「疎結合にしろ」(または「蜜結合にするな」)と言われることがありますね。システム開発においては大切なことの1つです。結合度や凝集度といったことに,まだいまいちピンと来ていないという人もこの機会にあらためて考えてみませんか?
シンプルさ vs 複雑さ
システムはシンプルなほど良いです。複雑になるほど,本来の意図から離れていったり,メンテナンスが困難になったりしがちです。システムが複雑になる原因は色々ありますが,その一つは依存関係の数です。依存関係の数が増えれば増えるほど,絡み合って複雑になっていきます。(負のネットワーク効果)
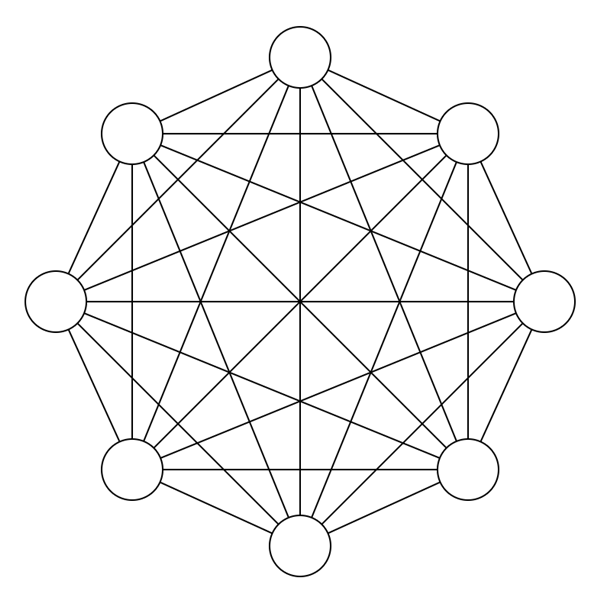
システムが大きくなるほど,モジュールの数とそれらの関連の数は多くなっていきます。ただでさえ複雑になっているところに関係ないものまでごちゃ混ぜになっていると,余計に複雑さが増大してしまいます。プログラムにおいても整理整頓してキレイに保つことが大切です。
そこで重要になるのが「結合度」と「凝集度」です。
結合度
結合度とは,モジュール(コンポーネント)同士がどのくらい関係しているかという度合いです。
たとえば,あるモジュールが変更された場合,別のモジュールにどの程度影響を及ぼすかということが1つの尺度になります。関係の度合いが大きいほど,他に及ぼす影響も大きくなります。影響範囲が広く,大きくなるほど変更が難しくなり,メンテナンスや機能拡張がしづらくなります。
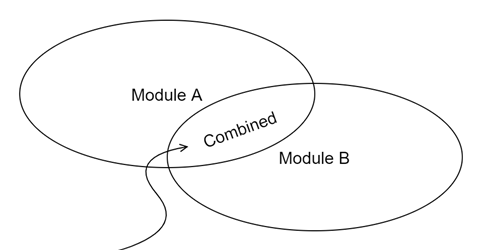
Module A を変更しようと思ったとき,Module B と結合している部分であった場合は,Module B の変更も余儀なくされます。結合しているモジュールが多いほど,同時に変更しなければならない箇所も多くなるということです。
- 結合度が高い(関係の度合いが大きい)=「蜜結合」
- 結合度が低い(関係の度合いが小さい)=「疎結合」
「疎結合にしろ」というのは,「モジュール同士の依存関係の度合いを小さくしろ(⊆システムの保守性・拡張性を向上させろ)」という意味です。
いくつか例をみてみましょう。
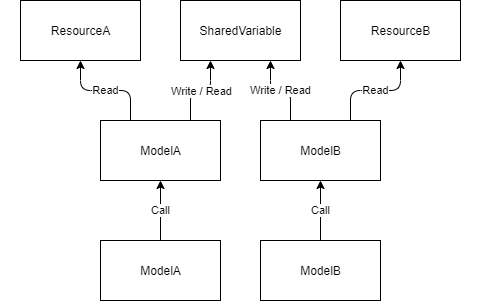
1. データを共有している
これはよく知られたアンチパターンですが,グローバル変数をみんなで直接読み書きしてしまうようなケースです。
// 共有データ
public static class SharedVariable
{
public static string Value { get; set; }
}
// 任意のモデルA
public class ModelA
{
// ResourceA を取得して共有データクラスのプロパティに設定する
public void LoadResourceA() => SharedVariable.Value = FetchResourceA();
// 共有データクラスのプロパティからデータを取得して返却する
public string GetValue() => SharedVariable.Value;
// UserInfoA を取得する
private string FetchResourceA() => { /* ... */ }
}
// 任意のモデルB
public class ModelB
{
// ResourceB を取得して共有データクラスのプロパティに設定する
public void LoadResourceB() => SharedVariable.Value = FetchResourceB();
// 共有データクラスのプロパティからデータを取得して返却する
public string GetValue() => SharedVariable.Value;
// ResourceB を取得する
private string FetchResourceB() => { /* ... */ }
}
SharedVariable が共有データクラスとしてプロパティを公開しています。
ModelA は取得したリソースを(なぜか)共有データに設定します。そのあと取得メソッドが呼び出されると共有データの値を返却します。さらに別のクラス ModelB も取得した別のリソースを同じ共有データに設定し,取得メソッドにて共有データの値を返却しています。また,共有データがシングルトンになっているため,スレッド間でも共有されてしまっています。
なんか,いろいろおかしいですね。
以下の順番で呼び出されたらどうなるでしょうか。
- ServiceA -> ModelA.LoadResourceA()
- ServiceB -> ModelB.LoadResourceB()
- ServiceA -> ModelA.GetValue()
3 を呼び出した人の期待値は ResourceA ですが,実際は ResourceB が返ってきてしまいます。
ModelA と ModelB がお互いに影響を及ぼし合ってしまっていますが,これらが本来は無関係だとすると,これは結合度が高いというより,もはや不具合ですね。
そもそも,ModelA と ModelB は何故外部の共有データに値を設定する必要があったのでしょうか。シンプルに FetchResourceA/B を公開するか,キャッシュが目的だとしても,それぞれの自クラス内や閉じたスコープで値を保持していれば,お互いに干渉し合うことはなくなります。
みんなで共有データを読み書きするようなことはやめましょう。
複数のコンポーネントで1つの DB を参照するのも同じく結合度が高まるため極力避けるべきです。
2. データの意味を共有している
システム内で使用する値に意味を持たせることがあります。定数や列挙子,あるいは DB でマスタ管理されるようなものです。
sex:
- 1: male
- 2: female
direction:
- 1: x
- 2: y
- 4: z
status_code:
- 1010: xxxx
- 1020: xxxx
- 1030: xxxx
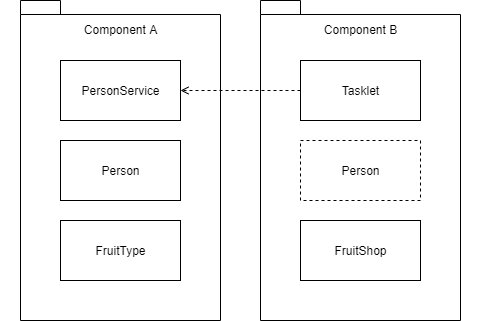
同じモジュール内であれば,定数や列挙体を使うことで参照先の値を一致させることができますが,DLL や Web API 経由で利用する場合は注意が必要です。
namespace ComponentA
{
// データの意味が定義されている
public class FruitType
{
public static int Apple = 1;
public static int Orange = 2;
public static int Banana = 3;
}
// データを保持する構造体
public class Person
{
public string Name { get; }
public int FavoriteFruit { get; } // FruitType で定義された値が入る
}
// Person を取得するサービス
public class PersonService
{
public Person Get(string name) { /* ... */ }
}
}
namespace ComponentB
{
public class FruitShop
{
// ComponentA.FruitType の値と同じ前提になっている(=依存している)
private readonly Dictionary<int, string> Dict =
new Dictionary<int, string>()
{
{1, "Apple" },
{2, "Orange" },
{3, "Banana" },
};
public string Order(int fruitType) => Dict[fruitType];
}
public class Tasklet
{
private PersonService PersonService { get; }
private FruitShop FruitShop { get; }
public void Main()
{
// 別ドメインからデータを取得する
var person = PersonService.Get("Taro");
// 自ドメインの定義を参照する
var fruit = FruitShop.Order(taro.FavoriteFruit);
Console.WriteLine($"{person.Name}'s favorite fruit is {fruit}");
}
}
}
ComponentA と ComponentB は別のサブシステムで,公開されている ComponentA のサービスを ComponentB が呼び出すとします。
Web API であれば以下の JSON が返ってくるイメージ。
{
"name": "Taro",
"favoriteFruit": 1,
}
FavoriteFruit は FruitType の値のいずれかで,ComponentA で定義されています。ComponentB ではこの定義を前提にして処理が書かれています。つまり,ComponentB はこの値の意味を ComponentA に依存(結合)しているわけです。
もしも,ComponentA が定義値の意味を変更してしまったら(たとえば 1 の意味を Apple から Mangoに変えてしまったら),ComponentB 内の処理は適正に機能しなくなってしまいます。万が一変更するのであれば,ComponentB も一緒に変更しなければなりません。しかし,別のサブシステムであれば,大抵の場合,同期をとるのは簡単でありません。ですので,値の定義を公開してしまったら,気軽に変更することは出来できないのです。
どうしてもこのような破壊的な変更が起きてしまう場合,ComponentA(提供する側)としては,バージョン管理などで後方互換性を維持する配慮が必要です。
また,呼び出す側(依存している方)としては,ラッパー(値や構造体の変換用のアダプター)を噛ませることで,ドメイン内の処理に影響を波及させないようにすることもできます。I/F のレイアウトが内部と外部が異なる場合もアダプターを使うことがありますが,区分値が異なる場合でも同様の方法で対応することができます。クリーンアーキテクチャのようなレイヤー構成では,Controllers や Gateways 層として,このような外部のデータ構造や定義値と内部で扱う形とを変換することで,ビジネスロジックが外部の変更に影響を与えないように設計します。
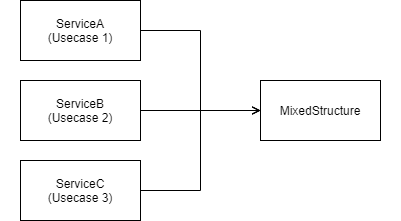
3. 構造体を共有している
複数の目的が異なる用途で1つの構造体を共用してしまっているケースです。
// 色々同梱されてしまっている構造体
public class MixedStructure
{
public string DataType { get; set; } // どれ使うか区分
public SubStructureA PropA { get; set; }
public SubStructureB PropB { get; set; }
public SubStructureC PropC { get; set; }
public class SubStructureA
{
public string CodeA { get; set; } // 固有のコード体系
/* ... */ // 固有のデータ構造
}
public class SubStructureB
{
public string CodeB { get; set; } // 固有のコード体系
/* ... */ // 固有のデータ構造
}
public class SubStructureC
{
public string CodeC { get; set; } // 固有のコード体系
/* ... */ // 固有のデータ構造
}
}
// SubStructureA を使うサービス
public class ServiceA
{
public MixedStructure Get(string codeA) => { /* ... */ }
}
// SubStructureB を使うサービス
public class ServiceB
{
public MixedStructure Get(string codeB) => { /* ... */ }
}
// SubStructureC を使うサービス
public class ServiceC
{
public MixedStructure Get(string codeC) => { /* ... */ }
}
Web API であれば以下の JSON が返ってくるイメージ。
{
"dataType": "1",
"propA": {
"codeA": "XXXX",
},
"propB": null,
"propC": null,
}
ServiceA を使って値を取得した場合,propA だけに値が入っていて,propB と propC は null になっています。dataType が 1 のときは propA の値を見ろということでしょう。
実際の現場では,このようにハッキリと分かれてもおらず,使う項目がバラバラに入っていて,どれを参照するべきなのかのパターンも多岐に渡るようなケースに出会ったこともあります。(カオスですね)
このケースでは,ServiceA の都合で MixedStructure を修正しようとすると,本来は無関係のはずの ServiceB, ServiceC にも影響が出ないかどうか考慮しなければならなくなってしまいます。また,構造体を見ただけでは,それが何を意味しているのか一意に特定することができないため,理解容易性も低くなります。
外向けの I/F に使用するような構造体は,ユースケースが異なるはずなので,それぞれごとに構造体を用意した方がよいでしょう。また,たまたま同じ項目を持っているからといって異なる意味で使用したり,簡単だからといって既存の構造体を安易に拡張したりするのはやめましょう。
4. 処理を共有している
しばしば「同じことを2度書くな」とか「再利用性を高めろ」とか言われます。これはその通りなのですが,不用意な再利用は無駄に結合度を高めてしまい,逆に保守性を低下させてしまう場合があります。
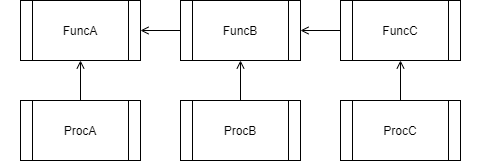
FuncB は FuncA に,FuncC は FuncB に依存しています。もし,FuncA に変更を加えたとすると,他の全てに影響を与えることになってしまいます。
もし,I/F のレイアウト(シグネチャ)に変更があったらコンパイルエラーになって処理の実行前に気が付くかもしれませんが,レイアウトはそのままで "副作用" のみ変更されると気が付かないうちに意図しない挙動の変更を誘発しまうことになる危険があるため,注意が必要です。
また,たまたま機能的に同じというだけで,ビジネス的に異なる意味の処理を利用してはいけません。異なる意図の利用者が依存していると,一方には変更が必要だけど,もう一方では変更されては困るという事態になります。変更に当たって切り離す必要が生じますが,洗い出すのも大変ですし,漏れてバグの原因になるかもしれません。
このような事態を避けるためには,利用される側の処理もその意図・存在理由を明確しておくことが大切です。そのためにも,ちゃんと 意味のある “まとまり” を意識して分けましょう。というのが次の話です。
凝集度
凝集度とは,同じ意味・役割のものが同じところに集まっているかどいう度合いです。
- 凝集度が高い = ある責務・関心ごとが1か所に集約されている
- 凝集度が低い = ある責務・関心ごとが色んな箇所に点在している or 1か所に色んな責務・関心が混在している
1つの責務・関心ごとは1つのモジュールに集約されていることが望ましく,1つのモジュールは1つの責務・関心だけを負っていることが望ましいです。つまり,凝集度は高い方がよいということです。
ある事柄に関する処理やデータが複数の箇所に点在していると,どのように処理によって実現されているのか把握するのが難しくなりますし,変更しようと思ったときに修正するべき箇所が多くなります。
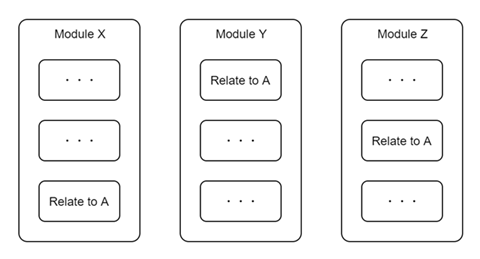
また,1つのモジュールが複数の責務を負っていると,変更の影響が本来関係のないコードへも影響を及ぼしてしまうかもしれません。意味のある関係性はないものをとりあえず1つのクラスやモジュールにどんどん機能を追加していってしまうと,凝集度が下がってメンテナンス性が低下します。
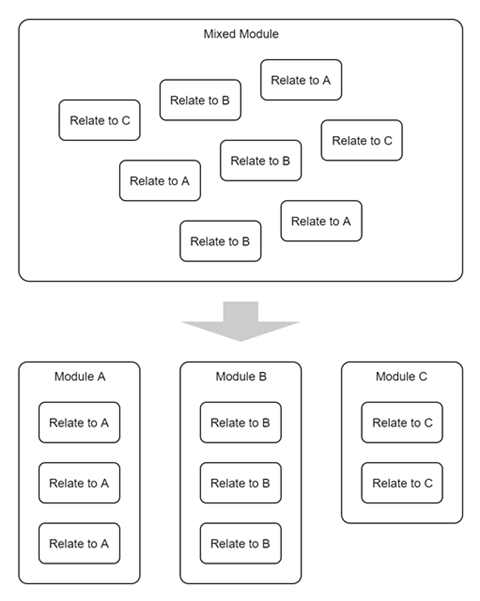
意味のあるもの同士でまとめて整理整頓することで,すっきり見やすくなり可読性も高まりますし,再利用の際の安全性も高まります。また,凝集度を高めることは不要な関連を排除することになるため,結果として結合度を下げることにもつながります。
まとめ
- システムはシンプルに保つ
- 凝集度は高くする(関係の深いものはまとめる)
- 結合度は低くする(関係のないものには依存しない)
<= To Be Continued...?