
はじめに
Hugging Faceが提供するライブラリ Transformers.js を使うことで、Pythonの実行環境やGPUサーバーを用意せず、ブラウザ上のJavaScriptだけでTransformer系モデルの推論を実行できます。本記事ではその技術要素(ONNX/WASM)と、HTMLファイル1つで動作する「感情分析アプリ」の実装手順を紹介します。
想定読者
- Transformers.js, ONNX, WebAssembly に興味がある
- 軽量な機械学習モデルの推論をWebブラウザ上で実装してみたい
ブラウザでMLモデルが動く仕組み
通常、機械学習モデルの推論のためにはGPUサーバーなどのコンピューティング環境が必要ですが、Transformers.js では以下の3つの技術の組み合わせにより、クライアントサイド(ブラウザ)での推論を実現することができます。
- モデル形式:ONNX
- 推論エンジン:ONNX Runtime Web
- 実行基盤:WebAssembly(WASM)
① ONNX (Open Neural Network Exchange)
ONNXは、機械学習モデルを共通形式で表現するためのオープンな標準フォーマットです。PyTorchやTensorFlow、scikit-learnなど、異なるフレームワークで作成されたモデルを同一の形式で保存・実行できることを目的に設計されています。
以下のような特徴があります。
- モデルの構造や重み、演算内容を「計算グラフ」として定義
→ 学習に使ったフレームワークに依存せず実行できる - 推論に特化したフォーマット
→ 効率的に推論が実行できる
ONNX
モデルのポータビリティと実行環境の自由度を高めるために活用される
② ONNX Runtime Web
Microsoftによって、ONNX形式のモデルを推論実行するためのランタイムとして「ONNX Runtime」が開発されています。「ONNX Runtime」はONNXで定義された計算グラフを解析し、最適化された形で推論を行います。
この「ONNX Runtime」をWebブラウザやJavaScript実行環境向けに移植したランタイムが「ONNX Runtime Web」です。ブラウザ環境に応じて以下のような実行方式がサポートされています*。
-
WebAssembly(WASM)
ネイティブに近い速度でCPU実行が可能。多くのブラウザで動作し、安定性が高い -
WebGPU
GPUを用いた高速推論を実行
ONNX Runtime Web
ONNXで定義されたモデルをWebブラウザで実行するためのランタイム
③ WebAssembly(WASM)
WASMは、Webブラウザ上で高速に実行できるバイナリ形式の仮想命令セットです。C/C++やRustなどの言語で書かれたコードをコンパイルして生成され、JavaScriptと連携しながら実行されます。
スタックベースの中間表現を持ち、ブラウザ上で安全にサンドボックス実行される点が特徴です。これにより、従来JavaScriptでは性能面で難しかった数値計算や画像処理、機械学習推論などをネイティブに近い速度で実行できます。
WebAssembly
Webブラウザ上でモデルの推論処理を実行するための実行形式
Transformers.js の仕組み
Transformers.js はHugging Faceが提供するJavaScript環境でTransformer系モデルの推論を実行するためのライブラリです。モデルのロードやトークナイズ、前処理・後処理を抽象化しており、クライアントサイド推論を簡単に実装できます。
内部ではモデルをONNX形式で扱い、推論エンジンとしてONNX Runtime Webを利用します。実際の数値計算は WebAssembly(WASM)やWebGPU上で実行され、ブラウザでも実用的な推論性能を実現できます。
Transformers.js の特徴
Webブラウザ上で機械学習モデルを動かすコードを簡単に実装できる
実装:感情分析モデルを動かしてみる
Transformers.js では事前学習済みのモデルを簡単に呼び出せます。今回は感情分析を行うモデルによる推論をHTMLファイル1つで実装してみます。
動作環境
- VS Code
- Live Server(VS Code拡張機能)
ソースコード
以下のコードを index.html として保存してください
index.html
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Transformers.js Demo</title>
<style>
body { font-family: sans-serif; max-width: 600px; margin: 2rem auto; padding: 0 1rem; }
textarea { width: 100%; height: 100px; margin-bottom: 1rem; padding: 0.5rem; }
button { padding: 0.5rem 1rem; cursor: pointer; background: #007bff; color: white; border: none; border-radius: 4px; }
button:disabled { background: #ccc; cursor: not-allowed; }
#result { margin-top: 1rem; padding: 1rem; border: 1px solid #ddd; background: #f9f9f9; min-height: 50px; }
.loading { color: #666; font-style: italic; }
</style>
</head>
<body>
<h2>⚡ ブラウザ完結型AI (Transformers.js)</h2>
<p>サーバーに送信せず、あなたのブラウザ内でAIが感情分析を行います。<br>(初回のみモデルのダウンロードが発生します)</p>
<textarea id="inputText" placeholder="ここに英語の文章を入力してください (例: I love coding!)"></textarea>
<br>
<button id="analyzeBtn" disabled>モデル読込中...</button>
<div id="result">ここに結果が表示されます</div>
<script type="module">
import { pipeline, env } from 'https://cdn.jsdelivr.net/npm/@xenova/transformers@2.17.2';
// ローカルモデルの設定
env.allowLocalModels = false;
env.backends.onnx.wasm.numThreads = 1; //スレッド数を1に制限
let classifier;
const btn = document.getElementById('analyzeBtn');
const resultDiv = document.getElementById('result');
const inputArea = document.getElementById('inputText');
// モデルロード
async function loadModel() {
try {
resultDiv.innerHTML = '<span class="loading">AIモデルをダウンロード中...(初回は数秒〜数十秒かかります)</span>';
// 感情分析のパイプラインを作成
classifier = await pipeline('sentiment-analysis');
btn.textContent = '分析する';
btn.disabled = false;
resultDiv.textContent = '準備完了!文章を入力してボタンを押してください。';
} catch (error) {
console.error(error);
resultDiv.textContent = 'エラー: ' + error.message;
}
}
// 分析実行
btn.addEventListener('click', async () => {
const text = inputArea.value;
if (!text) return;
resultDiv.innerHTML = '<span class="loading">分析中...</span>';
const startTime = performance.now();
// 推論実行
const output = await classifier(text);
const endTime = performance.now();
const processTime = (endTime - startTime).toFixed(2);
// 結果表示
const label = output[0].label;
const score = (output[0].score * 100).toFixed(1);
resultDiv.innerHTML = `
<strong>判定: ${label}</strong><br>
確信度: ${score}%<br>
処理時間: ${processTime} ms
`;
});
loadModel();
</script>
</body>
</html>
実行方法
- VS Code右下の「Go Live」をクリック(または右クリックしてOpen with Live Server)
- ブラウザが開いたらモデルのダウンロード完了まで待機し、任意の文字を入力して「分析する」ボタンをクリック

- 判定結果が表示されます!
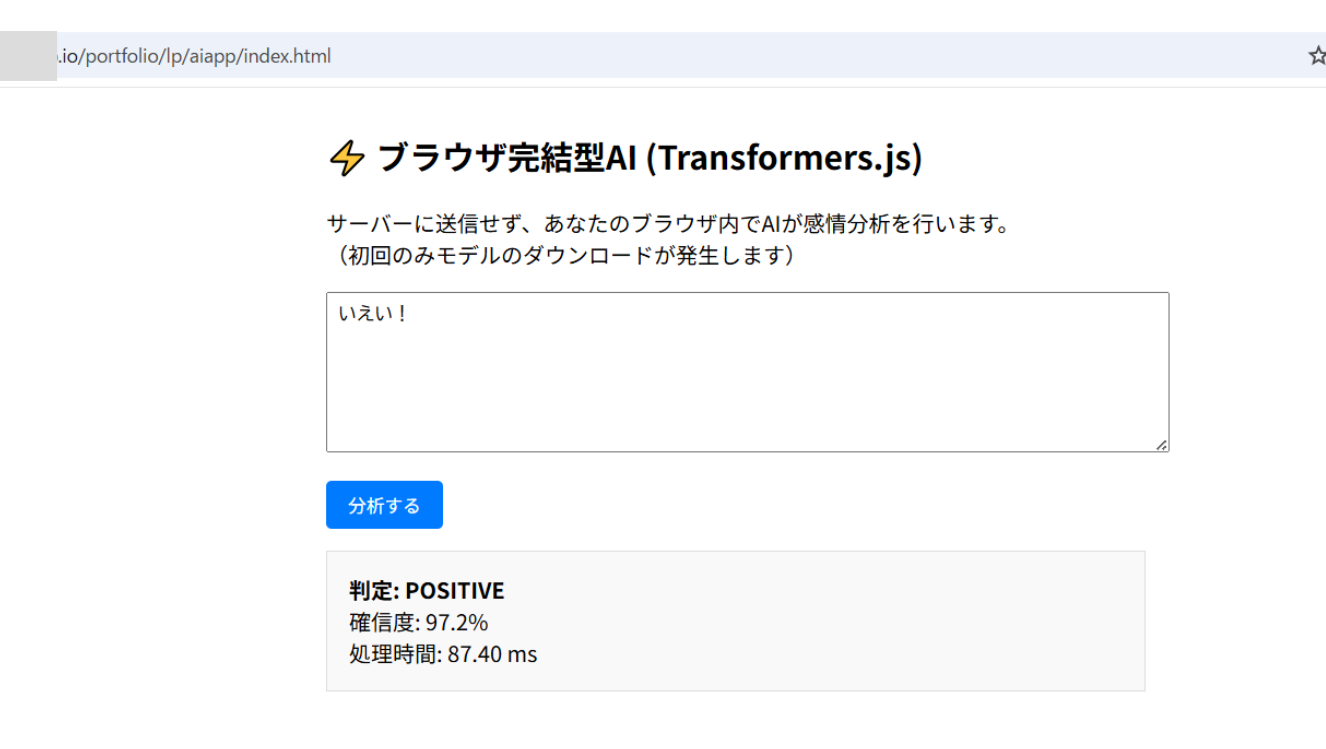
上記はローカルで実行していますが、Webサイト上にデプロイすることも可能です。以下はGitHub Pagesにデプロイして実行したときの画像です。
Transformers.js のメリットと課題
クライアントサイド推論の実現により、Transformers.js の利用には以下のようなメリットがあります。
- インフラ管理の負担・コストが不要
- 入力データがサーバーに送信されない(ブラウザ内に留まる)
- ONNX/WASM/WebGPUという標準技術で実現しているため、将来的なブラウザ進化の恩恵が期待できる
一方で以下のような課題もあるため、現状は軽量なモデルを扱うPoCやデモでの利用が現実的と考えられます。
- サーバーGPUほどの推論性能はない
- 初回のロードに時間がかかる(UXの工夫が必要)
- 実行環境依存が強い(ユーザーの端末やOSに配慮した設計が必要)
まとめ
現時点では感情分析、簡単な要約、画像分類などの軽量なタスクが主なユースケースですが、Web技術の進化によりブラウザ上でLLMが動く日が来るかもしれません。「サーバーレスAI」、試してみてはいかがでしょうか。