今回は前回同様、顧客をセグメンテーションしてみたいと思いますが、前回のようにただ単純に5つのグループにクラスタリングするのではなく、顧客同士の類似性もしくは違いを"距離"という概念を使ってもう少し詳しく見ていきたいと思います。
基本的には、まずその"距離"を計算し、それをMDS(多次元尺度構成法)というアルゴリズムを使って2次元の座標に落とし、それを散布図を使って可視化することによって、顧客同士の類似性をより直感的に理解するといった手法がデータサイエンスの現場では使われます。今回は、その具体的なやり方を見ていきます。
今回も引き続き、前回の顧客セグメンテーションで使ったワインのキャンペーンに対する顧客の反応のサンプルデータを使います。
ツール
今回もプログラミングなしでデータサイエンスができるExploratoryを使います。
データのインポート
Data Framesの右の+アイコンから、"Import File Data"を選択します。

そこで開くダイアログから、Localタブ、Text File(CSV, delimited)を選択します。
こちらからダウンロードした、campaign_customer_table.csvを選択し、インポートします。これは、あるキャンペーンにどの顧客が反応してくれたのかというデータになります。テーブルビューを見てみましょう。
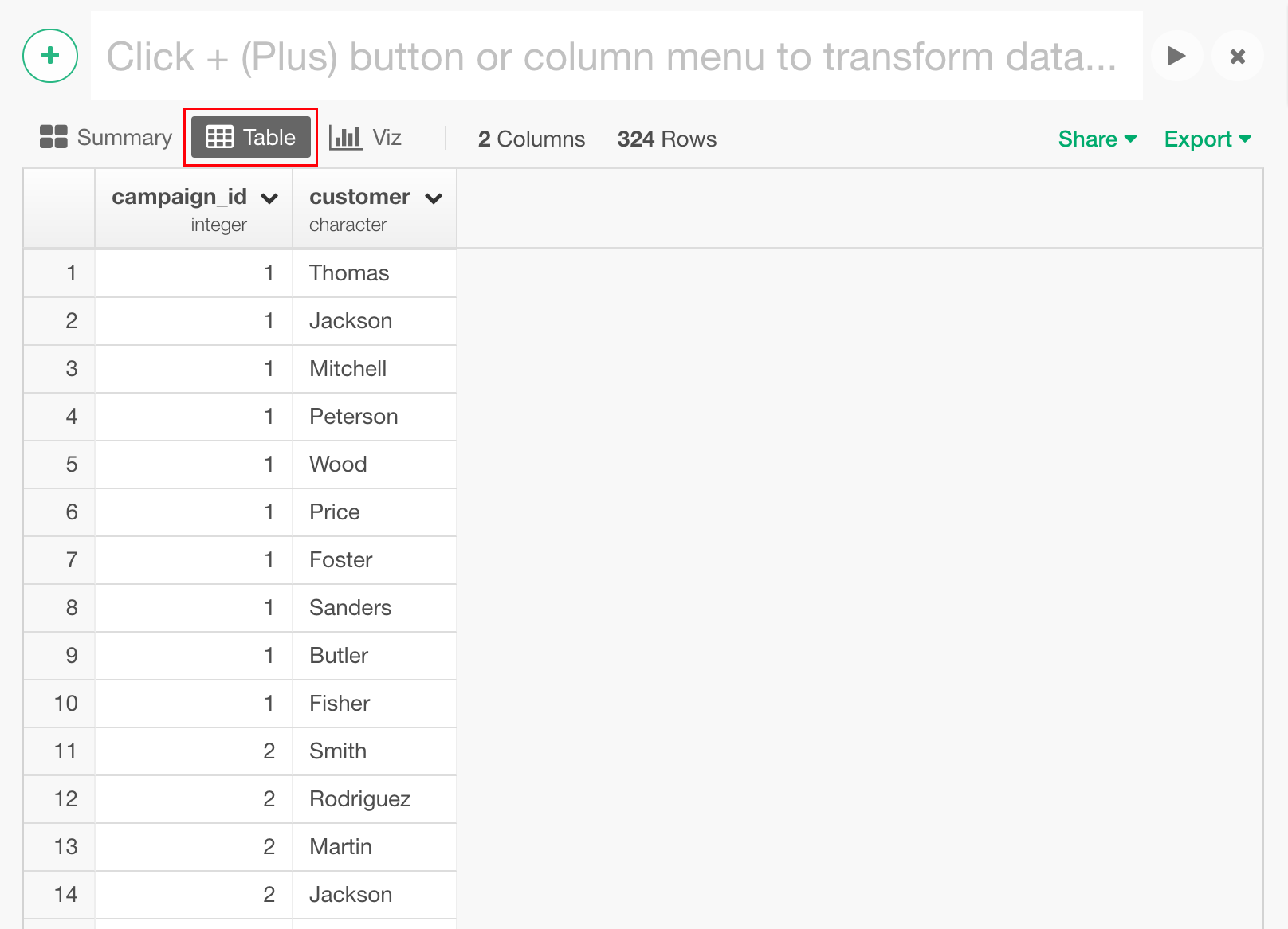
キャンペーンのIDを行に置き、顧客の名前を列に持ってくることによって、それぞれの顧客がそれぞれのキャンペーンに反応したかどうかを比べやすくします。こちらは、Pivotというコマンドを使って簡単に行うことができます。
左上の"+"アイコンから、Pivotを選択します。
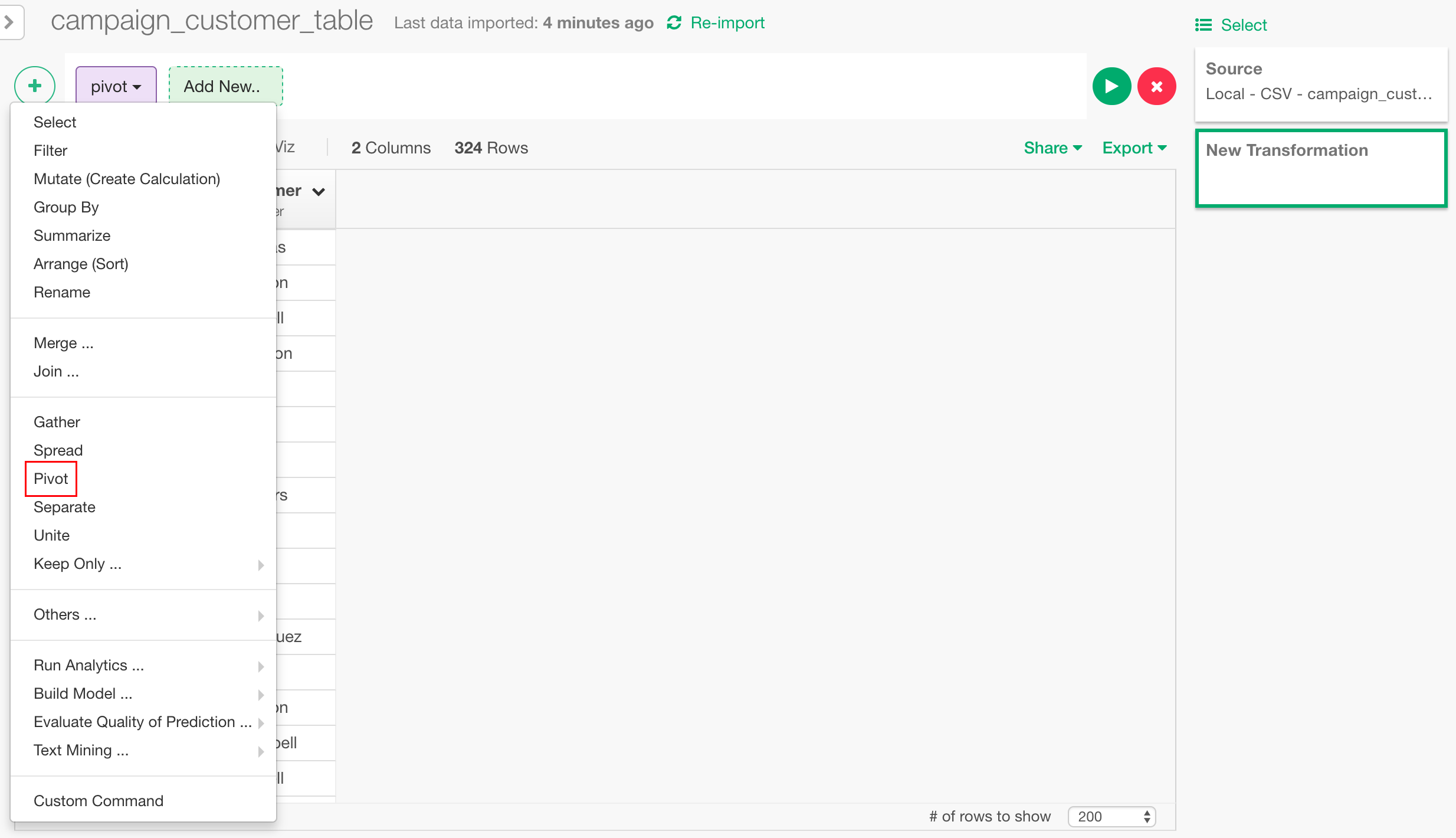
Rowに"campaign_id"、Columnsに"customer"を選択します。
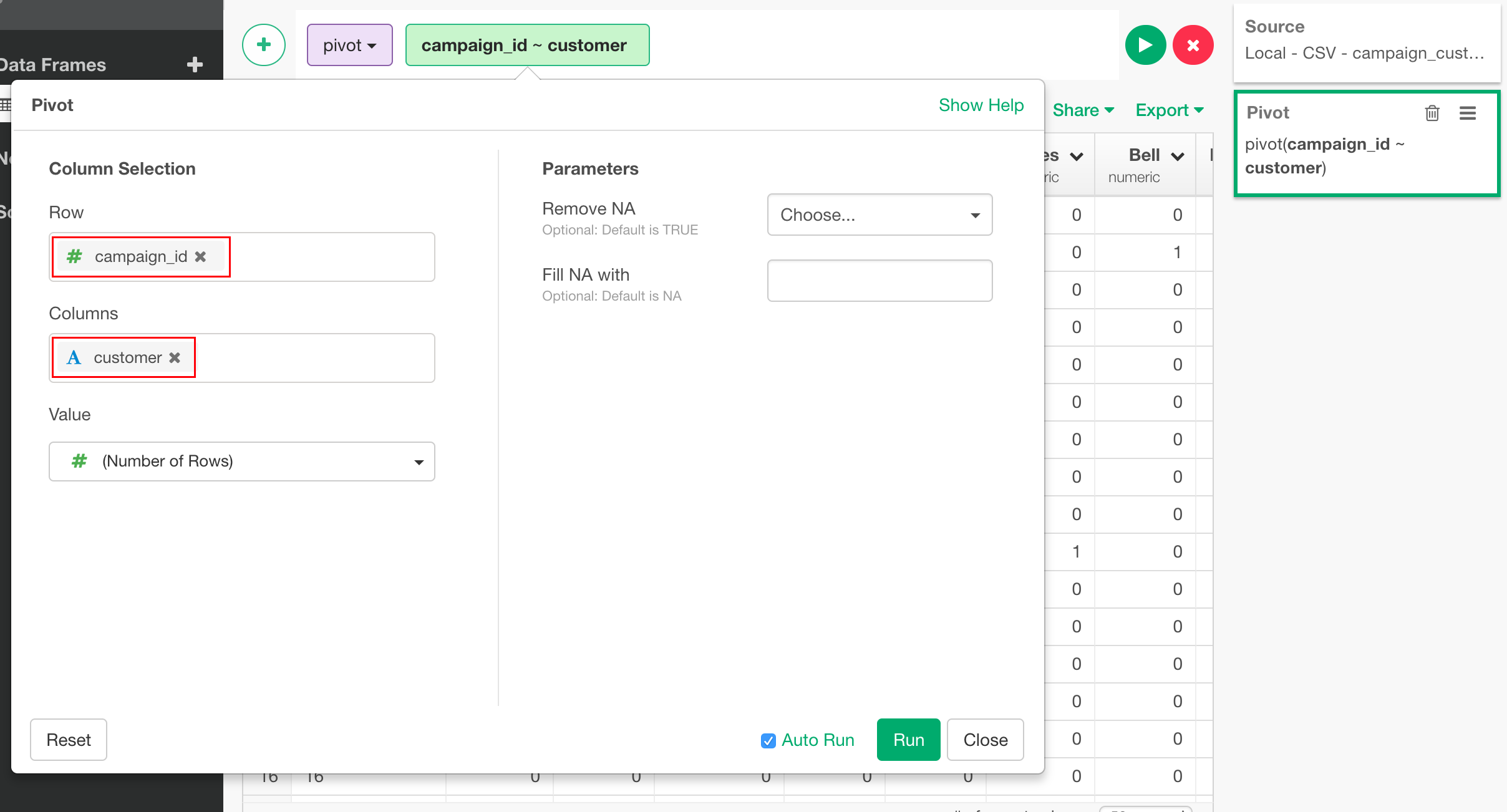
これを実行すると、このように、0と1が入ったテーブルになります。1はその該当するキャンペーンにそれぞれの顧客が反応したということを示します。例えば、下記の例ですとBakerは7と10のキャンペーンに反応したということになります。

まず、この0、1のパターンがcustomer同士でどれだけ異なっているか(距離)を計算します。
左上の"+" アイコンから、"Run Analytics..." -> "Calculate Distance"を選択します。
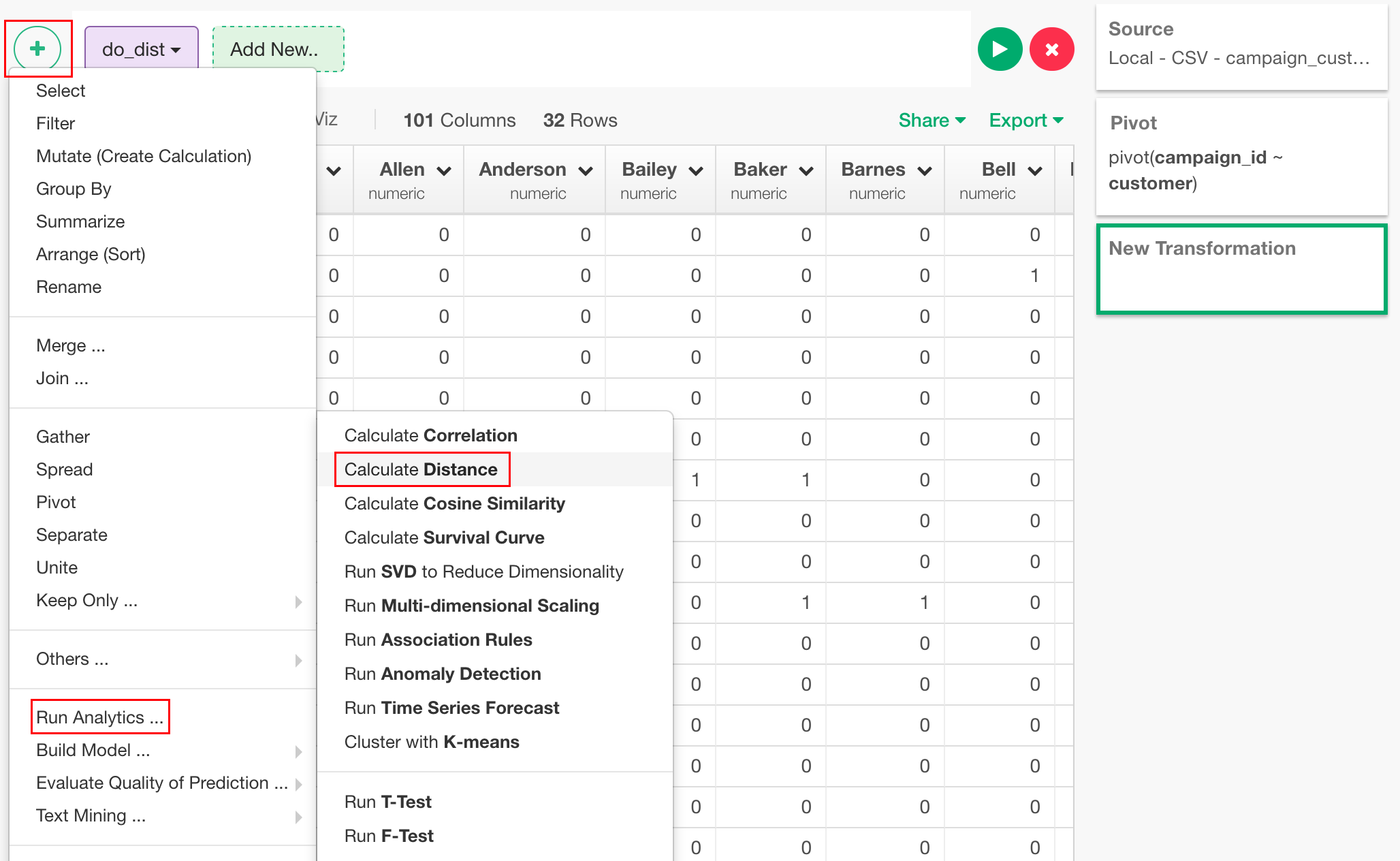
今回、"campaign_id"以外の各列がそれぞれの顧客をあらわしていて、それらの間の距離を求めたいので、Which distance do you want to see?に"Distance among columns"、Select Columnsで"Exclude"と"Select Column Names"、"campaign_id"を選択します。Distance Methodは、今回、値が全て0, 1なので"Binary"を選択します。

これを実行すると、以下のようにすべての顧客の名前の組み合わせに対しての距離が計算されました。

一旦これを可視化してみましょう。Vizタブに移り、Typeを"Heatmap"、X Axisを"pair.name.x"、Y Axisを"pair.name.y"、Colorを"value"にします。すると、以下のようなヒートマップが表示されます。

このチャートでは、赤は1に近い数値、青は0に近い数値になっています。こちらで現在可視化している数値というのは距離なので、赤ければ赤いほど数値が大きい、つまり距離が遠いということで、逆に青ければ青いほど数値が小さいということで距離が近い、もしくは似ているということになります。
このチャートを使って、例えば、MorrisとJohnsonは似ているということを発見することができますが、それぞれの顧客の組み合わせを見ていくよりも全体として似通った顧客のグループを可視化することを可能にするアルゴリズムにMDS(多次元尺度構成法)というものがあります。こちらは、都市を地図上に配置するようなものだと考えると想像しやすいかと思われます。例えば、東京、大阪、名古屋とあった場合に、それぞれの都市の距離にフォーカスするのではなく、この3都市を地図上で、経度、緯度をもとに配置することで全体としての関係性を可視化できるわけです。この、それぞれの距離から、経度、緯度にあたるものを計算するというのがMDS(多次元尺度構成法)のアルゴリズムです。
2次元での座標を求めるには、先程のdo_dist関数で、Output Typeに"Position values in X/Y coordinates"を選択します。
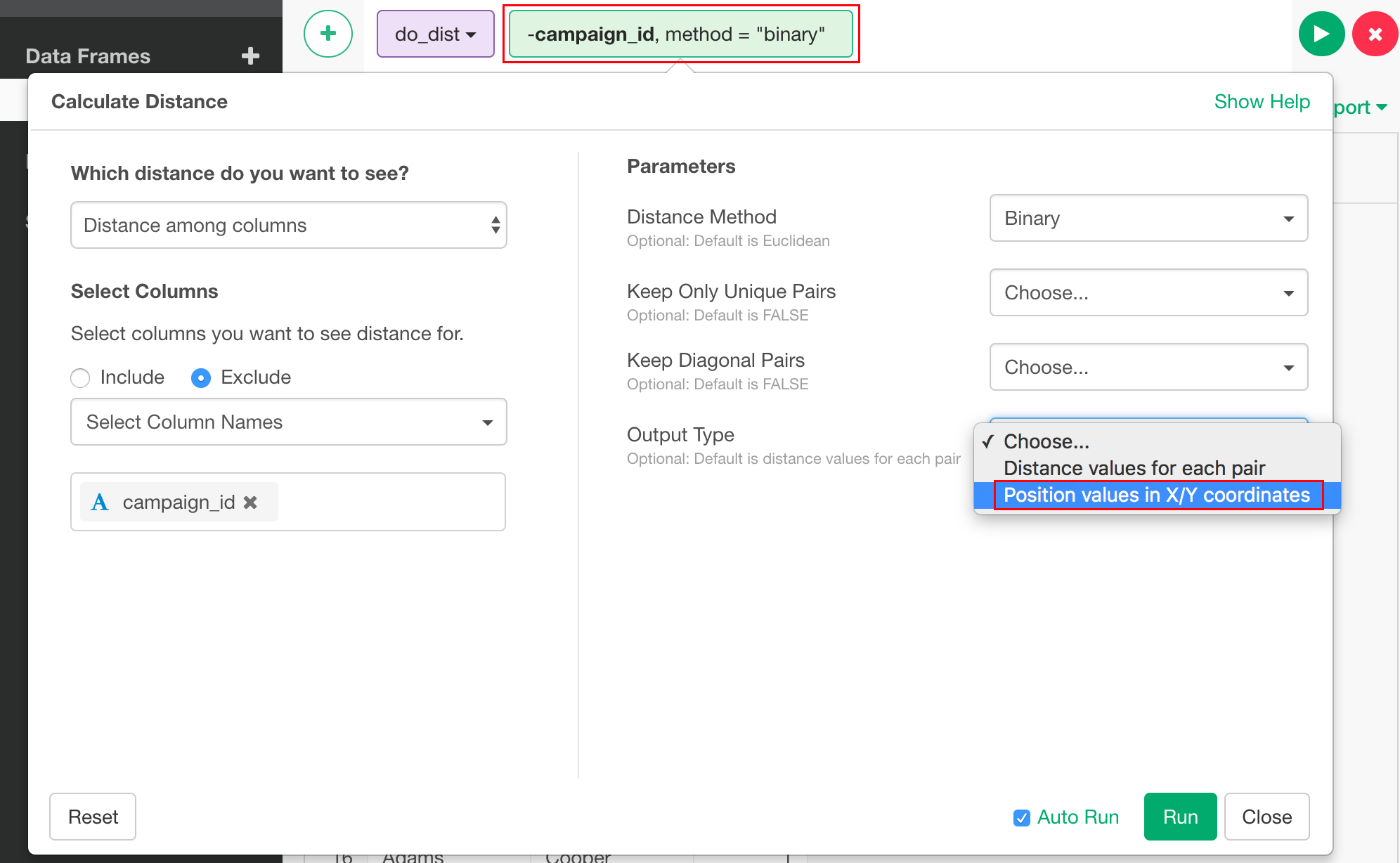
結果はこのようになり、各顧客の座標がV1, V2として表されます。
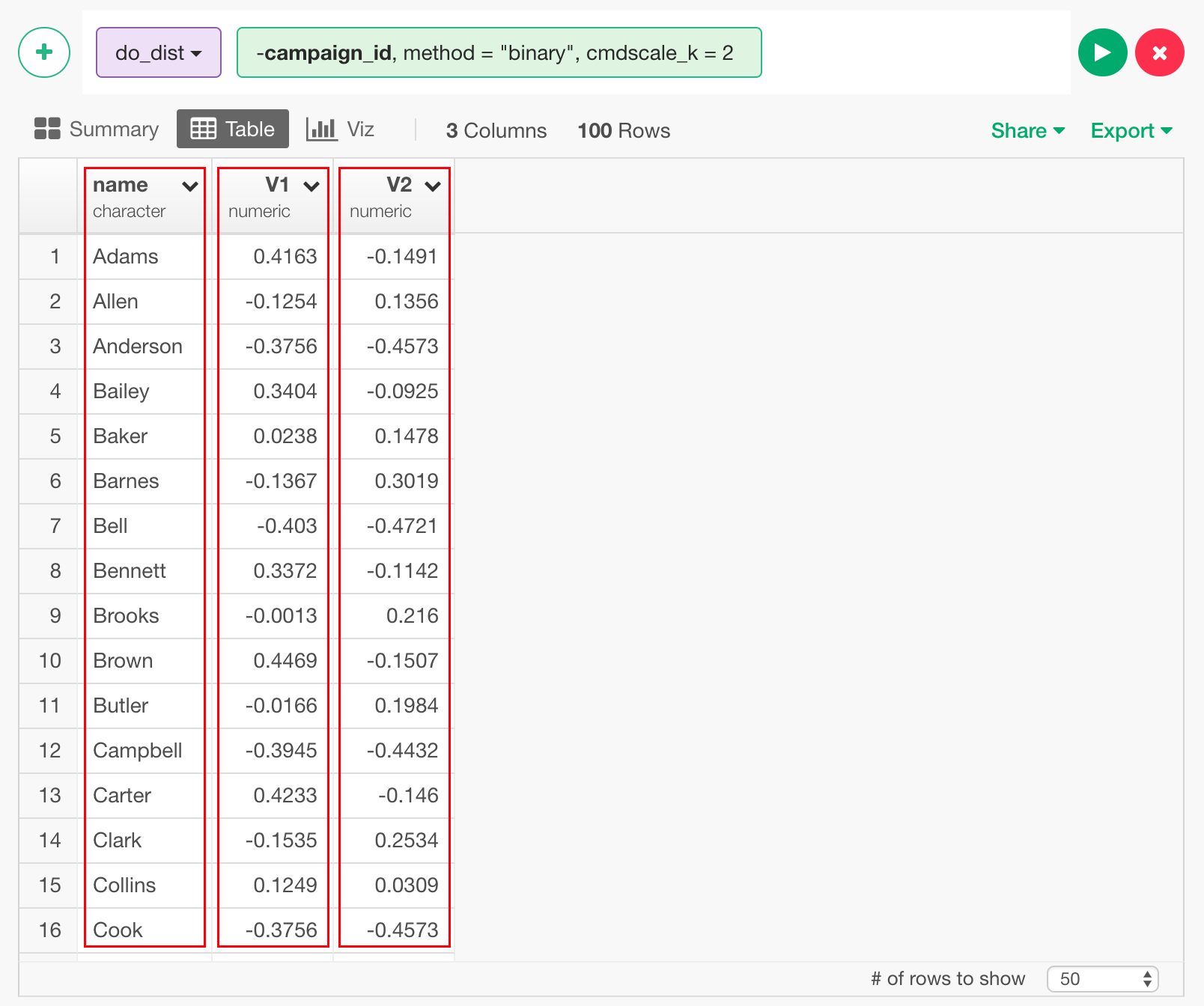
これを、散布図を使って可視化してみましょう。Vizタブに行き、Typeを“Scatter”、X Axisに“V1"、Y Axisに“V2”を割り当て、さらにLabelに“name”を割り当てることによって、それぞれの点の上にマウスを持っていくとそれぞれの顧客の名前がわかります。
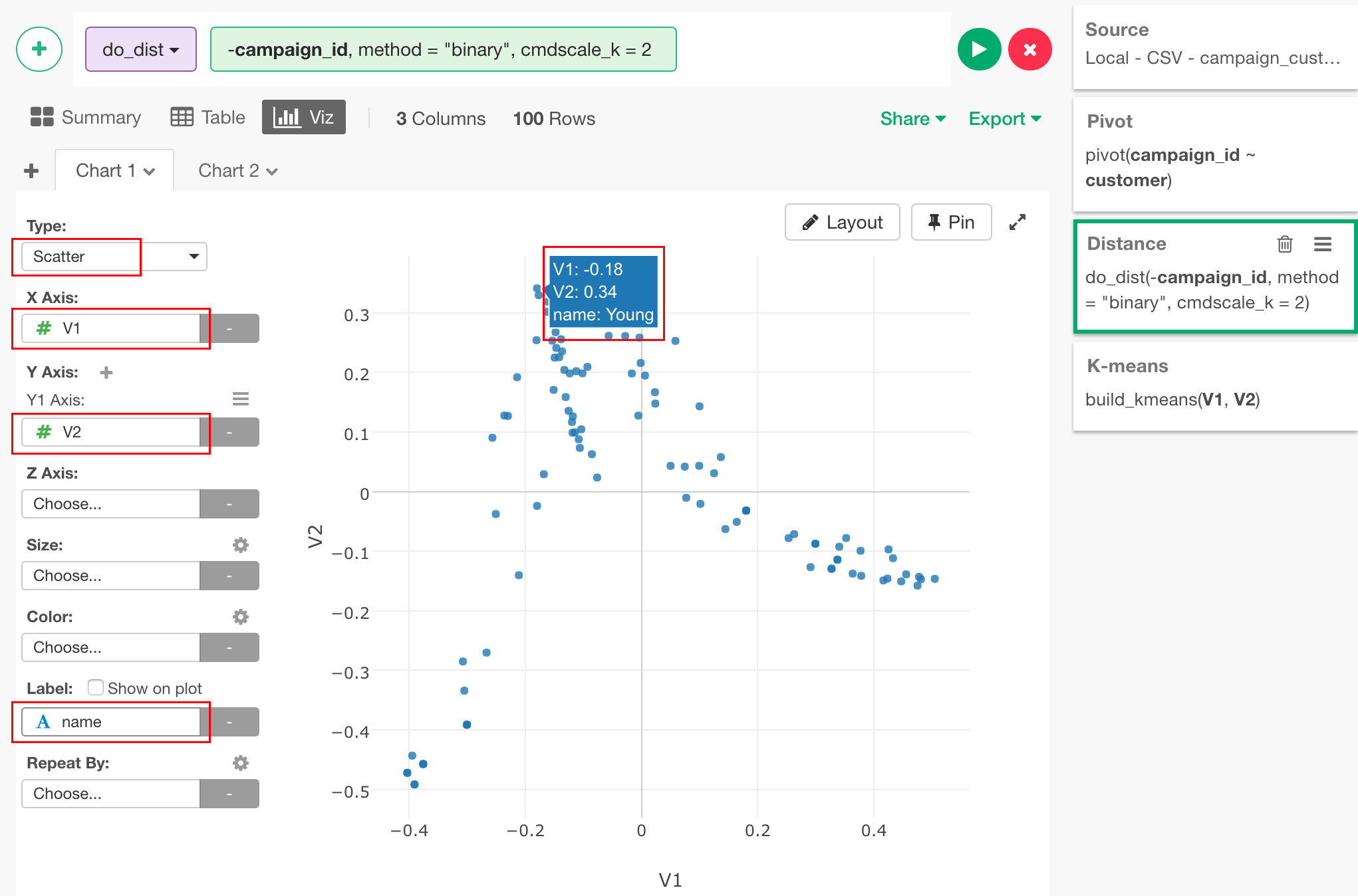
これによって、顧客の分布が可視化されました。
ここから、この位置情報を、前回使ったのと同じクラスタリングのアルゴリズムであるK-meansを使って幾つかのグループに自動的に分けてみましょう。
左上の + アイコンからK-meansを呼び出します。

今回は、各行が顧客で、それを座標に基いてクラスタしたいので、What do you want to cluster?に"Rows into clusters (groups)"、Select Columnsで"Include"と"Select Column Names"、"V1"、"V2"を選択します。Number of Clustersは、前回と同じく、5にします。

これで、各行にクラスタラベルが割り振られます。
これを、先程の散布図に表示させてみましょう。
Vizタブに戻り、Colorを"cluster"にします。
すると、以下のようにプロットされます。

さらに、それぞれのクラスタのサークルも表示させてみます。
Colorの歯車アイコンから、Show Circlesで"Filled Circles"を選びます。

今回のクラスタが前回と違う点としては、視覚化されているので議論をしやすかったり、クラスタがどれくらいまとまっているか、分散しているかといった情報も"見える"というメリットがあります。
このようにして、顧客の購買行動の類似性にもとづいて、顧客の分布を2次元で可視化し、クラスタ化することが数分で出来ました。
まとめ
前回は、顧客をセグメンテーションすること自体が目的でしたのでK-meansというアルゴリズムを使って一気にクラスタリングをかけてみましたが、今回は顧客がどうセグメンテーションされるかもさることながら、顧客同士の違いをもっと細かく直感的に理解したいということが目的でしたので、まずはその違いの程度(距離)を計算し、さらにMDS(多次元尺度構成法)というアルゴリズムを使ってその情報を2次元で表すことによって、顧客同士の類似性もしくは違いを可視化して、把握しやすくしました。結果として、顧客をセグメンテーションするにあたって、前回以上の細かで有用な情報が抽出されました。
このように、そういった情報を直感的に可視化できるということは、実際にデータを探索的に分析していくときに役立つのはもちろんですが、そこでの洞察を他の人に説明するときにこそ非常に役立ちます。結局、分析した結果というものは他の人と共有し、さらにそこから実際のビジネスに影響のある行動を促すということをもって初めて意味を持ちますので。
もし、何か質問やご要望などありましたら、support@exploratory.ioにご連絡ください。
データ分析をさらに学んでみたいという方へ
来月、シリコンバレーのExploratory社によって行われるデータサイエンス・ブートキャンプが東京で行われます。本格的に上記のようなデータサイエンスの手法をプログラミングなしで学んでみたい方、そういった手法を日々のビジネスに活かしてみたい方はぜひこの機会に、参加を検討してみてはいかがでしょうか。こちらに詳しい情報がありますのでぜひご覧ください。