの作成
検証に入る前に、まずはマネジメントコンソールからS3 Filesを作っていきます。手順自体はシンプルで、ポチポチっと数クリックで終わります。
Step 1:S3 Filesのメニューに入る
S3コンソールの左ペインに「ファイル」というカテゴリが追加されていて、その配下に「ファイルシステム」メニューが生えています。ここから作成画面に進んでいきます。
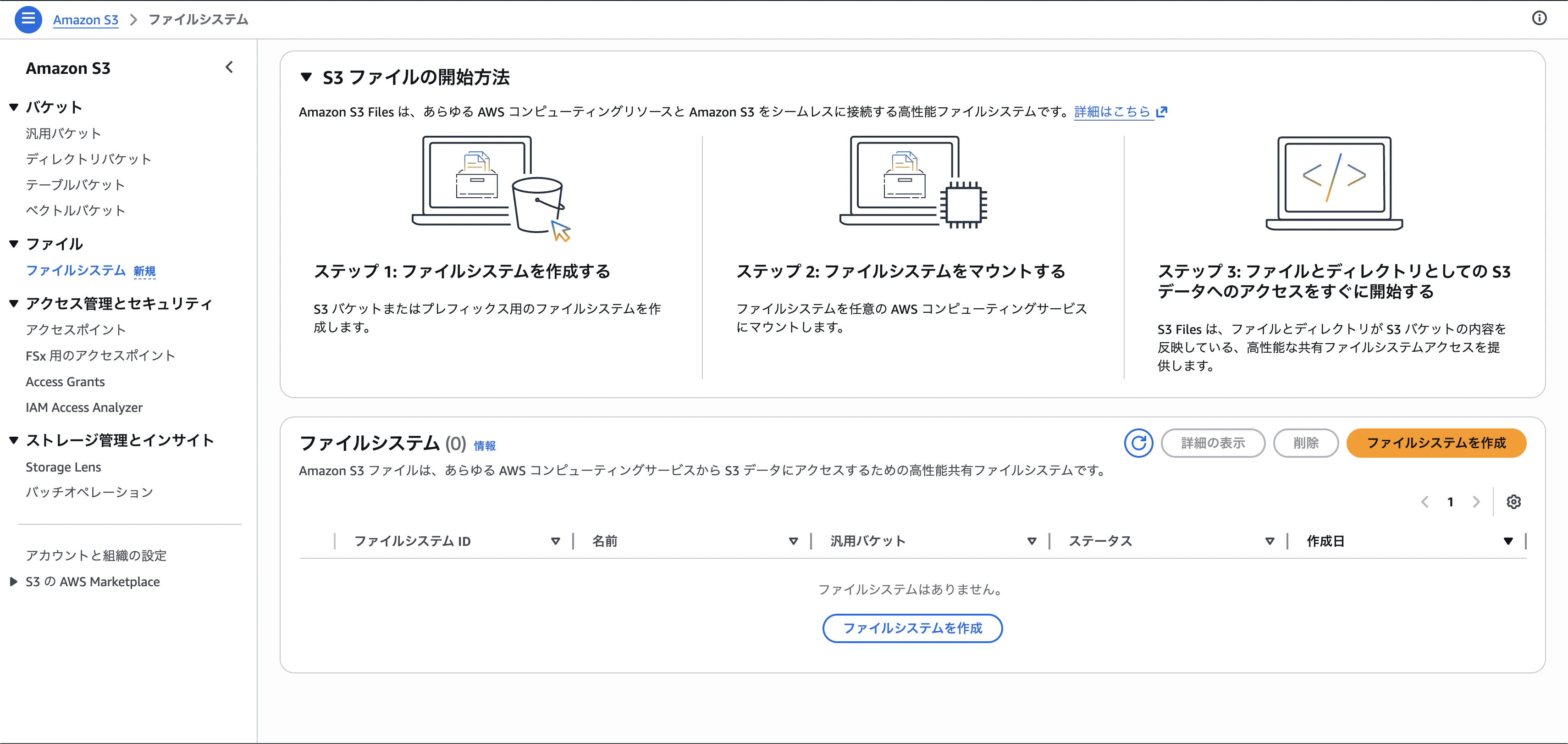
右上の「ファイルシステムを作成」ボタンを押すと、作成フォームが開きます。
Step 2:バケット・VPC・タグを設定
入力項目は少なくて、以下の3つだけ。
- 汎用バケットまたはプレフィックス:
s3://<バケット名>形式で指定。実体としてはS3バケットがバックエンドになる- あくまで既存のS3バケットをファイルシステムとして接続できるようにする、という機能のため、S3バケット自体は事前に作成が必須!!
- 仮想プライベートクラウド(VPC):マウントターゲットを作成するVPCを選択
- タグ - オプション:ファイルシステム名にあたるタグ(
Nameキーなど)を任意で付与
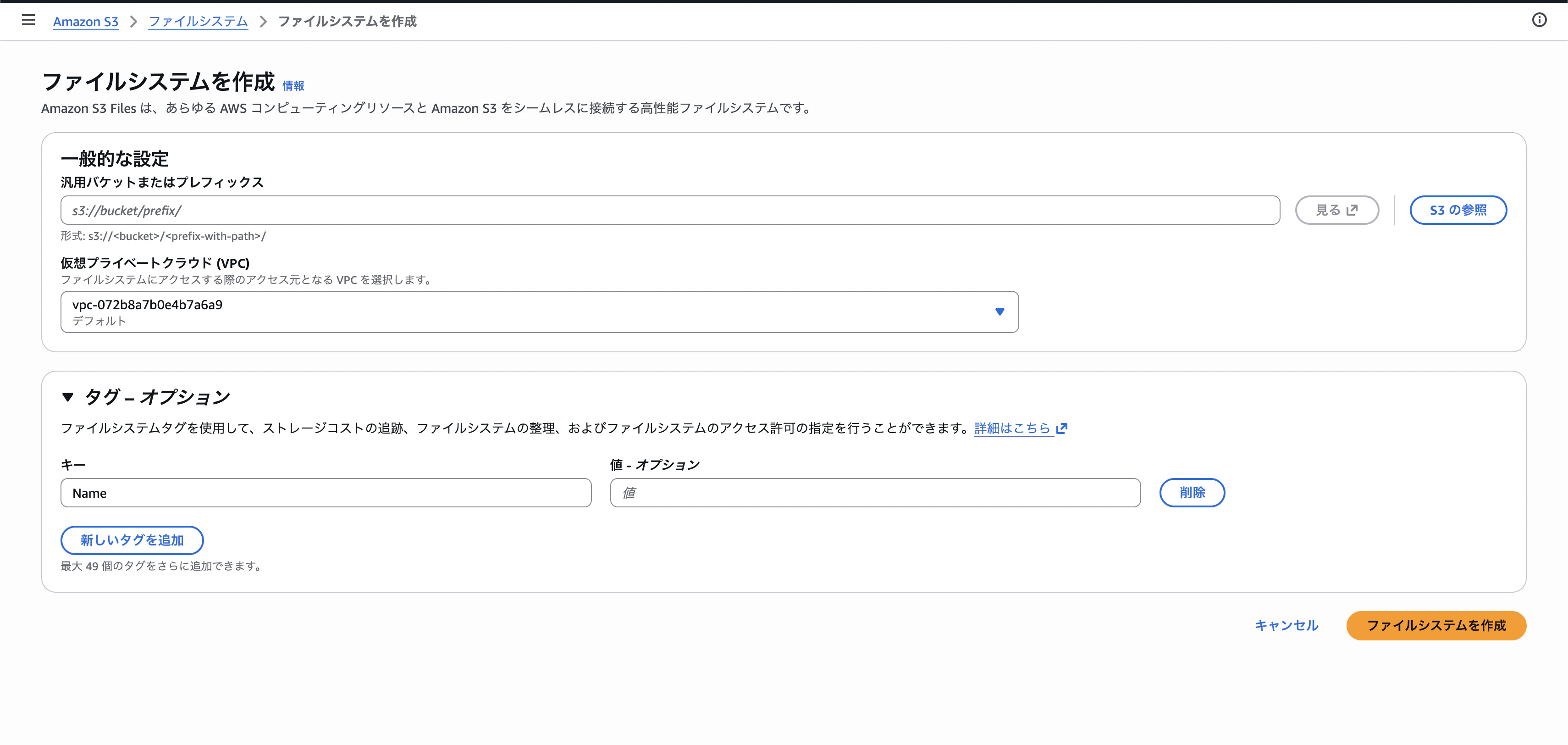
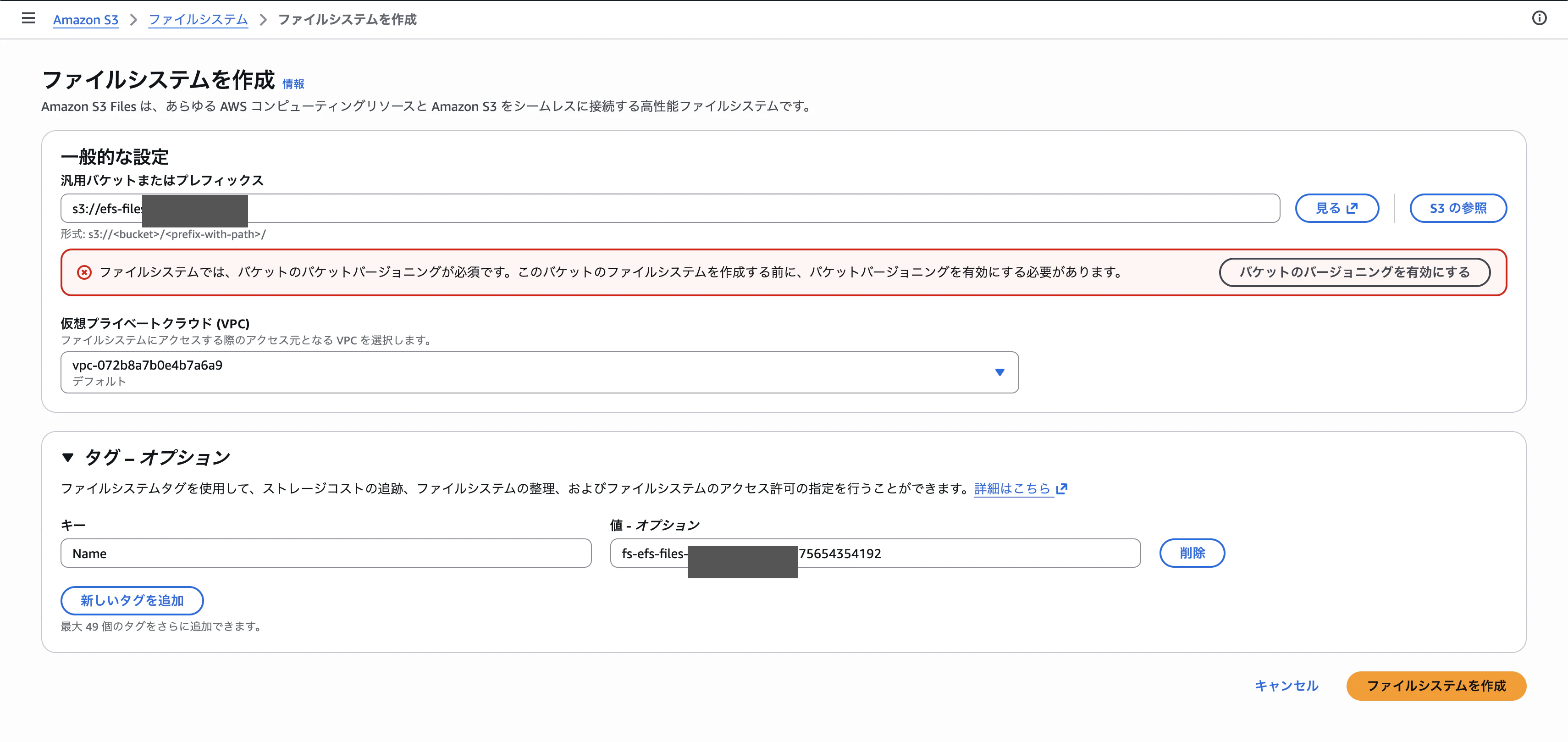
Step 3:バージョニングの注意書き
バケット名を入れると、対象のS3バケットでバージョニングが有効になっていない場合に警告が出ます。S3 Filesはどうやら内部的にバージョニング前提で動くようで、ここで素直に有効化しておくことが求められます。
もちろん、事前にバージョニングが有効なS3バケットを指定してもOK。
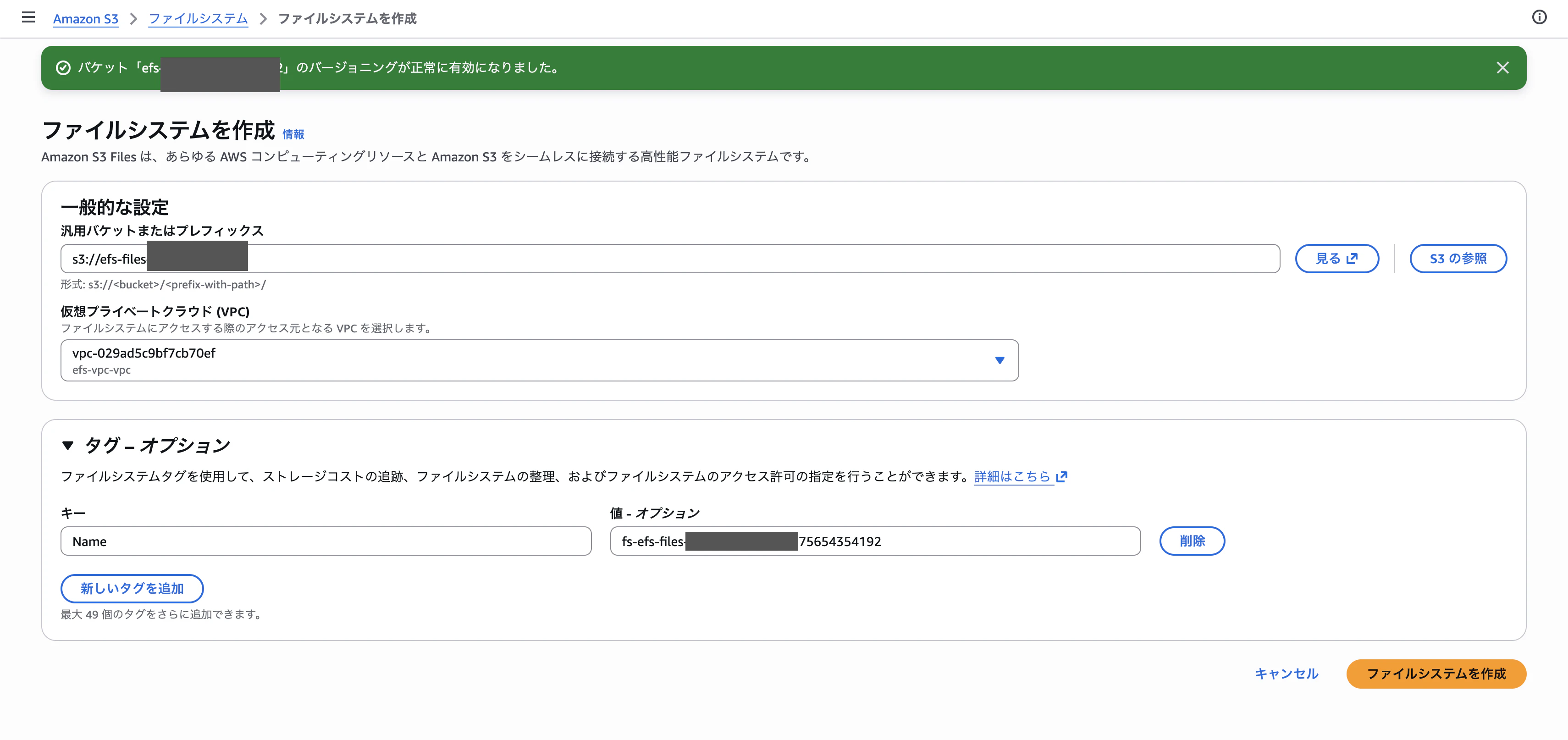
Step 4:マウントターゲットのサブネットを選ぶ
VPCを選ぶと、その中のサブネットを選択する画面に進んでいきます。マウントターゲットを作りたいAZのサブネットを選択します(後でCloudShell VPC環境からアクセスするので、CloudShellと同じVPCのサブネットを選ぶことがポイント)。
Step 5:作成完了 → ファイルシステムIDが払い出される
数秒待つとステータスがAvailableになり、ファイルシステムが完成します。ここで払い出されたfs-xxxxxxxx形式のIDが、以降のマウント作業で必要になるので控えておくと後が楽になります。
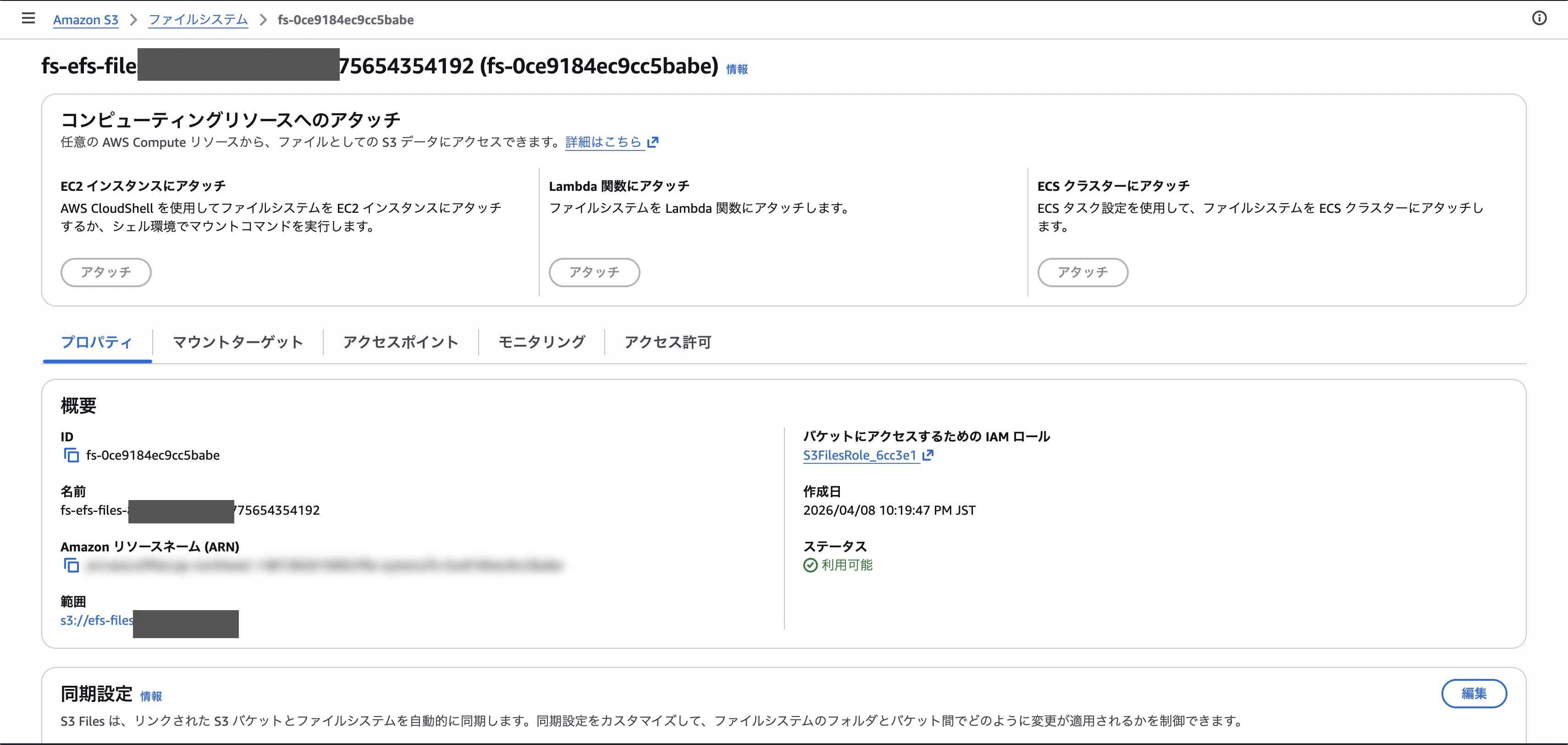
Step 6:自動生成されたIAMロールを確認
S3 Files作成時、裏側でサービスリンクロールが自動的に作られます。これはIAMコンソールからS3FilesRoleという名前で確認できます。中身を触る必要はありませんが、「あ、こういうロールが生えてるんだ」と知っておくと安心です。
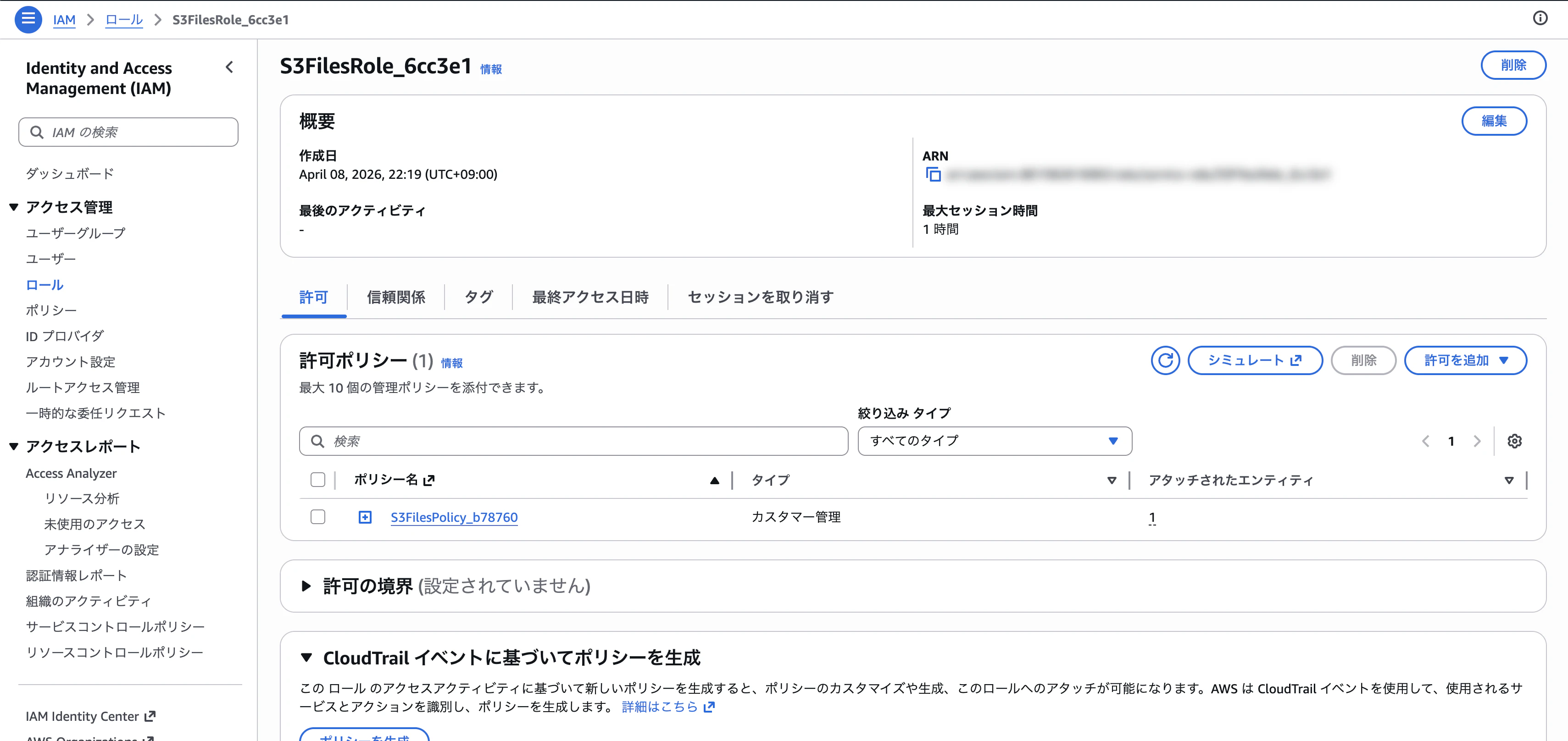
IAMポリシーの中身
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "S3BucketPermissions",
"Effect": "Allow",
"Action": [
"s3:ListBucket*"
],
"Resource": "arn:aws:s3:::efs-files-xxxxxxxxxxxxxxxx",
"Condition": {
"StringEquals": {
"aws:ResourceAccount": "xxxxxxxxxxxxxxxx"
}
}
},
{
"Sid": "S3ObjectPermissions",
"Effect": "Allow",
"Action": [
"s3:AbortMultipartUpload",
"s3:DeleteObject*",
"s3:GetObject*",
"s3:List*",
"s3:PutObject*"
],
"Resource": "arn:aws:s3:::efs-files-xxxxxxxxxxxxxxxx/*",
"Condition": {
"StringEquals": {
"aws:ResourceAccount": "xxxxxxxxxxxxxxxx"
}
}
},
{
"Sid": "UseKmsKeyWithS3Files",
"Effect": "Allow",
"Action": [
"kms:GenerateDataKey",
"kms:Encrypt",
"kms:Decrypt",
"kms:ReEncryptFrom",
"kms:ReEncryptTo"
],
"Condition": {
"StringLike": {
"kms:ViaService": "s3.ap-northeast-1.amazonaws.com",
"kms:EncryptionContext:aws:s3:arn": [
"arn:aws:s3:::efs-files-xxxxxxxxxxxxxxxx",
"arn:aws:s3:::efs-files-xxxxxxxxxxxxxxxx/*"
]
}
},
"Resource": "arn:aws:kms:ap-northeast-1:xxxxxxxxxxxxxxxx:*"
},
{
"Sid": "EventBridgeManage",
"Effect": "Allow",
"Action": [
"events:DeleteRule",
"events:DisableRule",
"events:EnableRule",
"events:PutRule",
"events:PutTargets",
"events:RemoveTargets"
],
"Condition": {
"StringEquals": {
"events:ManagedBy": "elasticfilesystem.amazonaws.com"
}
},
"Resource": [
"arn:aws:events:*:*:rule/DO-NOT-DELETE-S3-Files*"
]
},
{
"Sid": "EventBridgeRead",
"Effect": "Allow",
"Action": [
"events:DescribeRule",
"events:ListRuleNamesByTarget",
"events:ListRules",
"events:ListTargetsByRule"
],
"Resource": [
"arn:aws:events:*:*:rule/*"
]
}
]
}
Step 7:マウントターゲットの詳細確認
作成したファイルシステムの詳細画面で、マウントターゲットタブを開くと、IPアドレス・サブネット・SG・AZが確認できます。CloudShellからマウントするときに必要な情報がここに全部揃っています。
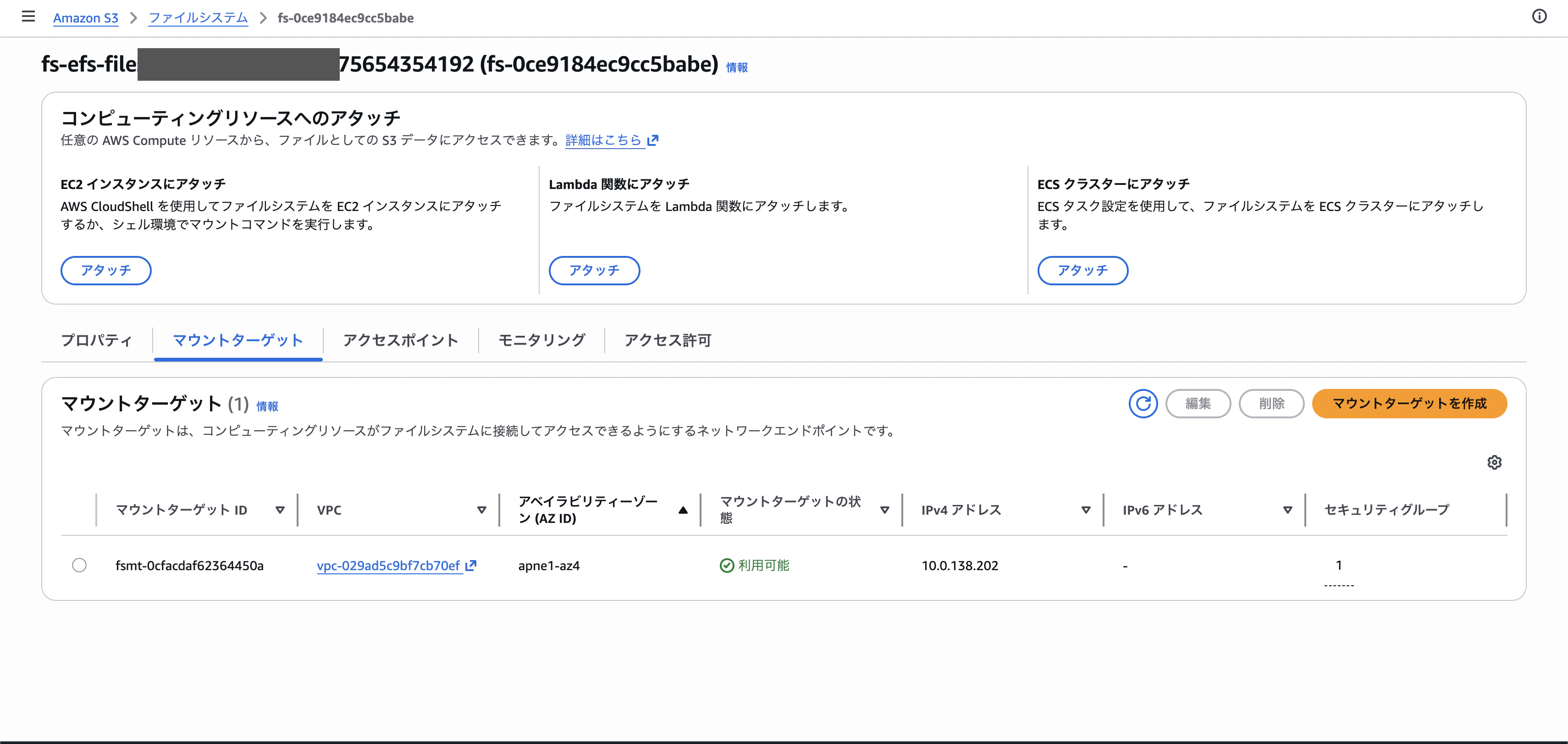
今回の検証で使うリソース情報
以上の手順で出来上がったリソースは以下の通りです。これらの値が以降のCloudShell検証で必要になります。
- ファイルシステムID:
fs-0ce9184ec9cc5babe - マウントターゲットID:
fsmt-0cfacdaf62364450a - マウントターゲットIP:
10.0.138.202 - VPC:
vpc-029ad5c9bf7cb70ef - サブネット:
subnet-0e72565cd0f34c12a - AZ:
apne1-az4 - マウントターゲットSG:
sg-0071cc82388c974a4
注意:マウントターゲットのSGは初期状態だとインバウンドが空っぽなので、後ほどNFS(TCP/2049)を許可しないと疎通できません。これがパターン2のStep 3でハマるポイントになりました。。。
パターン1:VPC外CloudShellで「失敗を見届ける」検証
Step 1:CloudShell環境の事前確認
~ $ ip route
default via 172.31.255.193 dev eth0
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1 linkdown
172.31.255.192/26 dev eth0 proto kernel scope link src 172.31.255.194
~ $ ip -4 addr show | grep inet
inet 127.0.0.1/8 scope host lo
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
inet 172.31.255.194/26 brd 172.31.255.255 scope global eth0
~ $ cat /etc/resolv.conf
search ap-northeast-1.compute.internal
nameserver 127.0.0.11
options ndots:0
CloudShellは 172.31.255.0/26 というAWS管理レンジに居て、ユーザーのVPCとは完全に別世界であることが確認できました。DNSも 127.0.0.11(Dockerの内部DNSを指しています)。
Step 2:マウント武器の在庫確認
~ $ which mount.s3files mount.efs mount.nfs4 2>&1
/usr/bin/which: no mount.s3files in (...)
/usr/bin/which: no mount.efs in (...)
/usr/sbin/mount.nfs4
~ $ rpm -qa | grep -iE "nfs|efs|s3files" || echo "no related packages"
libnfsidmap-2.5.4-2.rc3.amzn2023.0.3.x86_64
nfs-utils-2.5.4-2.rc3.amzn2023.0.3.x86_64
mount.s3filesヘルパーは入っておらず、mount.nfs4だけある状態です。
mount.s3files と mount.nfs4 の違い
-
mount.s3files:S3 Files専用のマウントヘルパーで、amazon-efs-utilsパッケージに同梱されています。mount -t s3filesを実行すると自動的に呼び出され、TLS暗号化・IAM認証・AZ-IDの自動解決などを裏側でやってくれます。S3 Filesのマウントには事実上これが必須です。 -
mount.nfs4:汎用的なNFS v4マウントコマンドで、nfs-utilsパッケージに含まれています。通常のNFSサーバへの接続に使いますが、S3 FilesはTLS+IAM認証が必須のため、このコマンド単体ではマウントできません。
Step 3:AWS CLIのs3filesサブコマンド問題
2026年4月11日現在、CloudShellに標準同梱されているAWS CLI v2 (2.34.25) では、なんと s3files サブコマンドが未搭載でした!
~ $ aws --version
aws-cli/2.34.25 Python/3.14.3 Linux/6.1.163-186.299.amzn2023.x86_64 exec-env/CloudShell exe/x86_64.amzn.2023
~ $ aws s3files help 2>&1 | head -5
aws: [ERROR]: An error occurred (ParamValidation): argument command: Found invalid choice 's3files'
GA直後の新サービスあるあるなのですが、CloudShellのAWS CLIの対応が追いついていないことがわかりました。対処法として、pip install --user --upgrade awscli でv1の最新(1.44.75)を入れたら使えるようになりました。
~ $ pip install --user --upgrade awscli
(略)
Successfully installed awscli-1.44.75 botocore-1.42.85 ...
~ $ hash -r
~ $ aws --version
aws-cli/1.44.75 Python/3.9.25 Linux/6.1.163-186.299.amzn2023.x86_64 awscrt/0.29.2 exec-env/CloudShell botocore/1.42.85
~ $ aws s3files help 2>&1 | head -10
NAME
s3files -
DESCRIPTION
S3 Files makes S3 buckets accessible as high-performance file systems
powered by EFS. ...
v2より先にv1で対応というパターン。GA直後は注意が必要です!
Step 4:マウントターゲット情報を取得
~ $ aws s3files get-mount-target --mount-target-id fsmt-0cfacdaf62364450a --region ap-northeast-1
{
"availabilityZoneId": "apne1-az4",
"ownerId": "xxxxxxxxxxxxx",
"mountTargetId": "fsmt-0cfacdaf62364450a",
"fileSystemId": "fs-0ce9184ec9cc5babe",
"subnetId": "subnet-0e72565cd0f34c12a",
"ipv4Address": "10.0.138.202",
"networkInterfaceId": "eni-0c4652fe26911fa77",
"vpcId": "vpc-029ad5c9bf7cb70ef",
"securityGroups": [
"sg-0071cc82388c974a4"
],
"status": "available"
}
注目ポイント:DNS名フィールドが無い!
S3 FilesのAPIレスポンスにはDNSフィールドが存在せず、完全にIP指定スタイルになっています。EFSのdescribe-mount-targetsではIpAddressに加えてDNSNameが返ってきますが、S3 Filesのget-mount-targetにはipv4Addressのみです。これはS3 Filesがon.awsという新しいドメイン体系を採用しているためで、DNS名はAPIから返すのではなく、{az_id}.{fs_id}.s3files.{region}.on.awsの規則で組み立てる設計になっているようです。
Step 5:疎通確認
~ $ timeout 10 bash -c "</dev/tcp/10.0.138.202/2049" && echo "REACHABLE" || echo "UNREACHABLE"
UNREACHABLE
~ $ nc -zv -w 5 10.0.138.202 2049 2>&1
Ncat: Version 7.93 ( https://nmap.org/ncat )
Ncat: TIMEOUT.
~ $ ping -c 3 -W 2 10.0.138.202 2>&1
PING 10.0.138.202 (10.0.138.202) 56(84) bytes of data.
--- 10.0.138.202 ping statistics ---
3 packets transmitted, 0 received, 100% packet loss, time 2072ms
予想通り、ICMPもTCPもすべて到達不可でした。VPC外CloudShellからユーザーVPC内のENIには届かないことが確認できました。
Step 6:強行マウント
~ $ sudo mount -t s3files fs-0ce9184ec9cc5babe:/ /tmp/s3files 2>&1
mount: /tmp/s3files: unknown filesystem type 's3files'.
~ $ sudo mount -t nfs4 -o nfsvers=4.1,timeo=50,retrans=2,_netdev 10.0.138.202:/ /tmp/s3files 2>&1
mount.nfs4: Connection timed out
決定的な失敗証拠が2段で取れました。
-
アプリ層の壁:
mount -t s3filesはmount.s3filesヘルパーを呼び出そうとしますが、CloudShellにはamazon-efs-utilsが未インストールのためunknown filesystem typeで即エラーになります。 -
ネットワーク層の壁:仮にヘルパーを入れたとしても、VPC外CloudShellの
172.31.255.0/26(AWS管理レンジ)からユーザーVPC内の10.0.138.202(マウントターゲットENI)へはルーティングが存在しません。VPCピアリングやTransit Gatewayのような接続経路もないため、パケットが物理的に到達できない状況です。
なぜVPC外CloudShellからユーザーVPCに到達できないのか?
VPC外CloudShellはAWSが管理する専用ネットワーク空間で動作しており、ユーザーのVPCとは完全に分離されています。Step 1で確認した通り、CloudShellの ip route にはユーザーVPCの 10.0.0.0/16 系へのルートが一切ありません。これはセキュリティ上の設計であり、VPC外CloudShellからユーザーVPC内のリソースにアクセスするには、パブリックIPを持つリソース(パブリックサブネットのEC2など)経由か、VPC内モードに切り替える必要があります。
パターン1の結論
VPC外CloudShellからS3 Filesは原理的にマウント不可能でした。これは設計上の制約であり、パッケージを足せば解決する類の話ではないようです。
パターン2:VPC内CloudShellで本命検証
Step 1:環境の自己紹介
~ $ ip route
default via 10.0.128.1 dev ens7
10.0.128.0/20 dev ens7 proto kernel scope link src 10.0.133.115
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1 linkdown
~ $ cat /etc/resolv.conf
search ap-northeast-1.compute.internal
nameserver 10.0.0.2
VPC内モードの証拠が取れました。
- インターフェースは
ens7(VPC外モードはeth0だった) - IPは
10.0.133.115/20、マウントターゲットと同じサブネット内 - DNSは
10.0.0.2(VPC内DNSリゾルバ)
Step 2:CLI周りはVPC外と同じ
mount.s3files ヘルパー不在、CLI v2ではs3files未対応…という状況は完全に同じでした。CloudShellの実行基盤は公式には明言されていませんが、VPC内/外の違いはネットワーク部分だけのようです。
Step 3:疎通確認 → SG問題発覚
~ $ timeout 10 bash -c "</dev/tcp/10.0.138.202/2049" && echo "REACHABLE" || echo "UNREACHABLE"
UNREACHABLE
同じサブネットに居るのに疎通できない問題が発生!ルーティングは dev ens7 で直接認識されていたので、Security Group問題だと当たりをつけました。
~ $ aws ec2 describe-network-interfaces --filters "Name=addresses.private-ip-address,Values=10.0.133.115" --region ap-northeast-1 --query 'NetworkInterfaces[*].[NetworkInterfaceId,Groups,SubnetId,VpcId]' --output json
[
[
"eni-08184828699d0a26b",
[
{
"GroupId": "sg-08e93285f91708d3c",
"GroupName": "All-OK"
}
],
"subnet-0e72565cd0f34c12a",
"vpc-029ad5c9bf7cb70ef"
]
]
~ $ aws ec2 describe-security-groups --group-ids sg-0071cc82388c974a4 --region ap-northeast-1 --query 'SecurityGroups[*].IpPermissions' --output json
[
[
{
"IpProtocol": "-1",
"UserIdGroupPairs": [
{
"UserId": "xxxxxxxxxxxxx",
"GroupId": "sg-0071cc82388c974a4"
}
],
...
}
]
]
判明したこと
- CloudShellのSG:
sg-08e93285f91708d3c(All-OK) - マウントターゲットのSG:
sg-0071cc82388c974a4 - マウントターゲットSGは自己参照ルールしか持っていない
つまり、CloudShellに別のSGが付いていたため、自己参照ルールではマッチせず弾かれていました。
そこで、マウントターゲットSG(sg-0071cc82388c974a4)のインバウンドに「CloudShellのSG(sg-08e93285f91708d3c)からTCP/2049を許可」というルールを追加します。これで初めてCloudShellからNFSポートへの疎通が通るようになります。
~ $ aws ec2 authorize-security-group-ingress --group-id sg-0071cc82388c974a4 --protocol tcp --port 2049 --source-group sg-08e93285f91708d3c --region ap-northeast-1
{
"Return": true,
...
}
~ $ timeout 10 bash -c "</dev/tcp/10.0.138.202/2049" && echo "REACHABLE" || echo "UNREACHABLE"
REACHABLE
SGルール追加で疎通完了!!
Step 4:素のNFSマウントは弾かれる
~ $ sudo mount -t nfs4 -o nfsvers=4.1,rsize=1048576,wsize=1048576,hard,timeo=600,retrans=2,_netdev 10.0.138.202:/ /tmp/s3files 2>&1
mount.nfs4: access denied by server while mounting 10.0.138.202:/
ネットワークは通っているのに、NFSサーバ側で拒否されました。
ここで公式ドキュメントを読み込むことで、致命的な仕様を発見しました。
the mount helper automatically uses
tlsandiammount options when mounting an S3 file system as S3 Files requires these options to establish a connection. This is because S3 Files always mounts a file system using TLS encryption and IAM authentication and these cannot be disabled.
つまりS3 Filesは「TLS暗号化 + IAM認証」が必須で、無効化できないことが判明しました!素のNFSマウントは原理的に不可能だったようです。。。
Step 5:amazon-efs-utilsのインストール
Step 4の公式ドキュメントの一文を改めて引用すると:
the mount helper automatically uses
tlsandiammount options when mounting an S3 file system as S3 Files requires these options to establish a connection.
ここでいう mount helper こそが mount.s3files コマンドです。素のmount -t nfs4では不可能で、このヘルパー経由でしかマウントできません(TLS + IAM認証が必須なので)。つまりStep 4の結果から「ヘルパーの導入が必須」ということが確定しました。
そして、このmount.s3filesヘルパーはamazon-efs-utilsパッケージに同梱されているため、これをdnfで入れていきます。
~ $ sudo dnf install -y amazon-efs-utils
(略)
Installing:
amazon-efs-utils x86_64 3.0.0-4.amzn2023 amazonlinux 6.7 M
Installing dependencies:
stunnel x86_64 5.58-1.amzn2023.0.2 amazonlinux 156 k
(略)
Complete!
~ $ which mount.s3files mount.efs
/usr/sbin/mount.s3files
/usr/sbin/mount.efs
Amazon Linux 2023の標準リポジトリに既にS3 Files対応版(3.0.0-4)が来ていたため、CloudShellでも普通にdnfで入れることができました。
Step 6:マウント実行 → IMDS問題
~ $ sudo mount -t s3files fs-0ce9184ec9cc5babe:/ /tmp/s3files
Cannot retrieve AZ-ID from metadata service. This is required for S3Files mounts using {az_id} in dns_name_format.
mount.s3filesはEC2インスタンスメタデータサービス(IMDS, 169.254.169.254)からAZ-IDを取得しようとしたのですが、CloudShellではIMDSが存在せず失敗してしまいました。
余談:CloudShellの実態はVM?コンテナ?
AWS公式ドキュメントではCloudShellの実行基盤は「compute environment(Amazon Linux 2023ベース)」と表現されていて、VM・コンテナのどちらとも明言されていません(参考:AWS CloudShell compute environment: specifications and software)。
ただし、今回のように IMDSエンドポイント(169.254.169.254)が存在しない 挙動や、Docker in Dockerでコンテナを実行できる、セッションがSSM経由で起動するといった特性から、実質的にはコンテナベースと推定できます。厳密な実装は非公開なので、本記事では「IMDSを持たない実行環境」という挙動ベースで扱っていきます。
Step 7:dns_name_formatを書き換え
/etc/amazon/efs/s3files-utils.conf を確認すると、S3 Files専用の設定ファイルが存在することがわかりました。
~ $ cat /etc/amazon/efs/s3files-utils.conf | grep dns_name
dns_name_format = {az_id}.{fs_id}.s3files.{region}.{dns_name_suffix}
dns_name_suffix = on.aws
新しいドメイン on.aws を使っているのも面白いポイントです!本来のFQDNは apne1-az4.fs-0ce9184ec9cc5babe.s3files.ap-northeast-1.on.aws という形式となっています。
なぜデフォルトで {az_id} が含まれているでしょう?
S3 Filesの想定ユーザーはEC2インスタンス。EC2ならIMDSから自分のAZ-IDを瞬時に取得でき、同一AZ内のマウントターゲットに接続することで、クロスAZ通信料金を避けつつ低レイテンシで読み書きできる設計になっています。つまりデフォルトの {az_id}.{fs_id}.s3files.{region}.on.aws 形式は、EC2から「自AZのマウントターゲット」をダイレクトに引き当てるための標準ルートです。
一方、CloudShellはIMDSを持たない(Step 6で判明)ため、この標準ルートに乗ることができません。これが今回のイレギュラーの本質です。
そこで、{az_id} を取り除いてIMDS呼び出しをスキップさせる作戦に出ました。
~ $ sudo cp /etc/amazon/efs/s3files-utils.conf /etc/amazon/efs/s3files-utils.conf.bak
~ $ sudo sed -i 's|^dns_name_format = {az_id}\.{fs_id}\.s3files\.{region}\.{dns_name_suffix}|dns_name_format = {fs_id}.s3files.{region}.{dns_name_suffix}|' /etc/amazon/efs/s3files-utils.conf
~ $ grep dns_name_format /etc/amazon/efs/s3files-utils.conf
dns_name_format = {fs_id}.s3files.{region}.{dns_name_suffix}
Step 8:DNS解決問題
~ $ sudo mount -t s3files fs-0ce9184ec9cc5babe:/ /tmp/s3files
Failed to resolve "fs-0ce9184ec9cc5babe.s3files.ap-northeast-1.on.aws" - check that your file system ID is correct, and ensure that the VPC has an S3Files mount target for this file system ID.
{az_id}抜きのDNS名はそもそも解決できません。fall_back_to_mount_target_ip_address_enabled = true が設定されているのですが、これはDNS解決失敗時のフォールバックのはずなのに発動していない点が問題でした。
Step 9:フルFQDNでIMDSをバイパスする発想の転換
ここでmount.s3filesの実装を直接覗いてみました。するとPythonスクリプトだったので中身が読めました!
~ $ grep -n "az_id\|AZ_ID\|azid" /usr/sbin/mount.s3files
71: r"^((?P<az_id>[a-z0-9-]+)\.)(?P<fs_id>fs-[0-9a-f]+)\.(?:[a-z0-9-]+\.)+"
122: fs_id, path, azid = match_device(config, fsname, options)
124: return fs_id, path, mountpoint, add_field_in_options(options, "azid", azid)
正規表現を見ると、fsnameに完全なFQDN形式({az_id}.{fs_id}.s3files.{region}.on.aws)を渡せば、正規表現でaz_idを自動抽出してazidオプションに追加してくれる実装になっていることがわかりました。
つまりIMDS呼び出しを完全にバイパスできるってことがわかりました!!
念のためフルFQDNのDNS解決確認すると、以下のようになります。
~ $ getent hosts apne1-az4.fs-0ce9184ec9cc5babe.s3files.ap-northeast-1.on.aws
10.0.138.202 apne1-az4.fs-0ce9184ec9cc5babe.s3files.ap-northeast-1.on.aws
VPC内DNSリゾルバがon.awsゾーンを普通に処理していることがわかります。Step 8で失敗した{az_id}抜きの短縮名はそもそも存在しないので解決できなかった、というカラクリだったようです。
そのため、設定ファイルは初期状態に戻し、デフォルトのdns_name_formatのままで、マウント時のfsname側でフルFQDNを指定するよう方針転換をしました。
~ $ sudo mount -t s3files apne1-az4.fs-0ce9184ec9cc5babe.s3files.ap-northeast-1.on.aws:/ /tmp/s3files
AWS Access Key ID and Secret Access Key are not found in AWS credentials file (/root/.aws/credentials), config file (/root/.aws/config), from ECS credentials relative uri, or from the instance security credentials service
マウントはまだ通っていませんが、エラーが大きく前進していることをログで確認しています
~ $ sudo tail /var/log/amazon/efs/mount.log
INFO - version=3.0.0 options={'rw': None, 'azid': 'apne1-az4'}
INFO - binding 20801
ERROR - AWS Access Key ID and Secret Access Key are not found ...
options={'rw': None, 'azid': 'apne1-az4'} に注目すると、fsnameから自動抽出されたazidがちゃんと設定されていることがわかります。IMDSバイパス成功、DNS解決成功、stunnelのローカルbind成功!残るはIAM認証だけまでいきました。
Step 10:sudoの環境変数リセット問題
CloudShellの認証情報は環境変数で提供されています。
~ $ env | grep -E "^AWS_" | sed 's/=.*/=<値あり>/'
AWS_CONTAINER_CREDENTIALS_FULL_URI=<値あり>
AWS_CONTAINER_AUTHORIZATION_TOKEN=<値あり>
AWS_DEFAULT_REGION=<値あり>
AWS_REGION=<値あり>
...
ところがsudo mountで実行すると、これらの変数がroot環境に引き継がれていませんでした。。。sudo -Eやenvコマンド経由でもenv_reset設定のため失敗したようです。
~ $ sudo -E env "PATH=$PATH" mount -t s3files apne1-az4.fs-0ce9184ec9cc5babe.s3files.ap-northeast-1.on.aws:/ /tmp/s3files
AWS Access Key ID and Secret Access Key are not found in AWS credentials file ...
CloudShell(VPC内モード)のsudoersは環境変数を厳しくリセットする仕様です。AWS_CONTAINER_CREDENTIALS_FULL_URIのような非標準変数はenv_keepに入っていないため、どうやっても渡らない問題があります。
Step 11:コンテナ認証エンドポイントから一時クレデンシャルを取得
では正攻法で!!!ということで、CloudShellのコンテナ認証エンドポイントから一時クレデンシャルを取得して/root/.aws/credentialsに書き込む作戦に切り替えました。
~ $ CREDS=$(curl -s -H "Authorization: $AWS_CONTAINER_AUTHORIZATION_TOKEN" "$AWS_CONTAINER_CREDENTIALS_FULL_URI")
~ $ AK=$(echo "$CREDS" | jq -r .AccessKeyId)
~ $ SK=$(echo "$CREDS" | jq -r .SecretAccessKey)
~ $ TK=$(echo "$CREDS" | jq -r .Token)
~ $ sudo mkdir -p /root/.aws
~ $ printf '[default]\naws_access_key_id = %s\naws_secret_access_key = %s\naws_session_token = %s\n' "$AK" "$SK" "$TK" | sudo tee /root/.aws/credentials > /dev/null
~ $ sudo chmod 600 /root/.aws/credentials
~ $ printf '[default]\nregion = ap-northeast-1\n' | sudo tee /root/.aws/config > /dev/null
~ $ sudo aws sts get-caller-identity
{
"UserId": "AROA3VAYNP5DJ47LQZPCU:atsuhisa9998",
"Account": "xxxxxxxxxxxxx",
"Arn": "arn:aws:sts::xxxxxxxxxxxxx:assumed-role/AWSReservedSSO_AdministratorAccess_.../atsuhisa9998"
}
これによりroot環境で認証情報が使えるようになりました!!
Step 12:ついにマウント成功!!
~ $ sudo mount -t s3files apne1-az4.fs-0ce9184ec9cc5babe.s3files.ap-northeast-1.on.aws:/ /tmp/s3files
Could not start amazon-efs-mount-watchdog, unrecognized init system "node"
~ $ df -Th | grep s3files
127.0.0.1:/ nfs4 8.0E 0 8.0E 0% /tmp/s3files
~ $ mount | grep s3files
127.0.0.1:/ on /tmp/s3files type nfs4 (rw,relatime,vers=4.2,rsize=1048576,wsize=1048576,...,port=20464,...,addr=127.0.0.1)
これにより!!!8.0E(エクサバイト)という事実上無制限の容量が確認できました!!
俺のストレージか?欲しけりゃくれてやる、探せ!!!8Eのデータをここにおいてきた
※もちろん言いたいだけ
ここで面白いのは、NFSマウント先が127.0.0.1になっていること。これはefs-proxy(stunnel派生)がローカルでTLS終端していて、そこから外部のマウントターゲットへTLS+IAM認証された接続を張る設計であるということなのでしょうか。。。
~ $ ps aux | grep efs-proxy | grep -v grep
root 373 /sbin/efs-proxy /var/run/efs/stunnel-config.fs-0ce9184ec9cc5babe.tmp.s3files.20464 --tls
~ $ ss -tlnp | grep 204
LISTEN 127.0.0.1:20464 0.0.0.0:*
ログに出ていた警告2つは無害でした。
| 警告 | 原因 | 影響 |
|---|---|---|
Could not start amazon-efs-mount-watchdog, unrecognized init system "node" |
CloudShellのinit systemがnode(AWS管理)でsystemd等ではない |
なし。自動再接続機能が動かないだけ |
Failed to modify read_ahead_kb: ... Read-only file system |
コンテナから/sysに書き込めない |
なし。パフォーマンスチューニングがスキップされるだけ |
実際に読み書きできるか確認してみました。
~ $ echo "hello from cloudshell $(date)" | sudo tee /tmp/s3files/test.txt
hello from cloudshell Sat Apr 11 07:05:48 AM UTC 2026
~ $ sudo ls -la /tmp/s3files/
total 20
drwxr-xr-x. 3 root root 10240 Apr 11 07:05 .
drwxrwxrwt. 1 root root 4096 Apr 11 07:03 ..
drwx------. 2 root root 10240 Apr 8 13:19 .s3files-lost+found-fs-0ce9184ec9cc5babe
-rw-r--r--. 1 root root 54 Apr 11 07:05 test.txt
.s3files-lost+found-fs-0ce9184ec9cc5babeというEFS特有のディレクトリも見えます。中身が完全にEFSとして振る舞っていることが裏付けられています。
以降作業しやすいよう、所有者をcloudshell-userに変更しておきます。
~ $ sudo chown cloudshell-user:cloudshell-user /tmp/s3files
Step 13:本命のterraform init
いよいよ本命のterraform initを試していきます!!
~ $ mkdir -p /tmp/s3files/bin
~ $ cd /tmp && curl -sLO https://releases.hashicorp.com/terraform/1.9.8/terraform_1.9.8_linux_amd64.zip
~ $ unzip -o terraform_1.9.8_linux_amd64.zip -d /tmp/s3files/bin/
~ $ rm terraform_1.9.8_linux_amd64.zip
~ $ export PATH=/tmp/s3files/bin:$PATH
~ $ terraform version
Terraform v1.9.8
on linux_amd64
AWS Providerを読み込む最小限のmain.tfを作成しました。
terraform {
required_version = ">= 1.5.0"
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 5.0"
}
}
}
provider "aws" {
region = "ap-northeast-1"
}
data "aws_caller_identity" "current" {}
output "account_id" {
value = data.aws_caller_identity.current.account_id
}
そして運命のterraform init!
tf-test $ terraform init
Initializing the backend...
Initializing provider plugins...
- Finding hashicorp/aws versions matching "~> 5.0"...
- Installing hashicorp/aws v5.100.0...
- Installed hashicorp/aws v5.100.0 (signed by HashiCorp)
Terraform has been successfully initialized!
完走!!!!そのままplanまで流してみました。
tf-test $ terraform plan
data.aws_caller_identity.current: Reading...
data.aws_caller_identity.current: Read complete after 0s [id=xxxxxxxxxxxxx]
Changes to Outputs:
+ account_id = "xxxxxxxxxxxxx"
完璧に動作してくれました!AWSアカウントIDも正しく取れています!
tf-test $ df -Th /tmp/s3files /home && du -sh /tmp/s3files/tf-test/.terraform /tmp/s3files/bin
Filesystem Type Size Used Avail Use% Mounted on
127.0.0.1:/ nfs4 8.0E 0 8.0E 0% /tmp/s3files
/dev/nvme1n1 ext4 16G 6.2G 8.6G 42% /home
675M /tmp/s3files/tf-test/.terraform
85M /tmp/s3files/bin
合計760MBのTerraform環境が全てS3 Files上に乗ったため/home消費はゼロ!当初の目的「CloudShellの容量制限を突破してterraform initを完走させる」を達成できました!
まあ、今回は760MBだったので、ギリギリVPC外CloudShellでもなんとかなったかもしれないですね。。。
Step 14:最後に立ちはだかる壁(認証情報の有効期限切れ)
勝利の余韻に浸っていたのですが、しばらく経ってから再度dfやterraform planを叩いた時に事件が発生しました。
tf-test $ df -Th /tmp/s3files
df: /tmp/s3files: Permission denied
tf-test $ terraform plan
-bash: /tmp/s3files/bin/terraform: Permission denied
そう、急に全操作が拒否されるようになりました。
原因を調べて判明したのは、一時クレデンシャルの有効期限切れ。CloudShellのコンテナ認証エンドポイントが返すクレデンシャルは有効期限は約15分しかなく、efs-proxyはこのIAM情報を継続的にリフレッシュしながらNFSセッションを維持する実装なので、/root/.aws/credentialsの情報が古くなると一切の操作が弾かれてしまうというのが原因です。
対処は「認証情報取り直し→アンマウント→再マウント」の3ステップです。
~ $ CREDS=$(curl -s -H "Authorization: $AWS_CONTAINER_AUTHORIZATION_TOKEN" "$AWS_CONTAINER_CREDENTIALS_FULL_URI")
~ $ AK=$(echo "$CREDS" | jq -r .AccessKeyId); SK=$(echo "$CREDS" | jq -r .SecretAccessKey); TK=$(echo "$CREDS" | jq -r .Token)
~ $ printf '[default]\naws_access_key_id = %s\naws_secret_access_key = %s\naws_session_token = %s\n' "$AK" "$SK" "$TK" | sudo tee /root/.aws/credentials > /dev/null
~ $ sudo umount /tmp/s3files
~ $ sudo mount -t s3files apne1-az4.fs-0ce9184ec9cc5babe.s3files.ap-northeast-1.on.aws:/ /tmp/s3files
~ $ sudo chown cloudshell-user:cloudshell-user /tmp/s3files
これで復活するのですが、15分ごとにこれを繰り返す必要があるのは実用上かなり厳しい制約です。
CloudShellから長時間S3 Filesを使いたい場合、この認証情報リフレッシュ問題が最大のネックになります。理想はefs-proxyがコンテナ認証エンドポイントを直接読んでくれる改修なのですが、それは将来のamazon-efs-utilsアップデート待ちですね。。。
最終まとめ
検証の結論として、VPC内CloudShellからS3 Filesをマウントしてterraform initを完走させることに成功しました!!
パターン別の結論
| パターン | 結果 | 理由 |
|---|---|---|
| VPC外CloudShell | マウント不可能 | ユーザーVPCのENIに到達不可(設計上の壁) |
| VPC内CloudShell | マウント成功(条件付き) | 複数の回避策を組み合わせれば動作。ただし15分ごとに再認証必要 |
技術的な発見(最終版)
| カテゴリ | 発見内容 |
|---|---|
| CloudShellのストレージ | 1GB制限の正体は/dev/loop0のループバックファイル。VPC内モードには存在せず/homeの16GBがそのまま使える |
| S3 Filesの正体 | 中身はEFS。ENI構造、SG、設定ファイル名、.s3files-lost+foundディレクトリなど全てEFSと共通 |
| 新ドメイン | S3 Filesはon.awsという新ドメインを使用。FQDN形式は{az_id}.{fs_id}.s3files.{region}.on.aws
|
| CLI対応状況 | CloudShell同梱のCLI v2はs3files未対応。pip経由のv1(1.44系)で対応 |
| 必須セキュリティ | TLS暗号化+IAM認証が強制。素NFSマウントは原理的に不可能 |
| mount.s3files | Amazon Linux 2023標準リポジトリに対応版(3.0.0-4)あり。CloudShellでもdnfで一発 |
| IMDSバイパス技 | fsnameにフルFQDNを渡すと正規表現でaz_idを自動抽出し、IMDS呼び出しをスキップできる |
| 認証経路 | efs-proxyは/root/.aws/credentialsを読む。コンテナ認証エンドポイントから一時credsを書き込めばroot実行でも動作 |
| ローカルTLS終端 | NFSマウント先は127.0.0.1。efs-proxyがローカルでTLS終端して外部MTへ接続する設計 |
| 認証の有効期限問題 | efs-proxyはIAMを継続使用するため、15分でcreds切れ → 操作拒否。定期リフレッシュが必要 |
CloudShellからS3 Filesマウントに成功させる手順
参考までに、VPC内CloudShellからS3 Filesをマウントしてterraform initを完走させる完全手順を整理しました。
- 事前準備:S3 Filesファイルシステム作成&マウントターゲットをCloudShellと同じサブネットに配置
- SGルール:マウントターゲットSGに、CloudShellが使っているSGからのTCP:2049 ingressを追加
- パッケージ導入:
sudo dnf install -y amazon-efs-utils - 認証情報注入:コンテナcredsエンドポイント →
/root/.aws/credentials - マウント:fsnameにフルFQDNを指定して
sudo mount -t s3files {az_id}.{fs_id}.s3files.{region}.on.aws:/ /mnt - Terraform配置:
/mnt/binにTerraformバイナリをインストール - terraform init:
/mnt/tf-testで実行 → 容量制限なく完走
15分ごとに戦う運命
本手順は一応動作しますが、一時credsの有効期限切れ問題があるため長時間作業には向きません。現実的な使い分けは以下の通りです。
- 短時間作業:本手順でS3 Filesを使う(1回の
terraform initなど) - 継続作業:そのままVPC内CloudShellの
/home(16GB)を使う方が遥かにラク - 本格利用:素直にEC2やECS Execで使う
おわりに
Amazon S3 Filesを「CloudShellからマウントしてterraform initの容量問題を解決する」という当初目的は、条件付きで達成できました。ただ、VPC内モードなら/homeが16GB使えるという肩透かしオチもあり、道中で得られた学びの方がむしろ大きかった気がします。
得られた学び
- CloudShellの1GB制限の正体:VPC外モード固有のループバックファイル。VPC内モードなら消える
- S3 FilesがEFSベースである証拠:ファイル名、エラーメッセージ、
lost+foundディレクトリ、すべてEFS - mount.s3filesの内部設計:IMDS依存、
azidオプション、正規表現によるFQDN自動パース - TLS+IAM必須の安全設計:efs-proxyがローカルで中継するアーキテクチャ
- CloudShellの認証情報の罠:環境変数で提供される → sudo環境では使えない → ファイルに書き込みで回避
- 一時credsとefs-proxyの相性問題:15分ごとにリフレッシュしないとNFS操作が止まる
現実解
今回の検証を通じて、「CloudShell × S3 Filesは原理的には動くが、実用では素直に別の手段を選ぶのが吉」という結論に至りました。
- CloudShellで容量問題に困ってるなら → VPC内モードを使う(
/homeが16GB使える) - S3 Filesを本気で使うなら → EC2やECSで使う(
amazon-efs-utilsが想定通り動く) - どうしてもCloudShellから触りたいなら → 本記事の手順でOK、ただし15分制約あり
とはいえ、「やれるかな?」を「やってみた」ことで、新サービスの設計思想やCloudShellの内部構造を深く理解できました。失敗も寄り道も全部お宝、というのが検証の醍醐味ですね!
同じようにCloudShellの容量問題に困っていた人や、S3 Filesの中身が気になっていた人の参考になれば幸いです。