TiDBは、スケーラブルで高可用な分散SQLデータベースです。そのパフォーマンスを最大限に引き出すためには、クエリ最適化のためのクエリレビューが欠かせません。この記事では、TiDBにおけるクエリレビューの方法を紹介したいと思います。
なぜクエリレビューを行うのか
-
コスパ
クエリレビューで非効率のクエリの改善により、同じスペックのクラスターのスループットが多くなり、全体のコスパが改善されることはあります。 -
性能・レイテンシー
非効率のクエリの改善、例えば、不必要なフルテーブルスキャンを避け、適切なインデックスを使用し、クエリプランを最適化することで、クエリ性能を大幅に向上させることができます。 -
障害対応:
アプリケーションにパフォーマンスの問題が発生したり、データベースの負荷が異常になった場合、クエリのレビューは問題を引き起こしている可能性のあるクエリを発見し、迅速に問題を特定して修正するための助けになります。
TiDB のクエリの実行計画の基本知識
TiDB のアーキテクチャ によると、クエリがオプティマイザーによって、論理最適化・物理最適化され、実行計画(図のPhysical planの部分」になり、distributed executor に実行されます。実行計画はクエリ実行のアルゴリズムそのものになるので、効率の良し悪しは非常に重要になります。
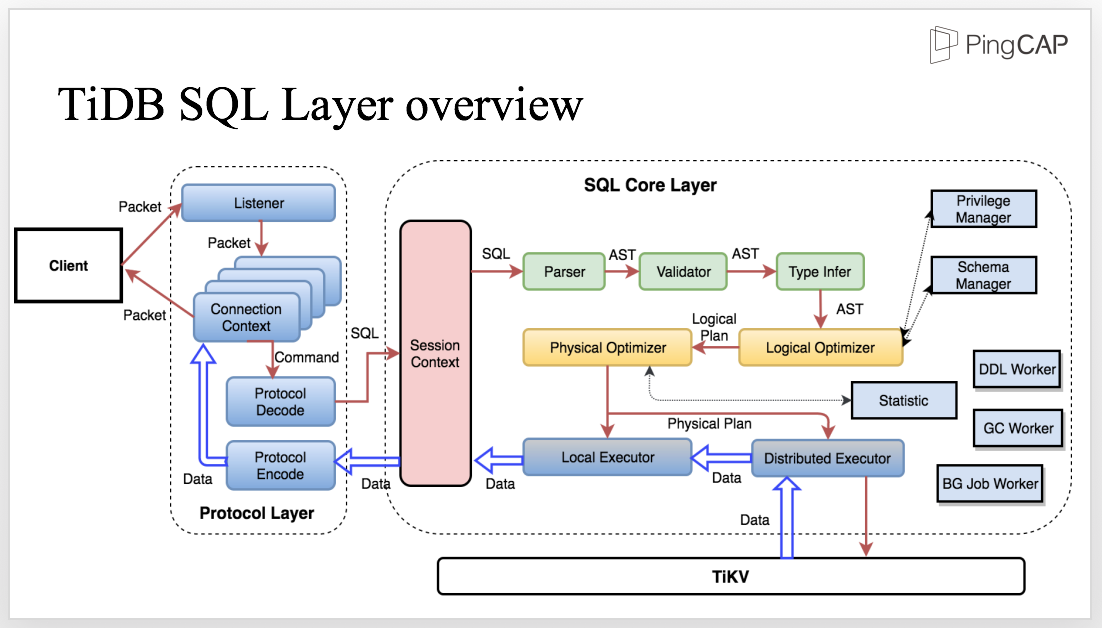
クエリの実行計画の確認できる場所はいくつがあります:
-
explain また explain analyze での確認
※ explain analyze は実際に後ろのクエリを実行するので、実行時の情報(actRows と execution info)も含まれるEXPLAIN SELECT COUNT(*) FROM t1; +----------------------------+-----------+-----------+---------------+---------------------------------+ | id | estRows | task | access object | operator info | +----------------------------+-----------+-----------+---------------+---------------------------------+ | StreamAgg_16 | 1.00 | root | | funcs:count(Column#7)->Column#5 | | └─TableReader_17 | 1.00 | root | | data:StreamAgg_8 | | └─StreamAgg_8 | 1.00 | cop[tikv] | | funcs:count(1)->Column#7 | | └─TableFullScan_15 | 242020.00 | cop[tikv] | table:t1 | keep order:false | +----------------------------+-----------+-----------+---------------+---------------------------------+ 4 rows in set (0.00 sec) EXPLAIN ANALYZE SELECT COUNT(*) FROM t1; +----------------------------+-----------+---------+-----------+---------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+---------------------------------+-----------+------+ | id | estRows | actRows | task | access object | execution info | operator info | memory | disk | +----------------------------+-----------+---------+-----------+---------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+---------------------------------+-----------+------+ | StreamAgg_16 | 1.00 | 1 | root | | time:12.609575ms, loops:2 | funcs:count(Column#7)->Column#5 | 372 Bytes | N/A | | └─TableReader_17 | 1.00 | 4 | root | | time:12.605155ms, loops:2, cop_task: {num: 4, max: 12.538245ms, min: 9.256838ms, avg: 10.895114ms, p95: 12.538245ms, max_proc_keys: 31765, p95_proc_keys: 31765, tot_proc: 48ms, rpc_num: 4, rpc_time: 43.530707ms, copr_cache_hit_ratio: 0.00} | data:StreamAgg_8 | 293 Bytes | N/A | | └─StreamAgg_8 | 1.00 | 4 | cop[tikv] | | proc max:12ms, min:12ms, p80:12ms, p95:12ms, iters:122, tasks:4 | funcs:count(1)->Column#7 | N/A | N/A | | └─TableFullScan_15 | 242020.00 | 121010 | cop[tikv] | table:t1 | proc max:12ms, min:12ms, p80:12ms, p95:12ms, iters:122, tasks:4 | keep order:false | N/A | N/A | +----------------------------+-----------+---------+-----------+---------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+---------------------------------+-----------+------+ 4 rows in set (0.01 sec) -
CLUSTER_STATEMENTS_SUMMARY テーブルの
PLAN列、また、TiDB Dashboard でも確認できる
例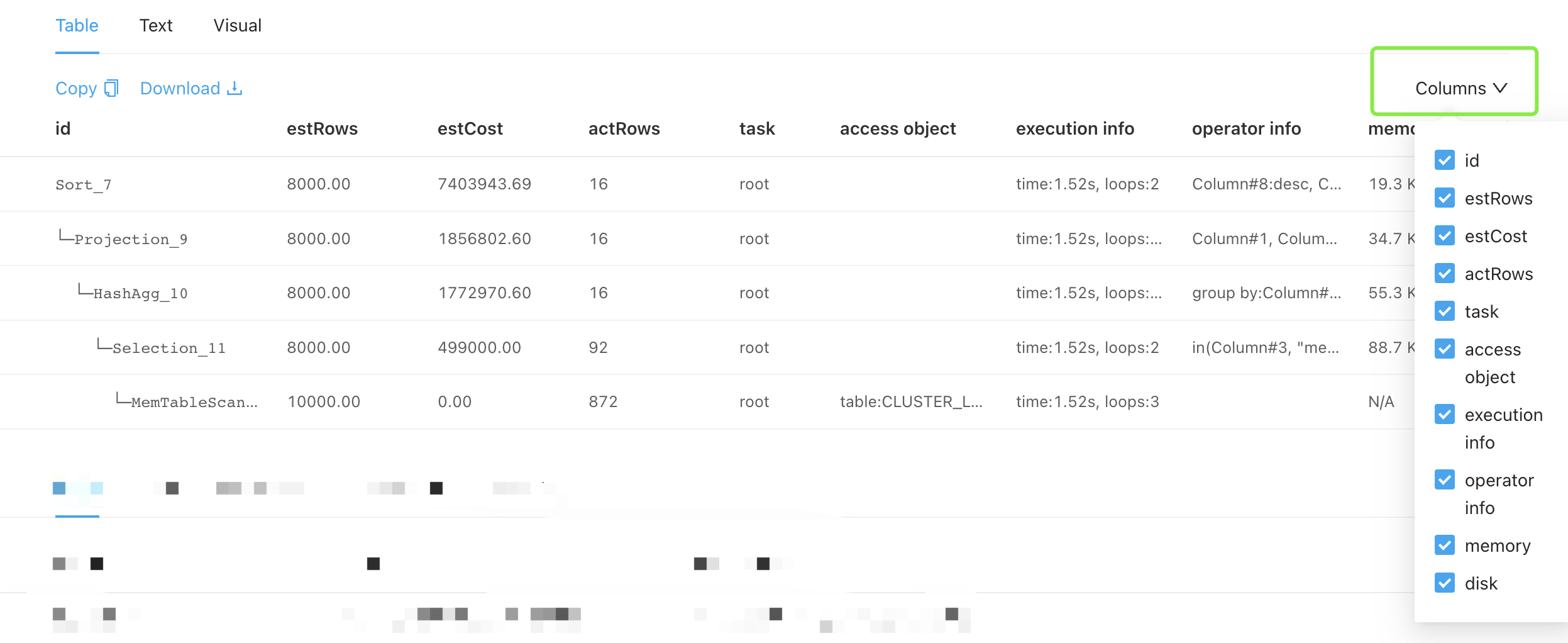
※ 実は 1つの statement が複数の Plan を持つ場合もあります。ご了承ください -
Slowlog の
Plan列、また、CLUSTER_SLOW_QUERY テーブルのPLAN列
Raw slowlog に Plan 列は1行の base64 format のデータになっていて、tidb_decode_plan('...')に囲まれるが、中身を見る時に任意の tidb にselect tidb_decode_plan('...');を実行すれば表示される
例:# Plan: tidb_decode_plan('ZJAwCTMyXzcJMAkyMAlkYXRhOlRhYmxlU2Nhbl82CjEJMTBfNgkxAR0AdAEY1Dp0LCByYW5nZTpbLWluZiwraW5mXSwga2VlcCBvcmRlcjpmYWxzZSwgc3RhdHM6cHNldWRvCg==')
実行計画の task 列は主に3種類があります。
root はが TiDB-server で実行されます。 cop[tikv] が TiKV-server で実行されます。 mpp[tiflash] が TiFlash-server で実行されます。
実行計画の id 列はツリー形になるので、わかりやすいと思います。Operator(アルゴリズムの名前)と呼ばれます。
※ Operator一覧
抜粋:
- PointGet/BatchPointGet : Primary Key でデータを取得する
- TableFullScan : (Primary Key 順に) テーブル全体のスキャン (但し Limit と組み合わせて、早めに止める場合も)
- TableRangeScan : (Primary Key 順に) 指定された範囲でテーブルをスキャンする
- IndexFullScan : (インデックス順に) テーブルデータではなくインデックスがスキャンされる点を除いて、「テーブルフルスキャン」に似ている
- IndexRangeScan : (インデックス順に) 指定された範囲でインデックスをスキャンする
- IndexLookup : よく IndexRangeScan と TableRowIDScan の親 Operator になる。インデックスデータにデータを探して、テーブルデータにこのレコードデータを取得する
- TableRowIDScan : よく IndexLookup の子 Operator になる。通常は、インデックス読み取り操作の後に、テーブルデータから RowID(Primary Key) で一致するデータ行を取得する
- Selection : 検索条件のフィルタリング処理。よく外の Operator と組み合わせる。SQL の Where 条件が PointGet/TableRangeScan/IndexRangeScan に実現できない場合、取得されたデータを eq/not/or/ge/le 等の関数で判断処理を実現して Selection Operator になる
また、データ集計(HashAgg/StreamAg) や Join (HashJoin/IndexJoin) や TopN / Limit 等の Operator も存在します。
MySQL も、TiDB の分散 DB の世界にも、アルゴリズムの効率はデータの配置方法(データの位置と順番)との関係性が強いです。
PointGet/BatchPointGet/TableRangeScan/IndexRangeScan は順番あるデータを直接に探すため性能が良いです。
TableFullScan/IndexFullScan は Limit と組み合わせてデータが足りる場合に効率はまだ良いですが、データが足りない時や TopN と組み合わせとすべてのデータを舐めてしまうので、コストが高いですね。
IndexLookup について、IndexRangeScan の部分は集中される順番データを探すため効率良いが、TableRowIDScan の部分は行データに RowID で取得するので性能が BatchPointGet と近い、データが複数 region に分散される場合 1 region 対して 1 task が生まれるため、task 多い時にコストが高いです。
※ 参照資料: Cygames さん TiDBにおけるテーブル設計と最適化の事例
コストを評価する時に、実行計画の actRow や execution info の中の task 数、また RU 数は参考になります。
クエリレビューの手段
上記の実行計画の基本知識がありましたら、ようやくクエリレビューできるようになります。TiDB にいくつのレビュー手段があります。
- TOP-SQL のレビュー
- Statements のレビュー
- Slowlog のレビュー
TOP-SQL のレビュー
TiDB Dashboard に TOP-SQL 画面が提供されています。
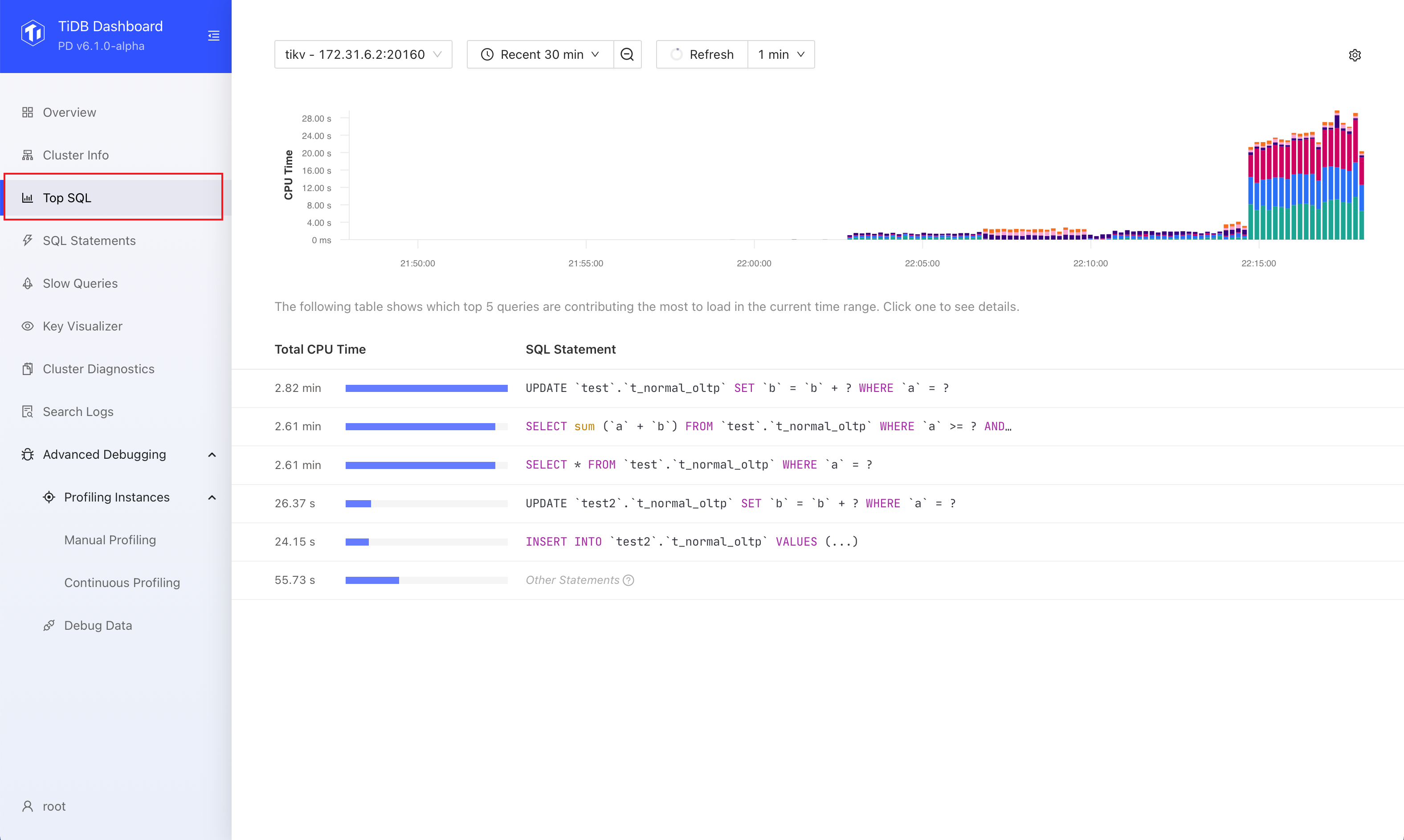
TiDB インスタンス、TiKV インスタンスを選んで、時間帯も選んたら、CPU 時間での TOP-5 の SQL が表示されます。
アプリケーションがリリースされた直後、また、DB移行後に、非効率のクエリがよく冪乗則のようにでます。その時に TOP-SQL で問題SQLを見つかるのが効率いいと思います。
Statements のレビュー
CLUSTER_STATEMENTS_SUMMARY テーブル( CLUSTER_STATEMENTS_SUMMARY_HISTORY テーブルも )、また、TiDB Dashboard の statement 画面 で statement を見ることが出来ます。
statement_smmary テーブルに plan like %FullScan% のような検索は便利です。
Dashboard の方が細かい情報を見るのが得意です。例えば、Total Latency や Execute count 逆順で検索します。
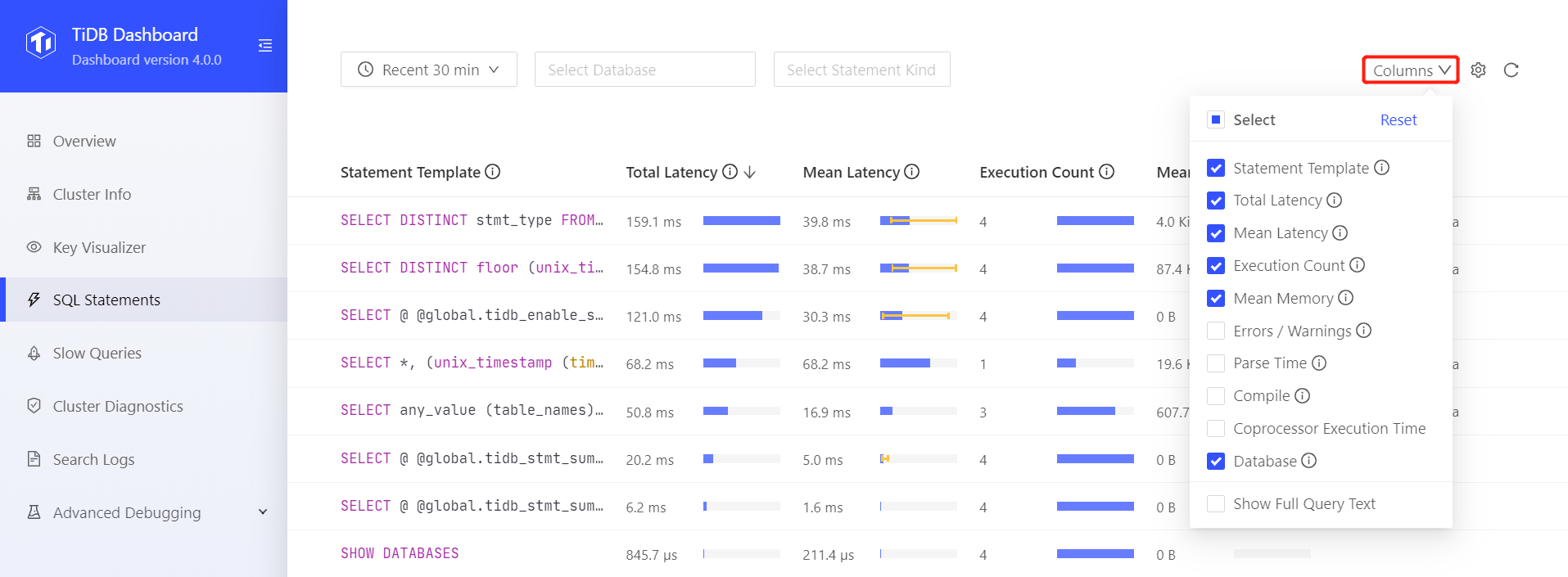
Statement の詳細画面から Plan の詳細も確認できます。また、Slow Log 画面に飛ぶことが出来ます。
※ 制限1: システム変数で色々コントロールされています。特に tidb_stmt_summary_max_stmt_count (default 3000) はメモリにサンプリングされる statement の量の設定です。短時間に statements の量がこれより多くなると、一部 statement が記録されなくなり、Statements の集合が完全ではなくなります。
※ 制限2: Statements の Plan の中の actRows や execution info の task 数等の情報は、一回実行の plan 情報になります。現実世界には Statements --1:*-- Plan の関係性ですが、TiDB statements summary の世界には Statements --1:1-- Plan の関係性になるので、ご了承ください。すべての Plan を正確に把握したい場合に、slowlog の plan を拾ってください
Slowlog レビュー
Statements レビューは抽象的な分析になりますが、Slowlog レビューはより具体的な分析になります。特に影響が大きい「悪SQL」を特定する時に、Slowlog レビューは役に立ちます。また、総合的な分析の場合、Statements の plan 情報が不十分であり、Slowlog の Plan 情報を精密に統計したりできるので、役に立ちます。後文の「高級版」にご参照ください。
クエリレビューの手段(高級版)
クエリのパタンが多い際に、slowlog を集計して、俯瞰的に総合的に分析しても良さそうです。
下記のツールで showlog ファイルを csv に転換できます。
https://github.com/dulao5/tidb-slowlog2csv
Duckdb で csv ファイルを分析できます。
処理時間の全体像
target columns: "QueryTime", "ParseTime", "CompileTime", "RewriteTime", "OptimizeTime", "WaitTS", "CopTime", "ProcessTime", "WaitTime"
各時間は Total QueryTime の割合を計算して、処理時間の構成を見ます:
CREATE TABLE slowlog AS SELECT * FROM read_csv("/pathto/slowlog.csv", max_line_size=400971520, auto_detect=true);
SELECT
round(sum(ParseTime)/sum(QueryTime)*100,2) as ParseTimePercent,
round(sum(CompileTime)/sum(QueryTime)*100,2) as CompileTimePercent,
round(sum(RewriteTime)/sum(QueryTime)*100,2) as RewriteTimePercent,
round(sum(OptimizeTime)/sum(QueryTime)*100,2) as OptimizeTimePercent,
round(sum(WaitTS)/sum(QueryTime)*100,2) as WaitTSPercent,
round(sum(CopTime)/sum(QueryTime)*100,2) as CopTimePercent,
round(sum(ProcessTime)/sum(QueryTime)*100,2) as ProcessTimePercent,
round(sum(WaitTime)/sum(QueryTime)*100,2) as WaitTimePercent
FROM slowlog;
出力例
┌──────────────────┬────────────────────┬────────────────────┬─────────────────────┬───────────────┬────────────────┬────────────────────┬─────────────────┐
│ ParseTimePercent │ CompileTimePercent │ RewriteTimePercent │ OptimizeTimePercent │ WaitTSPercent │ CopTimePercent │ ProcessTimePercent │ WaitTimePercent │
│ double │ double │ double │ double │ double │ double │ double │ double │
├──────────────────┼────────────────────┼────────────────────┼─────────────────────┼───────────────┼────────────────┼────────────────────┼─────────────────┤
│ 0.05 │ 3.19 │ 0.13 │ 3.01 │ 0.03 │ 178.95 │ 136.73 │ 0.53 │
└──────────────────┴────────────────────┴────────────────────┴─────────────────────┴───────────────┴────────────────┴────────────────────┴─────────────────┘
- ParseTimePercent と CompileTimePercent の割合が多い場合、とても長い SQL が存在するかもしれない
- WaitTSPercent の割合が多い場合、TiDB CPU や PD 側負荷が高い可能性がある
- CopTimePercent と ProcessTimePercent の割合が多い場合、
- WaitTimePercent の割合が多い場合、TiKV 側ボトルネックになる可能性がある(また、これらのSQLは根本原因ではなく影響されたSQLの可能性がある)
NumCopTasks の数の TOP-10
CREATE TABLE slowlog AS SELECT * FROM read_csv("/pathto/slowlog.csv", max_line_size=400971520, auto_detect=true, types = {'NumCopTasks': 'INTEGER', 'TotalKeys': 'INTEGER', 'ProcessKeys': 'INTEGER'});
CREATE TABLE top_slowlog_statements
AS SELECT
digest,
sql,
count(*) as cnt,
sum(NumCopTasks) as SumNumCopTasks as SumNumCopTasks,
round(avg(NumCopTasks),1) as AvgNumCopTasks,
round(sum(QueryTime), 1) as SumQueryTime,
sum(TotalKeys) as SumTotalKeys,
any_value(plan) as plan
FROM slowlog
GROUP BY digest,sql HAVING AvgNumCopTasks > 30
ORDER BY 4 DESC LIMIT 20;
COPY top_slowlog_statements TO '/pathto/top-NumCopTasks-slowlog-statements.csv' ;
例の出力 (sql[0:50] 等で調整後)
┌──────────────────────────────────────────────────────────────────┬────────────────────────────────────────────────────┬───────┬────────────────┬────────────────┬──────────────┬──────────────┐
│ Digest │ "sql"[0:50] │ cnt │ SumNumCopTasks │ AvgNumCopTasks │ SumQueryTime │ SumTotalKeys │
│ varchar │ varchar │ int64 │ int128 │ double │ double │ int128 │
├──────────────────────────────────────────────────────────────────┼────────────────────────────────────────────────────┼───────┼────────────────┼────────────────┼──────────────┼──────────────┤
│ 35b92f11b13dc572d5d5397bf536644063d8f6c0ede558faf798382ba4c0547f │ select distinct `ec_force_customers` . * from `ec_ │ 2 │ 27730 │ 13865.0 │ 47.8 │ 988746 │
│ 08335f76a15ba03709767e2618f77aa0ce2174ff6e1fc9d9e322402f7b577f93 │ select distinct `ec_force_customers` . * from `ec_ │ 2 │ 24828 │ 12414.0 │ 28.2 │ 1434312 │
│ 8e91fbdcb9f89253aeb7fe5fd2e41609a0bf24d70d65605c8bf1baa777e8850f │ select sum ( `ec_force_orders` . `total` ) from `e │ 11 │ 2962 │ 269.3 │ 6.6 │ 34085 │
│ 20d2d919921d2995b45b0b1ba075cdefc6a509cb7373787b0d20de33901ee0cf │ select count ( ? ) from `ec_force_orders` where `e │ 10 │ 2867 │ 286.7 │ 5.9 │ 32844 │
│ 1f8b2105eb3d7819d61cdb68db25150763d097f42b6a297e274f73e194b4cec0 │ select sum ( `ec_force_orders` . `total` ) from `e │ 10 │ 2867 │ 286.7 │ 5.9 │ 32844 │
│ f97df1fc9512c0e727221c3b9f3511c18c790f957f4ec51f7b88fc9d84e45e74 │ select count ( ? ) from `ec_force_orders` where `e │ 10 │ 2867 │ 286.7 │ 5.9 │ 32844 │
│ 97e7ce62aa539746ed38d066a2ba5c8371e872728b1141c554a555f2feb6bbea │ select distinct `ec_force_customers` . * from `ec_ │ 18 │ 2719 │ 151.1 │ 44.5 │ 11138195 │
│ 114af20e17219c0bc21227368294e38fc675a0d9d9b88bb3e171abc185da2079 │ select count ( ? ) from ( select distinct `ec_forc │ 18 │ 1928 │ 107.1 │ 8.6 │ 26276208 │
│ 2fb21302125e5120ffebb8657a0164a15621d25aa114d0685496e79218d3ad0f │ select distinct `ec_force_orders` . * from `ec_for │ 18 │ 1928 │ 107.1 │ 22.3 │ 26147551 │
│ f9875cdd644017a740e3c9b8f0cda23426c4351a38f8375b961e8679f9fbb6fb │ select distinct `ec_force_customers` . * from `ec_ │ 40 │ 1654 │ 41.4 │ 72.1 │ 19540455 │
│ e9a1a4a59cf679996d021b397e57351e26c605ff84ef95a8901d6985eb0c91e3 │ select count ( ? ) from `ec_force_orders` where `e │ 2 │ 892 │ 446.0 │ 2.2 │ 5070 │
│ 772d6415fa0e16826e1f05db80d0c7097200d2a91c9a58429cbe5053e25d789d │ select sum ( `ec_force_orders` . `total` ) from `e │ 2 │ 892 │ 446.0 │ 2.2 │ 5070 │
│ 5a17cde7b6dd718055b07723be290fdc59c5a6235c994b713ad438f027d9f958 │ select sum ( `ec_force_orders` . `total` ) from `e │ 2 │ 892 │ 446.0 │ 2.0 │ 5070 │
│ 3c997f1ec58ced76e527ba7b9b2ececf0aaf64307d3d05abf94225227faef248 │ select count ( ? ) from `ec_force_orders` where `e │ 2 │ 892 │ 446.0 │ 1.9 │ 5070 │
│ c5dfe81200e6ad78babbd208f028d5b47e5582bb742c28a430372b9f13ad3caf │ select count ( ? ) from ( select distinct `ec_forc │ 53 │ 742 │ 14.0 │ 22.0 │ 12703190 │
│ 38968f5241363b52636bf9fba954ded3f492d4341749d834b5231256b08c1a0a │ select distinct `ec_force_customers` . * from `ec_ │ 53 │ 742 │ 14.0 │ 88.2 │ 12703190 │
│ b737deb75fb8e425f18a22b4af6435dc7a3ca931f05e08291e40a88e062c7dfd │ select count ( distinct `ec_force_subs_orders` . ` │ 9 │ 693 │ 77.0 │ 4.3 │ 863427 │
│ ec3d88df2ee9906c8716f2a89465ad5ade1e19df38e5c2f95112232088113a55 │ select distinct `ec_force_subs_orders` . * from `e │ 8 │ 616 │ 77.0 │ 3.9 │ 904595 │
│ 42e01b7b6ab0e6a7da8a0fc47e69a368701c276f32bc2cb8acaef6598efe10fe │ select `ec_force_orders` . * from `ec_force_orders │ 105 │ 533 │ 5.1 │ 113.1 │ 23618837 │
│ 0c4f5cbc329ab4b9d7b96eb5556c101c6d7cc08a98c3ced52bd12dad2e926fc4 │ select distinct `ec_force_customers` . * from `ec_ │ 2 │ 523 │ 261.5 │ 8.3 │ 1901772 │
├──────────────────────────────────────────────────────────────────┴────────────────────────────────────────────────────┴───────┴────────────────┴────────────────┴──────────────┴──────────────┤
TotalKeys の数の TOP-10
CREATE TABLE slowlog AS SELECT * FROM read_csv("/pathto/slowlog.csv", max_line_size=400971520, auto_detect=true, types = {'NumCopTasks': 'INTEGER', 'TotalKeys': 'INTEGER', 'ProcessKeys': 'INTEGER'});
CREATE TABLE top_slowlog_statements AS SELECT digest,sql,count(*),sum(NumCopTasks),sum(QueryTime),sum(TotalKeys),any_value(plan) FROM slowlog GROUP BY digest,sql ORDER BY 6 DESC LIMIT 10;
COPY top_slowlog_statements TO '/pathto/top-TotalKeys-slowlog-statements.csv' ;
MVCC_Versions の数の TOP-10
CREATE TABLE slowlog AS SELECT * FROM read_csv("/pathto/slowlog.csv", max_line_size=400971520, auto_detect=true, types = {'NumCopTasks': 'INTEGER', 'TotalKeys': 'INTEGER', 'ProcessKeys': 'INTEGER'});
SELECT digest, sql, count(*), sum(TotalKeys-ProcessKeys) as MVCC_Versions,
round(sum(TotalKeys-ProcessKeys) / sum(TotalKeys) * 100, 2) as DupVersionPercent,
sum(TotalKeys) as Sum, sum(ProcessKeys) as Sum, sum(NumCopTasks) as Sum,
sum(QueryTime) as SumQueryTime,
any_value(plan)
FROM slowlog
GROUP BY digest,sql
HAVING DupVersionPercent > 10
ORDER BY 5 DESC LIMIT 10;
COPY top_slowlog_statements TO '/pathto/top-MVCCVersions-slowlog-statements.csv' ;
テーブルのアクセス方法の分析
下記の例は テーブルのアクセス方法を統計する方法です。
MySQL のテーブル設計文化として、auto-increment を使うのが好みですが、実は auto-increment の代理キーの使用によって、非効率のテーブル設計になる場合もあります。
例えば、ゲームにユーザーが持っているキャラクターのテーブル:
create table UserChar
(
id bigint AUTO_INCREMENT PRIMARY KEY,
user_id bigint ,
char_id int,
count int,
KEY idx_user_id(user_id)
) AUTO_ID_CACHE=1
このようなテーブルが設計された後運用する時に、user_id で IndesRangeScan また IndexLookup するクエリが圧倒的に多いはずです。Primary Key の id でデータを直接に引くのがほどんどです。前文の記述で IndexLookup がコスト高い場合もありますので、下記の定義で Primary Key で検索するのが好みです。
create table UserChar
(
user_id bigint ,
char_id int,
id bigint AUTO_INCREMENT,
count int,
PRIMARY KEY (user_id,char_id,id)
) AUTO_ID_CACHE=1
こうすると、一番多く読み込まれるクエリが TableRangeScan になるので、効率よくなります。
テーブルのクエリでテーブルの設計を最適化したいので、Slowlog レビューでこの良くないアクセスパターンを識別したいです。
TIDB での Slowlog のやり方は statements -> plan のデータを parse して、テーブルの Operator を統計し、Primary Keyでの検索(TableRangeScan/PointGet)と Index での検索(TableRowIDScan)の回数を計算します。もし Primary Key での検索回数がほどんど、Index での検索が多い場合に、このテーブルの設計を調整した方が言えます。
もちろん、この分析はアプリケーションのリリース前に負荷試験の時に実行した方が良いでしょう。
CREATE TABLE rawslowlog AS SELECT * FROM read_csv("./tidb-slow-with-results.csv", auto_detect=true, max_line_size=400971520);
CREATE TABLE slowlogs AS
select
ROW_NUMBER() OVER () AS slowlogID,
*
FROM rawslowlog;
create table plan_lines as
select
slowlogID, digest, REGEXP_SPLIT_TO_ARRAY(plan, E'\n') as lines
from slowlogs;
create table plan_line_maps as
select slowlogID, digest, unnest(map_entries(map(range(len( lines )) , lines ))) as linemap
from plan_lines ;
create table plan_split_cols as
select slowlogID, digest, linemap.key as lineNumber, REGEXP_SPLIT_TO_ARRAY(linemap.value, E'\t') AS cols
from plan_line_maps;
CREATE TABLE plancsv AS
select
plan_split_cols.slowlogID as slowlogID,
plan_split_cols.digest as digest,
format('{:011d}-{:04d}', plan_split_cols.slowlogID, lineNumber) as sortID,
regexp_replace( regexp_replace(regexp_replace(cols[2], '_\d+\s*', ''), '^\W+', ''), '\s+', '') as type,
lineNumber,
length(regexp_extract(cols[2], '^\W+')) as depth,
regexp_replace(cols[2], '^ ', '.') as planId,
cols[3] as task,
cols[4] as estRows,
regexp_replace(cols[5], '\s*$', '') as operatorInfo,
TRY_CAST(cols[6] AS INTEGER) as actRows,
TRY_CAST(cols[6] AS INTEGER) as digestExecCountXactRows,
regexp_replace(cols[7], '\s*$', '') as executionInfo,
cols[8] as memory,
cols[9] as disk,
regexp_extract_all(cols[5], 'table:(\w+)', 1)[1] as tablename,
regexp_extract_all(cols[5], 'index:([\w\(,\)]+)', 1)[1] as indexname,
TRY_CAST(regexp_extract_all(cols[7], 'loops:(\d+)', 1)[1] AS INTEGER) as loops,
TRY_CAST(regexp_extract_all(cols[7], 'cop_task:\s*\{.*num:\s*(\d+)', 1)[1] AS INTEGER) as cop_task_num,
TRY_CAST(regexp_extract_all(cols[7], 'tikv_task:\{.*tasks:\s*(\d+)', 1)[1] AS INTEGER) as tikv_task_num,
TRY_CAST(regexp_extract_all(cols[7], 'tiflash_task:\{.*tasks:\s*(\d+)', 1)[1] AS INTEGER) as tiflash_task_num,
TRY_CAST(regexp_extract_all(cols[7], 'total_process_keys:\s*(\d+)', 1)[1] AS INTEGER) as total_process_keys,
TRY_CAST(regexp_extract_all(cols[7], 'total_keys:\s*(\d+)', 1)[1] AS INTEGER) as total_keys
from plan_split_cols left join slowlogs on plan_split_cols.slowlogID = slowlogs.slowlogID
where lineNumber <> 0;
-- table full scan stats --
COPY (
select tablename, avg(actRows) as avgActRows, sum(actRows) as SumActRows
from plancsv
where type = 'TableFullScan'
and tablename <> ''
group by tablename
order by SumActRows desc
) TO '/pathto/tablefullscan.csv'
;
-- table access method stats --
CREATE TABLE table_access_methods AS
SELECT
tablename,
SUM(CASE WHEN type IN (
'Point_Get' , 'TableRangeScan', 'Batch_Point_Get',
'Point_Get(Build)', 'Batch_Point_Get(Build)', 'TableRangeScan(Build)',
'Point_Get(Probe)', 'Batch_Point_Get(Probe)', 'TableRangeScan(Probe)',
) THEN 1 ELSE 0 END) AS ViaPrimaryKeyAccessSum,
SUM(CASE WHEN type IN ('TableRowIDScan', 'TableRowIDScan(Probe)') THEN 1 ELSE 0 END) AS ViaIndexAccessSum,
SUM(CASE WHEN type IN ('TableFullScan') THEN 1 ELSE 0 END) AS ViaTableFullScanSum,
FROM plancsv
WHERE tablename <> ''
GROUP BY tablename
ORDER by ViaPrimaryKeyAccessSum , ViaIndexAccessSum DESC;
COPY table_access_methods TO '/pathto/table_access_methods.csv' ;
統計結果は下記のように /pathto/table_access_methods.csv に書かれます。

この例の結果を解読すると、TableHoge が ViaIndexAccessSum の数が圧倒的なので、テーブル設計が調整対象になりそうです。TableFoga の BiaPrimaryKeyAccessSum の数が圧倒的なので、テーブル設計が問題なさそうです。TableBar が ViaTableFullScanSum の数が多いので、Primary Keyの設計や Index の設計も失敗したようです。
まとめ
本文は TiDB のクエリレビューを紹介しました。クエリレビューは TiDB 開発プロセスにおける重要なステップであり、開発者がアプリケーションのパフォーマンスを最適化し、リスクを低減し、データベースリソースの効率的な使用を確保するための重要な手段です。ご参照ください。