この記事について
数回に分けてGCPの無料枠でできることを紹介しています(前回記事はこちら)。無料枠の内容は変更になる可能性があるのと、従量課金のものは制限を超えると課金されたりもするので、公式の情報を確認しつつ自己責任でご利用ください。
今回のゴールはCompute EngineにインストールしたApache Airflow(以下Airflow)からCloud Functionsを実行することです。 少し変わった構成かもしれませんが、私は実際にこの構成でTwitterでの情報収集・発信を自動化しています(こちら) →2020/10/24追記:このbotは停止しました。
ちなみに、以下の理由でこの構成に落ち着きました。お金がある人は素直にCloud Composerを使いましょう。
- 無料でAirflowを使うには、f1-micro(Compute Engineの無料枠)にインストールするしかないと思った
- Airflowを起動するとf1-microのメモリに余裕がないため、Cloud Functionsをフル活用するしかないと思った
各サービスの簡単な紹介
Cloud Functions
サーバーレスでコードを実行できるGCPのサービス。今回はHTTPリクエスとに応じて、Pythonのコードを実行します。ほかにもCloud Pub/Subから実行したり、Python以外のコードを実行することもできます。
Compute Engine
GCPの仮想マシン。無料枠だとf1-microというマシンタイプを使うことができる(ただしメモリが0.6GBとスペックは控えめ)。OSもUbuntu・Debian・CentOSなどの中から選べる。
Airflow
もとはAirbnbで開発された、ワークフローを管理するフレームワーク。cronの強化版みたいなイメージだが、以下のような点で優れている。
- エラーが出ても任意の回数、任意の時間をおいて再実行できる
- タスク間の依存関係をDAG(有効非巡回グラフ)という形で指定できる
GCPにはCloud Composerというサービスが無料枠がなさそうなので、今回は無料枠のCompute Engineに自分でインストールする。
Cloud Functionsの設定
ここでは、以下2つのFunctionsを作成します。
- 明日の天気をAPIから取得してCloud Storageに保存
- Cloud Storageから明日の天気を取得し、LINE Notifyで通知
準備するのは以下の2ファイルです。普通は関数ごとにファイルを分けると思いますが、今回は簡単にmain.pyもrequirements.pyも2つのFunctionsで共通にしてしまいます。
- main.py
- requirements.py
まずmain.pyの内容は以下の通りです。LINE Notifyについてはこちらの記事をなどをご覧ください。
import requests
import json
import datetime
from google.cloud import storage
# function1... 明日の天気をAPIから取得してCloud Storageに保存
def function1(request):
url = "http://weather.livedoor.com/forecast/webservice/json/v1"
payload = {"city": 130010} # 東京
res = requests.get(url, params=payload)
res_json = json.loads(res.text.replace("\n", "")) # "\n"がエラーを起こすので置換
tomorrow = datetime.datetime.now() + datetime.timedelta(days=1)
forecast = [x for x in res_json["forecasts"] if x["date"] == tomorrow.strftime("%Y-%m-%d")][0]
client = storage.Client()
bucket = client.get_bucket("xxxxx") # 自分のbucketを作成して置き換えてください
blob = bucket.blob("forecast.json")
blob.upload_from_string(json.dumps(forecast))
# function2... Cloud Storageから明日の天気を取得し、LINE Notifyで通知
def send_message(msg):
url = "https://notify-api.line.me/api/notify"
token = "xxxxx" # 自分のトークンに置き換えてください
payload = {"message": msg}
headers = {"Authorization": "Bearer {}".format(token)}
requests.post(url, data=payload, headers=headers)
def function2(requests):
client = storage.Client()
bucket = client.get_bucket("xxxxx") # 自分のbucketを作成して置き換えてください
blob = bucket.blob("forecast.json")
forecast = json.loads(blob.download_as_string())
send_message(forecast["telop"])
次に、requirements.txtは以下のようにします。
requests==2.22.0
google-cloud-storage==1.26.0
ここまで来たら、main.pyとrequirements.txtがあるディレクトリで以下を実行してデプロイします。--ingress-settings internal-onlyで外部からのHTTPリクエストを禁止するのがポイントです。後で作成するCompute Engineからは問題なくリクエストできます。
gcloud functions deploy qiita_function1 --entry-point function1 --runtime python37 --trigger-http --ingress-settings internal-only --allow-unauthenticated
gcloud functions deploy qiita_function2 --entry-point function2 --runtime python37 --trigger-http --ingress-settings internal-only --allow-unauthenticated
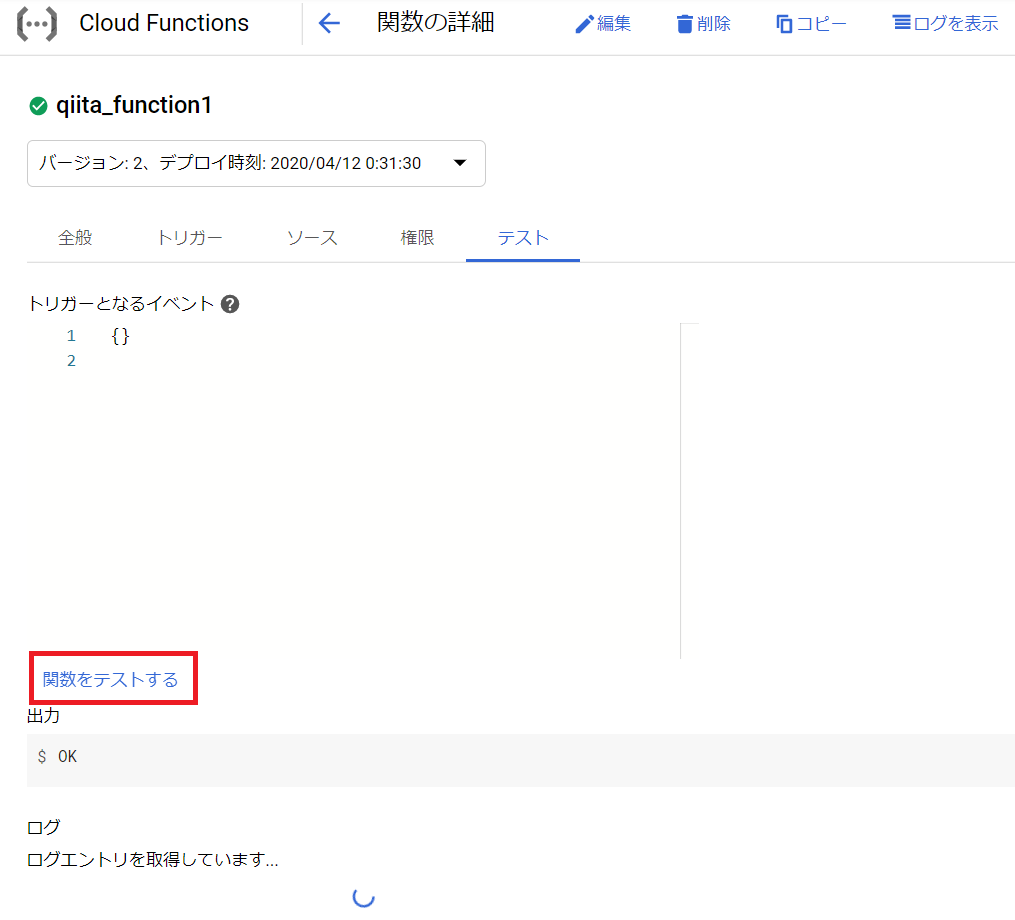
実際に動くかはCloud Functionsのコンソールから動かしてみましょう。トリガーとなるURLもご確認ください(https://us-central1-<PROJECT>.cloudfunctions.net/qiita_function1のような形式です)。
Airflowの導入
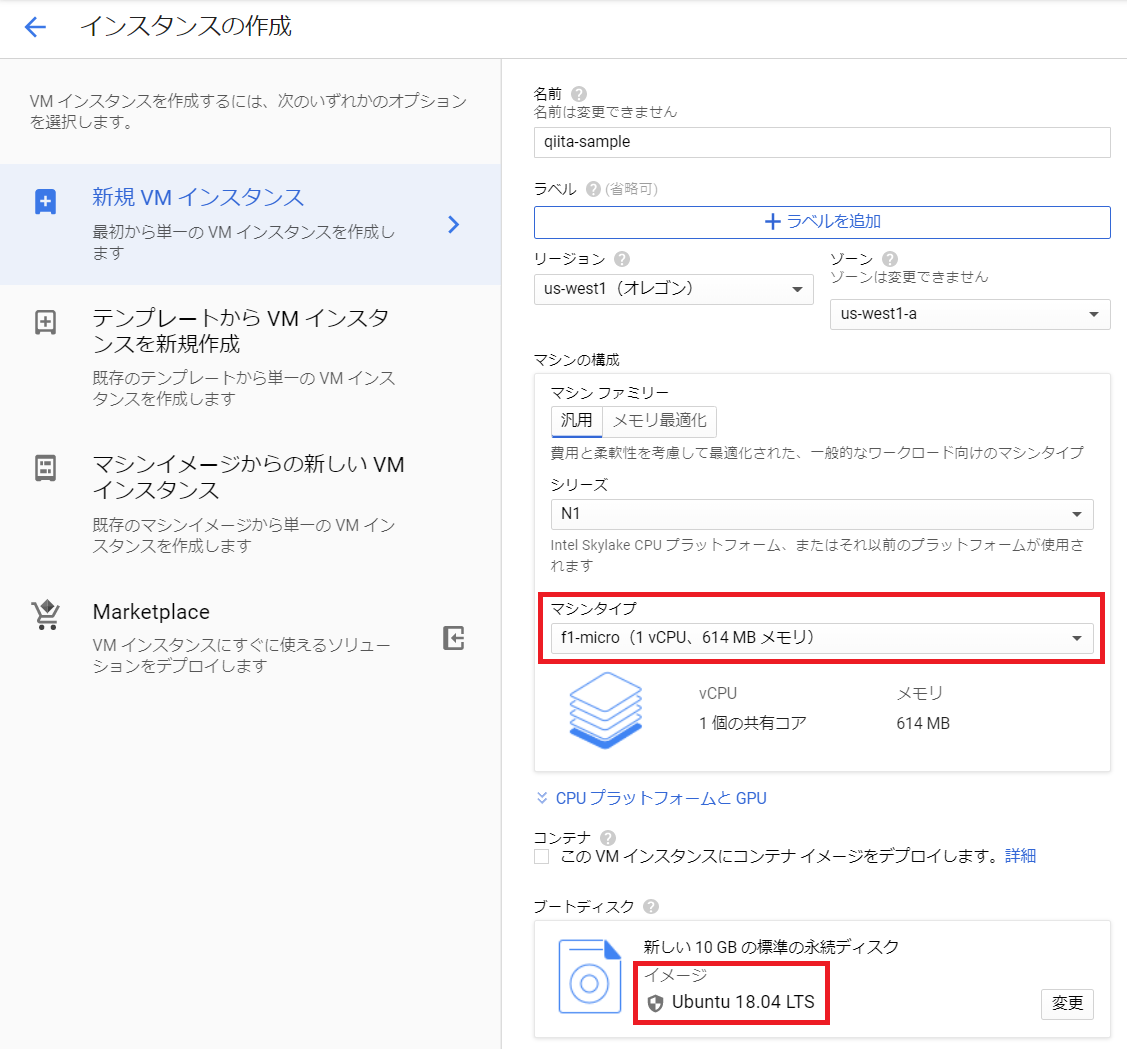
まずはGCPのコンソールからCompute Engineを作成します。自分が動作確認した環境は、デフォルトから下の画像の赤枠部分を変更しています。
- マシンタイプをf1-microに変更(無料で使うため)
- イメージをUbuntu 18.04 LTSに変更
ログインしたら以下のコードを実行します。Python3のインストールとAirflowのインストールが完了します。requestsも後で使うので一緒にインストールしてしまいましょう。ちなみに動作確認時、apache-airflowのバージョンは1.10.9でした。
sudo apt update
sudo apt -y install python3.7 python3-pip
pip3 install --upgrade apache-airflow requests
一度ログアウトしたら、再度ログインし次のコードでデータベースを初期化します。デフォルトでは~/airflowがAirflowのホームディレクトリとなります。
airflow initdb
次に~/airflow/airflow.cfgを編集して設定を変更します。該当部分を探して以下のようにしてください。
# DAGが認識されたときに停止状態にしない(Trueのままだと明示的にairflow unpauseコマンドが必要)
dags_are_paused_at_creation = False
# 開始日が過去のDAGを実行するときに、過去分を実行しない
catchup_by_default = False
# DAGの例を表示しない
load_examples = False
次に、Cloud Functionsを実行するDAGのファイルを~/airflow/dags以下に作成します。URLは先ほど作成したCloud FunctionsのURLに置き換えてください。
from datetime import timedelta
# The DAG object; we'll need this to instantiate a DAG
from airflow import DAG
# Operators; we need this to operate!
from airflow.operators.python_operator import PythonOperator
from airflow.utils.dates import days_ago
# These args will get passed on to each operator
# You can override them on a per-task basis during operator initialization
import requests
import os
from datetime import timedelta
def exec_functions(url):
payload = {}
res = requests.post(url, data=payload)
if res.status_code//100 != 2:
raise Exception("response status code is not in 200 - 299")
common_args = {
'owner': os.environ.get("USER", "unknown"),
'depends_on_past': False,
'retries': 2,
'retry_delay': timedelta(minutes=5),
}
dag = DAG(
'qiita_sample_v0.0',
default_args=common_args,
description='sample dag',
start_date=days_ago(1),
schedule_interval="00 09 * * *", # 毎日9時に実行(日本時間で18時)
)
task1 = PythonOperator(
task_id='qiita_function1',
python_callable=exec_functions,
#provide_context=True,
op_kwargs={
"url": "xxxxx", # 1つめのCloud FunctionsのURL
},
dag=dag,
)
task2 = PythonOperator(
task_id='qiita_function2',
python_callable=exec_functions,
#provide_context=True,
op_kwargs={
"url": "xxxxx", # 2つめのCloud FunctionsのURL
},
dag=dag,
)
task1 >> task2 # タスクの依存関係を指定
作成後にairflow list_dagsコマンドを実行し、このDAGが表示されれば正しく認識されています。コードにコメントも入れましたが、何点か補足。
- cronと同じ形式で実行時刻を指定できます。デフォルトだと日本の時刻にはならないので注意してください。
-
exec_functionsという関数を冒頭で定義し、PythonOperatorの中で指定しています。引数の渡し方が少し特殊で、op_kwargsで指定している点に注意してください。ちなみにprovide_context=Trueにすると、そのDAGやタスクの名前といった情報も関数に渡すことができます。 - 最後の
task1 >> task2はタスクの依存関係を指定しています。今回だと、APIで天気予報を更新していないのにメッセージを送られると困るのでこのような指定になっています。
最後に以下のコードを実行すると、airflow-schedulerがデーモンとして起動し、指定した時刻にDAGが実行されるようになります。Compute Engineからログアウトしても処理は続きます1。
airflow scheduler -D
最後に
Airflowについて解説したページのほとんどはWeb UIについても触れていますが、ここではしませんでした。というのもf1-microのメモリの制約でairflow webserverコマンドを実行すると、数秒後にメモリ不足だと怒られたからです。
自動再実行や依存関係の指定を諦めれば、Airflowの代わりにCloud Schedulerで妥協するのもありかと思います。その場合、無料枠は3ジョブまでなので注意してください。また、私の環境だとCloud Functionsのデプロイ時に--ingress-settings internal-onlyを指定するとCloud Schedulerから実行できませんでした。別の形でリクエストを制限する必要があるかと思います。
-
初めはsystemdで起動しようとしましたが、うまくいかずこの形に落ち着きました。 ↩