背景
以前の記事で青空文庫のアクセス数ランキングのデータを分析してみたところ,ダウンロードの必要があるtxt版においてのみ短編作品である太宰治作「あさましきもの」の人気があることが分かった.正直,ダウンロードの必要性を考慮して人気は長編作品に集中していると思い込んでいたので思わぬ収穫であった.さて,そうなると何故この作品が人気になったのかが気になる.ということで調べてみた.
作業環境
OS: Windows10
言語:Python3
Jupyter上でプログラムは実行した.
いつから人気なのか
そもそも,「あさましきもの」はいつ頃から人気になったのだろうか?ランキングのデータは2009年からあるのだが,2009年のデータは以下のプログラムでうまく取得できなかったので取り敢えず2010年からの全ランキングのデータを取得してそれぞれのランキングをcsvファイルにして出力するプログラムを作成した.今回は作品の推定読了時間は取得していない.プログラム内の変数monthを変更するとhtml版またはtxt版のどちらかを取得できるようになっている.月によってはランキングが存在しなかったりするので,その場合はパスをして処理を続行するように設定した.
# coding: utf-8
import urllib.request
from bs4 import BeautifulSoup
import re
from exp_length_v2 import exp_length
import pandas as pd
aozora_url="http://www.aozora.gr.jp/cards/"
# アクセスするURLを決定しhtmlデータを取得する
ranking_url='http://www.aozora.gr.jp/access_ranking/' # ranking all
response = urllib.request.urlopen(ranking_url)
data = response.read()
# htmlをBeautifulSoupで扱う
soup = BeautifulSoup(data, "html.parser")
# 年内合計,および年毎(12月→1月)のhtml版,txt版のランキングのテーブルを抽出
table=soup.tbody.hr.findAll('tbody')
# ある月のランキングからデータを取得する関数
def get_lists(month_link):
# 与えられたURLからhtmlデータを取得する
response = urllib.request.urlopen(month_link)
data = response.read()
# htmlをBeautifulSoupで扱う
soup = BeautifulSoup(data, "html.parser")
# それぞれの作品のテーブルを抽出
tables=soup.body.findAll(valign='top')
tables=tables[1:]
# 題名,著者,順位,アクセス数をリストにして値を返す
Lists=[]
for table in tables:
title=table.findAll('td')[1].get_text().replace('\n','')
author=table.findAll('td')[2].get_text()
rank=table.findAll('td')[0].get_text()
access=table.findAll('td')[3].get_text()
Lists.append([title, author, rank, access])
return Lists
# 年ごとのランキング情報取得のループを回す
for idx in range(len(table)):
year=table[idx].findAll('tr')
# 年内合計,月ごとのランキング情報取得のループを回す
for idy in range(len(year)):
# html版のランキングへのリンクを取得
#month=year[idy].findAll('a')[0].get('href')
# txt版のランキングへのリンクを取得
month=year[idy].findAll('a')[1].get('href')
link_month=ranking_url+month
try:
# ランキング情報をリストとして取得
Lists=get_lists(link_month)
# pandasのデータフレーム形式に変換してcsvファイルで出力する
df=pd.DataFrame(Lists,columns=['題名','著者','ランキング','アクセス数'])
df.to_csv("Ranking"+month[:-5]+".csv", index_label=None,index=None,encoding="utf-8")
# ユニコードの特殊文字があるので,excelで開く際にはデータのインポートから行う
print(month)
except:
print(month+' showed error')
print('done')
とりあえずこれでcsvファイルに保存できた.次に「あさましきもの」へのアクセス数,ランキング上の作品のアクセス数総和,アクセス数の総和で正規化した「あさましきもの」へのアクセス数を取得した.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
asamasis=[] #「あさましきもの」のアクセス数推移
Access=[] # ランキングデータ上の総アクセス数推移
norms=[] # 「あさましきもの」アクセス数/総アクセス数 の推移
for year in range(2010,2018):
for month in range(1,13):
filename='Ranking'+str(year)+'_'+"{0:02d}".format(month)+'_txt.csv'
# txt版のアクセスランキングのデータを取得する
try:
# ファイルの読み込み
df=pd.read_csv(filename, header=None,encoding="utf-8").dropna()
# 「あさましきもの」のアクセス数取得
asamasi=float(df[df[0].isin(['あさましきもの'])][3])
# ランキング上のそれぞれの作品のアクセス数を取得
access=df[3][1:].get_values()
# floatに変換
for idx in range(len(access)):
access[idx]=float(access[idx])
# アクセス数の和を取得
access=sum(access)
Access.append(access)
# 総アクセス数で正規化した値を取得
norms.append(asamasi/access)
asamasis.append(asamasi)
print(filename)
except:
# ファイルが無かった時はNone値を追加
asamasis.append(None)
Access.append(None)
norms.append(None)
print(filename+' doesn\'t exist')
「あさましきもの」txt版へのアクセス数
%matplotlib inline
# 「あさましきもの」へのアクセス数の推移
plt.plot(asamasis)
plt.xticks(range(0,12*8,12),range(2010,2018))
plt.xlabel('Years')
plt.ylabel('Access')
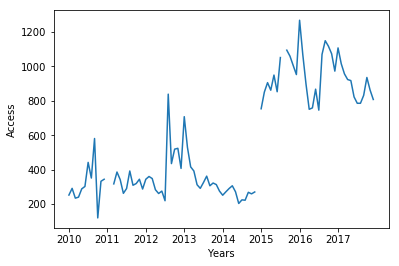
どうやら2015年に突如アクセス数が増加したようだ.しかし,たまたま青空文庫へのアクセスが増加していたためかもしれない.ということで総アクセス数の推移も見てみよう.
ランキングに記載されたtxt版作品の総アクセス数の推移
%matplotlib inline
plt.plot(Access)
plt.xticks(range(0,12*8,12),range(2010,2018))
plt.xlabel('Years')
plt.ylabel('Access')
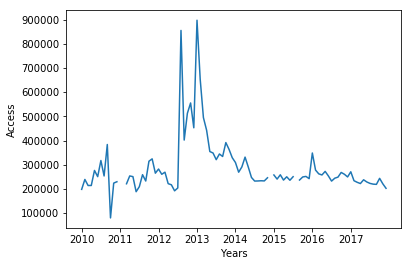
2012年中盤に青空文庫のtxt版へのアクセス数が増加したようだ.
「あさましきもの」へのアクセス/総アクセス数の推移
%matplotlib inline
plt.plot(norms)
plt.xticks(range(0,12*8,12),range(2010,2018))
plt.xlabel('Years')
plt.ylabel('Normed_access')
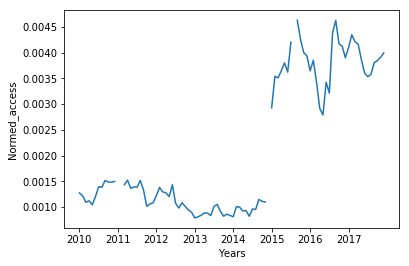
どうやら青空文庫へのアクセス数増加では「あさましきもの」へのアクセス数増加は説明ができないようだ.
原因は何なのだろうか
どうやら何か他に原因があるようだ.例えば,このような急激なアクセス増加は,「あさましきもの」特異的な現象なのだろうか?それを調べるために,「あさましきもの」のアクセス数・ランキング移と似た推移をする作品をアクセス数推移間の相関から求めた.
データを取得
import pandas as pd
import numpy as np
others=[] # 作品名のストック
authors=[] # 著者名のストック
for year in range(2010,2018):
for month in range(1,13):
filename='Ranking'+str(year)+'_'+"{0:02d}".format(month)+'_txt.csv'
# txt版のアクセスランキングのデータを取得する
try:
df=pd.read_csv(filename, header=None,encoding="utf-8").dropna()
# 2010年1月のランキング上作品タイトルデータを抽出する
if year==2010:
if month == 1:
dd=pd.read_csv('Ranking2015_01_txt.csv', header=None,encoding="utf-8").dropna()
for idx in range(len(df)):
if idx != 0:
try:
print(idx)
others.append(df[0][idx])
authors.append(df[1][idx])
except:
pass
print('add the other ' + str(len(others)) + ' titles')
AS=np.zeros((len(others),12*8)) # 作品ごとのアクセス数
RS=np.zeros((len(others),12*8)) # 作品ごとのランキング
# 作品ごとにアクセス数とランキングデータを取得
for idx,title in enumerate(others):
try:
AS[idx,(year-2010)*12+month-1]=float(df[df[0].isin([title])][3])
RS[idx,(year-2010)*12+month-1]=float(df[df[0].isin([title])][2])
# 作品がランキング上に無い場合
except:
AS[idx,(year-2010)*12+month-1]=200. # アクセス数を200に
RS[idx,(year-2010)*12+month-1]=500. # ランキング順位を500に
print(filename)
# ファイルが存在しないはエラーを出力して処理を続行
except:
print(filename+' doesn\'t exist')
相関行列の作成.
# 作品ごとのアクセス数推移を用いて作品間の相関行列を作成
C=np.corrcoef(AS)
# アクセス数順位の推移を用いて相関行列を作成
CR=np.corrcoef(RS)
相関が高い10作品の抽出
Corrs=[]
for rank in range(10):
if rank ==0:
# 「あさましきもの」は228番目に保管されている
idr=np.argmax(C[228]) # ここをCRにするとランキング相関に
che=C[228]
che[idr]=0
idr=np.argmax(che)
Corrs.append([others[idr],authors[idx],str(idr),che[idr]])
che[idr]=0
print(Corrs)
「あさましきもの」との相関(アクセス数)
| Title | Author | id | correlation |
|---|---|---|---|
| 'いなか、の、じけん' | '夢野 久作\u3000' | '355' | 0.75250919523161974 |
| '美少女' | '太宰 治\u3000' | '372' | 0.68587030676740279 |
| 'I can speak' | '太宰 治\u3000' | '93' | 0.63625564908728494 |
| '女生徒' | '太宰 治\u3000' | '188' | 0.5938179686365278 |
| '駈込み訴え' | '太宰 治\u3000' | '323' | 0.57851376302263458 |
| '川端康成へ' | '太宰 治\u3000' | '302' | 0.57334734340185978 |
| '富嶽百景' | '太宰 治\u3000' | '282' | 0.5726281104813491 |
| '愛' | '岡本 かの子\u3000' | '476' | 0.54021449601171312 |
| 'トカトントン' | '太宰 治\u3000' | '374' | 0.49328594740122145 |
| '文鳥' | '夏目 漱石\u3000' | '384' | 0.48031823515444438 |
「あさましきもの」との相関(ランキング順位)
| Title | Author | id | correlation |
|---|---|---|---|
| 'I can speak' | '太宰 治\u3000' | '93' | 0.85969524090548788 |
| '美少女' | '太宰 治\u3000' | '372' | 0.79445108216476246 |
| '川端康成へ' | '太宰 治\u3000' | '302' | 0.7800175601091951 |
| '文鳥' | '夏目 漱石\u3000' | '384' | 0.73057346994482486 |
| 'いなか、の、じけん' | '夢野 久作\u3000' | '355' | 0.68877634751474026 |
| '駈込み訴え' | '太宰 治\u3000' | '323' | 0.67733921407308728 |
| '愛' | '岡本 かの子\u3000' | '476' | 0.67219661256702468 |
| '人生論ノート' | '三木 清\u3000' | '259' | 0.65518569362939993 |
| 'トカトントン' | '太宰 治\u3000' | '374' | 0.59462851551401996 |
| '堕落論' | '坂口 安吾\u3000' | '87' | 0.54999225258907891 |
| 圧倒的太宰治作品率. |
結果を踏まえて
夢野久作の「いなか,の,じけん」も同時期にアクセスが増加した可能性があるようだが,以前から公開されていた太宰治作品が急に人気を帯びたと考えるのが自然であろう.特に,相関値が高かった「I can speak」や「美少女」のどちらも非常に短い作品である.「あさましきもの」も短編作品だったことからも,特に太宰治の短編作品をダウンロードして読むことに特定の需要が高まったことが考えられる.
結局何故人気になったのか分かっていない
太宰治の短編作品需要が高まったことまでは分かったが,その原因が分からない.そこで偉大なるGoogle先生に頼ることにした.とりあえず「あさましきもの」「I can speak」「美少女」で検索してみる.この時,検索期間設定を2014年10月1日から2015年1月30日に設定してみた.
修士研究として?
それらしいサイトにヒット.どうやら修士論文として太宰治作品に用いられる色彩語の研究を行っていたようだ.上記の3作品も解析の対象になっている.頻繁にこれらの作品をダウンロードしていたとすれば原因と考えられるが,データを青空文庫からダウンロードしたとは一言も書いていないので断定は難しい.
サイトの紹介?
検索ワードを「あさましきもの」「I can speak」に限定したところ次のサイトがヒット.どうやら太宰治作品初読者におすすめの作品を紹介しているようだ.しかも公開日が2014年の12月10日!時期的には極めて一致するものである.
文豪ストレイドッグス???
思い当たる節があって「文豪ストレイドッグス」で検索してみた.するとどうであろうか,一番最初に表示される登場人物のpixiv百科事典は太宰治のものであった.また,次の記事では12月4日の新刊発売を記念する企画で書店とコラボレーションをしていることが分かる.これをきっかけにして作品の読者の増加につながり,人気キャラクターの作品の需要が高まった可能性がある.
個人的考察
これまでの内容を踏まえての個人的な考察であるが,文豪ストレイドッグスの人気が急激に増加し,それに伴い人気キャラクターである太宰治作品の需要が高まった.その結果紹介サイトなどを通して短編作品の存在を知り,作品をブラウザではなくそれぞれの思い思いの媒体で読みたい読者層による人気がtxt版でのアクセス増加の要因になったのではないだろうかと考えた.もちろんこれらは明確な根拠に基づいたものではない.むしろこれを読んだどなたかが新しい発見をした場合は教えていただけると大変嬉しい.
感想
この解析を通して秘めたる人気作品を個人的には知ることができたと考えている.しかし,正直データ解析をした感じはあまりしないので,今後はレコメンデーションなども勉強して好みの作品を見つけられるようにしたい.
一方で,アクセス数の急激な推移変化の原因を追うことの難しさも痛感した.スクローリングなども勉強すればもっと効率よく原因解明ができるのではないかとも検討している.
コードや解析についての意見やご質問もお待ちしています.