前置き
前編の基礎知識に引き続き、本稿では具体的な Lookout form Metrics の操作を学ぶためのハンズオンを記載する。
本稿のハンズオンにはこちらのイベントにて実施された内容が含まれています。
本編で行うハンズオンのデータセットは @kame92782224 さんがハンズオンのために用意されていたこちらのデータを使用させて頂きました。ありがとうございます。
対象読者
- AWSのAI系マネージドサービスに興味のある方
- AWSを使わずに異常検知モデルを構築している機械学習エンジニア
本稿で目指すゴール
- Lookout for Metricsの設定方法とその意味が理解できるようになること。
- Lookout for Metricsを触ってみて具体的な異常検知の運用イメージをつかむこと。
2つの実験により、Lookout for Metricsを使用して異常検知を試してみる。
ハンズオン後に不要な料金がかからないように、AWSリソースのクリア方法も記載している。
実験1. backtestモードで異常検知の精度を確認する
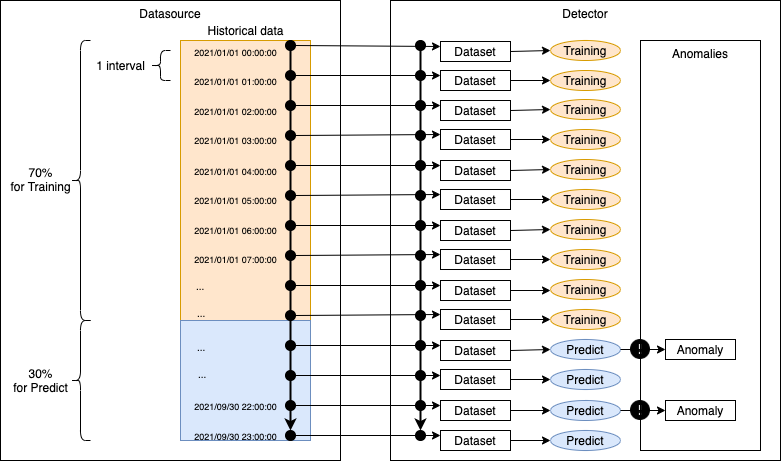
こちらはイベントのハンズオンでの実施した内容。
S3をデータソースとして履歴データを設置し、検出器を構築する。
学習完了後に推論(異常検知)の精度と発生要因を確認してみる。
データソースを用意する
今回の実験ではS3をデータソースとする。
S3にデータをアップロードする必要があるが、データ量が大きく時間がかかるため、CloudShellを使ってS3にアップロードする。この方法だとS3のコンソールからよりも数十倍早くアップロードができる。
S3バケットを作成する
適当な名前でデータソースとなるS3バケットを作成する。いまは実験のため設定はすべてデフォルトで問題ない。
CloudShell経由でS3バケットにデータをアップロードする
使用するデータはこちら。ecommerce.zip
これをローカルマシンにダウンロードしておく。
AWSのCloudShellを起動する。

Actions > Upload file でecommerce.zipファイルをアップロードする。
ファイルを解凍する。
$ unzip ./ecommerce.zip
展開されたディレクトリをまとめてS3にアップロードする。
$ !aws s3 sync ./ecommerce/ s3://{s3バケット名}/ecommerce/
S3バケットの /ecommerce/ 以下にデータがアップロードされていることを確認する。

検出器を作成する
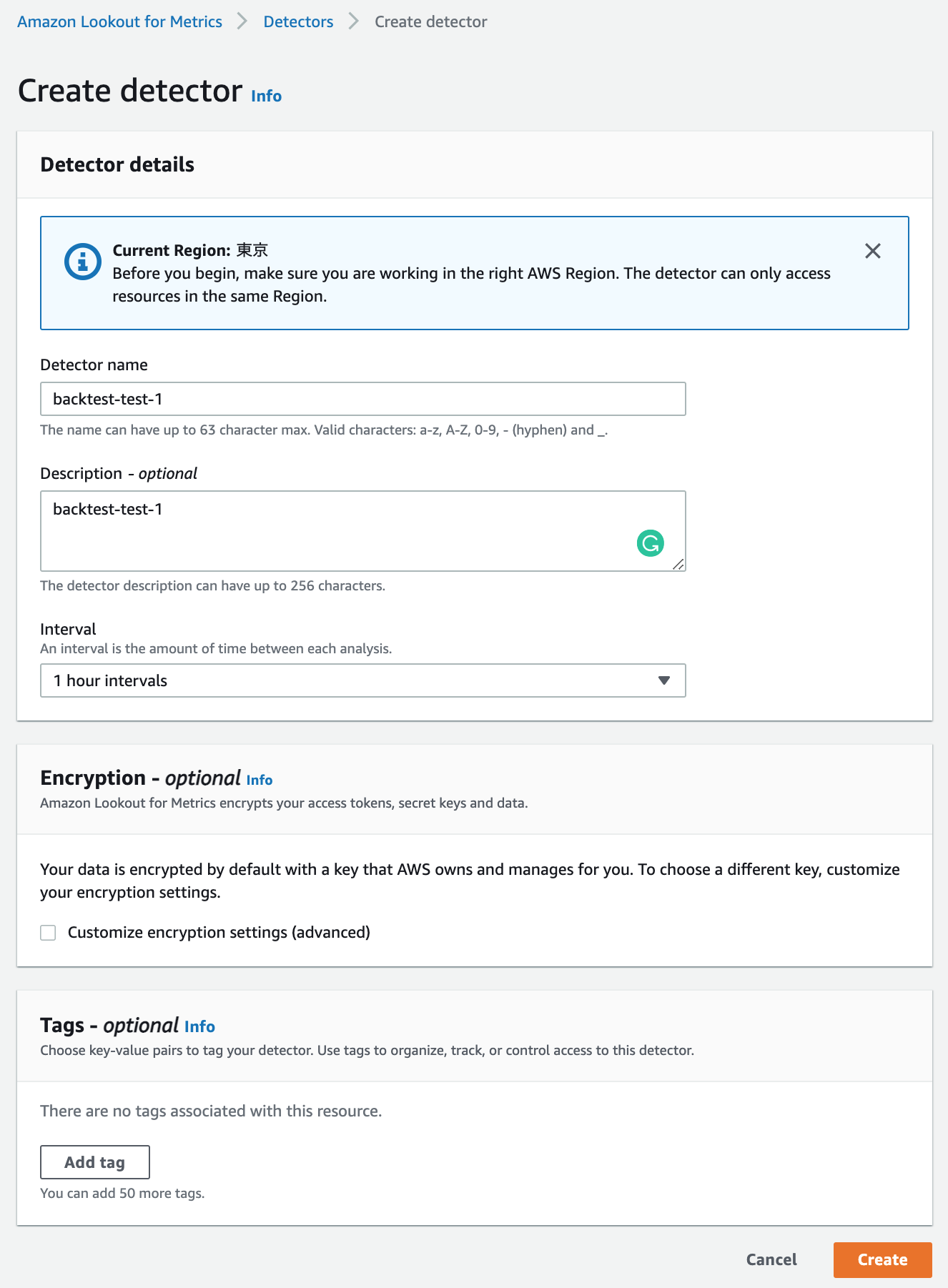
Interval項目はデータのタイムスタンプカラム値のインターバルと合致している必要がある。backtestモードで使用するS3のデータを確認してみよう。
timestampカラムの値が指定したInterval項目と同じ1時間間隔であることが確認できる。
s3://{S3バケット名}/ecommerce/backtest/input.csv
platform,marketplace,timestamp,views,revenue
pc_web,us,2021-01-01 00:00:00,298,89.39999999999999
pc_web,uk,2021-01-01 00:00:00,476,142.79999999999998
pc_web,de,2021-01-01 00:00:00,152,45.6
...
pc_web,us,2021-01-01 01:00:00,214,64.2
pc_web,uk,2021-01-01 01:00:00,380,114.0
pc_web,de,2021-01-01 01:00:00,125,37.5
...
pc_web,us,2021-01-01 02:00:00,148,44.4
pc_web,uk,2021-01-01 02:00:00,297,89.1
pc_web,de,2021-01-01 02:00:00,106,31.799999999999997
...
すべて入力後、 Createボタンを押すと検出器が登録される。
検出器にデータセットを追加し、異常検知を開始する
登録した検出器の詳細画面に遷移する。
Amazon Lookout for Metrics > Detectors > backtest-test-1
Add a datasetボタンを押す。
データソースの設定画面に必要な値を入力する。
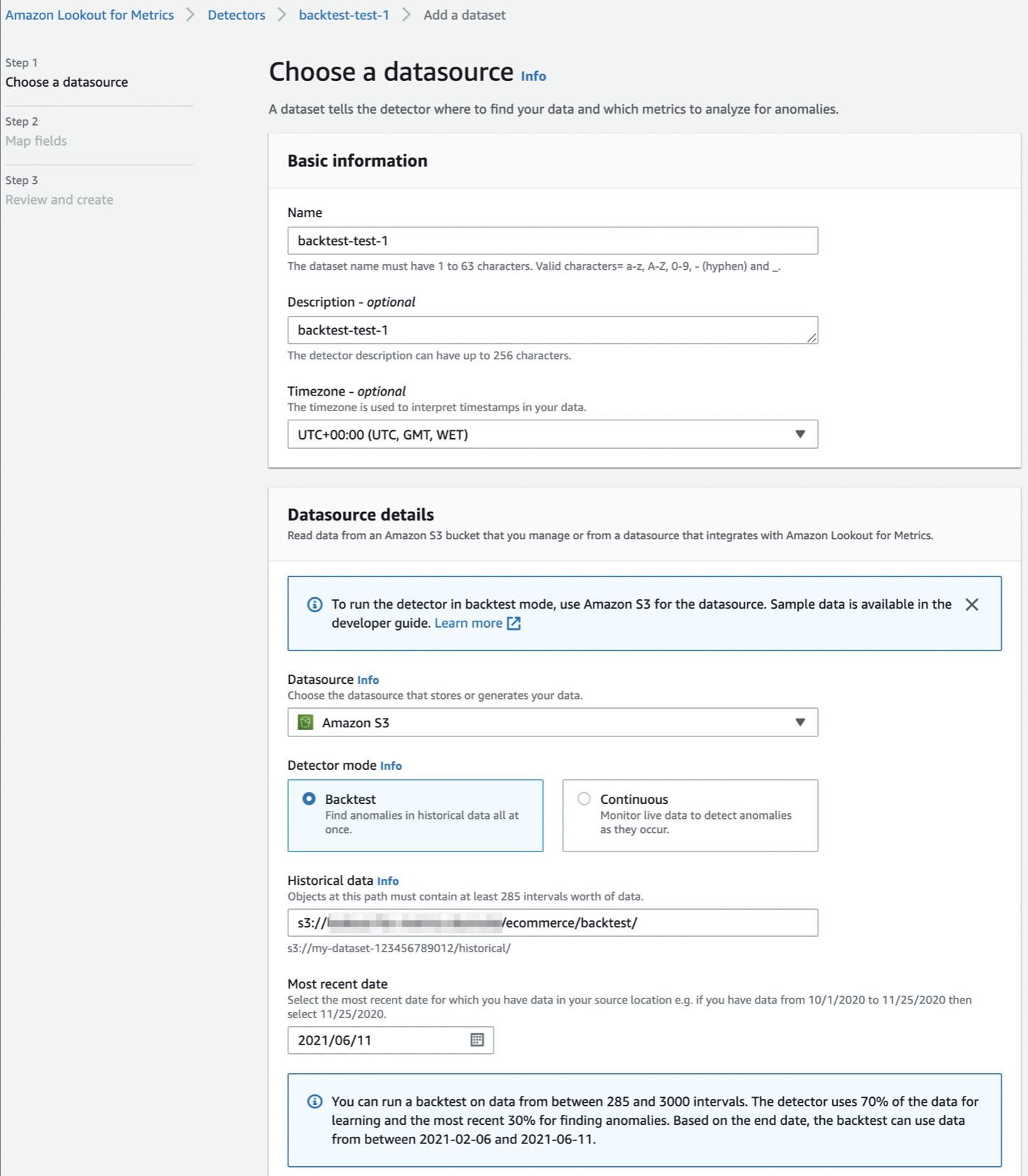
Historical data項目値には履歴データが存在するフォルダのS3オブジェクトキーを指定する。検出器はこのフォルダ内に在る1つ以上のデータファイルを読み込んで学習と推論を実行する。
s3://{S3バケット名}/ecommerce/backtest/input.csv
以下のように複数のデータファイルの指定も可能である。
s3://{S3バケット名}/ecommerce/backtest/20210104-20210110.csv
20210111-20210117.csv
20210118-20210125.csv
また、このデータには285〜3000インターバル分のデータが必要であることに注意する。今回は検出器作成時に1時間のインターバル指定をしたため、最低でも285時間分(12日分弱)のインターバルのデータが必要である。
念の為input.csvを確認してみると、2021/01/01〜2021/09/30 の期間で1時間インターバルのデータであることがわかる。
...
mobile_app,es,2021-09-30 23:00:00,265,79.5
mobile_app,it,2021-09-30 23:00:00,193,57.9
mobile_app,jp,2021-09-30 23:00:00,631,189.29999999999998
Permissions項目では Create a roleボタンを選択し、Create a service roleダイアログで作成したS3バケット名を指定する。他の項目はデフォルトのままでよい。
入力後にNextボタンを押すと、inputするデータのメトリクスとタイムスタンプカラムを指定する画面に遷移する。
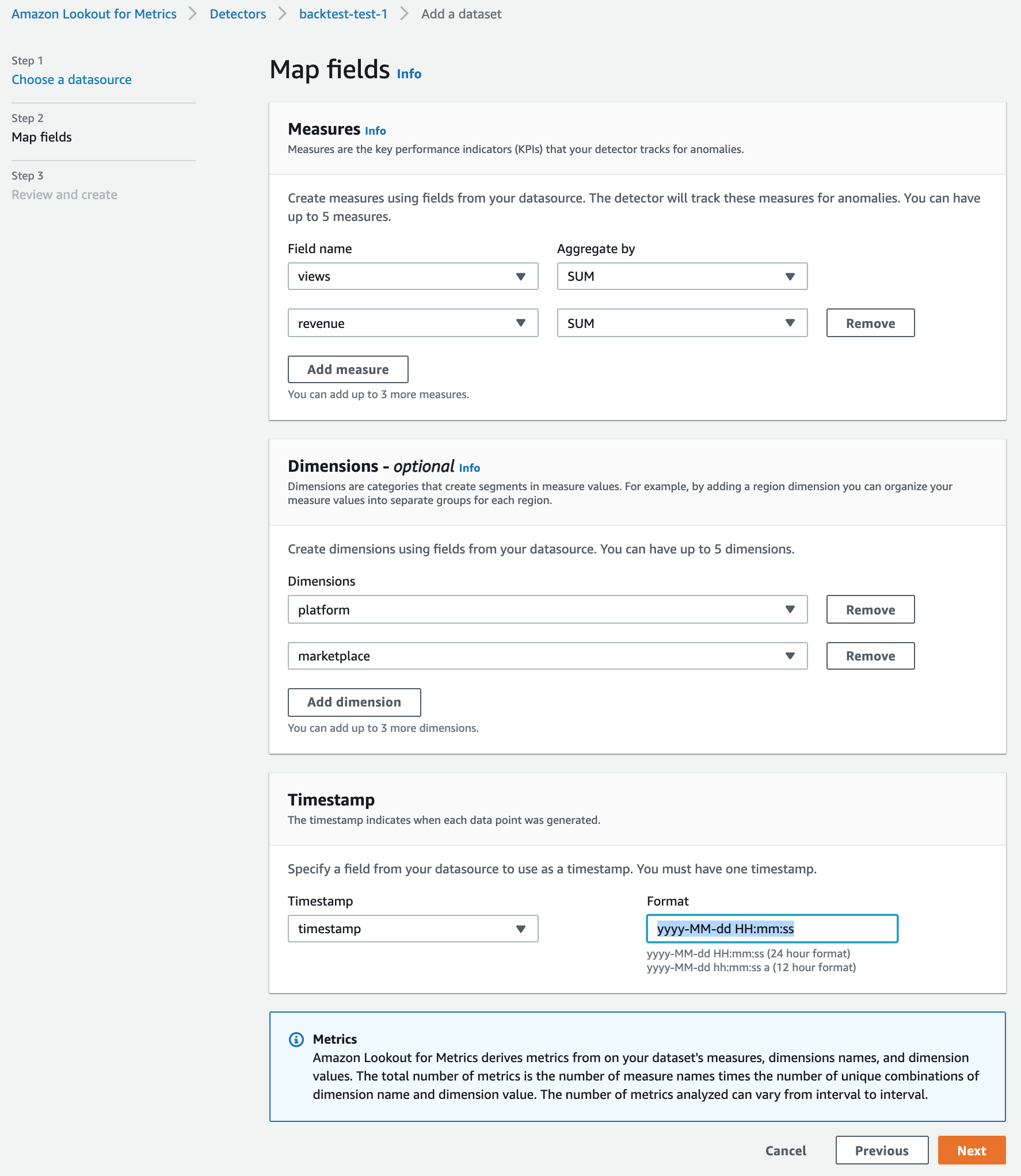
前編のデータセット項目にてメトリクスの説明をしたが、それはこの画面で設定をすることになる。
Measures欄には、データのカラムの中から異常検知の観測対象となる項目とその集計方法を選択する。集計とは、インターバル値ごとに区切られた複数のレコードの対象カラム値を観測対象値に変換する方法である。
例えば、データが以下の場合のことを考える。
platform,marketplace,timestamp,views,revenue
pc_web,us,2021-01-01 00:00:00,298,89.39999999999999
pc_web,uk,2021-01-01 00:00:00,476,142.79999999999998
pc_web,de,2021-01-01 00:00:00,152,45.6
...
pc_web,us,2021-01-01 01:00:00,214,64.2
pc_web,uk,2021-01-01 01:00:00,380,114.0
pc_web,de,2021-01-01 01:00:00,125,37.5
...
pc_web,us,2021-01-01 02:00:00,148,44.4
pc_web,uk,2021-01-01 02:00:00,297,89.1
pc_web,de,2021-01-01 02:00:00,106,31.799999999999997
...
Measures指定カラムをviewsカラムとrevenueカラムだとすると、検出器はSUM値の推移を観測対象とすることになる。
| タイムスタンプ値 | viewsカラムSUM値 | revenueカラムSUM値 |
|---|---|---|
| 2021-01-01 00:00:00 | 926 | 277.78 |
| 2021-01-01 01:00:00 | 719 | 215.7 |
| 2021-01-01 02:00:00 | 551 | 165.29 |
Dimensions欄には、データセットのレコードを分割するための指標となるカラムを指定する。
今回のデータを観察してみると、platform(PC / モバイル)とmarketplace(市場)という2つの指標でレコードが作成されているらしいことがわかる。これは、元データを観察した機械学習エンジニアが、プラットフォームと市場というファクターで元データを集計することが異常検知の精度向上につながると仮説をたてて前処理をし、このデータを作成したことを意味する。
入力後、Nextを押す。
最終確認画面にてSave and activateボタンを押すと、指定したデータソースを使った学習が開始される。backtestモードではデータの最初の70%を学習に、30%を推論(異常検知)に使用する。処理時間は数十分ほどかかる。
Detector一覧を確認してみる。
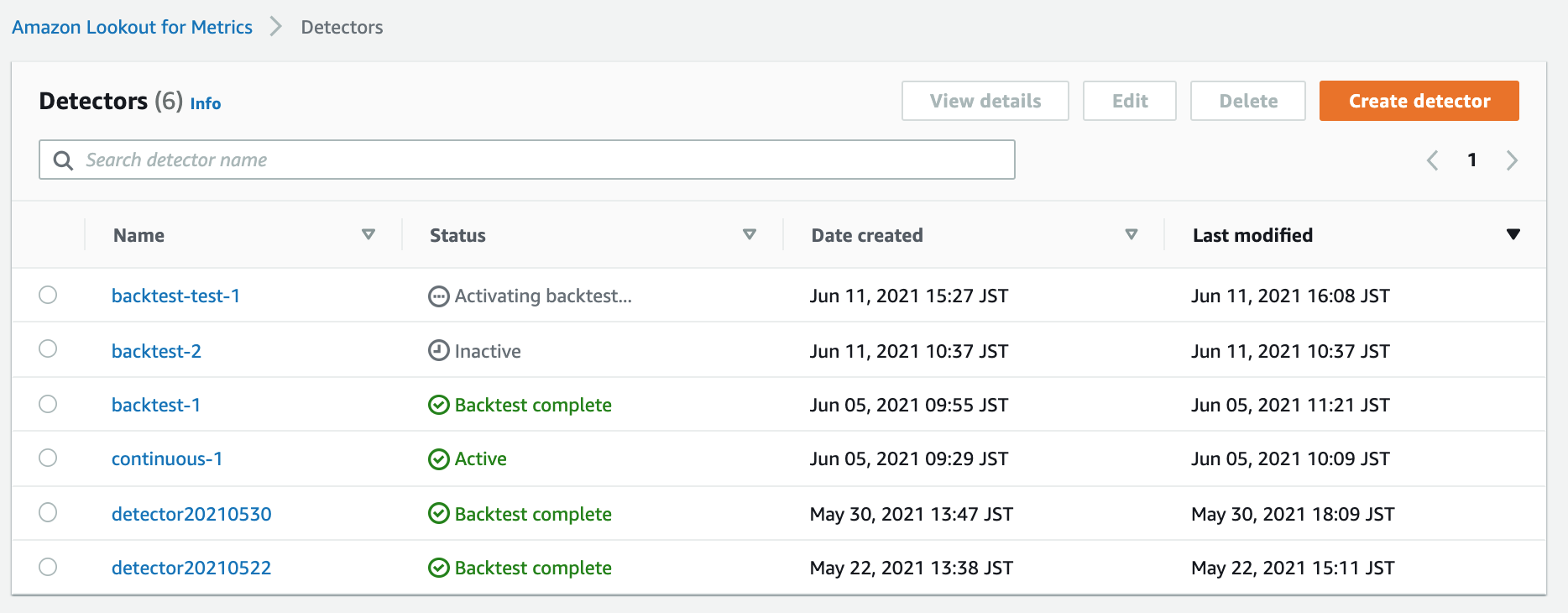
StatusがBacktest in progressとなったら学習が完了して推論が開始されている。異常を検知したら順次この一覧にリストアップされていく。もしアラートを設定していた場合は都度通知が実行される。
異常検知結果を確認する
リストアップされた異常検知結果を確認してみる。
Amazon Lookout for Metrics > Detectors > backtest-test-1 > Anomalies
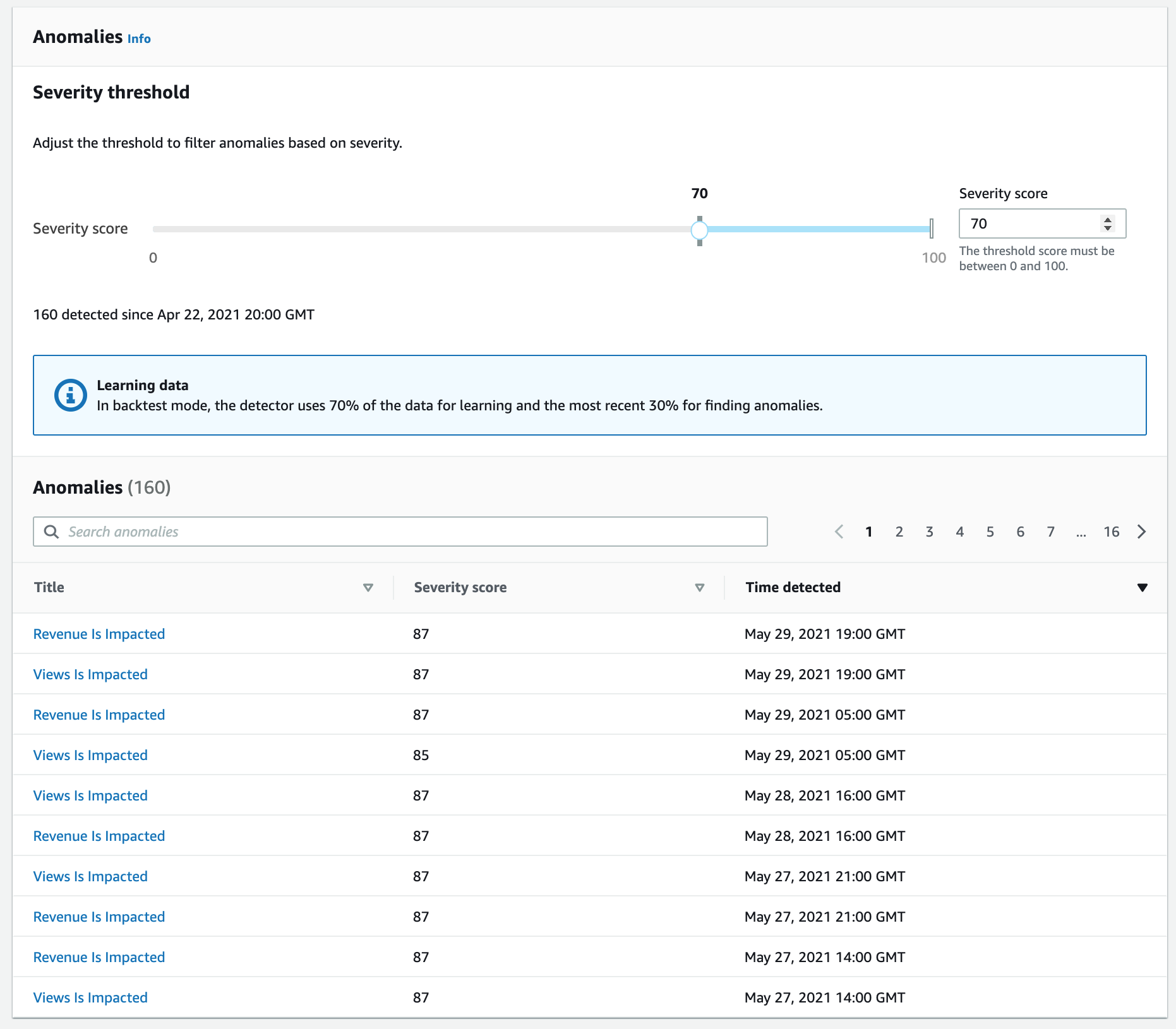
検出した異常がリストアップされている。各異常にはSeverity score(重大度スコア)という値が算出されており、一覧上部のスライダーで絞り込みが可能である。
Title列をクリックして各異常の詳細内容を確認してみる。
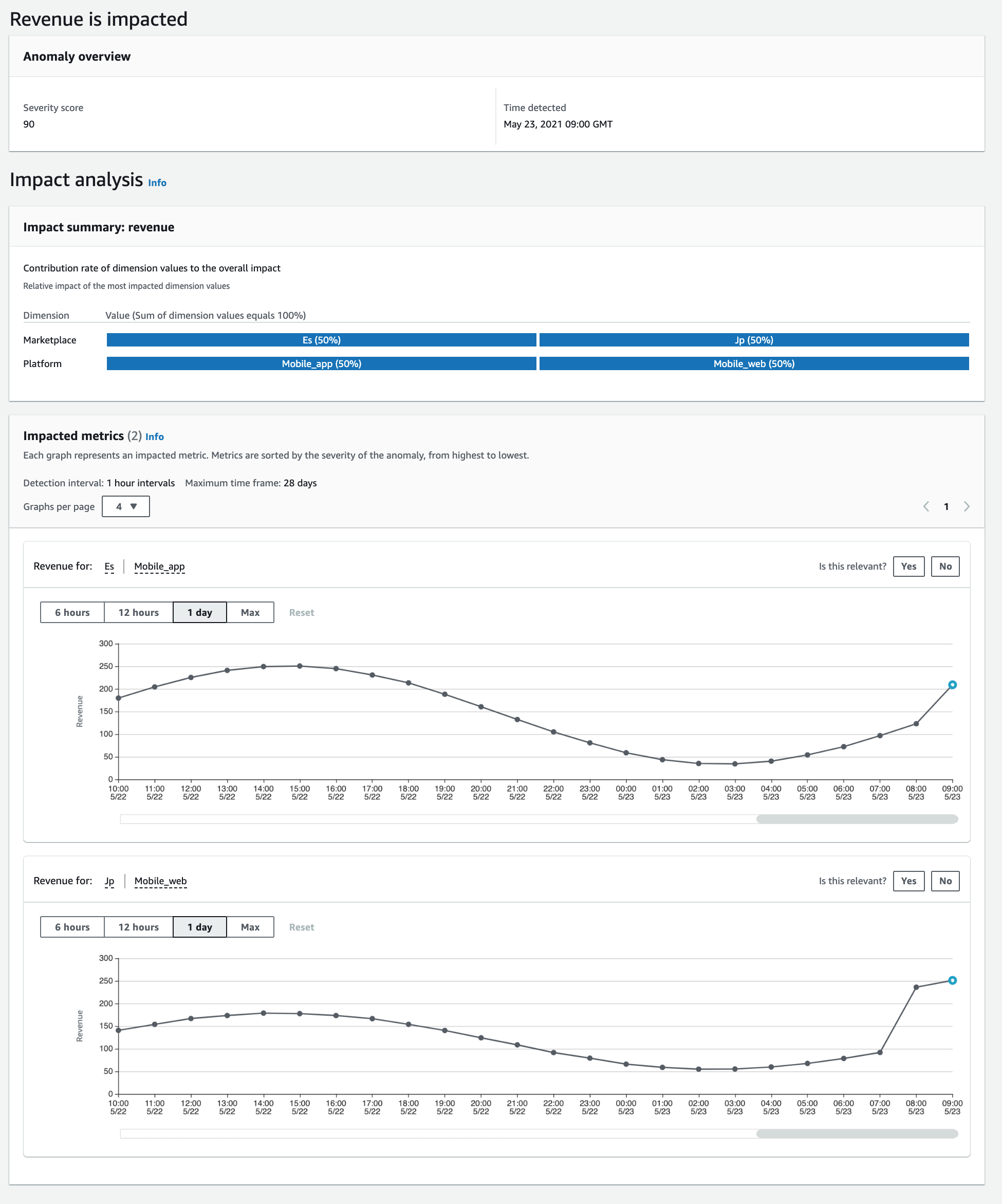
Measures指定カラムの観測値が推移していくなかで、検出器が異常と判定したタイミングで抽出されている。多くの異常は単一ディメンションで構成されているが、中には上記のように複数要因が絡んでいるものもある。
この例では、スペインと日本の両国でモバイルAPPの売上が急激に伸びていることを検知している。
グラフ右上の Is this relevant? のYes/Noボタンを押すと、検出器にこの異常検知結果についての関連性をフィードバックすることができる。
実験2. continuousモードで異常検知システムを運用する
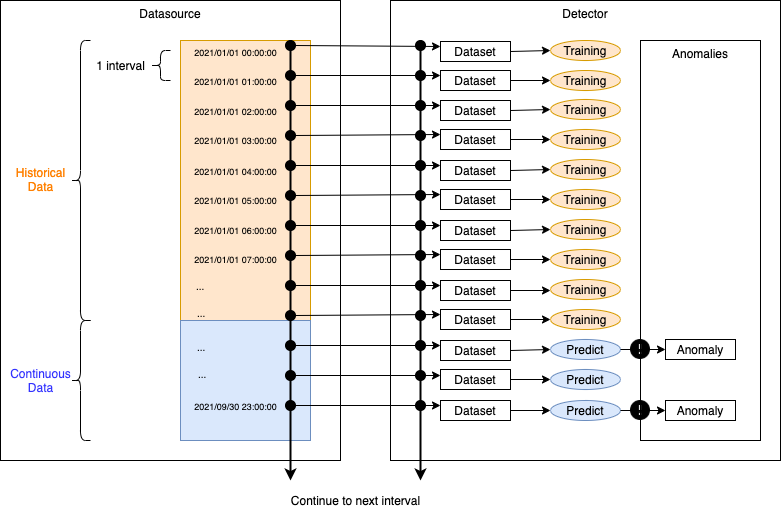
S3をデータソースとして履歴データと連続データを設置し、異常検知の運用を開始するまでの手順を確認してみる。
手順としては、データソースの選択欄でcontinuousモードのための設定をする以外は同じである。
データソースを用意する
データソースはすでにS3にアップロードしてあるのでそれを使う。
検出器を作成する
同じ手順で問題ない。Interval項目では 1 hour intervals を選択しておく。
検出器にデータセットを追加し、異常検知を開始する
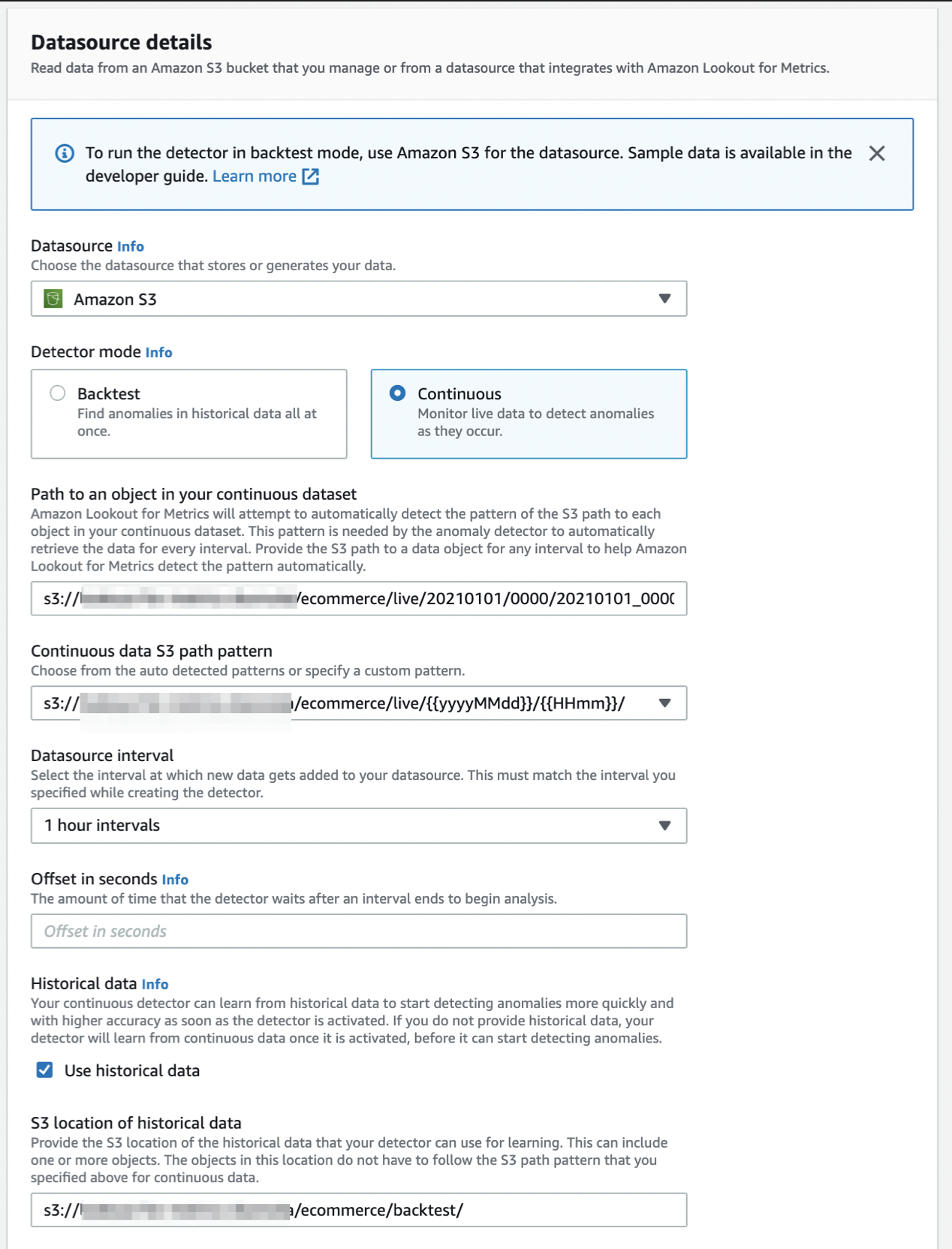
Detector mode項目で、Continuousモードを選択する。
Path to an object in your continuous dataset項目には、最初に読み込ませる連続データファイルのS3オブジェクトキーを選択しておく。
s3://{S3バケット名}/ecommerce/live/20210101/0000/20210101_000000.csv
そうすると、Continuous data S3 path pattern項目にて検出器に読み込ませるデータのパスのフォーマットが自動で選択肢に出てくる。パスの後ろが{{yyyyMMdd}}/{{HHmm}}のパスを選択する。検出器はこのフォーマット指定をもとにしてデータファイルをタイムスタンプ値の順番にinputするため、間違えないように注意すること。
Datasource interval項目では、検出器で指定したものと同じ 1 hour intervals を指定する。
Historical data項目はオプションである。backtestモードで指定したものと同じ履歴データファイルがあるフォルダのS3オブジェクトキーを指定しておこう。こうしておくと、検出器はまずこの履歴データで学習をしてから連続データで推論をするようになる。
もし未指定の場合、検出器は連続データの最初の285インターバル分のデータを使用して学習をし、それから推論(異常検知)をしていく。その分だけ推論の開始が遅れることになるため、基本的には指定をしておいたほうがよい。
異常検知結果を確認する
backtestモードと同様に、学習が終わった後に随時異常検知のリストアップを実行していく。
continuousモードでは、データソースに継続的にデータが出力されることを前提としているため、データソース側にもデータ出力のための仕組みが必要となる。仮に検出器がデータソースからデータを読み込めない場合にはエラーが発生する(この時、欠落データとしてそのまま処理を進めるのか、処理がストップするのかは未検証)。
検出器は指定インターバルごとにデータソースからデータをコピーしてデータセットを作成し、推論を実行する。異常検知結果でのフィードバックをすることにより、異常検知の精度を高めていくことが可能である。
リソースをクリアする
一通り確認し終わったら、不要な課金をされないようにリソースを削除する。
- Detector一覧でStatusが
Backtest completeとなった検出器をDeleteする。 - S3のバケットの中身を削除し、バケットを削除する。
所感
機械学習で最も労力を要するデータの前処理を楽にすることはできないが、それさえクリアできれば後は Lookout for Metrics がよろしくやってくれる。また、異常検知の通知や情報取得はSNSやLambdaでできるので、システムのUIも比較的簡単に構築できるという利便性は高いと思う。
Lookout for Metrics の処理プロセスは完全ブラックボックスであり、良くも悪くも開発エンジニアは関与できない。逆に言うと Lookout for Metrics で精度を高めるためのデータ前処理にだけ集中できるため、割り切って使うならばAWSに不慣れな機械学習エンジニアでもPoC案件で使用できると思われる。
いつくか注意点を挙げるとすれば、メトリクス数の制限とベンダーロックインだろうか。
現状では、Dimensions項目とMeasures項目を指定できるのはそれぞれ最大5つまでとなる。また、構築された検出器(異常検知モデル)のエクスポートはできないので、ベンダーロックインが許されない案件では使うことができないことに注意が必要である。
AWS SDKが用意されているので、データ前処理がうまく行って精度の良い検出器を作れれば、システムに組み込むことは容易にできるはず。
今回はできなかったが、いずれはAmazon AppFlow経由で外部データソースをinputするケースを試してみたい。