はじめに
GPUの性能が急速に伸びている中,数値計算界隈でもGPUでソルバーを解く機運が高まってきています.
しかし,cuda関連のプログラミングはレガシーな書き方が必要なため,自作はなかなか大変です.
そこで今回は,MAGMAと呼ばれるGPUによる線形代数ライブラリをインストールして連立一次方程式を解きたいと思います.
インストールだけだと,公式を見たほうが良いということになってしまうため,ここではEigen(CPUによる線形代数ライブラリ)からMAGMAへのデータ受け渡しについても書きたいと思います.
本記事で行う操作のイメージとしては,
Eigenで行列操作
↓
MAGMAに受け渡してAx=bを解く.
という感じです.
- makefileの編集ができること
- cudaがインストール済みであること
を前提に書いていきます.
私は,こちらの方のサイトを参考にCUDAを入れました.
nvcc -V
と打ってバージョンが出れば問題ないと思います.
目次
MAGMAとは
マシン情報
ディストリビューション: Ubuntu
バージョン: 18.04.5 LTS
CPU
Intel(R) Core(TM) i9-10900X CPU @ 3.70GHz
物理コア数:1
総スレッド数:20
GPU
NVIDIA GeForce RTX 2080 Ti
CUDA version: 11.4
Driver version: 470.57.02
メモリ: 32GB
インストール手順
openblasのインストール
MAGMAは,intel-MKL,openblas...等幅広いLAPACKに対応しています.自分は最初intelMKL(OneAPI)のライブラリを使おうとしましたが,OneAPIで入れたmklは対応しておらず(不可能ではないと思いますが),代わりにopenblasを用いることにしました.インストールは簡単で,
sudo apt install libopenblas-dev gfortran
だけです.
~10月7日追記~
ローカルに落としたい方はこちらが参考になります.
MAGMAのダウンロード
2021年10月4日地点での最新版を落とします.
wget http://icl.utk.edu/projectsfiles/magma/downloads/magma-2.6.1.tar.gz
tar -xzf magma-2.6.1.tar.gz
ビルド用のPATHをつなぐ
人によって違うと思いますが参考に...
export CUDADIR=/usr/local/cuda
export OPENBLASDIR=/usr/lib/x86_64-linux-gnu/openblas
make
make.inc-examplesディレクトリの中に様々なパターンのmake.incファイルがあります.
ここでは,"make.inc.openblas"を使います.
cp make.inc-examples/make.inc.openblas make.inc
このmake.incを開くと設定ファイルが出てくるので,修正していきます.
まず,openblasのパスは以下の通り.
OPENBLASDIR ?= /usr/lib/x86_64-linux-gnu/openblas
"set our GPU targets"では,マシンによって決まるGPUのアーキテクチャを選びます.
2080Tiは"Turing"なので,
GPU_TARGET = Turing
あとはmakeします.
自分は上記の操作で通りましたが,環境によってはmake.incをうまく編集する必要があります.
make
sudo mkdir /usr/local/magma
sudo chown $(whoami) /usr/local/magma
make install
sudo chown -R root /usr/local/magma
~10月7日追記~
ローカルに落としたい人は
make
make install prefix=<your path>/magma
magma/example/内でビルドがうまくいっているかテストすることができます.
Eigen+MAGMAコード例
以下のような"magmacg.cu"ファイル及び"Makefile"を作りました.
Eigen::SparseMatrixのouterIndexPtr(), innerIndexPtr(),valuePtr()メソッドで,ダイレクトに行列情報を送ることができるのが素晴らしいです.
# include <Eigen/Core>
# include <Eigen/Sparse>
# include <iostream>
# include <magma/include/magma_v2.h>
# include <magma/sparse/include/magmasparse.h>
using namespace Eigen;
using namespace std;
// solve Ax=b
int main()
{
int m = 10;
int n = 1;
// diagonal matrix A
SparseMatrix<double> AEigen(m, m);
for(int i = 0; i < m; i++)
AEigen.coeffRef(i, i) = 0.05;
// x,b
VectorXd rhs(m), sol(m);
rhs.setOnes();
sol.setZero();
// Initialize MAGMA and create some LA structures.
magma_init();
magma_dopts opts;
magma_queue_t queue;
magma_queue_create(0, &queue);
memset(&opts, 0, sizeof(magma_dopts));
magma_d_matrix A = {Magma_CSR}, dA = {Magma_CSR};
magma_d_matrix b = {Magma_CSR}, db = {Magma_CSR};
magma_d_matrix x = {Magma_CSR}, dx = {Magma_CSR};
// Pass the system to MAGMA.
magma_dcsrset(m, m, AEigen.outerIndexPtr(), AEigen.innerIndexPtr(),
AEigen.valuePtr(), &A, queue);
magma_dvset(m, 1, rhs.data(), &b, queue);
// Choose a solver, preconditioner, etc. - see documentation for options.
opts.solver_par.solver = Magma_PCGMERGE;
opts.solver_par.maxiter = 5000;
opts.solver_par.rtol = 1e-10;
opts.precond_par.solver = Magma_JACOBI;
opts.precond_par.levels = 0;
opts.precond_par.trisolver = Magma_CUSOLVE;
// Initialize the solver.
magma_dsolverinfo_init(&opts.solver_par, &opts.precond_par, queue);
// Copy the system to the device
magma_dmtransfer(A, &dA, Magma_CPU, Magma_DEV, queue);
magma_dmtransfer(b, &db, Magma_CPU, Magma_DEV, queue);
// initialize an initial guess for the iteration vector
magma_dvinit(&dx, Magma_DEV, b.num_rows, b.num_cols, 0.0, queue);
// Generate the preconditioner.
magma_d_precondsetup(dA, db, &opts.solver_par, &opts.precond_par, queue);
cudaDeviceSynchronize();
// If we want to solve the problem, run:
magma_d_solver(dA, db, &dx, &opts, queue);
cudaDeviceSynchronize();
// Then copy the solution back to the host...
magma_dmtransfer(dx, &x, Magma_DEV, Magma_CPU, queue);
// and back to the application code
magma_dvcopy(x, &m, &n, sol.data(), queue);
std::cout << "iterations: " << opts.solver_par.numiter << std::endl;
std::cout << " res: " << opts.solver_par.iter_res << std::endl;
// Free the allocated memory...
magma_dmfree(&dx, queue);
magma_dmfree(&db, queue);
magma_dmfree(&dA, queue);
magma_dmfree(&b, queue); // won't do anything as MAGMA does not own the data.
magma_dmfree(&A, queue); // won't do anything as MAGMA does not own the data.
// and finalize MAGMA.
magma_queue_destroy(queue);
magma_finalize();
// output
cout << sol << endl;
}
# ---------------------------------------------------------------
# User setting
# ---------------------------------------------------------------
# path
MAGMADIR ?= /usr/local/magma
CUDADIR ?= /usr/local/cuda
OPENBLASDIR ?= /usr/lib/x86_64-linux-gnu/openblas
# exe file
TARGET = magmacg.out
# set Eigen's path
INCLUDES = -I ../vendor/
# for magma
INCLUDES += -DADD_ -I$(MAGMADIR)/include -I$(MAGMADIR)/sparse/include -I$(CUDADIR)/include
# compiler
GCC = nvcc
# compiler option
CFLAGS = -std=c++14 -MMD -MP -O3 -DEIGEN_NO_DEBUG -DEIGEN_INITIALIZE_MATRICES_BY_ZERO
# link
LDFLAGS = -lm -L$(MAGMADIR)/lib -lmagma_sparse -lmagma -L$(CUDADIR)/lib64 -lcublas -lcudart -lcusparse -L$(OPENBLASDIR)/lib -lopenblas
# no make directory
NOMAKEDIR= .git% data% doc%
# object directory
OBJDIR = objs
# ---------------------------------------------------------------
# Don't change the following
# ---------------------------------------------------------------
# Run through the source directory with find command and list it down to the subdirectories.
SRCDIRS := $(shell find . -type d)
# List all cpp files with the foreach command based on the SRCDIRS
CPPS = $(foreach dir, $(SRCDIRS), $(wildcard $(dir)/*.cu))
# Remove directories not to make.
SRCS = $(filter-out $(NOMAKEDIR), $(CPPS))
# Get the name of the directory containing the SRCS.
DIRS = $(dir $(SRCS))
# Create a directory for binary with the same structure as the cpp files.
BINDIRS = $(addprefix $(OBJDIR)/, $(DIRS))
# Determine the object file name based on the SRCS
OBJS = $(addprefix $(OBJDIR)/, $(patsubst %.cu, %.o, $(SRCS)))
# Make the dependency file .d from the .o file
DEPS = $(OBJS:.o=.d)
default:
@[ -d $(OBJDIR) ] || mkdir -p $(OBJDIR)
@[ -d "$(BINDIRS)" ] || mkdir -p $(BINDIRS)
@make all --no-print-directory
@echo "make done!!"
all : $(OBJS) $(TARGET)
$(TARGET): $(OBJS) $(LIBS)
$(GCC) -o $@ $^ $(LDFLAGS)
$(OBJDIR)/%.o: %.cu
$(GCC) $(CFLAGS) $(INCLUDES) -o $@ -c $<
clean:
@rm -rf $(TARGET) $(OBJDIR)
-include $(DEPS)
Eigenへのパスだけ編集すれば,makeできます.
大量の"warning"が出ますが動くのでよしとします.
make
./magmacg.out
対角行列なので反復計算はしません.
iterations: 1
res: -0
20
20
20
20
20
20
20
20
20
20
所感
これを自分が作っているFEMプログラムに差し込んでみました.
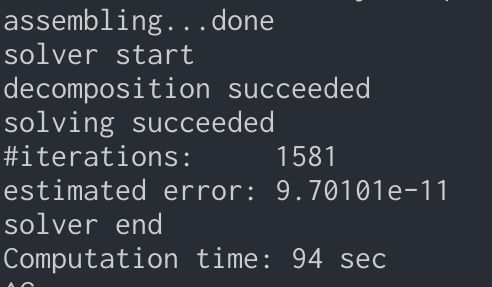
約200万自由度のFEMの計算を行った結果です.
Eigen(CPU)のCG
Magma(GPU)のCG
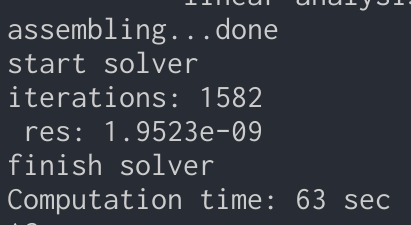
精度に申し分はなく,計算時間は2/3程度になりました.
アセンブリングなどの時間込みなので,ソルバーの時間だけでみれば更に差がついていると考えられます.
多分行列のサイズを大きくすれば更に差がつくと思います.そのへんの検証はまた時間があるときにやります.
裏を返せば,100万自由度超の計算でなければ恩恵は受けれないと思います.