はじめに
LightGBMで作ったモデルで予測させるときに、predictの関数を使っていました。
pred = model.predict(data) という感じです。
ふと公式のドキュメントを見てみたら、predictの引数にpred_contribというパラメタがあって、SHAPを使った予測への寄与度を出せると書かれてあったので、試してみました。
環境
環境は以下の通り。
$ sw_vers
ProductName: Mac OS X
ProductVersion: 10.13.6
BuildVersion: 17G14042
Jupyterlab (Version 0.35.4) 上で作業していたので、python kernelのバージョンも記載しておきます。
Python 3.7.3 (default, Mar 27 2019, 16:54:48)
IPython 7.4.0 -- An enhanced Interactive Python. Type '?' for help.
モデル構築
予測するためのデータとモデルを用意します。
データはscikit-learnで用意されているボストンデータセットを使用しました。
import pandas as pd
import sklearn.datasets as skd
data = skd.load_boston()
df_X = pd.DataFrame(data.data, columns=data.feature_names)
df_y = pd.DataFrame(data.target, columns=['y'])
以下の通り、506行13列のデータで全列がnon-nullのfloat型なのでこのままモデルを作ります。
df_X.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 506 entries, 0 to 505
Data columns (total 13 columns):
CRIM 506 non-null float64
ZN 506 non-null float64
INDUS 506 non-null float64
CHAS 506 non-null float64
NOX 506 non-null float64
RM 506 non-null float64
AGE 506 non-null float64
DIS 506 non-null float64
RAD 506 non-null float64
TAX 506 non-null float64
PTRATIO 506 non-null float64
B 506 non-null float64
LSTAT 506 non-null float64
dtypes: float64(13)
memory usage: 51.5 KB
LightGBMで、ハイパーパラメタはでほぼデフォルトのままでモデルを構築しておきます。
なお、このあと使うSHAPがモデルに設定したobjectiveのパラメタ設定値を見に行くので、デフォルトで問題ありませんが、paramsにobjectiveを明記しています(無いと後のexplainer.shap_valuesでエラーになります)。
import lightgbm as lgb
from sklearn.model_selection import train_test_split
df_X_train, df_X_test, df_y_train, df_y_test = train_test_split(df_X, df_y, test_size=0.2, random_state=4)
lgb_train = lgb.Dataset(df_X_train, df_y_train)
lgb_eval = lgb.Dataset(df_X_test, df_y_test)
params = {
'seed':4,
'objective': 'regression',
'metric':'rmse'}
lgbm = lgb.train(params,
lgb_train,
valid_sets=lgb_eval,
num_boost_round=200,
early_stopping_rounds=20,
verbose_eval=50)
Training until validation scores don't improve for 20 rounds
[50] valid_0's rmse: 3.58803
[100] valid_0's rmse: 3.39545
[150] valid_0's rmse: 3.31867
[200] valid_0's rmse: 3.28222
Did not meet early stopping. Best iteration is:
[192] valid_0's rmse: 3.27283
このあと使う予測用のデータを用意しておきます。
# 予測させるデータ
data_for_pred = pd.DataFrame([df_X_test.iloc[0, :]])
print(data_for_pred)
CRIM ZN INDUS CHAS NOX RM AGE DIS RAD TAX \
8 0.21124 12.5 7.87 0.0 0.524 5.631 100.0 6.0821 5.0 311.0
PTRATIO B LSTAT
8 15.2 386.63 29.93
predictで予測値の寄与度を出す
predict にデータを渡せば予測できます。
# 普通の予測
print(lgbm.predict(data_for_pred))
[16.12018486]
ここで、pred_contrib=Trueを引数に渡してpredictを実行します。
# pred_contrib=True
print(lgbm.predict(data=data_for_pred, pred_contrib=True))
[[ 8.11013815e-01 1.62335755e-03 -6.90242856e-02 9.22244470e-03
4.92616768e-01 -3.16444968e+00 -1.22276730e+00 -1.11934703e-01
2.56615903e-02 -1.99428008e-01 1.25166390e+00 3.43507676e-02
-4.03663118e+00 2.22982674e+01]]
このように、今回のデータだと1行14列の2次元配列を得ます。
公式ドキュメントでは、
Note that unlike the shap package, with pred_contrib we return a matrix with an extra column, where the last column is the expected value.
と書かれているので、1から13列目までは各特徴量の寄与度、14列目がexpected valueだとのことです。
この辺をSHAPで確認してみます。
SHAPで確認
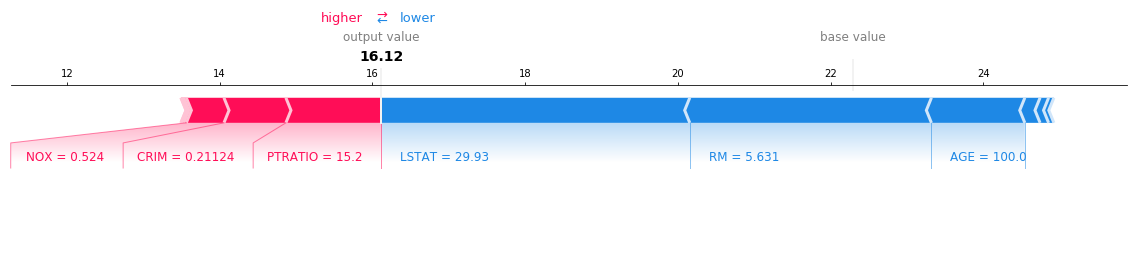
作ったモデルをTreeExplainerに渡してshap_valuesとexpected_valueを出してみると確かにpredictで出した値と一致しています。
つまり、force_plotで出力した図で使っているのと同じ情報をpredictでも得ることができるということが確かめられました。
import shap
explainer = shap.TreeExplainer(lgbm)
shap_values = explainer.shap_values(data_for_pred)
print('shap_values: ', shap_values)
print('expected_value: ', explainer.expected_value)
shap.force_plot(base_value=explainer.expected_value, shap_values=shap_values[0,:], features=data_for_pred.iloc[0,:], matplotlib=True)
shap_values: [[ 8.11013815e-01 1.62335755e-03 -6.90242856e-02 9.22244470e-03
4.92616768e-01 -3.16444968e+00 -1.22276730e+00 -1.11934703e-01
2.56615903e-02 -1.99428008e-01 1.25166390e+00 3.43507676e-02
-4.03663118e+00]]
expected_value: 22.29826737657883
そういえば、ここでexpected_valueってなんだっけ?と思い、SHAPのドキュメントを見ると、expected_valueは
the average model output over the training dataset we passed
とのこと。んー、もしかして学習用データの目的変数の平均値?と思って、meanを出して見ると確かに一致しました。
print(df_y_train.mean())
y 22.298267
dtype: float64
まとめ
ということで、LightGBMのpredictでshap_valueとexpected_valueが得られることが分かりました。
ただ、pred_contrib=Trueにすると、予測値そのものは出力されないところには注意かなと思いました。
なので、
pred = model.predict(data)
contrib = model.predict(data, pred_contrib=True)
# predが学習用データの目的変数の平均値よりも大きいとき:予測を押し上げた理由を出力
# predが学習用データの目的変数の平均値よりも小さいとき:予測を押し下げた理由を出力
という感じで使うといいのかなーと。
(jupyterってnotebookファイルをmarkdownに変換できるんですね。知りませんでした。今回以降活用していきたいと思います。)