この記事はNTTドコモソリューションズ Advent Calendar 2025 16日目の記事です。
はじめに
NTTドコモソリューションズの管です。
システム設計から開発・運用まで幅広い経験を持つ、キャリア8年目のフルスタックエンジニアです。最新技術に強い関心を持ち、現在はAIサービス開発チームのテックリーダーを務めています。
きっかけ
現在、私たちのチームでは AIを活用した自社サービスの開発を検討しています。しかし、まだ「完成形」と呼べる AI サービスは存在せず、将来的な拡張や技術変更に柔軟に対応できる設計が求められています。
業務遂行中に、「AIを使ったサービスを作りたい。でも、どんなアーキテクチャで設計すればいいんだろう?」という課題を持っています。
特に AWS 基盤との組み合わせを考えると、以下のような疑問が浮かんできました:
- Layered、Hexagonal、Clean Architecture… 名前は聞いたことあるけど、違いは何?
- AWS のようなクラウド環境と相性の良いアーキテクチャはどれ?
- 将来の変更に強く、長期的に保守しやすい設計とは?
この記事では、これらの疑問に答えるべく、主要な 3つのアーキテクチャパターンを比較・整理し、AWS 環境での実践的な設計指針を示します。
アーキテクチャ選定で迷っている方、特にクラウドネイティブな AI サービスを構築しようとしている方の参考になれば幸いです。
この記事で明らかにすること
- 各アーキテクチャ(Layered / Hexagonal / Clean Architecture)の内容とその違いを整理したい
- AWS を含めたインフラ基盤と相性の良いアーキテクチャはどれか検討したい
- アプリ構成の設計方針、メリットを明らかにしたい
検討内容
Layered Architecture(分層アーキテクチャ)
以下は階層分布イメージです。
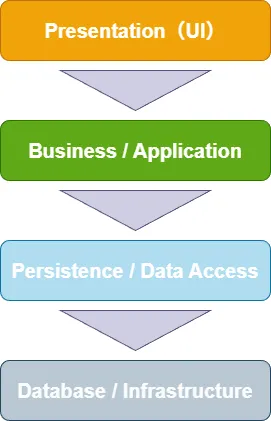
サービスプロセスの基本イメージ
以下はAPIサービスを例として、各層の役割を明記したユースケース図です。
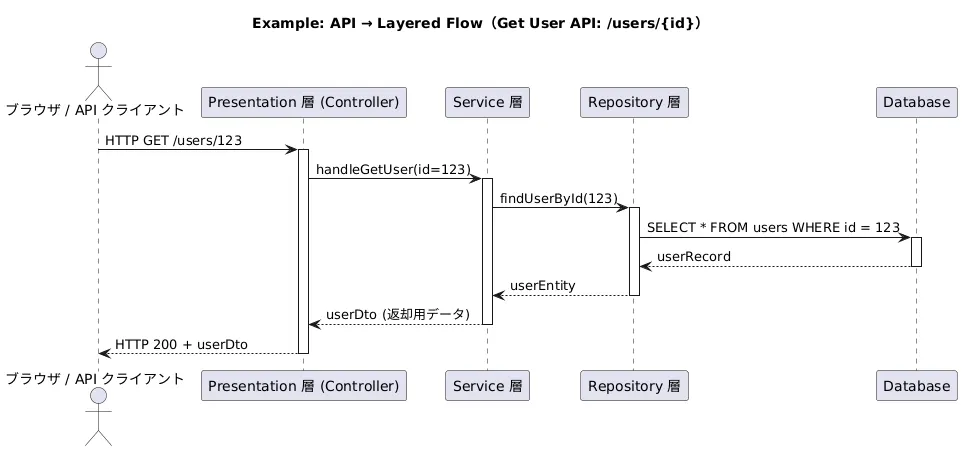
上記の図のように、ソフトウェアシステムを複数の水平な層に分割する設計パターンです。各レイヤーが特定の責任・役割を隣接する層とだけ通信するように構成されます。
この設計により、機能の分離を考慮したシステム設計により、モジュール性、可読性、保守性が向上します。
各層の役割
| レイヤー | 主な役割 |
|---|---|
| Presentation(UI) | ユーザーとの入出口(ブラウザ、モバイルアプリ、Web UI、画面レンダリング、入力バリデーションなど) |
| Business / Application | アプリケーションのビジネスロジック、業務処理、入力の受け渡し、データの加工やビジネス制約の実行など |
| Persistence / Data Access | DB への CRUD、ORM、リポジトリ層、キャッシュやストレージアクセスなど |
| Database / Infrastructure | 実際のデータ保存 (RDB / NoSQL / ファイル / ストレージ)、外部サービスとの接続、インフラ技術に関する部分 |
ディレクトリ構成例
今回のプロジェクトでは、TypeScript を利用した Node.js フレームワークを採用します。
project-root/
├── src/
│ ├── presentation/ ← UI 層 / API 層
│ │ ├── controllers/ ← HTTP ハンドラ / エンドポイント定義
│ │ ├── routes/ ← ルーティング (Express / Fastify / etc.)
│ │ └── dto/ ← リクエスト/レスポンス用 DTO 型定義
│ │
│ ├── application/ ← Business / Application 層 (ユースケース・サービス層)
│ │ ├── services/ ← ビジネスロジック実装
│ │ └── usecases/ ← ユースケース単位で整理 (オプション)
│ │
│ ├── persistence/ ← Persistence / Data Access 層
│ │ ├── repositories/ ← リポジトリ (データ取得・保存ロジック)
│ │ └── models/ ← ORM モデル/スキーマ定義 (例: TypeORM, Prisma, Sequelize など)
│ │
│ ├── infrastructure/ ← Database / Infrastructure 層
│ │ ├── db/ ← DB 接続設定、初期化、マイグレーション、接続プールなど
│ │ └── config/ ← 環境変数、共通設定、ログ設定 など
│ │
│ └── common/ ← 共通ユーティリティ (エラーハンドリング, ログ, 共通型 など)
│
├── tests/ ← テストコード (ユニット/統合テスト)
├── scripts/ ← ビルド/マイグレーション/補助スクリプト
├── package.json
メリット/デメリットの比較
| 区分 | 内容 |
|---|---|
| メリット | - 初学者にも分かりやすい - テンプレートや実例が豊富で学習コストが低い - 短期間、小規模開発、シンプル機能には十分 |
| デメリット | - 最下層がインフラ / DB なのでインフラ依存が強い - ドメイン(ビジネスロジック)が DB や外部 API の設計に引きずられやすい - 長期運用や仕様変更が多いと、サービス層や Repository 層が肥大化しやすい |
Layered Architecture はシンプルな機能を持つシステムに適した設計です。しかし、世の中の激しい変化に対応する必要がある AI サービスにとっては不十分であり、より柔軟性の高い他のアーキテクチャ設計手法を検討する必要があります。
Hexagonal Architecture(Ports & Adapters)
Onion Architectureの思想と同じような実装方法がより明確になったHexagonal Architectureを検討しておきます。
Hexagonal Architecture は、アプリケーションのコアを外部依存から完全に切り離すための実践的な設計モデルです。
基本コンセプト
このアーキテクチャは Alistair Cockburnによって提唱され、Ports and Adapters という別名でも知られています。
核となる考え方は以下の通りです:
- 中心 (Core):ドメインロジック・ビジネスルールを含むアプリケーションの本質部分
- 外部との接続:すべての外部システム (DB、UI、外部 API、メッセージキューなど) は、Port (抽象インターフェース) と Adapter (具体的な実装) のペアを経由して接続
Port と Adapter の役割
| 要素 | 説明 |
|---|---|
| Port (ポート) | アプリケーションコアと外部をつなぐ「抽象的な契約」。インターフェースとして定義され、技術的な詳細には依存しない。 |
| Adapter (アダプター) | Port で定義されたインターフェースを、具体的な技術 (HTTP、データベース、外部サービスなど) で実装したもの。 |
この構造により、外部技術の変更がアプリケーションコアに影響を与えない設計が実現できます。
以下はモデル構造イメージです。
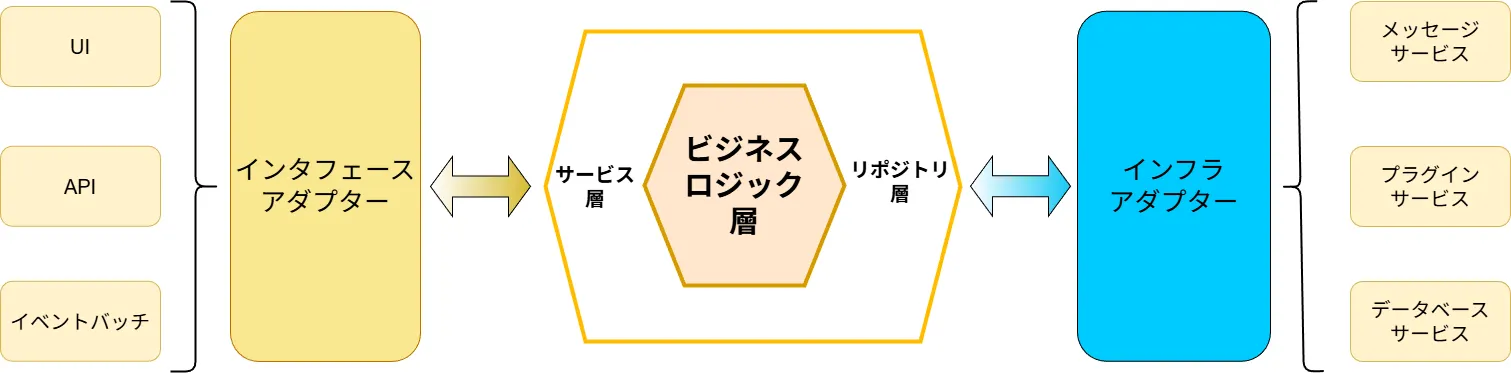
プロセスの基本イメージ
次に、シーケンス図に基づいて、具体的に各層の役割を説明します。

| 要素 | 説明/ 目的 |
|---|---|
| Core / Domain部分 (アプリケーションの中心) | ビジネスルールやドメインロジック、ユースケース、ドメインモデルを扱い、UI・DB・外部 API などの外部要素から独立した、ピュアなロジック層となる。 |
| Ports部分 (ポート/インターフェース層) | Core と外部システムを結びつけるための抽象的なインターフェース(契約)で構成される。これらは、外部からの入力を受け取る Inbound Port / Driving Port(例:HTTP API、CLI、Webhook、テスト用呼び出し)と、外部へ処理を委ねる Outbound Port / Driven Port(例:データ保存、外部 API の呼び出し、メッセージ送信)に分類される。 |
| Adapters部分 (アダプター / 実装層) | Ports で定義されたインターフェースを、実際の技術要素(HTTP サーバ、データベースクライアント、外部サービス向けライブラリ、メッセージキュー、テスト用モックなど)に結びつけて動作させるための実装層。たとえば、HTTP リクエストを Inbound Port に渡す実装や、ORM を使って Outbound Port を実現する実装などが該当する。 |
なぜこの構造が有用なのか
- インフラやフレームワークに依存しないロジック設計
- テストしやすさ
- 柔軟な拡張性・保守性
- 技術ロックインの回避
Hexagonal Architecture は、以下のような要件・環境で特に有効とされる:
- Web API + 複数の入出力 (HTTP, CLI, バッチ, メッセージなど) を持つシステム
- DB や外部サービスが頻繁に変わる、あるいは将来変わる可能性があるシステム
- テスト重視、CI での自動テスト、モック/スタブによるドメインロジックの検証が必要なプロジェクト
- 複数クライアント (Web, CLI, バッチ, 外部システム) を想定する汎用サービス
これで理想的なアーキテクチャを見つけました。しかし、好奇心旺盛なエンジニアとして、さらに優れた方法がないか考えてみました。次は、各層の責任範囲と依存関係の方向をより明確に定義した Clean Architecture について見ていきましょう。
Clean Architecture(クリーンアーキテクチャ)
Robert C. Martinが提唱した、Hexagonal や Onion Architecture の優れた要素を取り入れた比較的新しい設計思想。
中心となる考え方は 「依存性は内向きのみ(Dependencies only inward)」 というルールで、
ドメイン層やユースケース層を内側に、インフラ層や UI 層を外側に配置する構造をとります。
プロセスの基本イメージ
次に、シーケンス図を基づいて、具体的に各層の役割を説明します。

| レイヤー名 | 役割 |
|---|---|
| Entities(エンティティ) | ビジネスルールやドメインモデルを表す。データ構造 + ビジネスロジック。データベースや UI に依存せず、ビジネスの “本質” を担う |
| Use Cases / Application Business Rules | ユースケース (アプリケーション固有の振る舞い) を定義。エンティティを使って、ユーザー操作やシステム操作によるビジネスの流れを実装。ビジネスロジックの “操作” レイヤー |
| Interface Adapters(インターフェースアダプター層) | 外部(UI、DB、外部サービス、フレームワークなど)と Use Cases/Entities をつなぐ変換層。 コントローラー、ゲートウェイ、プレゼンター、DTO/マッピングなどを含み、外部と内部のモデル/インターフェースの差異を吸収 |
| Frameworks & Drivers(インフラ/外部ドライバ層) | 具体的な実装(Web フレームワーク、DB、外部サービス、UI、メッセージキューなど)。最も外側・最も “変化しやすい” 層。インフラ/技術仕様の影響が限定されるよう、他レイヤーからは遠ざけられる |
レイヤー間の流れのイメージ — “何がどこで走るか”
- ユーザーやクライアント (Web UI / API / CLI / バッチ など) が Interface Adapters(例:コントローラー)を呼び出します。
- コントローラーは入力値を受け取り、Use Case を実行します。
- Use Case は Entities を操作してビジネスロジックを実行
- 永続化や外部 API 呼び出しが必要な場合、Use Case 経由で Interface Adapters → Infrastructure (DB / 外部サービス) を使って実装
- 結果・レスポンスは再び Adapter 層で整形され、ユーザーに返される
この流れにより、ビジネスロジック (エンティティ + ユースケース) は外部の影響 (フレームワーク、DB、UI) を受けず、きれいに切り離されます。
Clean Architecture の強み・狙い
- 技術の独立性
- テスト容易性
- ソフトウェアの寿命と保守性
- 関心の分離 (SoC)
各アーキテクチャの使い分け(どれを選ぶべきか)
| シチュエーション / 要件 | おすすめのアーキテクチャ |
|---|---|
| 短期間・小規模・CRUD 中心で、仕様変更少なめ | Layered Architecture |
| 外部 API、多様な入出力(Web / メッセージ / バッチ)、クラウド / サーバレスで拡張性・差し替え性が必要 | Hexagonal Architecture |
| 将来的な拡張、インフラ・フレームワーク変更、複数 UI や異なる実装形式に耐えたい中〜大規模サービス | Clean Architecture |
クラウドサービス × 現代アーキテクチャ — なぜ Hexagonal / Clean が相性良いのか
-
インフラやサービスを差し替えやすい
例:AWS は多様なサービス (RDS, DynamoDB, S3, SQS, Lambda, API Gateway など) を提供し、要件やスケールに応じて使い分けやすい。Hexagonal/Clean なら、これらを Adapter に落とし込めば、たとえば「RDS → DynamoDB」「REST API → メッセージキュー」「オンプレ DB → マネージド DB」など 基盤構成の変更にドメインロジックを侵さず対応しやすいです。 -
テスト & モックが容易
ドメイン (ビジネスロジック) を外部依存から切り離すため、外部サービス (DB, 外部 API, AWS SDK など) をモック/スタブで置き換えてユニットテストできる。これにより、CI や自動テストパイプラインを整備しやすくなります。 -
拡張性・将来の変更耐性
ドメインとインフラ/外部インターフェースの境界が明確なので、新しい機能、外部連携、サービス分割、マイクロサービス化などを後から導入しやすい。例えば AI/外部 API 多用のような複雑なドメインでも柔軟に対応可能です。 -
ドメイン中心設計 (DDD 等) との親和性
AWS に限らず、ドメインのロジックをビジネスルールとして明確に保ちたい場合、Hexagonal/Clean の構造は非常に自然。一貫したドメインモデルと、外部実装の分離が保てます。
設計方針の結論
最終的には Clean Architecture をベースに、実装には Hexagonal(Ports & Adapters)を採用しました。
ディレクトリ構成例
src/
├─ domain/ ← エンティティ、ドメインモデル
├─ usecase/ ← アプリケーションロジック / ユースケース
├─ port/ ← インターフェース (Ports)
│ ├─ in/ ← 入力 (API, CLI, バッチなど) 用
│ └─ out/ ← 出力 (DB, 外部 API, メッセージキューなど) 用
├─ adapter/ ← Port の具体実装 (Adapters)
│ ├─ api/ ← REST / GraphQL / Lambda ハンドラなど
│ ├─ db/ ← DB(DynamoDB / RDS など)の実装
│ └─ external/ ← 外部サービス API, メッセージ, ストレージ などの実装
└─ infrastructure/ ← AWS SDK 初期化、設定、DI コンテナなど(独立べき)
この構成のメリット
将来的に以下のような変更があっても、ドメイン(ビジネスロジック)をほとんど破壊せず対応可能:
- DB を DynamoDB → RDS に変更
- HTTP API → メッセージ / バッチ処理に切り替え
- 外部 Oracle / API を別サービスへ差し替え
まとめ
- Layered / Onion / Hexagonal / Clean いずれも一長一短。目的と要求(スケール性 / 拡張性 / 保守性など)に応じて適切に使い分けるべき
- Web3 / DeFi / AI / クラウド(AWS)のような、外部依存や将来的な仕様変更が多い環境では、Hexagonal or Clean Architecture が特に有効
- Clean Architecture + Hexagonal のハイブリッド構成を設計方針として採用
この記事が、「モダンな AI / クラウドサービスを作るためのアーキテクチャ選定」の第一歩になれば幸いです。
記載されている会社名、製品名、サービス名は、各社の商標または登録商標です。