概要
Googleスプレッドシートを使ってスクレイピングを行ったときのメモです。
シートに記入したURLのmeta情報を取得するスクリプトを書きました。
スクレイピング方法
今回は以下のようなシートを作成を使います。
例では、URLにはCodeZineさんの記事URLを入力しています。

1. Parserライブラリの追加
今回はより簡単に取得するため、以下のライブラリを使用しています。
スプレッドシートのメニューから「ツール > スクリプトエディタ」を選択し、エディタを開きます。
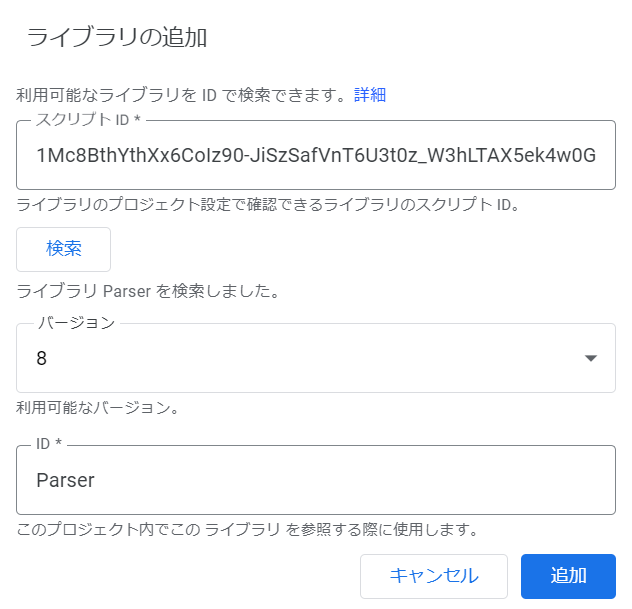
左メニューの「ライブラリ+」でIDを指定することで追加が可能です。
スクリプトIDは M1lugvAXKKtUxn_vdAG9JZleS6DrsjUUV となっています。
(ソースコードのURL部分がIDです。※ソースに記載されているIDは古いので注意)
IDを入力・検索し、以下の状態で「追加」をします。
2. ソースコードの実装
ソースコードは以下のようになっています。
function myFunction() {
// 現在開いているシートを参照する
const sheet = SpreadsheetApp.getActiveSheet();
// 取得するデータ範囲
const firstCol = 1; // A列
const lastCol = 1; // A列のみ
const firstRow = 2; // 2行目から
const lastRow = sheet.getLastRow(); // 最終行まで
// 入力するデータ範囲
const titleCol = 2; // B列
const keywordCol = 3; // C列
const descriptionCol = 4; // D列
// 指定範囲の値を取得して一次配列にする
const values = sheet.getRange(firstRow, firstCol, lastRow, lastCol).getValues();
const urls = values.map((line) => line[0]);
for (var key in urls) {
const url = urls[key];
let title = '-';
let keyword = '-';
let description = '-';
// URLに対しフェッチを行ってHTMLデータを取得する
const html = UrlFetchApp.fetch(url).getContentText('UTF-8');
// Parserライブラリを使用して条件を満たしたHTML要素を抽出する
const head = Parser.data(html).from('<head>').to('</head').build();
title = Parser.data(html).from('<title>').to('</title').build();
// 空でないかチェック
const hadKeyword = head.match(/<meta name="keywords" content="">/g);
const hasKdescription = head.match(/<meta name="description" content="">/g);
if (hadKeyword === null) {
keyword = Parser.data(html).from('<meta name="keywords" content="').to('">').build();
}
if (hasKdescription === null) {
description = Parser.data(html).from('<meta name="description" content="').to('">').build();
}
// 書き込む行数を取得
const low = parseInt(key) + parseInt(firstRow);
// シートに書き込み
sheet.getRange(low, titleCol).setValue(title);
sheet.getRange(low, keywordCol).setValue(keyword);
sheet.getRange(low, descriptionCol).setValue(description);
}
}
スクレイピング
スクレイピングを行っている部分は以下になります。
まずはURLにアクセスしてHTMLを取得し、取りたい要素をParser.dataを使ってパースします。
.from()に取得する開始の文字列、.to()に終わりの文字列を指定し、.build()で実行します。
const html = UrlFetchApp.fetch(url).getContentText('UTF-8');
const title = Parser.data(html).from('<title>').to('</title').build();
これで、<title>~~~</title>の~~~の部分を取得することができます。
.build()は最初の要素を返しますが、liなど複数取る場合は.iterate()を使うと配列で返してくれます。
詳しい使い方は、以下参考サイトが詳細に書いて下さっています。
![]() GASで簡単WEBスクレイピング!HTMLを簡単にパースできるライブラリParserを使ってみた
GASで簡単WEBスクレイピング!HTMLを簡単にパースできるライブラリParserを使ってみた
空要素対策
今回、keywordとdescriptionに関しては一旦headのソースを取得し、空かどうかをチェックしています。
// Parserライブラリを使用して条件を満たしたHTML要素を抽出する
const head = Parser.data(html).from('<head>').to('</head').build();
// 空でないかチェック
const hadKeyword = head.match(/<meta name="keywords" content="">/g);
const hasKdescription = head.match(/<meta name="description" content="">/g);
これは、単純に以下のように取得してcontent""部分が空だったとき、
Parser.data(html).from('<meta name="keywords" content="').to('">').build();
閉じタグが意図しない位置で判定され、空ではなく取得したくない部分が取れてしまったための対策です。
.fromなどには正規表現も使えないようなので、色々やってみた結果これに落ち着きました。
(ライブラリソースをコピーして、改変すればうまく使えるかもしれませんが・・・)
まとめ
こんな感じでスクリプトを実行し、無事にmetaタグを取得することができました。

実際には外部サイトではなく、自サイトのタグをリストアップするために作成したものですが、PHPやサーバーが無くてもスクレイピングが出来るのはとても便利だなと思いました ![]()
以上です!