Pythonを使ってTwitterに画像付きツイートをするBotを作ろうと考えました。
TwitterのREST APIを使い、PythonでTwitterを操作するライブラリはいくつか存在します。その中で活発に開発が継続している「TwitterAPI」というライブラリがあります。
このライブラリはネーミングセンスが最悪で、Twitter社が用意しているREST APIの「Twitter API」と同名でググりにくさも相まって情報が探しにくいです。そこで自身のアプリを制作する際に必要最低限の機能を簡単に関数化しましたので、Qiitaに画像付きツイートをするまでのチュートリアルとして残しておくことにしました。
やること
- ライブラリのインストール
- ユーザー認証
- タイムライン表示
- 自分のホームTLを表示
- 特定ユーザーのTLを表示
- 特定ユーザーのツイート各種情報を表示
- キーワード検索してツイート表示
- 書き込み
- 文字列だけでツイート
- ローカルファイルの画像をアップロードして画像付きツイート
- 画像URLを指定して画像付きツイート
基本的にはこのライブラリの./examplesディレクトリに多くのサンプルがあります。詳しく知りたい方はTwitterのAPIドキュメントと併せてそちらを参照してください。
インストール
pipでのインストールが可能です。
pip install TwitterAPI
ユーザー認証する
まず認証をしないと何も始まらないです。Twitter APIを利用するためのAPIキーを発行するには少しだけ面倒な申請が必要ですが、もちろん無料で10分程度の手間で出来ます。この記事では申請関連の記述の仕方は記載しませんので、こちらの記事などを参考に申請を完了してください。
以降は、既にアプリケーション申請をしてRead & Write権限のトークンが発行されている前提で進めます。
from TwitterAPI import TwitterAPI
consumer_key = 'WWW' # 自身のCustomer Key
consumer_secret = 'XXX' # 自身のCustomer Secret Key
access_token_key = 'YYY' # Read & Write権限で発行したAccess Token Key
access_token_secret = 'ZZZ' # 上記AccessトークンのSecret Key
api = TwitterAPI(consumer_key, consumer_secret, access_token_key, access_token_secret)
タイムライン表示
自身のホームTLのツイート取得
def read_home_timeline(num):
r = api.request('statuses/home_timeline', {'count':num})
tws = []
for item in r.get_iterator():
if 'text' in item:
tws.append(item['text'])
return tws
# 10件取得してみる
home_tl_list = read_home_timeline(10)
print(home_tl_list)
特定ユーザーのツイート取得
def read_user_timeline(user_s_nm, num):
r = api.request('statuses/user_timeline', {'screen_name':user_s_nm, 'count':num})
tws = []
for item in r.get_iterator():
if 'text' in item:
tws.append(item['text'])
return tws
# 八景島シーパラダイスの公式アカウントのツイートを10件取得してみる
seapara_tl_list = read_user_timeline('_seaparadise_', 10)
print(seapara_tl_list)
['🎄12/24(木)・25(金)限定🎅\n\nクリスマスの夜だけご覧いただける特別ショーを開催🌟…]
水族館が好きなのでシーパラを例にしましたが、'_seaparadise_'部分を自分のアカウント名に指定すれば自分のツイートを取得できます。
上記はitem['text']としてツイート内容のみ抜き出していますが、r.get_iterator()部分をr.json()と書き換えて返却すれば辞書形式で各種情報を得られます。
def read_user_tl_json(user_s_nm, num):
r = api.request('statuses/user_timeline', {'screen_name':user_s_nm, 'count':num})
return r.json()
# 八景島シーパラダイスの公式アカウントのツイートの各種情報を辞書で取得
seapara_tl_dict = read_user_tl_json('_seaparadise_', 1)
# リストの中に辞書が格納されている形で返却される
print(type(seapara_tl_dict[0]))
print(seapara_tl_dict)
:出力結果
<class 'dict'>
[{'created_at': 'Thu Dec 10 10:00:07 +0000 2020', 'id': 1336973962341806081, 'id_str': '1336973962341806081', 'text': '🎄12/24(木)・25(金)限定🎅…]
キーワード検索で得たツイートを取得する
def read_tweet_search(search_word, num):
r = api.request('search/tweets', {'q':search_word, 'count':num})
tws = []
for item in r:
if 'text' in item:
tws.append(item['text'])
return tws
# 'Microsoft'と発言しているツイートを10件取得取得してみる
ms_search_tw_list = read_tweet_search('Microsoft', 10)
print(ms_search_tw_list)
['@Microsoft This is me in regards to basically any halo…]
書き込み
ツイートする
def write_tweet_text(text):
r = api.request('statuses/update', {'status': text})
print('SUCCESS' if r.status_code == 200 else 'FAILURE')
write_tweet_text('テストツイートです')
結果
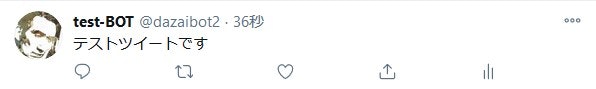
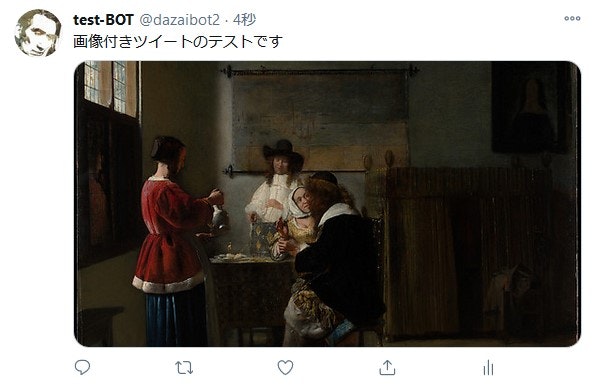
画像付きツイートをする(ローカルファイル)
画像付きのツイートをする場合は、まずTwitterに画像をアップロードし、アップロードした画像のmedia_idを取得し、ツイートする際のリクエストでmedia_idsキーの値に対象の画像のmedia_idを指定します。
※画像はパブリック・ドメインのものを使用しました。
def write_tweet_img(text, img_file_nm):
# ステップ1:画像アップロード
file = open(img_file_nm, 'rb')
data = file.read()
r = api.request('media/upload', None, {'media': data})
print('UPLOAD MEDIA SUCCESS' if r.status_code == 200 else 'UPLOAD MEDIA FAILURE')
# ステップ2:アップロードした画像の参照付きでツイート
if r.status_code == 200:
media_id = r.json()['media_id']
r = api.request('statuses/update', {'status':text, 'media_ids':media_id})
print('SUCCESS' if r.status_code == 200 else 'FAILURE')
write_tweet_img('画像付きツイートのテストです', './test_image.jpg')
結果
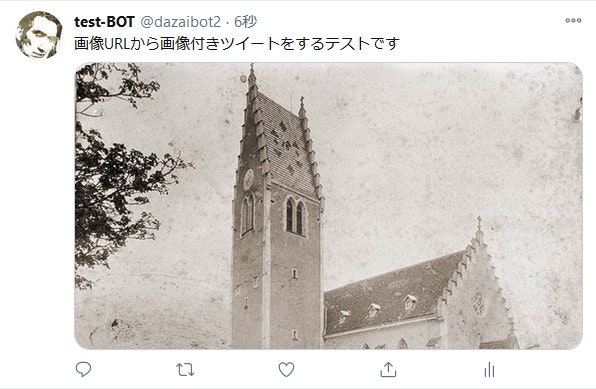
画像付きツイート(画像URLで指定する)
画像付きツイートをする際、画像をローカルファイルではなくURL指定する場合、base64エンコード形式にしてからデータをアップロードする形をとります。
import requests
import base64
# URLで指定された画像をbase64形式にエンコード
def get_as_base64(url):
content = requests.get(url).content
content_b64 = base64.b64encode(content)
return content_b64
def write_tweet_img_url(text, img_url):
# キー名を「media_data」にする
r = api.request('media/upload', None, {'media_data': get_as_base64(img_url)})
print('UPLOAD MEDIA SUCCESS' if r.status_code == 200 else 'UPLOAD MEDIA FAILURE')
if r.status_code == 200:
# アップロードした画像の'media_id'を得る
media_id = r.json()['media_id']
# 'media_id'をつけてツイートする
r = api.request('statuses/update', {'status':text, 'media_ids':media_id})
print('SUCCESS' if r.status_code == 200 else 'FAILURE')
write_tweet_img_url(
'画像URLから画像付きツイートをするテストです',
'https://upload.wikimedia.org/wikipedia/commons/5/5b/Pfarrkirche_Maria_Himmelfahrt_Bendern_FL.jpg'
)
結果