課題
ヤフオクで商品を買った場合、基本的には、領収書は発行されません。そのため、証明するものがない場合、経費として落ちないことがあります。この対処法として、取引画面のキャプチャという方法があります。しかし、一個一個を手作業でやるのは、かなりの苦行です😌
今回は、ChromeDriverを使って、自動化していきたいと思います。
動作環境
Mac OS Mojave
Python 3.7.6
VSCode
ChromeDriver
処理の流れ
①【ヤフオクに自動ログイン】
↓
②【商品毎の落札の取引画面を開く】
↓
③【PDFに変換】
↓
④【指定のファイルに保存】
処理後の例
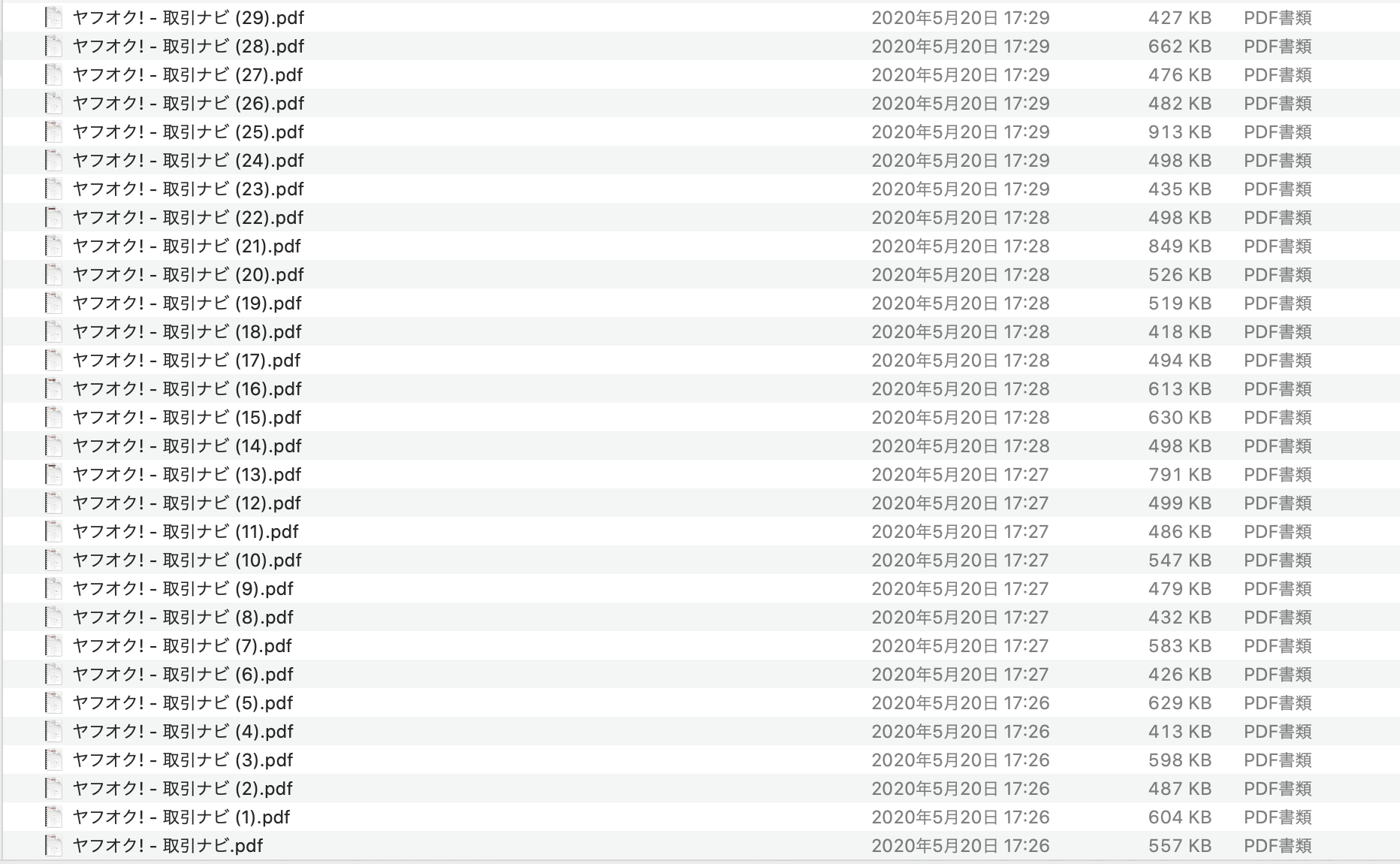
ソースコードはこちら
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
import json
import sys
username= "ユーザー名"
password="パスワード"
def main():
#ヤフオクのURL
driver.get('https://login.yahoo.co.jp/config/login?.src=auc&.done=https%3A%2F%2Fauctions.yahoo.co.jp%2F' )
#自動ログイン
driver.find_element_by_id("username").send_keys(username)
driver.find_element_by_id("btnNext").click()
time.sleep(1)
driver.find_element_by_id("passwd").send_keys(password)
driver.find_element_by_id("btnSubmit").click()
#driver.find_element_by_id("").click() *ポップアップ広告が出た時
driver.find_element_by_xpath('//*[@id="yjMain"]/div/div[2]/div[2]/div/div[2]/table/tbody/tr[3]/td[1]/a').click()
time.sleep(1)
#次へのボタンがなくなるまでループ
while True:
try:
if len(driver.find_elements_by_xpath("//img[@src='https://s.yimg.jp/images/auct/template/ui/search/arrow_next.gif']")) > -1:
print("start PDF")
item_list= []
for item in driver.find_elements_by_css_selector('p.decTxt01'):
try:
link = item.find_element_by_tag_name("a").get_attribute("href")
except:
link = "skip"
item_list.append(link)
for link in item_list:
try:
driver.get(link)
time.sleep(2)
driver.find_element_by_class_name('decIcoArw').click()
time.sleep(2)
driver.execute_script('return window.print()')
driver.back()
except :
print("None")
btn = driver.find_element_by_link_text("次の50件").get_attribute("href")
print(btn)
print("next url:{}".format(btn))
driver.get(btn)
print("Next page") #強制的に終了
except:
sys.exit()
#印刷を無理やりPDF保存する設定
chopt=webdriver.ChromeOptions()
appState = {
"recentDestinations": [
{
"id": "Save as PDF",
"origin": "local",
"account":"" #Chrome (78.0.3904.108)は、必要
}
],
"selectedDestinationId": "Save as PDF",
"version": 2
}
prefs = {'printing.print_preview_sticky_settings.appState':
json.dumps(appState)}
chopt.add_experimental_option('prefs', prefs)
chopt.add_argument('--kiosk-printing')
driver = webdriver.Chrome(executable_path='chromedriverのディレクトリ ',options=chopt)
#処理実行
if __name__ == '__main__':
main()
#*注意点
掲示板にて、取引をしている場合のみは、手作業でのPDF保存になります。
まず最初に、selenium, time, json,sysをインポートします。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
import json
import sys
ヤフオクのログイン画面から自動的にログインしてくれます。サーバーに負荷をかけないようにtime.sleep(1)で1秒間だけ時間を置いてます。
def main():
#ヤフオクのURL
driver.get('https://login.yahoo.co.jp/config/login?.src=auc&.done=https%3A%2F%2Fauctions.yahoo.co.jp%2F' )
#自動ログイン
driver.find_element_by_id("username").send_keys(username)
driver.find_element_by_id("btnNext").click()
time.sleep(1)
driver.find_element_by_id("passwd").send_keys(password)
driver.find_element_by_id("btnSubmit").click()
#driver.find_element_by_id("記入").click() *ポップアップ広告が出た時
driver.find_element_by_xpath('//*[@id="yjMain"]/div/div[2]/div[2]/div/div[2]/table/tbody/tr[3]/td[1]/a').click()
time.sleep(1)
次のページがなくなるまで、自動でページ遷移するようにループします。
#次へのボタンがなくなるまでループ
while True:
try:
if len(driver.find_elements_by_xpath("//img[@src='https://s.yimg.jp/images/auct/template/ui/search/arrow_next.gif']")) > -1:
print("start PDF")
item_list= []
for item in driver.find_elements_by_css_selector('p.decTxt01'):
try:
link = item.find_element_by_tag_name("a").get_attribute("href")
except:
link = "skip"
item_list.append(link)
for link in item_list:
try:
driver.get(link)
time.sleep(2)
driver.find_element_by_class_name('decIcoArw').click()
time.sleep(2)
driver.execute_script('return window.print()')
driver.back()
except :
print("None")
btn = driver.find_element_by_link_text("次の50件").get_attribute("href")
print(btn)
print("next url:{}".format(btn))
driver.get(btn)
print("Next page") #強制的に終了
except:
sys.exit()
ChromeOptionsによって、印刷を強制的に停止させて、PDF保存を自動的にするようにしてます。
# 印刷を無理やりPDF保存する設定
chopt=webdriver.ChromeOptions()
appState = {
"recentDestinations": [
{
"id": "Save as PDF",
"origin": "local",
"account":"" #Chrome (78.0.3904.108)は、必要
}
],
"selectedDestinationId": "Save as PDF",
"version": 2
}
prefs = {'printing.print_preview_sticky_settings.appState':
json.dumps(appState)}
chopt.add_experimental_option('prefs', prefs)
chopt.add_argument('--kiosk-printing')
driver = webdriver.Chrome(executable_path='chromedriverのディレクトリ ',options=chopt)
#処理実行
if __name__ == '__main__':
main()
おわりに
ヤフオクのデータは90日で、更新されてまうので、3ヶ月毎にこのツールを使っていきたいと思います。Xpathで要素を指定している箇所は、次に使う時に変わっているかもしれませんが…🤗(2020/5/25 動作確認済み)