
近年の、機械学習、AIのブームに伴って、よく、__クラスタリング__という言葉を耳にするようになってきたのではないでしょうか。クラスタリングとは、データを分類する手法の一つになります。
ほぼ全てのビジネスにおいて、何かを分類していきたいというニーズは存在するはずです。とくに、顧客の分類です。顧客の特性を深く理解出来、どういったアプローチを取るべきか見えてくるからです。それによって、顧客満足度を高め、ビジネスを改善していくことができるようになります。
そのような観点から、顧客データに対するクラスタリング分析は、__顧客をアルゴリズムを使って自動的に分類し、__その中に共通している性質を見つけ出すことが出来るので、とても強力な手法になります。
今回は、ワインのキャンペーンに対する顧客の反応のデータというサンプルデータで、顧客のクラスタリング分析を行ってみます。
ツール
データのインポート、加工、分析のインターフェースとして、RのUIとして世界中でよく使われているExploratoryを使います。
データのインポート
Data Framesの右の+アイコンから、"Import File Data"を選択します。

そこで開くダイアログから、Localタブ、Text File(CSV, delimited)を選択します。
こちらからダウンロードした、campaign_customer_table.csvを選択し、インポートします。これは、あるキャンペーンにどの顧客が反応してくれたのかというデータになります。テーブルビューを見てみましょう。
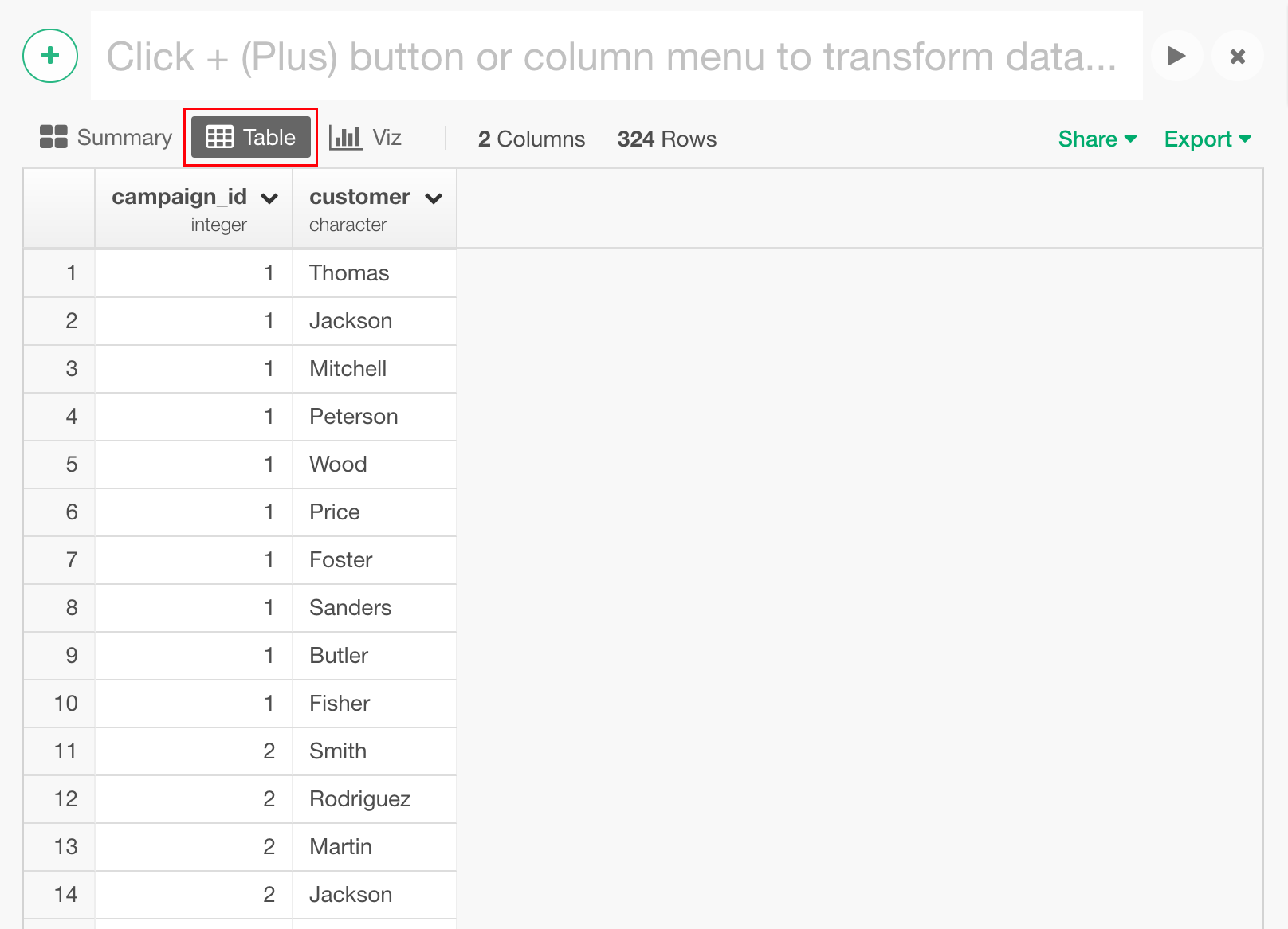
あるキャンペーンがどのようなものだったのかというデータは別のファイルとしてあるのですが、なんと、たったこれだけの情報からでも、実はクラスタリングしてしまうことが出来るのです。
早速、ユーザーをクラスタリングしてみましょう。左上の+アイコンから、"Run Analytics" -> "Cluster with K-means"を選択します。
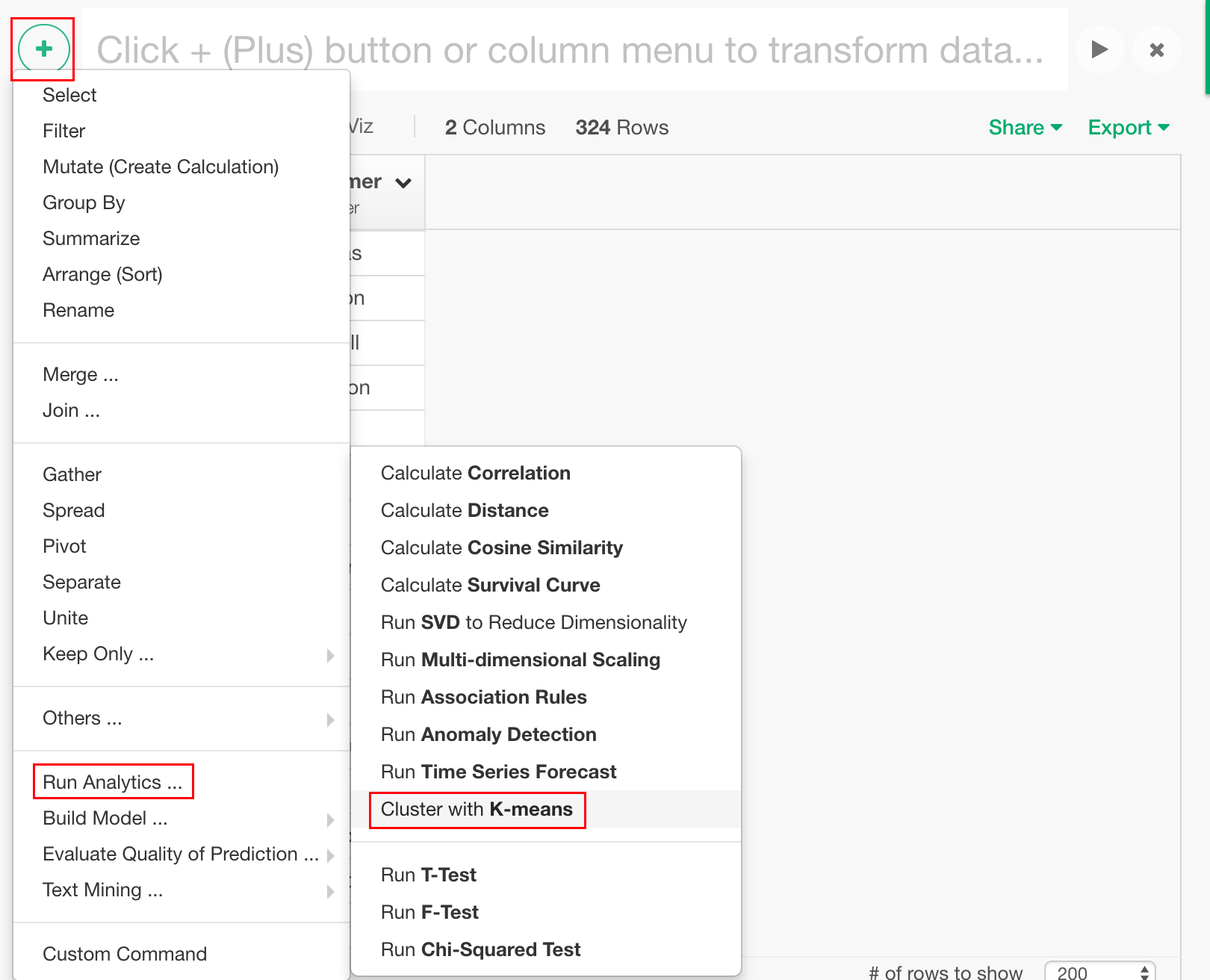
それぞれの、__customer__にクラスタIDを割り振っていきたいので、ダイアログで、What do you want to cluster (group)?に"Categories in a column into columns (groups)"を選択します。Which column holds the categories?には、クラスタする対象である、"customer"、Dimensions & Measureには、"campaign_id"、Measureには、"(Number of Rows)"を選択します。また、Number of Clustersは5にします。

実行すると、clusterという新しい列に、顧客のクラスタラベルが入ります。
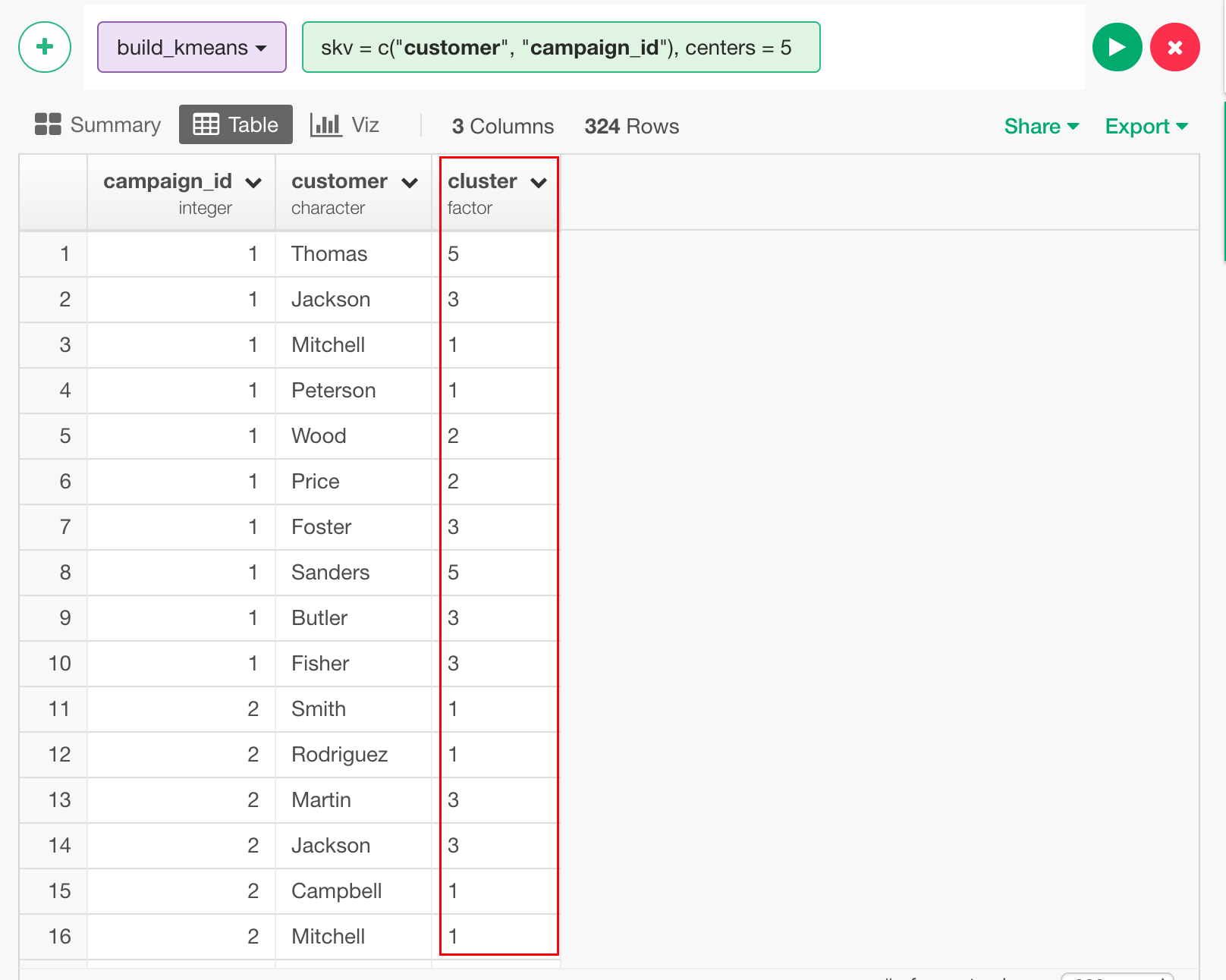
意味としては、Thomasはクラスタ5、Jacksonはクラスタ3に属するというように解釈できます。
これで、ユーザーが、campaignに反応する傾向から、クラスタリングが行われました。では、それぞれのクラスタに、どういった特徴があるかを見ていきます。
クラスタの特徴分析
次に、それぞれのcampaignがどのような内容だったのかという情報を取得します。
campaignに関するデータとして、こちらのデータがあります。先ほどと同じように、Data Framesの右の+アイコンから、"Import File Data"を選択します。
そこで開くダイアログから、Localタブ、Text File(CSV, delimited)を選択します。
そこで、こちらからダウンロードされたcampaign_table.csvを取り込みます。
このデータには、それぞれのキャンペーンがどの月に行われたのか(campaign)、どんなタイプ(varietal)と国(origin)のワインが対象だったのか、どれくらいの割引が告知されたのか(discount_percent)といった情報が入っています。
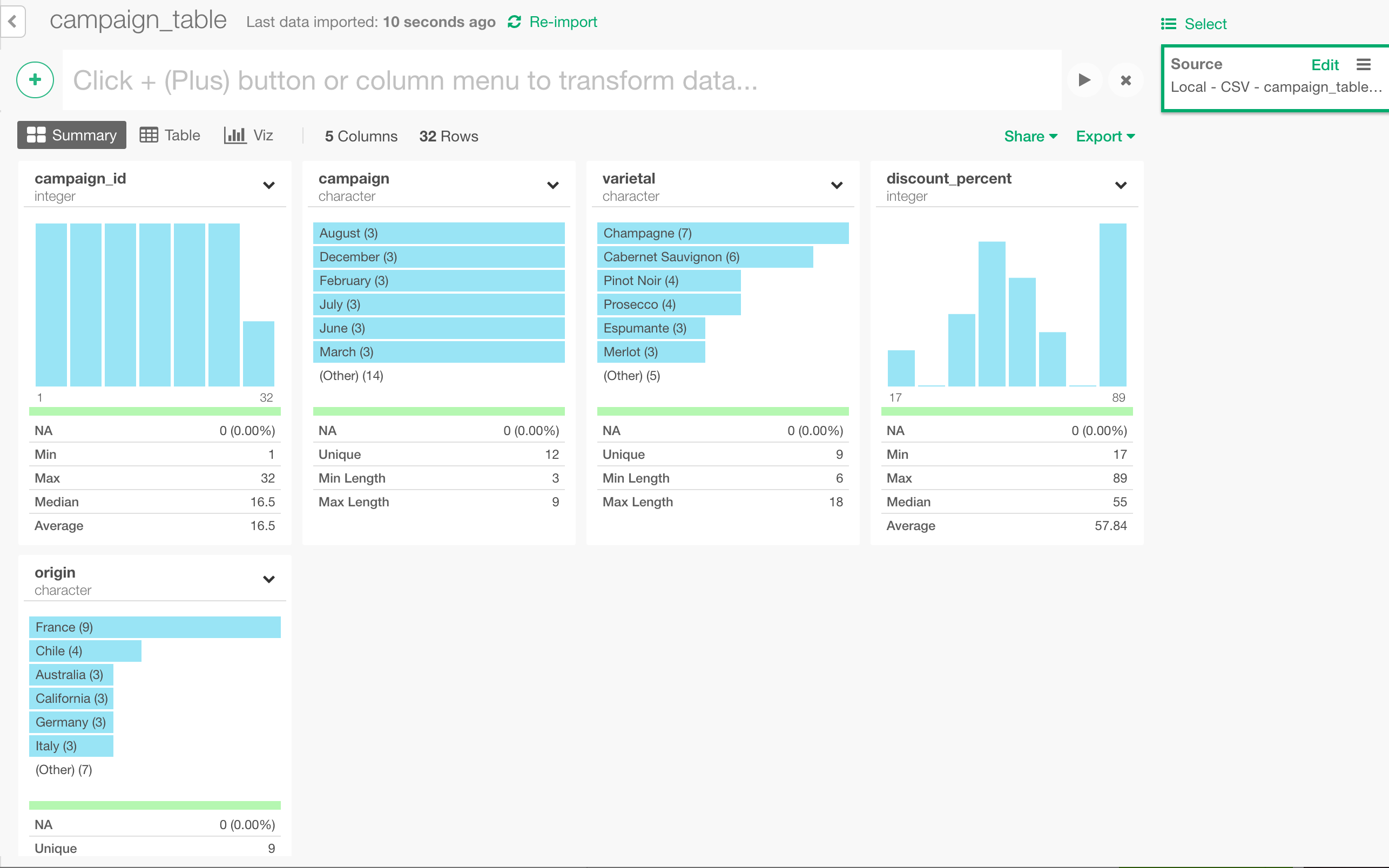
クラスタごとに、反応するキャンペーンの内容がどう異なっているかを見るために、データの結合を行います。
クラスタリングを行ったデータフレームに戻り、campaign_idのカラムメニューから、Joinを選択します。

Join Typeは"Left Join"、Target Data Frameは"campaign_table"、Current ColumnとTarget Columnは"campaign_id"にセットします。
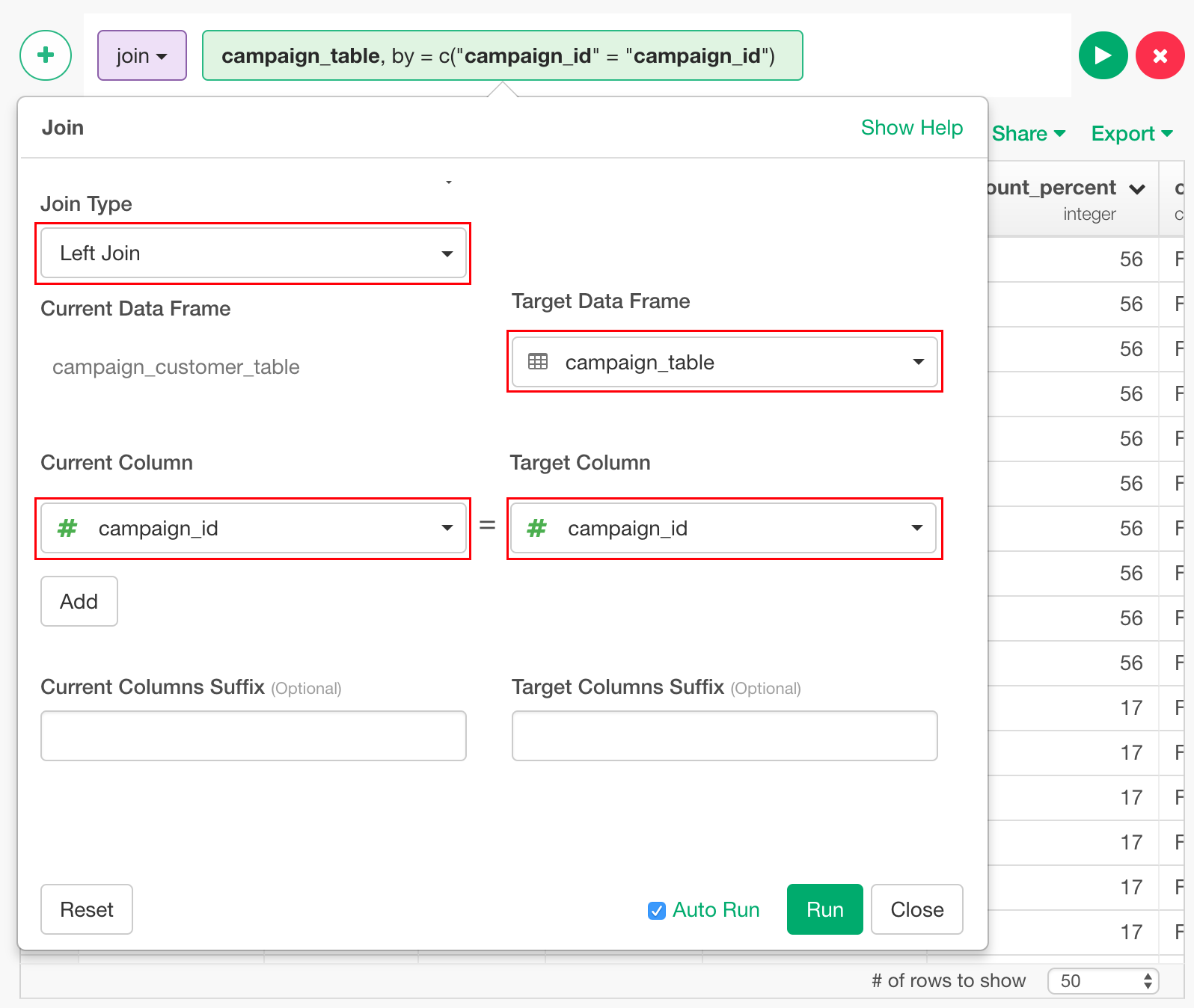
これで、それぞれのキャンペーンがどのようなものだったかという情報が入ったので、それをもとにクラスタの傾向を見てみます。
Vizタブに移り、それぞれのクラスターごとにどの国のワインがどれくらい入っているのかを可視化してみましょう。
Typeに"Bar"、X Axisに"cluster"、Y Axisに"(Number of Rows)"、Colorには、"origin"を設定すると、このようなグラフになります。
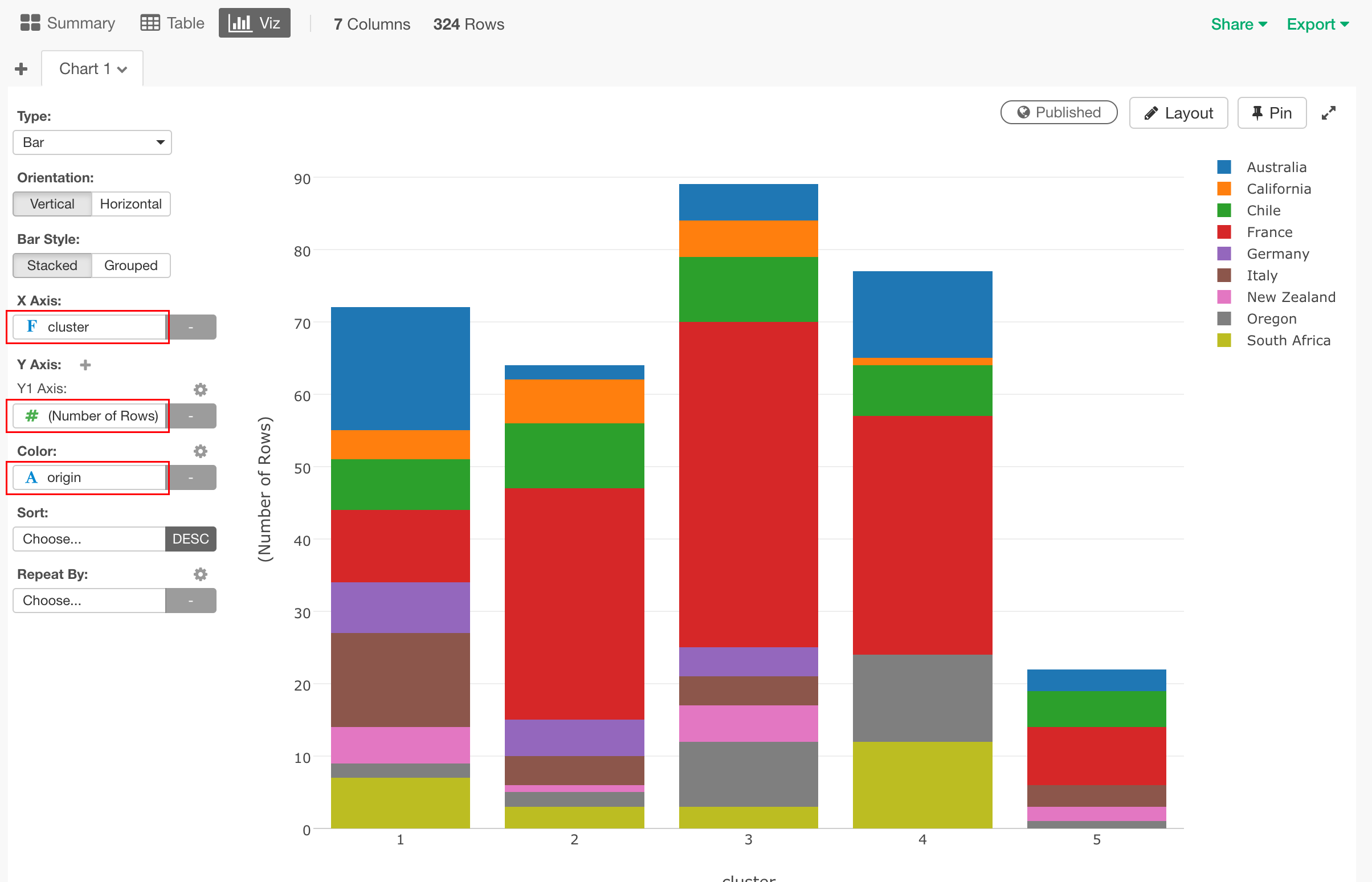
それぞれのバーの中での比率をもっと見やすくするためにY-Axis を絶対数でなく、% of Total(全体に対するパーセント)にしてみます。
Y Axisの歯車アイコンからメニューを開き、Window Calculationを選び、Calculation Typeに"% of Total"を設定します。
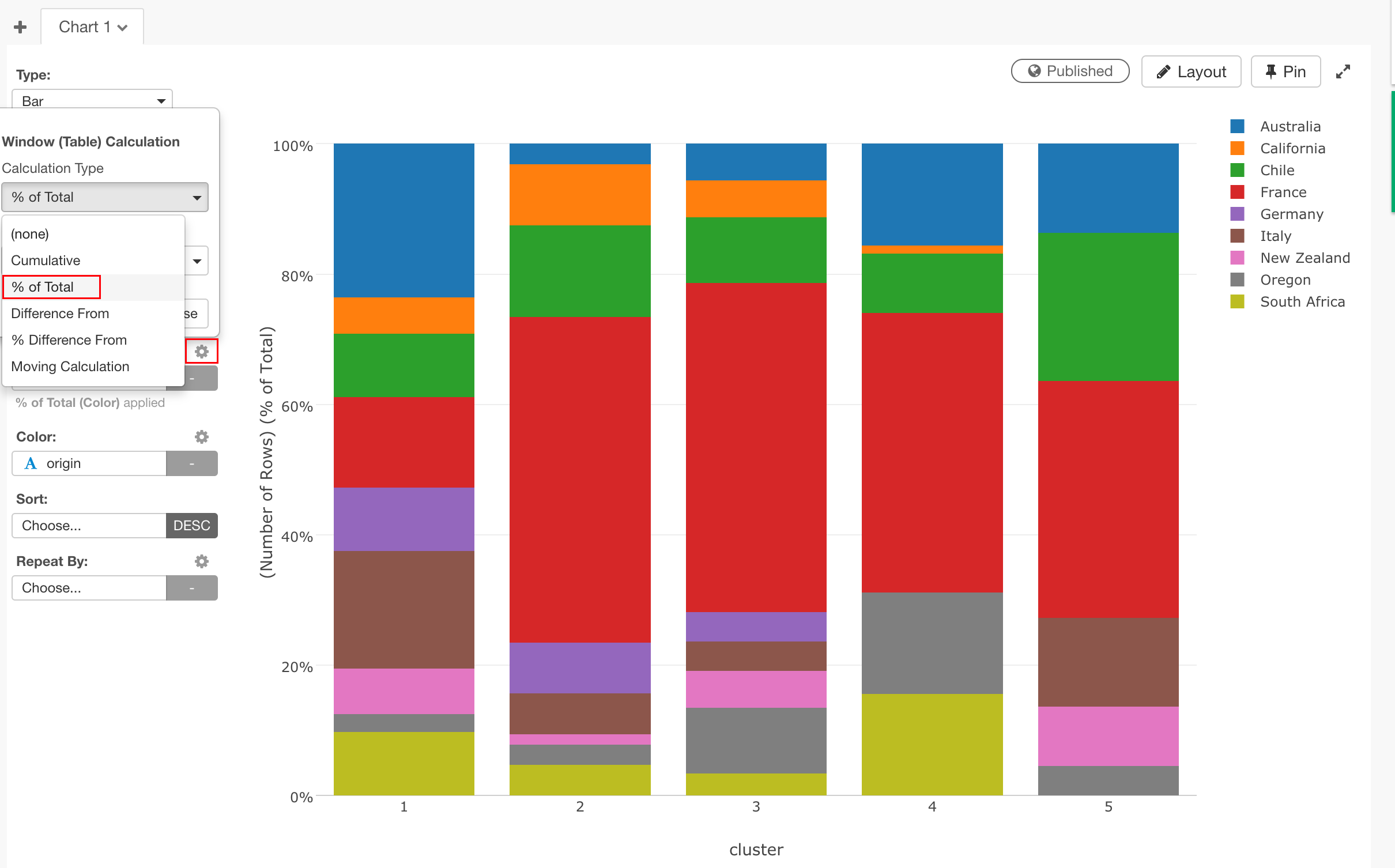
これから、1のクラスタには、オーストラリアが多く、4には南アフリカが多いということが見て取れます。
また、Colorを"varietal"に変えることで、クラスタごとに、選ぶワインの種類の違いも見えてきます。

例えばクラスタ1は、圧倒的にPinot Noirが多く、クラスと4はEspumante, Malbec, Pinot Grigioが多いのが特徴的です。
このように、可視化を活用することによって、それぞれのクラスタの特性を見つけ出すことが出来ます。
まとめ
今回の分析では、ワインのキャンペーンに対する顧客の反応の履歴から、顧客のクラスタリングが出来、クラスタごとに、よく反応するワインの産地や、種類などがどう違っているのかわかりました。
ここからさらにクラスターの数を変えたり、他の属性をクラスターを作る過程に入れたりすることでさらにこの分類のクオリティを高めることができますが、機械学習のアルゴリズムを使って顧客を自動的に分類し、さらにその結果をこのように可視化することでその有用性を確認することが数分でできました。こういった分析は特に探索的データ分析(Exploratory Data Analysis)ではよく使われる手法です。そうしたステップでは、機械学習や統計のアルゴリズムや可視化を使っていかに早くさらにインタラクティブに未知のデータの中から隠されたパターンやトレンドを発見していくということが重要になります。
もし、何か質問やご要望などありましたら、support@exploratory.ioにご連絡ください。
データ分析をさらに学んでみたいという方へ
来月、シリコンバレーのExploratory社によって行われるデータサイエンス・ブートキャンプへの参加を現在受付中です。本格的に上記のようなデータサイエンスの手法をプログラミングなしで学んでみたい方、そういった手法を日々のビジネスに活かしてみたい方はぜひこの機会に、参加を検討してみてはいかがでしょうか。こちらに詳しい情報がありますのでぜひご覧ください。