こんにちは!
react native のアドベントカレンダー22日目の記事になります。
BeatFit で CTO をしております、飯塚と申します。
弊社のプロダクトでは、状態管理ライブラリーに、Redux、middleware に Redux-Observable、store と component の間に、selector 層を入れております。
このアーキテクチャーでなんの疑念も抱くことなく2年ほど開発してまいりましたが、selector 層が導入されていない別プロジェクトに携わる機会があり、この層の存在価値を1から再勉強しようと思った次第であります。
また、React を使っていると、所々にメモ化の概念が出ることがあり、そもそもメモ化ってなんだっけ?という基礎的な部分からおさらいできればと思います。
では、よろしくお願いします!
人間の脳の限界、忘却曲線について
我々の脳で処理できることは限られています。
ドイツのエビングハウスが130年以上前に発表した忘却曲線や、この実験データを使い再検証したカナダのウォータールー大学の20年以上前の実験によると、人は一度インプットして記憶した内容を、そのまま何もしなければ、1週間後には約7割忘れてしまうといわれております。
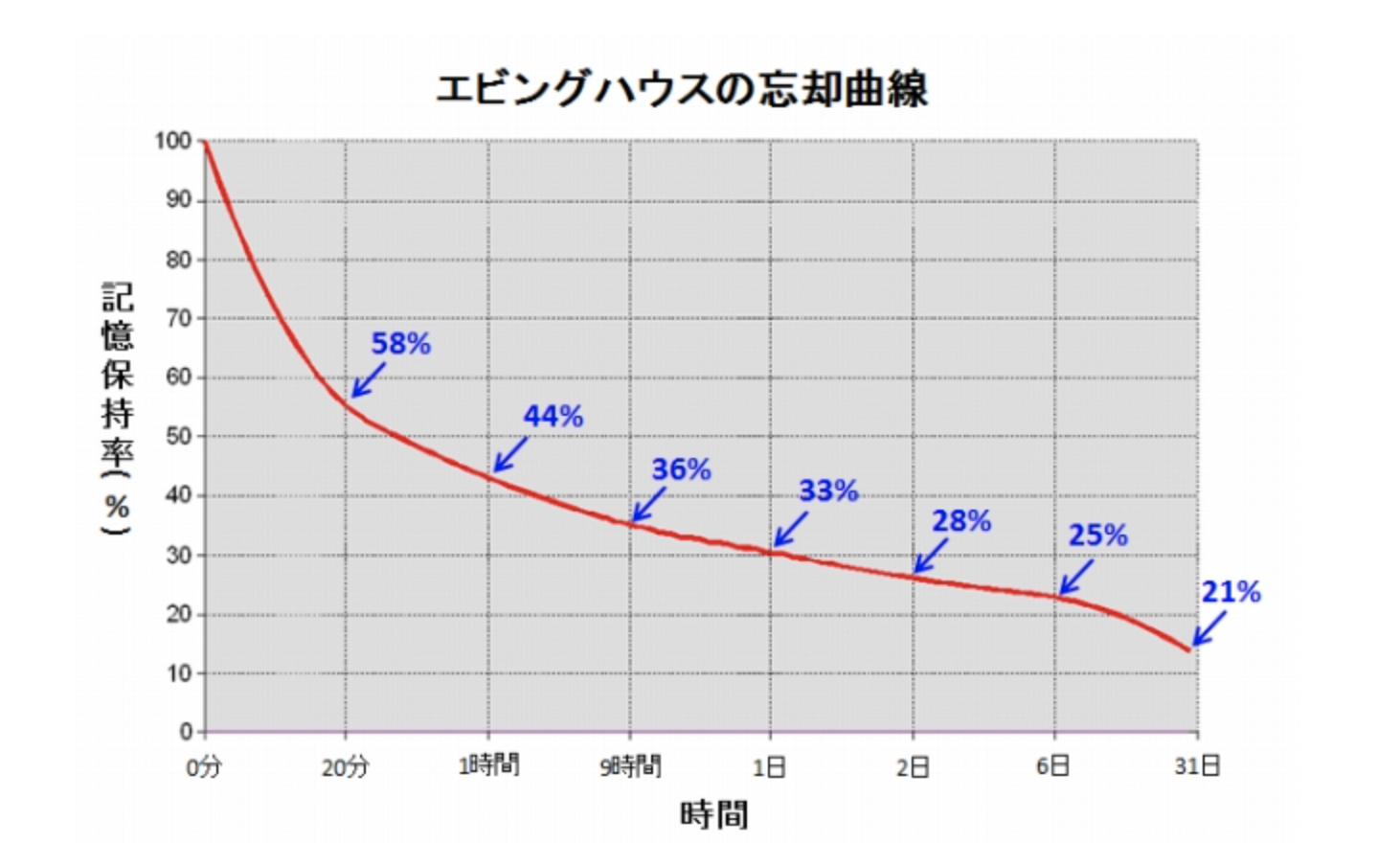
どうやら人間の脳では、一時記憶に頼ってるだけでは、記憶を保持することが難しいようです。
医療分野における学習方法
医療にも同じことが言えます。
医学は日進月歩で発展するため、その膨大な医療知識を網羅的に暗記し、全ての知識を update し続けることはできません。ですが、患者さんに最適な医療を提供するためには、医療者は勉強した最新の知見を、提供し続けなければいけません。
忙しい外来業務や救急外来では、秒単位で時間との勝負になるため、最適な治療にいかに最速でたどり着けるか?が重要になります。
この無理難題に、限界がある人間の脳でどう立ち向かうのでしょうか?
また、どのような方法で、日々発展し続ける膨大な知識をupdateしていくのでしょうか?
結論から申しますと、これは、二次記憶をうまく使うことによって、可能となります。
つまり、全ての情報を一時記憶のまま暗記するのではなく、二次記憶を利用して暗記しない状態で情報を利用することを目指します。
具体的には、白衣の中に電子機器を忍ばせ、最新の情報が載っている論文(PubMed など)や、文献(upToDate など)や、医学書や、ツール(EverNote やNotion など)などを用意し、いつでもどこでも最速でアクセスできるように準備します。これで、いざ医療現場で困った時に、その場で迅速に調べることによって、欲しい情報をリアルタイムで取得することが可能になります。
IT における学習方法
おそらく、IT の勉強にも同じことが言えます。
優れたハッカーとは?に関する、以下の記事を抜粋します。
ハッカーと認められるには、素早く問題を片付けることができないといけないんだ。それでは素早く問題を解決できるようになるためにするべきことはなんだろう。
問題を解くために必要となる知識・情報をすばやく探しだせるようにすることだ。最も速いのは一次記憶、すなわち自分の記憶している知識だ。しかし人間の記憶力には限度があるから、二次記憶を有効に利用することも大事だ。
この場合の二次記憶とは検索エンジンで検索することだったり、書籍だったり、友人だったりする。一次記憶・二次記憶を有効につかって雑多な知識やネタを蓄え、それを必要な時にすぐに思いだして応用できるようにすることが重要だ。
これはもちろんすぐにできるようになるわけじゃない。どんな優れたハッカーだって地道に経験をつんできているはずだ。優秀なハッカーは問題に出会ってから解決方法を探すというよりも、むしろ普段からなにかしらシステムやツールの使い方を探求している。普段からいろいろな使い方を試して、利用法をマスターしたり、あまり使いこなしていないとひっかかりそうな罠なんかを学習していっている。そのようにツールに慣れていれば、処理すべき問題がでてきた時に一々使い方から調べたりする必要はないわけで、それだけで経験がない人と比べるとかなりリードできているわけだ。
ここまでのまとめ
人は学習する時に、何の工夫もせず、そのまま一時記憶として暗記すると、1週間後に7割、1ヶ月後に8割忘れてしまいます。次に同じ困ったことを調べる時に、また1から勉強しなければならず、大変効率が悪くなってしまいます。
しかし、もし二次記憶が利用できる状況 (Notion や EverNote など)を作り、そこに適切な index を貼れば、その知識を得るのに O(1) で迅速にアクセスができます。
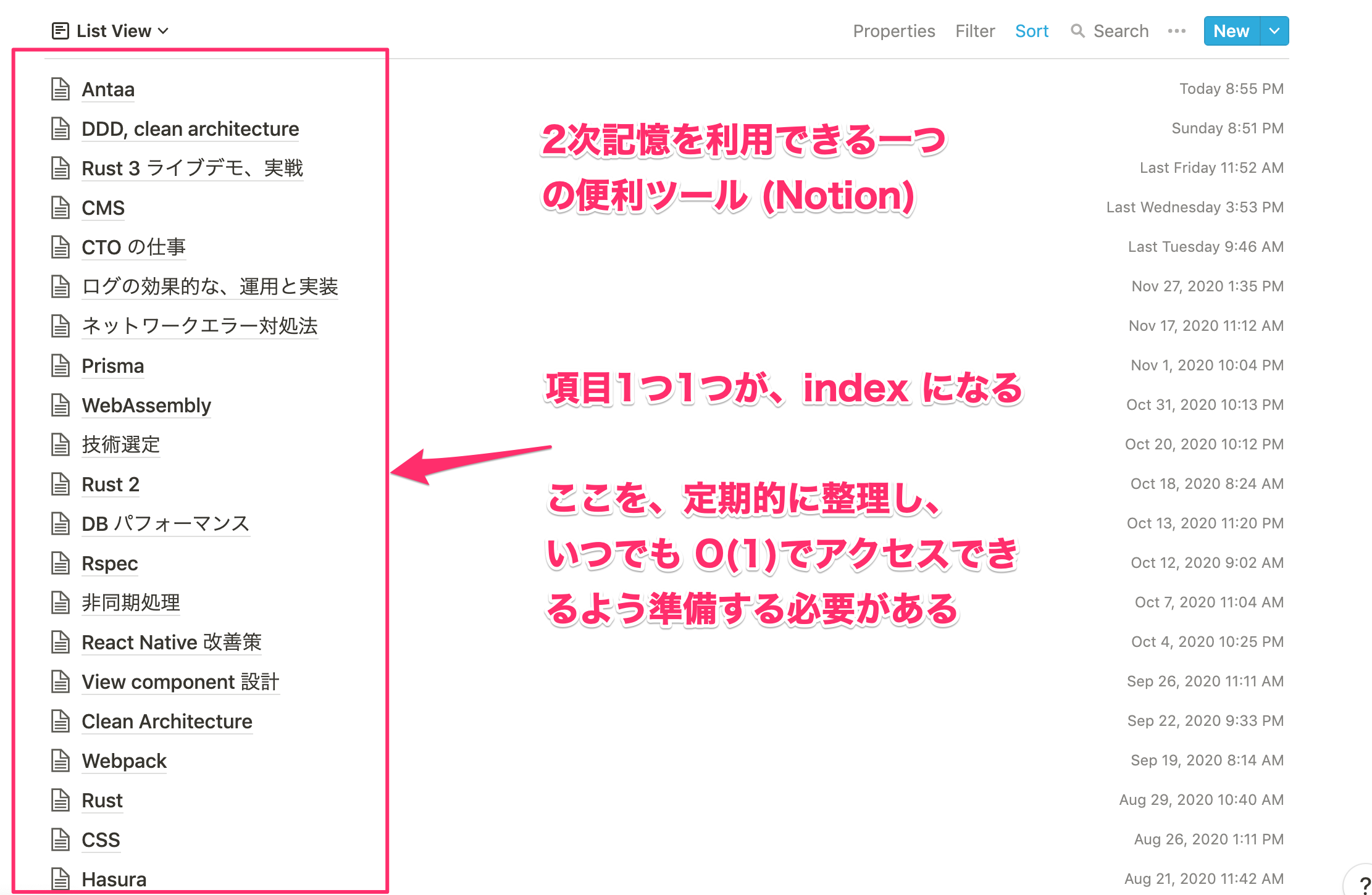
この引き出しを整理していくことが、とても重要になってきますね!
メモ化の威力をコードで体験する。
さて、察しが良い方は気づかれたかと思いますが、ここまでのお話がメモ化になります。
今度は、メモ化を具体例ではなく、fibonacci 数列のプログラムで説明したいと思います。
fibonacci 数列は、下記を満たします。
F(0) = 0, F(1) = 1
F(N) = F(N - 1) + F(N - 2), for N > 1.
これを、何の工夫もなくコードでかくと、こんな感じになります。
const fib = n => {
if(n <= 1){
return n
}
return fib(n -1) + fib(n-2)
}
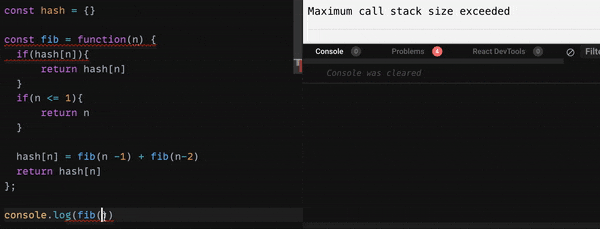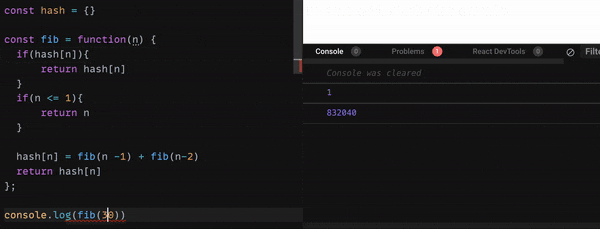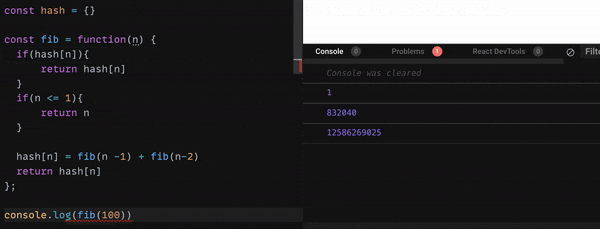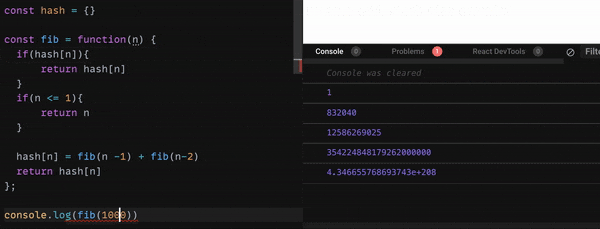
しかし、このコードは効率が良くありません。
なぜなら、n = 10 だった時に、fib(9) + fib(8) を、fib(9) は fib(8) + fib(7)を・・・
というように、二重で計算をしているからです。
つまり、一度勉強をしたことを全て忘れ、1から勉強し直しているのと同じです。
大変効率が悪いわけです。
下のGif 画像をご覧ください。
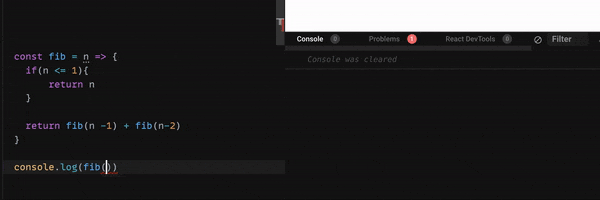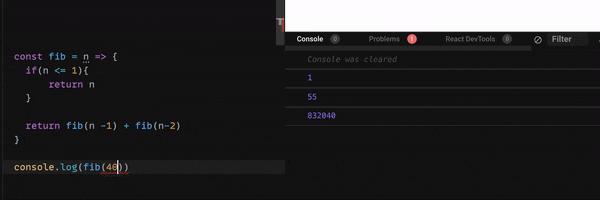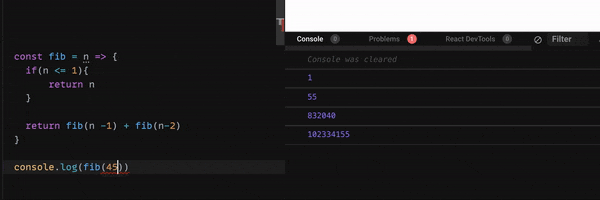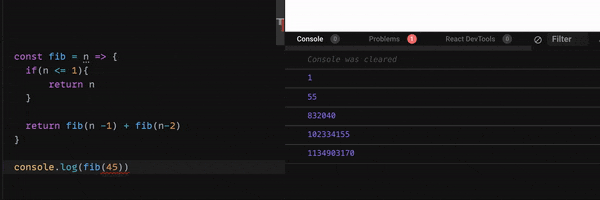
nが40 を超えると、console に表示されるまでのスピードが、とても遅くなりますね。
ではこのコードを、メモ化を使って、効率化してみましょう。
const memo = {} // 実生活だと、Notion や EverNote など
const fib = function(n) {
if(memo[n]){
return memo[n] // もし、見出し(index) があれば、その中身を返す
}
if(n <= 1){
return n
}
memo[n] = fib(n -1) + fib(n-2)
return memo[n]
};
memo の見出しが既にあった場合、それに対応する中身を返すという条件を追加しました。
これは、Notionの見出し(index)をクリックし、中の記事を読むのと同じことですね。
実際これで、どれくらい早くなるのか?
こちらのGif 画像をご覧ください。
かなり高速化しましたね。
値に1000を入れても、一瞬で値を返せています。
このようにメモ化とは、実生活の話だけでなく、プログラムを書く上でもとても重要になってきます。
selector はなぜ必要なのか?
ここから、React の話になります。
最近になり、状態管理をするにあたり、hooks やApollo cache、Recoil などの選択肢が増えてきました。しかしながら、いまだに私達のように、状態管理ライブラリである Redux を使っている企業も多いことでしょう。
store に保存しているstateを、React Component に渡すには、react-redux から提供されるconnect関数を使います。
connect(mapStateToProps, mapDispatchToProps) と書くことで、Reduxの Storeに格納されたstateを、React Componentに props として渡します。
const DisplayBelts = ({ belts } : Props) => {
return (
<>
{belts.map(belt => <Image source={belt.imgUrl} />}
</>
)
}cあ
}
const mapStateToProps = state => {
return {
belts: state.items.belts
}
}
export default connect(mapStateToProps)(DisplayBelts)
とても、simple にかけますね!
しかしながら、このコードには、いくつか問題があります。
問題1.
問題の1つは、React Component 自身が、Storeの知識を知る必要があるということです。
これは、ちょっとわかりづらいので、具体例で考えてみましょう。
あなたは、React Componentです。
スボンの紐が突然きれ、ゆるゆるになってしまいました。
緊急事態です!!!
あなたは、ベルトを買いに、大きなストア(コストコとか)へ行くことにしました。
しかしながら、あなたはベルトがどこで売っているのか知りません。
広いストアの中を探さなければなりません。
あなたはシャイのため、店の中で誰にも話しかけることができず、一人黙々とベルトの場所を見つけるために歩き回らなければなりません。
ベルトがどこにあるか?
という情報を、React Component であるあなたが知らなければ、ベルトを買うことができない状況です。
問題2.
2つめとして、コードの保守性が低下するという問題があります。
このbelts のstate は、10箇所のReact Component で使用されていたとします。
(= mapStateToProps への下手書きが、10箇所で行われているとします。)
もし、仕様変更により ベルト情報が
state.items.belts → state.items.shops.belts
に変わったとしたら、どうなるでしょうか?
そうです、10箇所のファイルで、mapStateToProps 内のコードを修正する必要になりますね。
問題3.
3つめとして、パフォーマンスが低下する問題があります。
こちらのコードをご覧ください。
const DisplayBelts = ({ belts, dispatch } : Props) => {
const onPress = () => dispatch(changeBelts())
return (
<View>
<TouchableOpacity onPress={onPress}>
<Text>Press me</Text>
</TouchableOpacity>
{belts.map(belt => <Image source={belt.imgUrl} />}
</View>
)
}
const mapStateToProps = state => {
return {
belts: state.items.belts.filter().reduce()... // some heavy calculation!
}
}
export default connect(mapStateToProps)(DisplayBelts)
Press me をクリック すると、ベルト情報を更新する actionが dispatch されるコードを加えました。
このアクションにより store が更新されると、毎回 mapStateToProps が呼び出されます。
mapStateToProps が呼び出されると、毎回 React Component が rerender される、のではなく、ある特定の条件を満たすと、rerender が起きます。

そのある条件というのが、shallowEqual となります。
shallowEqual とは何か?の前に、Javascript における比較を簡単にご説明致します。
const a = 1
const b = 1
console.log(a === b) // true
=== は、二つの値が等しいかを見る、厳格な等価性チェック になります。数字や文字列、true/false などのプリミティブな値はこのチェックが当てはまり、この結果は直感的で、特に迷うことはないと思います。
一方で、こちらをご覧ください。
const objA = { a : 1 }
const objB = { a : 1 }
console.log(objA === objB) // false
const arrayA = [1,2,3]
const arrayB = [1,2,3]
console.log(arrayA === arrayB) // false
配列やオブジェクトを比較するときは、メモリアドレスを比較します。
つまり、key, value や、配列の中身が全く同じでも、上記二つは、それぞれ異なるメモリ上に展開されるため、異なるもの( !== )と認識されます。なぜこういう挙動なのか?は、以下の記事に大変わかりやすく書いてありました。
Arrayオブジェクトに代表されるオブジェクト型は、小さくまとまっているプリミティブ型とは異なり大きな構造を持ちます。例えばArrayオブジェクトで言えば、複数の値を持てる、多数のメソッドが存在する、多数のプロパティが存在する、などです。そういった大きな構造を持つ値を毎回コピーしていると、どうしても処理に時間がかかり、遅くなってしまいます。しかし参照の値を受け渡しするのならば、簡単な値のコピーだけで済むので、短時間で処理を終わらせることができます。つまり、この方式の方が、無駄が少ないのです。
また、reducer でstateを変えるときには、immutable を意識しなければなりません。
// mutable な更新 (メモリアドレスは同じ)
const stateA = { name : "Bob", age: 31}
stateA.age = 35
const stateB = [1,2,3,4,5]
stateB.push(6)
// immutable な更新
const stateC = { name : "Bob", age: 31}
const newStateC = {...stateC, age: 35}
const stateD = [1,2,3,4,5]
const newStateD = [...stateD, 6]
state のオブジェクトを直接 mutableに変更しても、参照するメモリアドレスは同じになってしまうため、Redux が stateの更新を検知できず、思わぬエラーの原因になりえます。具体的にはこちらの記事 や、こちらの日本語記事をご参照ください。
stateを更新する際は、必ずスプレッド演算子などを使い、オブジェクトをコピーして新たなメモリアドレスを作る immutable な更新をしましょう。これで、Redux(や React)が、prevStateから新しいstate への更新を検知できます。
shallowEqual
このように、オブジェクトは、たとえkey、valueが全く同じだったとしても、異なるものと認識されます。
しかし、時としてこれは有害事象(rerenderなど)の原因となり、オブジェクトの中身が同じだったら、厳格な等価性チェック(===) のように、同じオブジェクトとして扱いたい・・・!時があります。shallowEqual は、この欲求をかなえるための比較となります。
具体的には、以下のようなコードとなります。
const shallowCompare = (newObj, prevObj) =>{
for (key in newObj){
if(newObj[key] !== prevObj[key]) return true;
}
return false;
}
オブジェクトのプロパティ同士を、=== でそれぞれ比較し、全て同じ値なら true を返します。
first level の階層を比較しているため、shallow equal と呼ばれます。これで
const objA = { a : 1 }
const objB = { a : 1 }
console.log(shallowCompare(objA === objB)) // true
となるわけです。
const A = { a: { b : 2 }}
const B = { a: { b : 3 }}
こういう深い階層の比較はできない点にご注意ください。
mapStateToProps による React Component のRerender
だいぶ脱線したので、戻ります。
mapStateToProps には、shallowEqual で前回のpropsと、今回のPropsを比較する機能を持ちます。
Strict Equality (===) versus Shallow Equality Checks in React-Redux
How does shallow compare work in react
shallow-equal for Object/React props
こちらのコードをご覧ください。
import {connect} from 'react-redux';
const mapStateToProps = state => (
{keyA: state.reducerA.keyA, keyB: state.reducerB.keyB}
);
export default connect(mapStateToProps)(MyComponent);
このmapStateToProps は、オブジェクトを返します。
ここでもし、厳格な等価性チェック(===) をしてしまうと、たとえオブジェクトの中身が前回と同じだったとしても、異なるものと認識されます。つまり、毎回新しいProps と認識され、store が更新するたびに、React Component のrerender を促してしまいます。しかし、mapToStateProps で返されるオブジェクトは shallowEqual の比較をされるため、オブジェクトの中身が同じであれば同じものと認識し、余計なrerender を防いでいるわけですね。
冒頭の例に戻ります。
Reduxの storeが更新されると、mapStateToProps が呼び出されますが、このmapStateToProps 内で重い計算をしていると、store が更新される毎に重い計算をしなければならず、パフォーマンスが低下してしまいます。
const mapStateToProps = state => {
return {
belts: state.items.belts.filter().reduce()... // some heavy calculation!
}
}
これまで、mapStateToProps は、shallowEqual で、返却されるオブジェクトの等価性チェックをしていると述べました。しかし、store が更新されるたびに、このheavy な計算を毎回する手間を、省くことはできません。mapStateToPropsがオブジェクトを返却するためには、計算をしなければいけないからです。つまり
store 更新 → heavy な計算
→ mapStateToProps で返されるオブジェクトの、shallow Equal チェック
この間の、heavyな計算をするというステップを、どうしても、省くことができません。
どうしたら良いのでしょうか・・・?
解決策
上記1の問題は、React Component が、store の知識を持たないように設計すれば解決します。
(storeの情報を、誰かが、React Component に教えてくれるようにすれば、解決します。)
先ほどの例で言えば、デパートにベルトを買いに行った時、あなた自身でベルトの場所を探すのではなく、店員さん がベルトの場所を教えてくれれば良いわけですね。
この店員さんの機能が、selector の役割になります。
const getBelts = (state) => state.items.belts
このgetBelts という純粋関数を、React Component に渡すことで、store の情報を隠すことができます。
export const getBelts = (state) => state.items.belts;
import { connect } from 'react-redux'
import { getBelts } from './selector'
const DisplayBelts = ({ belts } : Props) => {
return (
<>
{belts.map(belt => <Image source={belt.imgUrl} />}
</>
)
}
}
const mapStateToProps = state => {
return {
belts: getBelts(state)
}
}
export default connect(mapStateToProps)(DisplayBelts)
また、このgetBelts関数を他のReact Component でも再利用することによって、問題2が解決されます。つまり、ベルトの場所が変わったとしても、このgetBelts関数だけを修正すれば良いわけですね。
これは、ラッパー関数と同じです。
やめたろうさんの記事がわかりやすいのですが、third party library をそのまま至る所で呼び出すのではなく、ラッパー関数を作り、そのラッパー関数を他の場所から importして使用することによって、もし今後 library のAPI が変わったとしても、修正する場所がその関数内の一箇所で済みます。コードの保守性が向上するというわけですね。
参考記事: Understanding Javascript Selectors With and Without Reselect
このようにして、問題1,2 はselector を導入することで解決されましたが、問題3のパフォーマンス問題はまだ解決されておりません。
これを解決するには、mapStatToProps 内のselector 関数の重い計算を、関数内の引数が前回と同じ値なら計算をスキップし、メモリ上から前回の計算結果をO(1) でキャッシュとして取得して返すことができれば、解決しそうです。
この役割を、reselectというライブラリが担います。
reselect について
小さなアプリでは、上記のように、selector層を作り、そこに書かれた純粋関数をReact Component に渡すだけで事足ります。
しかしアプリが大きくなるにつれ、store は複雑化し(後述の store の正規化が重要になります)、reducer やselector 内のロジックも、複雑化します。
そうなって初めてパフォーマンス問題が出てきますが、Redux 公式ドキュメントでは、この問題に対し、reselectの使用を強く推奨しております。
reselect の createSelector は、最後の引数に、resultFunction、それ以外の引数に、inputSelectors を取得します。
createSelector(...inputSelectors | [inputSelectors], resultFunc)
inputSelectors で、state tree の中から、本当に関心のあるstate だけをpick up します。
これにより、無関係なstate tree の更新によって計算処理が何度も実行されることを防ぎます。
この inputSelectors はただのselector ですが、一方で、resultFunction は、メモ化された selector になります。つまり、もしinputSelectors が返す値が前回と同じだった場合は、resultFunction を呼ぶことなく、キャッシュした前回の値を返します。これで、 store 更新 → mapStateToProps の呼び出し → 前回の値を返す(heavy な再計算をスキップ)という流れで、パフォーマンス低下を防いでくれます。
具体的なコードは、以下のようになります。
const beltSelector = state => state.items.belts
export const mapStateToPropSelector = createSelector(
beltSelector,
(belt) => belt.filter().reduce()... // some heavy calculation here!
)
import { mapStateToPropSelector } from './selector'
const mapStateToProps = state => {
return {
belts: mapStateToPropSelector(state)
}
}
これで、store の更新に伴いmapStateToProps が呼び出されても、毎回heavyな計算をすることなく、createSelector の第一引数の結果が不変であれば、キャッシュされた前回の値が返されるようになりました。
reselct は、どうやってこの機能を実装しているのか?
ソースコードを一部改変して抜粋します。
function equalityCheck(a, b) {
return a === b
}
function areArgumentsShallowlyEqual(equalityCheck, prev, next) {
if (!prev || !next|| prev.length !== next.length) {
return false
}
for (let i = 0; i < prev.length; i++) {
// ここで、前回の値と、今回の値を shallow Equal で比較している
if (!equalityCheck(prev[i], next[i])) {
return false
}
}
return true
}
このように、inputSelectors の戻り値 に更新があったかどうかを prev[i] === next[i]と、shallowEqualで比較します。
function memoize(func) {
let lastArgs = null
let lastResult = null
return function(...currentArgs) {
if (!areArgumentsShallowlyEqual(defaultEqualityCheck, lastArgs, currentArgs)) {
lastResult = func(...currentArgs) // もし、現在の引数(currrentArgs) が前回と異なる場合、original function(func) を呼ぶ
}
lastArgs = currentArgs
return lastResult
}
}
この関数は、引数に関数をとり、別の関数を返す、いわゆる 高階関数(High Order Function)になります。
クロージャーを使うことで、関数を次に実行した時、前回の引数と結果を参照できます。
もし前回の引数と今回の引数に変更がなかった場合は resultFunc を再実行せず、キャッシュしておいた前回の結果 (lastResult)を返します。
これにより、resultFunction の再計算を防ぐことができるわけです。
このmemoize 関数を、createSelector の内部で使用します。
function createSelector(...selectors) {
const resultFn = memoize(selectors.pop()) //createSelectors の引数の最後が、resultFunction
return memoize((...args) => {
const resultFnParams = selectors.map(selector => selector(...args))
return resultFn(...resultFnPatams)
})
}
createSelector の引数の最後尾をresultFunctionにし、それ以外のinputSelectors にargs(state)を、それぞれmap の中で渡します。
その結果を、resultFunctionの引数に展開して渡し、もしこの引数が前回とshallow Equal だった場合、計算をスキップします。
Reselect source code — seeing closure and memoization in practice
Examining the Benefits of Reselect.js by Recreating It
このように、重い計算処理を引数の最後尾に位置する resultFunctionに書くことで、もしinputSelectors の結果がクロージャーを使って参照される前回の引数とshallowEqualだった場合、resultFunctionを再実行することなく、前回の計算結果をキャッシュとして返すことができます。
これで晴れて、問題3が解決されるわけです。
reselect + deepEqual
一方で、reselect は shallowEqualなため、deepEqual をするときは、lodash の isEqualを使い、以下のようなコードを書きます。
import { createSelectorCreator, defaultMemoize } from 'reselect'
import isEqual from 'lodash.isequal'
const todosSelector = state => state.todos
// create a "selector creator" that uses lodash.isequal instead of ===
const createDeepEqualSelector = createSelectorCreator(
defaultMemoize,
isEqual
)
const mySelector = createDeepEqualSelector(
todosSelector,
(todos) => {
...
}
)
ただし、
Always check that the cost of an alternative equalityCheck function or deep equality check in the state update function is not greater than the cost of recomputing every time.
と公式ドキュメントに書いてあるように、再計算する処理と、このdeepEqual の比較をする処理のどちらが負荷が高いかを意識して、この処理を使うか判断すべしとのことです。わざわざ deepEqual しなくて済むためにには、予め storeには正規化されたデータを格納することが重要ですね。
useSelector について
useSelector は、react-redux から提供されるAPI です。
const result = useSelector(selector: Function, equalityFn?: Function)
詳細については省略しますが、既出の mapStateToProps との違いは、以下の通りになります。
・useSelector は、default で、厳格な等価性チェック(===) を使う。
・useSelector は、オブジェクトだけではなく、値も返す。
mapStateToProps はオブジェクトを返し、前回との値と shallowEqual で比較をすると述べました。しかしながら、useSelector は、=== によるチェックを行うため、もし useSelectorがオブジェクトを返す場合、毎回新しいオブジェクトを返すと認識され、rerender が起きてしまいます。
故に複数の値を返すには、複数の useSelector()を細かくよび、プリミティブな valueを毎回返す必要があります。
const counter = useSelector(state => state.counter)
const belt = useSelector(state => state.items.belts[props.id])
const todo = useSelector(state => state.todos[props.id])
...
別のやり方として、react-redux から提供される、shallowEqual を使うことができます。もし前回の値と shallowEqual なら、rerenderすることなくオブジェクトを返すことができます。
import { shallowEqual, useSelector } from 'react-redux'
const selectedData = useSelector(selectorReturningObject, shallowEqual)
これで、useSelector() はオブジェクトを返しますが、もしオブジェクトのプロパティが前回と同じなら、rerender はおきません。
また、reselect と同じように、lodash のisEqual を使い、deepEqual にすることもできます。
しかしやはり、rerendering とdeep compare のコストの比較や、正規化で防げないかなどの判断が必要で、deepEqual の使用には慎重さが必要となります。
また、useSelctor() のなかで、reselect によってメモ化されたselector を使用することができます。
import React from 'react'
import { useSelector } from 'react-redux'
import { createSelector } from 'reselect'
const selectNumOfDoneTodos = createSelector(
state => state.todos,
todos => todos.filter(todo => todo.isDone).length
)
export const DoneTodosCounter = () => {
const NumOfDoneTodos = useSelector(selectNumOfDoneTodos)
return <div>{NumOfDoneTodos}</div>
}
useSelector に渡す selector が、重い計算をしていた場合は、積極的にreselect を使っていきたいですね。
おまけ: 正規化について
これまで、selector層の導入や reselectを使うことによって、アプリの保守性をあげたり、パフォーマンスを上げたりできると書いてきましたが、それ以外にも、アプリのパフォーマンスを上げる方法はたくさんあります。
その中でも、これまで何度も話に出てきた正規化について、簡単にお話ししたいと思います。
公式ドキュメント では、redux store をリレーショナルデータベースのように扱い、store に格納されるデータは、正規化されることが望ましいと言われております。
つまり、store に保存する形を、配列ではなく、key value のオブジェクトの形で保存すれば、アクセスを 迅速にすることができます。
この部分は、ちょっとわかりにくいので、具体例で考えてみましょう。
const blogPosts = [
{
id: 'post1',
author: { username: 'user1', name: 'User 1' },
body: '......',
comments: [
{
id: 'comment1',
author: { username: 'user2', name: 'User 2' },
comment: '.....'
},
{
id: 'comment2',
author: { username: 'user3', name: 'User 3' },
comment: '.....'
}
]
},
{
id: 'post2',
author: { username: 'user2', name: 'User 2' },
body: '......',
comments: [
{
id: 'comment3',
author: { username: 'user3', name: 'User 3' },
comment: '.....'
},
{
id: 'comment4',
author: { username: 'user1', name: 'User 1' },
comment: '.....'
},
{
id: 'comment5',
author: { username: 'user3', name: 'User 3' },
comment: '.....'
}
]
}
// and repeat many times
]
公式ドキュメントの例から抜粋します。上記blogPosts のような形は、APIから返ってくるデータとしてよく見かける形だと思います。
このblogPosts をこのままStore に保存すると、どういう問題が起きてしまうでしょうか?
問題1. Read の問題
post2 の author{ username: 'user2', name: 'User 2' }を取得したい時、以下のコードを書くことになります。
blogPosts.filter(post => post.id === 'post2')[0].author
まだこのネストはそこまで深くないためこの程度の O(n)ロジックですみますが、よりnest が深くなると、filterや map, reduceなどを method chain のようにつなげるロジックが必要となります。また、blogPosts が数万件以上の場合、readするのに非常に大きな負荷がかかってしまいます。
問題2. Update の問題
上記のblogPosts をご注目ください。
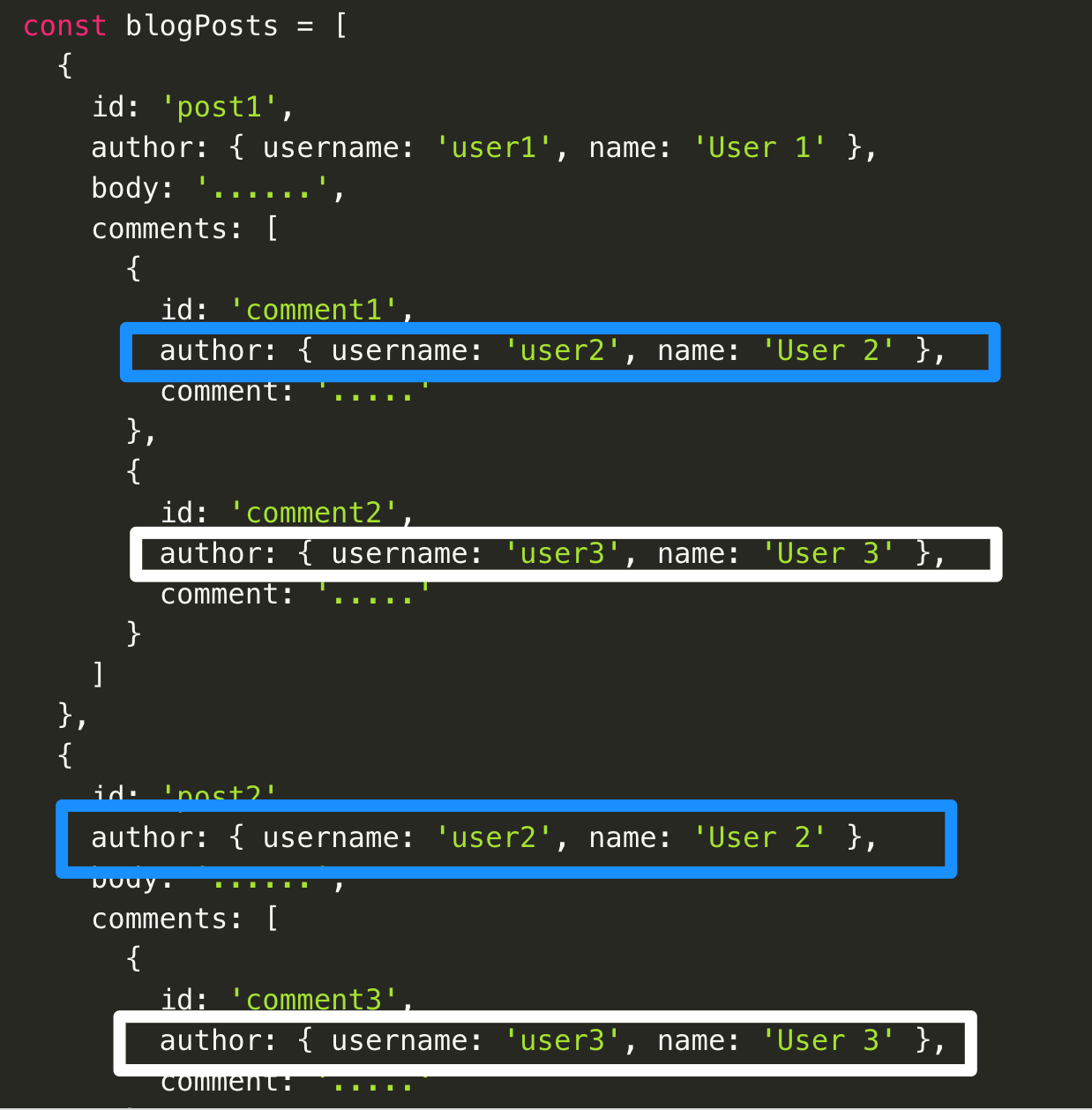
データが重複していることがわかります。
もし、白枠の author のusername を、user3 → user33 に更新するとどうなるでしょうか?
id がpost1 のオブジェクトと、id が post2のオブジェクトの両方を更新しなければならず、非常に無駄ですね。
またこの不必要な state treeの更新は、mapStateToProps を通じて React Component に不必要な
rerender を促します。ネストが深くなればなるほど、二重三重と重複するデータが生まれやすい構造となり、更新に伴うパフォーマンス低下の影響は大きくなっていきます。
解決策
故に、ここで、リレーショナルデータベースで行っている、正規化を行います。
すると、先ほどのblogPosts は以下のようになります。
const blogPosts = {
posts : {
byId : {
"post1" : {
id : "post1",
author : "user1",
body : "......",
comments : ["comment1", "comment2"]
},
"post2" : {
id : "post2",
author : "user2",
body : "......",
comments : ["comment3"]
}
},
},
comments : {
byId : {
"comment1" : {
id : "comment1",
author : "user2",
comment : ".....",
},
"comment2" : {
id : "comment2",
author : "user3",
comment : ".....",
},
"comment3" : {
id : "comment3",
author : "user3",
comment : ".....",
}
},
users : {
byId : {
"user1" : {
username : "user1",
name : "User 1",
},
"user2" : {
username : "user2",
name : "User 2",
},
"user3" : {
username : "user3",
name : "User 3",
}
},
}
}
一つのセルには一つの値を入れる(配列の形での格納はやめ、スカラ値を入れる)ように、適切なテーブル分割を行い、第一正規系を満たすことを意識してみましょう。複数の値を含む配列の形でstoreに無造作に格納するのではなく、オブジェクトの形式でデータを格納し、ドメイン毎に適切に情報を分割します。すると、主キーが決まれば値が必ず一意になるというDBの性質を得ることができます。(y = f(x) のように、x を決めたら、yが必ず1つに決まるという、関数従属性を満たすことができます。)
つまり、こういう感じになります。
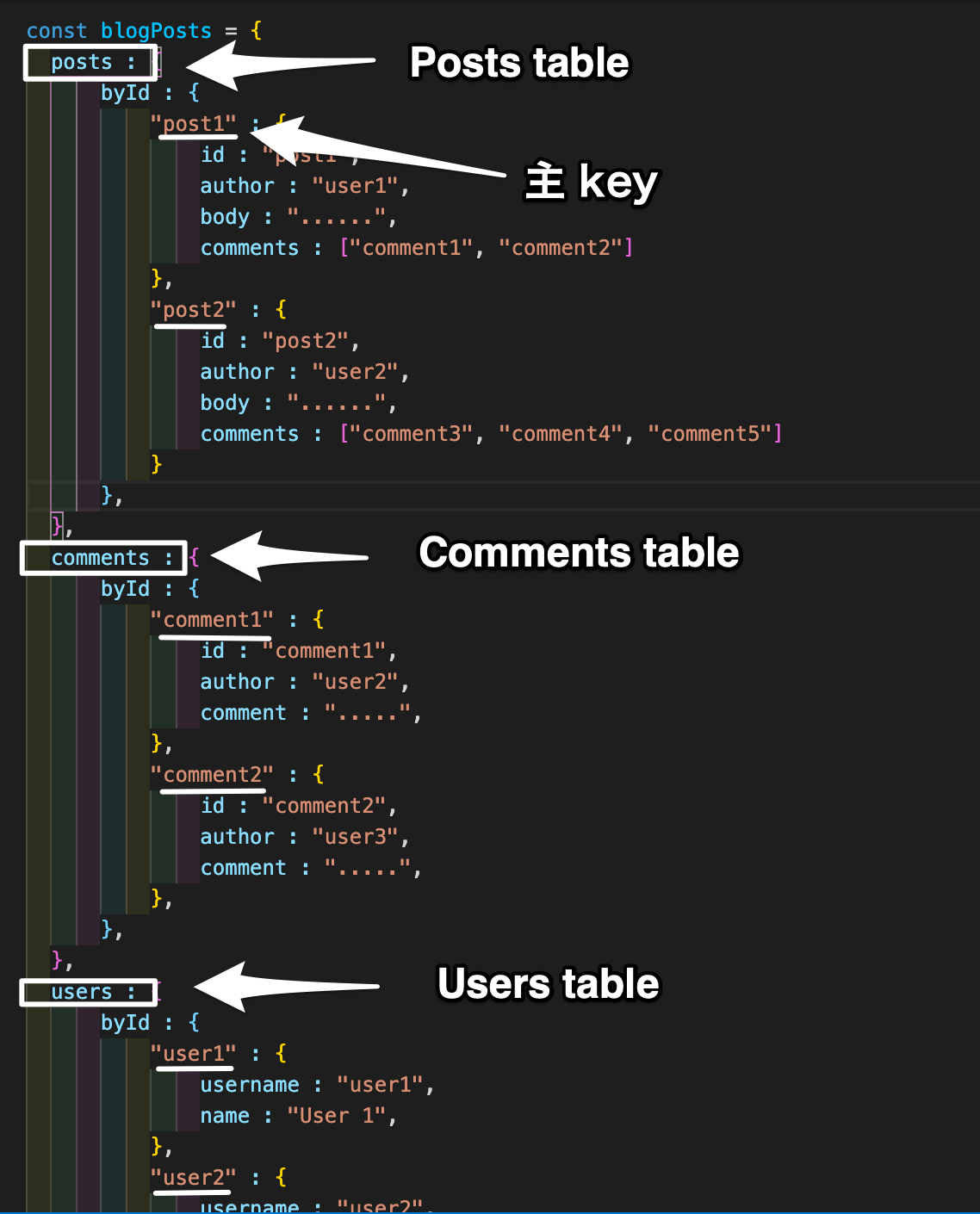
このような正規化をすることで、先ほどの post2 のauthor をread するコードは、以下のように変更できます。
blogPosts.posts.byId.post2.author
filter 処理をすることなく、ダイレクトにアクセスすることができました。
また、2の更新するときの問題も、正規化された状態では解決されます。
値の重複がなく適切に分割されているため、その関心を持つドメインのオブジェクト(table)内部だけを見れば良くなります。値を更新する時は、値が一意であることが保証されているため、一箇所のみを更新すれば良くなります。
参考記事: [Redux/Fluxでも役立つ] サーバーが返却するデータは正規化して格納すべし
参考記事: Reduxを用いる時にオススメしたい3つのTips
まとめ
1年ぶりに記事を書いてたら、とんでもなく長い文章になってしまいました。
メモ化の重要性、selector の役割、reselect、useSelector、正規化のお話をしました。
メモ化の概念は、React Hooks のuseState や useEffect にも出るため、React とは切っても切れない関係です。この記事が、少しでも皆様のお役に立てれば幸いです。
間違っていることがありましたら、コメント欄にどしどし教えてくださいませ。
ではでは〜