前置き
Amazon Lookout for Metrics を使ったデータの異常検知について体系的にまとまった日本語情報がなかったので整理してみる。
書いていて長くなったので、前編と後編に分けています。
前編は Lookout for Metrics の概念と設定項目の説明となっており、人によっては後編のハンズオンから始めたほうがイメージをつかみやすいかもしれません。前篇と後編を行き来するなどしてやりやすい方法で読み進めてください。
対象読者
- AWSのAI系マネージドサービスに興味のある方
- AWSを使わずに異常検知モデルを構築している機械学習エンジニア
本稿で目指すゴール
- Lookout for Metricsの設定方法とその意味が理解できるようになること。
- Lookout for Metricsを触ってみて具体的な異常検知の運用イメージをつかむこと。
Amazon Lookout for Metricsとは
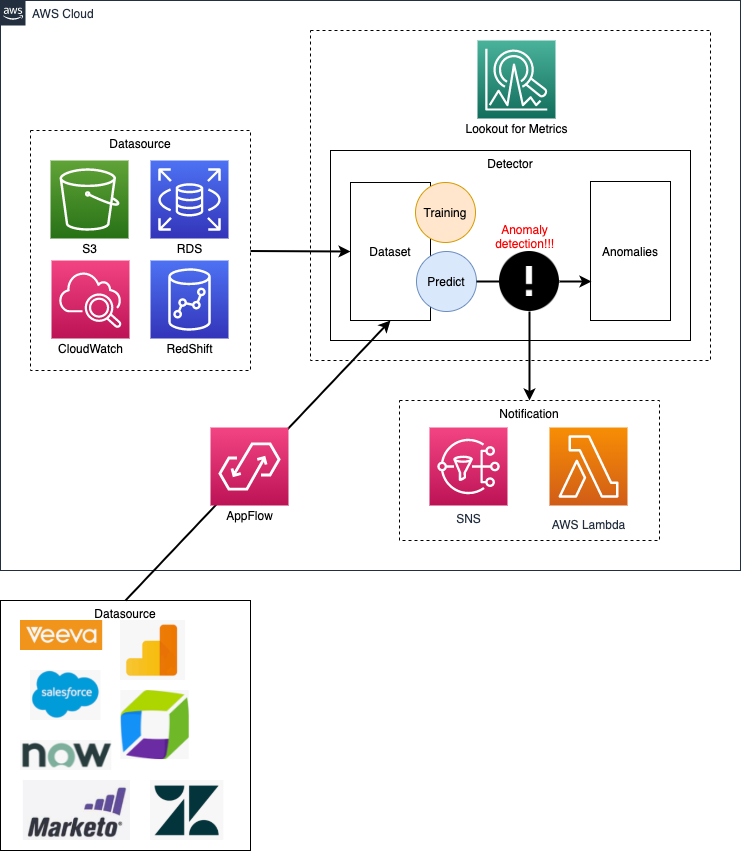
Amazon Lookout for Metricsとは、機械学習を使って時系列データから異常を検出し、その発生原因の抽出までを一貫して運用管理できるサービスである。
データソースにはAWSのS3やCloudWatch、RDS、RedShift、加えて様々な外部サービスを指定できる。
異常検知時は重大度スコアを算出してその発生要因となった項目値を抽出する。
検知時に通知先としてAWSのLambdaやSNSを指定できる(要するにどこにでも通知可能)。
「異常」の定義
ここでいう異常とはどんな状態を指すのか。
具体的には、時系列データにおいて観測対象の値が一定の推移パターンから乖離している状態のことである。
異常と言うと悪い状態のイメージがあるが、その状態の良し悪しは人間が判断するものであり、Lookout for Metrics はそのような意味付けまではしない。
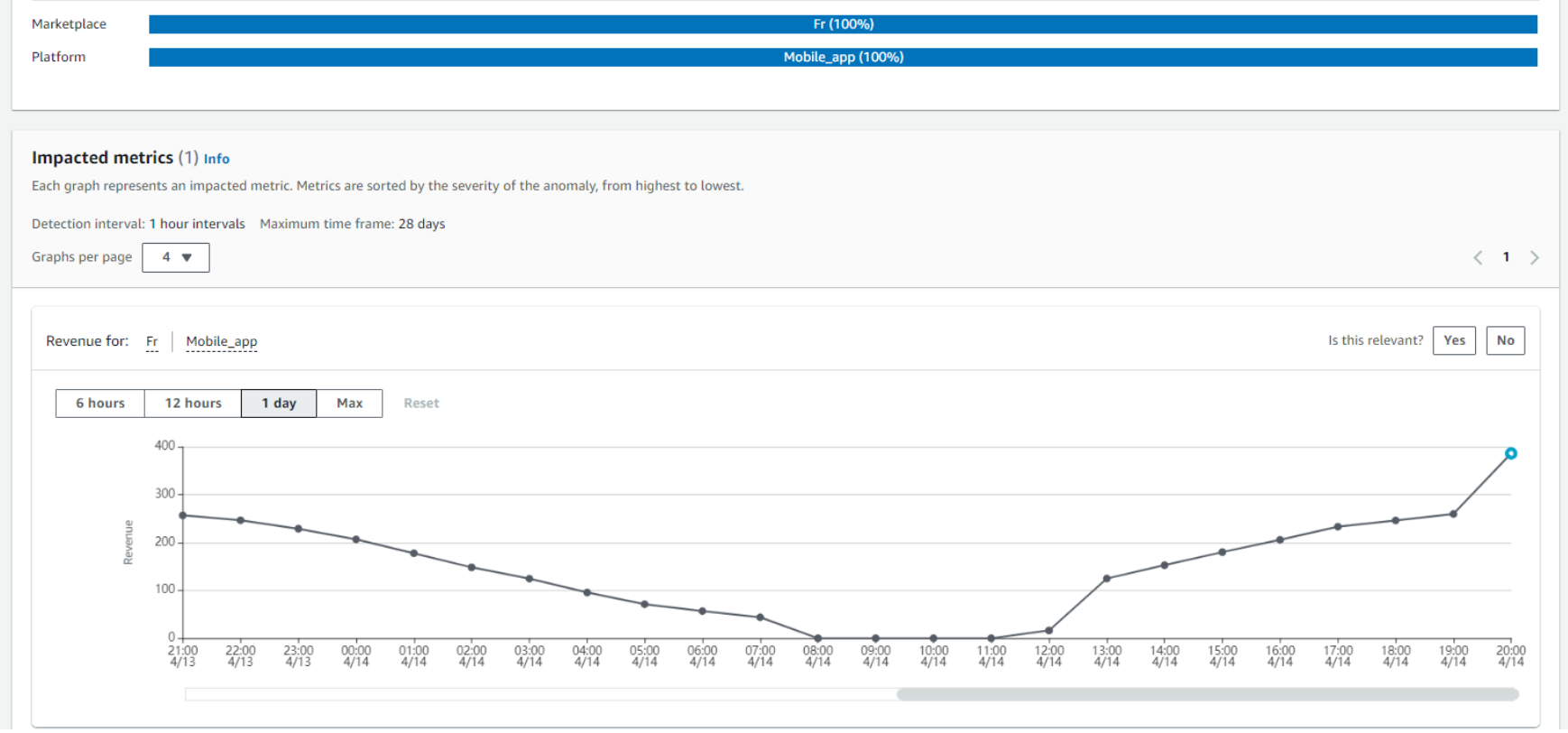
異常検知結果の詳細コンソール。観測対象の値(売上)の急激UPを検知している例。
実行モード
Amazon Lookout for Metricsには、用途に分けて2種類の実行モードが存在する。
backtestモード
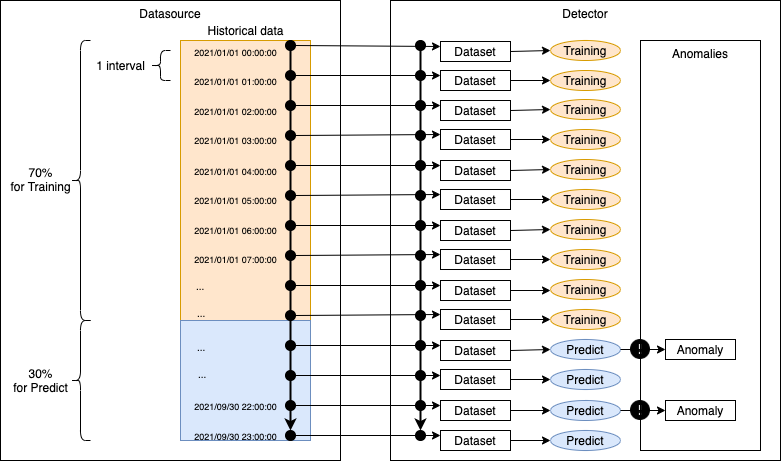
過去の履歴データを用いて検出器を学習し、同時に推論(異常検知)を実行する。履歴データの70%は学習に、30%は推論に使われる。
後述のcontinuousモードで異常検知を継続運用する前段階として、そのデータでどの程度の精度が出せる検出器を構築できるかを試行錯誤する用途で使用する。
continuousモード
異常検知を継続運用するためのモードである。
履歴データ、連続データの両方を指定時は、履歴データを学習に使用してから連続データで推論(異常検知)を行う。
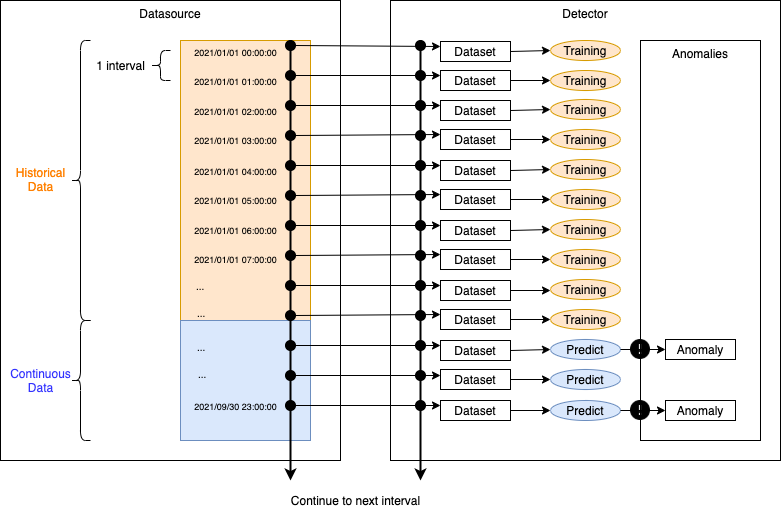
連続データのみを指定時は、連続データの最初を学習に使用してから連続データで推論(異常検知)を行う。
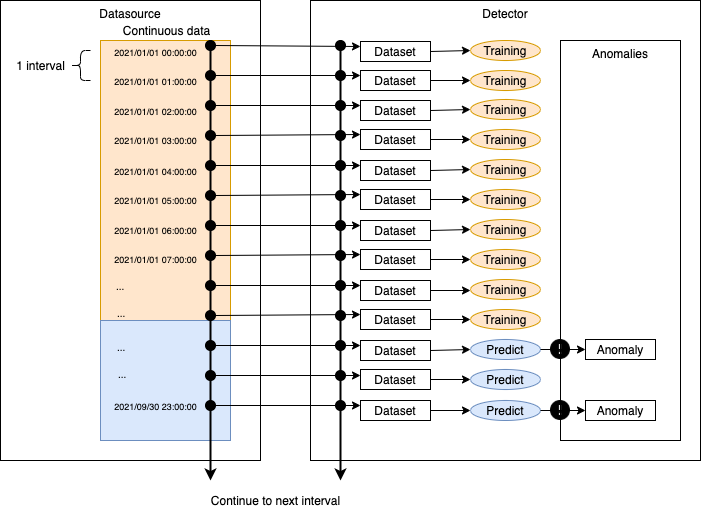
連続データは継続的にデータソースに提供されることが前提である。
指定インターバルでデータソースからデータをinputし、推論(異常検知)を繰り返し実行する。
データについて
本格的に運用する場合は、backtestモード使用の際に未処理データの前処理を行うための機械学習の知見が必要となる。加えて、データソース側で適切なデータ出力設計もせねばならない。
一応サンプルデータの作成はこちらのスクリプトを使えばできるようである。
後編で行うハンズオンのデータセットは @kame92782224 さんがハンズオンのために用意されていた以下のデータを使用させて頂きました。ありがとうございます。
Amazon Lookout for Metricsの基礎知識
Detector(検出器)
検出器は時系列データを監視する異常検知モデルであり、最初に登録するリソースである。
異常検知を始めるには、登録した検出器に時系列データで学習させる必要がある。
登録時には時系列データをデータソースからインプットする間隔(5m/10m/1h/1d)を指定せねばならない。
Datasource(データソース)
検出器で使用するデータを提供するサービス、もしくはリソースである。
AWSでは S3/CloudWatch/RDS/Redshift が対応している。
他にも、Amazon AppFlow のデータ転送経由で様々な外部サービスをデータソースとして連携可能である。
データの種類
データソースにはLookout for Metricsの実行モード別に必要とされる以下2種類のタイプがある。
Historical data / Continuous data
| backtestモード | continuousモード | |
|---|---|---|
| Historical data | 必須 | 必須ではない(※1) |
| Continuous data | - | 必須 |
Historical data(履歴データ)
backtestモード実行時には必須となるデータソース。
backtestモードを実行時、その70%は学習に、30%は推論(異常検知)のために使用される。
実行のためには、時系列を表現するタイムスタンプカラムに285〜3000のインターバル分の値が格納されたデータが必要となる。例えば、検出器登録時に指定するインターバル値を1h(1時間)とした場合、タイムスタンプカラムが285時間〜3000時間の範囲のデータが必要となる。
※1: continuous実行モードでは指定は必須ではない。もし未指定の場合は、連続データでの学習が必要となるため、推論が開始されるタイミングが遅れることに注意。指定時は検出器は履歴データで学習を実行した後に連続データで推論(異常検知)を開始する。
Continuous data(連続データ)
continuousモード実行時に指定をするデータソース。
continuousモードの性質上、継続的にデータソースにデータとして提供されることが前提となる。そのため、データソース側にもデータの継続出力のためのなんらかの仕組みが必要となる。
continuousモード実行時、履歴データを未指定の場合はこのデータを学習に使用する。学習は古いデータから順に使われる。推論(異常検知)の開始はその分だけ遅れることになる。
Dataset(データセット)
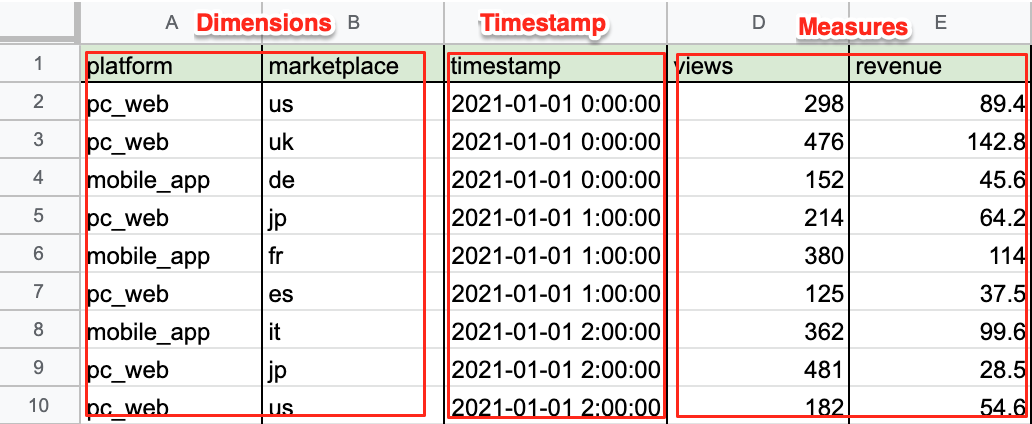
データセットとは、学習と推論を実行する時にデータソースから検出器にコピーしたデータである。データセットには以下の要素が含まれる必要がある。
タイムスタンプカラム
データを時系列で分析するために、Lookout for Metrics が検知可能なタイムスタンプを表現するカラム。
値は検出器登録時に指定したインターバル(5m/10m/1h/1d)で出力されている必要がある。
検出器が値を認識するために、タイムスタンプ値のフォーマットを指定せねばならない。
Metrics(メトリクス)
ディメンション
元データをレコード単位に分割するための指標となるカラム。異常検知の精度に影響を与える。検出器にデータセットを学習にかける際、最大5つまで指定可能。
メジャー
異常検知を行う対象となる値。項目と集計方法を指定する。検出器にデータセットを学習にかける際、最大5つまで指定可能。
メトリック
ディメンション項目とメジャー項目の組み合わせ。
補足
機械学習プロジェクトの成否を左右する最も重要なファクターは学習データの質と量である。
精度の良いモデルを構築するためには、まず顧客から受け取った前処理をしていないデータをよく観察することから始める。そして、精度向上に必要な特徴量を抽出するための仮説を立て、学習に使えるデータを作成する必要がある。これが一般的な機械学習プロジェクトのファーストアプローチである。
Lookout for Metrics を使う際も同様である。
検出器を作成するための学習モデルはAmazonが過去20年の研究開発を経て作り上げた優秀なモデルが使用されるようだが、データソースに提供されるデータの質が悪い場合は当然ながら実運用に使えるだけの異常検知精度は出せない。求められる精度を出せる検証器が構築されるまで、データの前処理とbacktestモードの実行を繰り返すことになると思われる。ここは機械学習の知見が要求される、もっとも労力を要するフェーズである。
Alerts(検知アラート)
検出器が異常を検知した時は、通知先にSNSやLambdaを指定できる。
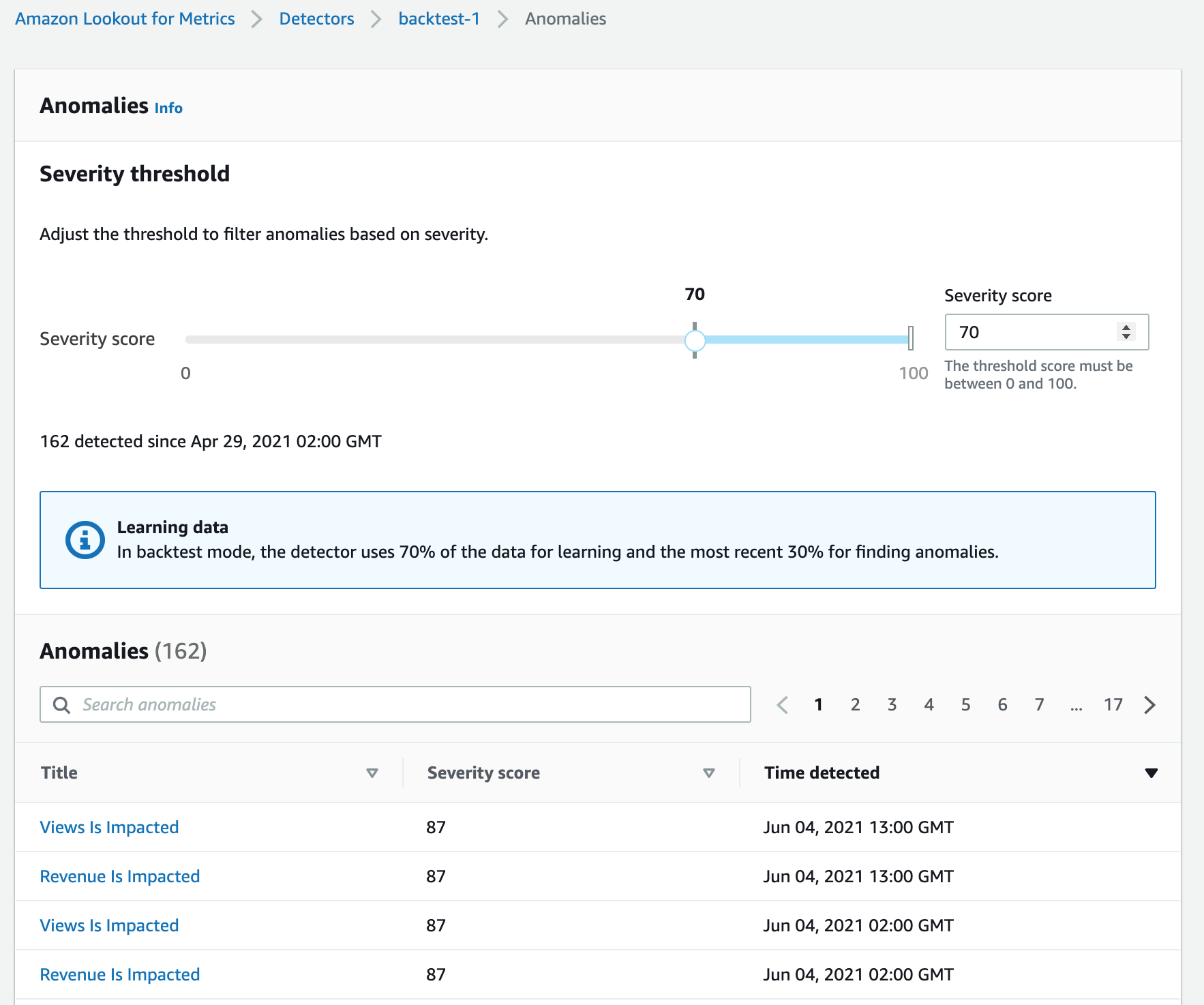
Anomalies(検知結果)
異常検知一覧
異常検知詳細
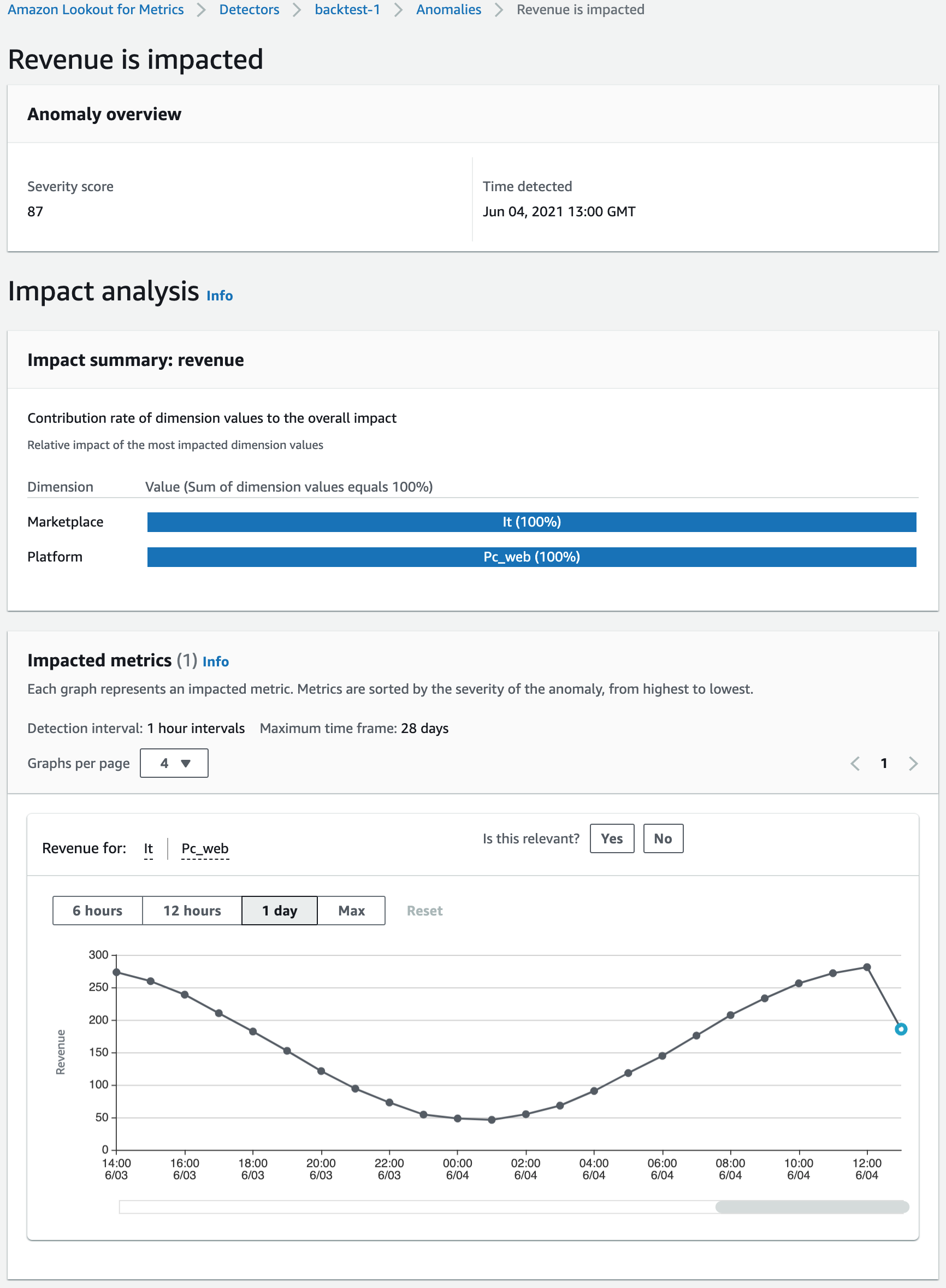
検知した異常は検出器別に一覧でリストアップされ、詳細画面でその発生要因を確認することができる。このレポートには異常発生の要因となるメトリクスとその関連性情報が表示されている。
ユーザーはその情報を確認し、検出器にその関連性をフィードバック提供することができる。検出器はこのフィードバックを利用してさらに学習を進め、異常検知の精度を向上させることができる。
費用について
後編では、実際に Lookout for Metrics をコンソールから操作するハンズオンを行う。
backtestモードとcontinuousモードで異常検知を運用することによって、より具体的な利用イメージを持てるようになることを目指す。