はじめに
独学や会社の研修で基本的なプログラミングのやり方が分かっても,一定以上の規模のシステムを作ろうと思ったら,それだけでは足りません。
仕様書・設計書を渡されて「これを作って」と言われたものの,どこから手をつけたらいいのか分からない。あるいは,ある程度のプログラムは書けるけど,オブジェクト指向はよく分からない。そんな方に向けて書いています。
C# や Java のようなオブジェクト指向言語を想定しています 1 が,なるべく具体的な言語や技術に依存しないように配慮するつもりです。実際,要求される言語やフレームワークは変わりゆくものです。具体的な技術はその都度,学んでいくことになるでしょう。それでも,より抽象度・汎用性の高いスキルが身についていれば,新しい技術においてもそれらをより活かすことができるはずです。
というわけで,これから何回かに分けてシステム開発の入門記事を書いていきます。
I/F(インターフェイス)
ある程度の規模のシステムを開発する現場では,未経験者にいきなり全体の設計を任せることは稀です。おそらくアーキテクト的な人がシステム全体の設計をして,各メンバーにはそのうちの一部分が任されます。どんな粒度で切られるかはシステムの規模や性質,チームの体制などによるでしょう。モノリシックなシステムでは1つの機能やパッケージになるかもしれませんし,SOA / マイクロサービスのような分散システムではコンポーネント単位かもしれません。
いずれにしても,まずはじめに,最も大切なことは**「I/F(インターフェイス)」**です。
I/F はドメインやモジュールの境界であり,そいつとそいつ以外との間における約束事です。(ここでの意味はオブジェクト指向言語の機能としてのそれよりも広義のものを指しています)
I/F とは,ざっくりいうと
“何が入力として必要で,何が出力として返されるのか” 2
ということです。
例えば以下の関数
public int Inc(int x) => x + 1;
public int Add(int x, int y) => x + y;
-
Incは int 型の値を1つ受け取り,1を加えた値を返す -
Addは int 型の値を2つ受け取り,合計した値を返す
となっています。
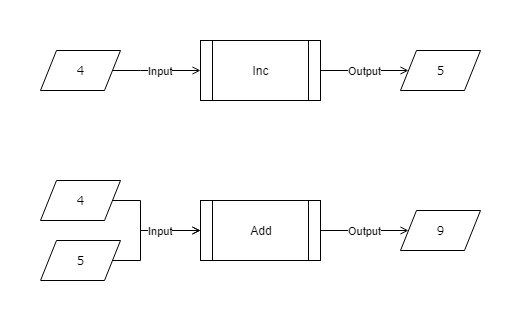
これだと中身の処理が明白なので I/F の有難味がよく分かりませんね。
もう1つ別の例も見てみましょう。
public interface IArticleRepository
{
// Query
public Article FindOneById(int articleId);
public IEnumerable<Article> FindByKeyword(string keyword);
// Command
public void Create(Article article);
}
public class Article
{
public int Id { get; }
public string Title { get; }
public string Body { get; }
public int AuthorId { get; }
public DateTime CreatedDatetime { get; }
public Article(/* all params */) { /* set params */ }
}
記事の構造体とそれを取得・保存するためのリポジトリーです。
-
FindOneByIdは記事IDを渡したら記事を一つ返す -
FindByKeywordは記事に関するキーワードを渡したら記事のリストを返す -
Createは記事イベントを永続化する
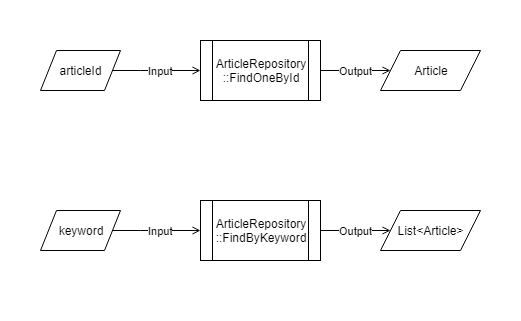
このように引数の型と戻り値の型 3 によって,利用の仕方を規定しています。静的型付け言語であれば,型によってこのルールが守られているかどうかがコンパイル時に分かるため,安全にプログラミングすることができます。
型の種類と数だけでなく多重度(カーディナリティ)も大切です。多重度は簡単に言うと1件か複数件かということです。慣れてくると当たり前に思いますが,初心者のうちは混乱してしまう方もいるようです。
結果が0件の場合や保存・削除に失敗した場合,どのように振る舞うべきかということも考慮する必要があります。null や 空のリストが返るのか,例外が発生するのか。上記の例では,Command系は戻り値が void (戻り値なし)なので失敗時は例外が発生しそうですね。もし戻り値が bool であれば成功か失敗かを真偽値で返してくれそうです。4
そういったこともドキュメントコメントや I/F 仕様書に記載しておくとよいでしょう。
重要なことは
“決められたパラメーターを渡せば結果を返してくれる”
すなわち
“使う側は中の実装がどうなっているかは気にしなくてよい”
ということです。
これは「カプセル化」と言われています。
記事のデータがどこからやってくるのか(DBなのか,ファイルなのか,キャッシュメモリなのか)は,記事が欲しい人(該当の関数を呼び出す処理)からしてみたらどうでもいいことです。記事を取ってくる人と,取ってきた記事を使って何かの処理をする人は,それぞれ関心ごとが異なるはずです。まずは、処理ごとの役割を把握して分割しましょう。(関心の分離)
このように処理を責務ごとに切り分けておくことには様々なメリットがあります。
まず,その処理が何者なのかが分かりやすくなります。ソースコードを読むときに,それが何者であるのかを知ることは第一歩です。1つの関数に色んな処理がごちゃ混ぜになっていると何をしたいのかを把握するのも苦労します。I/F をきちんと定義することは,役割を明確にすることです。役割が明確になっていれば理解しやすくなり,可読性(ソースコードの読みやすさ)が向上します。人に機能の説明をしたり,要求と合っているのかを確認したりするときも,容易なりますね。
テストもしやすくなります。データを取ってくる関数のテストはデータさえ取って来ることができれば OK になります。一方,取得したデータに対して処理をする関数は,本来の目的である,与えられたデータに対する処理のテストだけに専念できます。役割がきちんと分かれていれば,実際にその役割を果たしているのかの検証が容易になります。スタブやモックを使うことでデータが取得できた前提(あるいは取得できなかった前提)でテストができ,テストそのものもコンパクトになります。
不具合が発見されたときも原因箇所のアタリが付けやすくなりますし,変更にも柔軟に対応できるようになるでしょう。システムには必ず不具合が生じます。また,仕様変更も発生します。ソースコードは生もの です。システム開発を続けていく中で,日々の状況に合わせて変化していくものだという前提で望みましょう。保守性(不具合修正,リファクタリング,機能拡張のしやすさ)を保つことは,システム開発をする上で大切なポイントです。
注意)プログラムの汎用性・再利用性を向上させることは有用ですが,はじめのうち(開発の序盤)から意識しすぎると逆効果になる場合もあります。また,下手な再利用の仕方をすると結合度が高まり,保守性が低下することもあります。抽象化よりもまずは責務・関心ごとの分離を優先しましょう。
I/F を定義するということは
“処理をどのような単位に区切るか”
を考えることであり,
“区切られたそれぞれの処理の責務は何か(何者であるのか)”
を規定ことです。
ベタベタと処理をまとめて書かず,一定の意味のまとまりごとにクラスやモジュールに区切りましょう。この辺がうまく切り分けられないと1つの関数の中にどんどん処理が詰め込まれて巨大なモンスターとなり,後々誰か(往々にして自分)が泣くことになります。
この基本的な考え方はシステム全体にも言えます。どのようなサブシステムで構成されているか。どのようなモジュール群で構成されているか。各要素はどのような関連があるのか。大小のモジュールが入れ子(フラクタル)構造を形作っているのがシステムです。I/F を考えることは,システム全体のアーキテクチャを考えることにもつながっていきます。
また,I/F が変更されると,それを呼び出していた処理が動かなくなって(ビルドできなくなって)しまいます。呼び出し元のソースが全て自分でコントロール可能な範囲であればまだよいのですが,複数人で共同開発していたり,API が公開されていて外部のからアクセスされたりする場合には問題となります。修正しようとしているソースがどこまで影響を及ぼす可能性があるのかについては常に注意が必要です。公開された I/F は変えられないという点でも設計時点の検討は重要です。互換性のない変更は避けましょう。 5
副作用
さて,カプセル化(ブラックボックス化)にもいくつか問題があります。
Q:「中で何が起こっているのか本当に知らなくていいの?」
A:「場合によりますね」
たとえば getXXX 6という関数があったとします。単なるプロパティの取得処理かなと思って気軽に呼び出したら,実は裏で「重たいクエリ投げる」「大量のデータをゴリゴリ弄りまわす」というようなヘビーなやつかもしれません。そうとは知らずループの中で何回も呼び出してしまったらパフォーマンスの悪化につながります。7
さらに気を付けなければならないのは**「副作用」**です。
いわゆる純粋関数であれば,入出力(引数と戻り値)以外の外部データに影響を受けず,与えません。また,同じ入力に対して常に同じ結果を返します。(参照透過性)
前述の Inc や Add 関数はこれにあたります。(たとえば,Inc(1) == 2 は常に True となります)
しかし,多くのプログラミング言語において,関数/メソッドは引数以外にも外部の値を参照することもできますし,戻り値を返すだけではなく外部の値を書き換えることも可能です。このような引数と戻り値以外のデータの操作を「副作用」といいます。
先ほどのリポジトリーでは,Query系の処理は外部のデータを参照しますし,Command系の処理は外部にデータを保存していますので,これらは副作用になります。
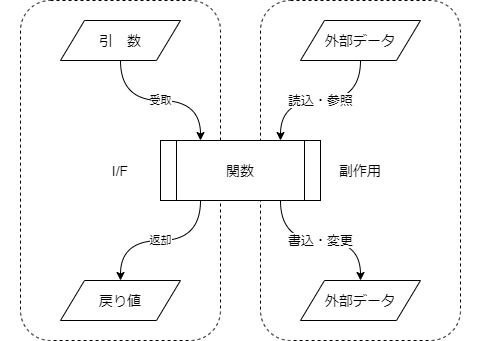
▽ 外部から影響を受けるもの
* 引数
* 読込・参照する外部データ
▽ 外部に影響を与えるもの
* 戻り値・・・実際の影響は使う側次第
* 書込・変更する外部データ
※ 外部データ:ファイル,DB,共有メモリ,標準入出力,環境変数 など
引数と戻り値は明示的ですが,副作用は暗黙的です。副作用の何が問題になるのかというと,I/F で規定されたルール以外の挙動に配慮しなければならなくなってしまう点です。引数と戻り値で閉じられた世界では,I/F だけに関心を持てばよかったのですが,副作用を含む場合は外部に対する挙動についても関心を持たなければならなくなります。I/F が守られているかどうかは型で保証されますが,副作用に関しては型によって安全性を担保することはできません。
中でログを出力している処理をループで何度も呼び出したら,意図しないログが大量に出力されていた。読込または書込しようとしていたファイルが突然なくなった(処理中に誰かが消した)。DB や HTTP などのネットワーク接続が途中で切断されたためデータにアクセスできなくなった。などということは,当然想定しなければなりません。
該当の処理(モジュール)と外部の処理(モジュール)との間における関係・作用は,I/F だけではなく,どんな副作用があるのかということについても考慮する必要があります。
簡単な副作用の例としては,可変なローカル変数を持つオブジェクトです。
public class Counter
{
private int _value = 0;
public int GetValue() => ++_value;
}
GetValue は,初期値が0で,呼び出す度に前回より1大きい値が返却されます。つまり,呼び出す度に結果が変わります。もし,同じ値を参照したければ,もう一度この関数を呼ぶ代わりに,変数に取っておく必要があります。参照透過であれば,変数にとっておいた値ともう一度関数を呼ぶことは同義になります。 8
この例では書き換える値のスコープがフィールド内に限定されていますが,もしこれが開かれていると不確実性はさらに上がります。private のままであれば,1つのインスタンスに対して値は必ずシーケンシャルに取得できることが保証されていました。もしも Counter._value が public だったらどうなるでしょう。だれでも値を書き換え可能になってしまいます。例えば,受付の整理番号を発行するためにこのクラスを利用していたとすると,誰かがこの値を現在値よりも小さい値に上書きしてしまったら,発行される整理番号が重複することになってしまいます。
発行 101 → 102
発行 102 → 103
発行 103 → 104
上書 104 → 101
発行 101 → 102 !?
ちなみに,このように外部からデータへのアクセスを制限して安全性を高めることもカプセル化の目的の一つです。
しかし,データを共通で利用したい場合もあるでしょう。例えば,処理制御のためのフラグです。(もはやフラグというテクニック自体やめた方がいいという向きもあるでしょうが・・・)
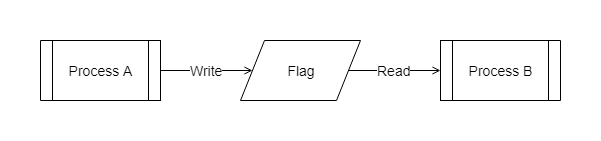
あるフラグを変更する 処理A と同じフラグを参照する 処理B があったとします。処理A は何かの条件によってフラグの値を設定します。処理B はフラグの値を参照して自身の挙動を決定します。それぞれ任意のタイミングに実行される可能性があるとすると,処理B から見た時にフラグがいつ変わるかは分かりませんし,誰が変えたのかも分かりません。しかし,プログラマは知っていなければなりません。 処理B を作成・修正する人は影響範囲として 処理A の挙動を把握しておかなければならないのです。
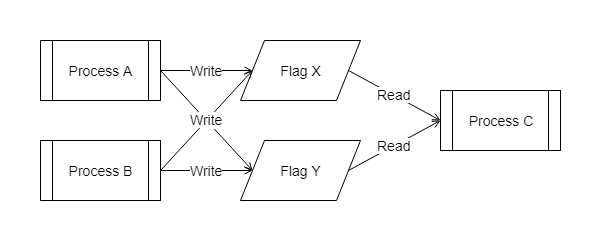
これが,もう一つフラグと処理が増えただけで複雑性がぐっと増すのが分かります。複数のフラグが掛け合わさると状態のバリエーション(順列・組み合わせ)は爆発的に増えます。処理Cの挙動のバリエーションは単純に考えると「フラグXの状態の種類 × フラグYの状態の種類」になります。状態遷移のケースを洗い出すのに苦労しそうです。そのバリエーションごとのテストも大変です。
システムが大きくなると制御のためのフラグや条件を増やしたくなるものですが,気をつけないとすぐに「フラグ祭り」となり,メンテナンスが困難なシステムになりかねません。 慎重に検討しましょう。(アプリケーション設定なども,稼働中の動的な変更はないにしてもバリエーションに関する観点は一緒です)
システムを作る上で副作用は避けられないものですが,プログラムを複雑にし,見通しを悪くしやすくする性質も持っています。とくに,非同期処理を行うときには問題になりやすいため注意が必要です。可能な限り関数の純粋性を保つという方針を持ちつつ,副作用を起こす処理は明確に切り分けられるようにするのが望ましいでしょう。
そのクラスの責務を考えたとき,本当にそのように振る舞うべきかどうか慎重に見極めることが大切です。たとえば,そのクラスが直接 DB を参照する代わりに,他のクラスで取得したデータを引数として受け取る。あるいは,そのクラスが直接 DB に書込む代わりに,結果を戻り値として返却し,別のクラスが保存する。などといったことです。
どのような粒度で行うのが良いのか,この辺はケースによって異なります。経験を積むとその精度が上がっていきますが,はじめのうちは経験者・緒先輩方に相談したりレビューをしてもらったりしながら進めていくとよいでしょう。
まとめ
- 処理は役割ごとに切り分けましょう(そして適切な名前を付けましょう)
- 処理の中身を書く前に I/F(インターフェイス)を定義しましょう
- 副作用を持つ関数と持たない関数は意図を持って明確に分けましょう
参考図書
-
サンプルは大体 C# です。 ↩
-
もう少し詳しくいうと,型にどのようなメンバーを持つのかなども含みます。 ↩
-
実際は,
IdなどもintではなくArticleIdのような値オブジェクトにする方が望ましいですが,今回は取っ掛かりやすさを優先しています。 ↩ -
実際は,
OptionやResultのような型で表現するのが良さそうです。 ↩ -
常に後方互換性に配慮しましょう。互換性のない変更が必要な場合はバージョンで切り替えられるようにしましょう。 ↩
-
この場合は名前の付け方にも問題があるかもしれません。例えば,クエリを投げるような処理であれば,
fetchXXXなどの方がよいでしょう。 ↩ -
プロキシー(キャッシュ)を挟んだり,軽量版の関数を用意したりするなどの対応が必要かもしれません。 ↩
-
実際には関数呼び出しのオーバーヘッドがかかるかもしれません。あるいは,言語によってはインライン展開などで最適化されるかもしれません。 ↩