1. VRChatのスクリーンショット多すぎ問題
僕はVRChatをしていると,たくさん写真を撮る.
心を揺さぶるようなkawaiiに出会ったときには,もちろん連写する.
VRChatを初めてから合計6000枚以上のスクショを撮ってきたが,
ここから自分が写っている画像を探すのは面倒くさい.
誰か代わりにやってくれないかなぁー.
2. 名付けて "どらやきチェッカー"
作戦はこうだ.これまでに取り貯めた6000枚のスクショを使って,どらやきの特徴を覚えたAI を作る.新しく撮ったスクショは**"どらやきチェッカー"**によって自動的に "どらやきあり" か "どらやきなし" かに分類されるのだ.やったー!!
3. やりたいこと
- 学習/テストデータ用に,スクショ1枚ごとに "どらやきあり" か "どらやきなし" のタグ付け
- PyTorchを使用した畳み込みニューラルネットワーク (CNN)の実装
4. VoTT (Visual Object Tagging Tool) で画像にタグ付けしよう
僕の手元には6000枚のスクショがあるが,"あり" と "なし" の画像が混在しているため,このままでは学習には使えない.
VoTT (Visual Object Tagging Tool)を使うことで,画像への領域付きタグ付けができる.
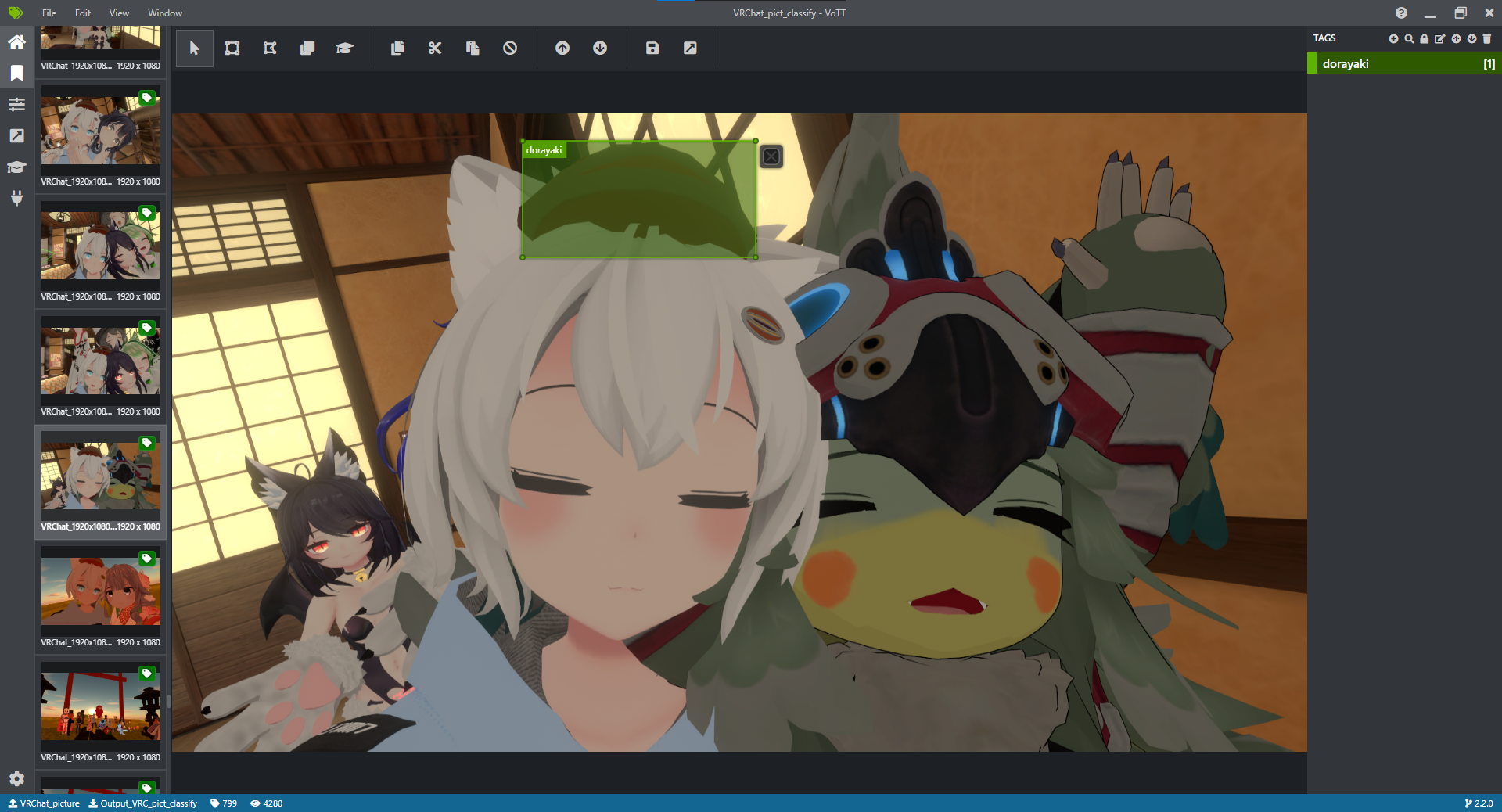
上の画像はVoTTの画面で,頭のどらやきの領域を指定して "dorayaki" というタグをつけている.
今回は**"あり"** か "なし" かの判定なので領域の指定は必要ないが,今後使えるかもしれないのでデータは残しておく.
スクショを見て,どらやきが写っていれば領域指定してタグ付け.
どらやきが写っていなければタグなし.
どらやきあればタグ付け.
どらやきなければタグなし.
どらやき,どらやき,どらやき,...
これを4000回ほど繰り返したところで力尽きた.
控えめにいって気が狂う作業だ.
タグ情報はjsonファイルで出力できる.以下が1つの画像に対するjsonのブロックだ.
"asset": {
"format": "png",
"id": "6e6136c4b3468036dc3727b41e7250fc",
"name": "VRChat_1920x1080_2019-12-10_01-20-37.933.png",
"path": "file:D:/Users/dorayaki/Pictures/VRChat_archive/VRChat_1920x1080_2019-12-10_01-20-37.933.png",
"size": {
"width": 1920,
"height": 1080
},
"state": 2,
"type": 1
},
"regions": [],
"version": "2.2.0"
必要な情報は path と state であり,state=2 が"dorayaki"タグ付きを表している.
5. PyTorchを使って機械学習しよう!
5.1 セットアップ
Python, Anaconda, PyTorchを順番にインストールします.
インストールの参考になるサイト:
Python: https://qiita.com/ssbb/items/b55ca899e0d5ce6ce963
Anaconda: https://www.javadrive.jp/python/install/index5.html#section1
PyTorch: https://qiita.com/mine820/items/c3046a44359bee9944e1
5.2 PyTorchのお勉強
僕はプログラミングも機械学習もシロートで,右も左も猫も杓子も分からない.
しかしPyTorchには親切なチュートリアルがあり,なんと有志による日本語化もされている.
渡りに船とは正にこのこと,さっそく以下のチュートリアルを進めた.
https://yutaroogawa.github.io/pytorch_tutorials_jp/
とりあえず,0. PyTorch入門, 1. PyTorch基礎, を読み進めた.
数学の知識,特に線形代数と偏微分を知っていると内容が深く理解できそうだけど,
別に簡単なAIを実装するくらいなら知らなくてへーき.
5.3 実装
以下のサイトを参考にした(というかコードを借りた).
- https://qiita.com/mathlive/items/8e1f9a8467fff8dfd03c
-
https://qiita.com/mathlive/items/2a512831878b8018db02
あと,PyTorchチュートリアルのコードも流用.手を抜くために手段を選ばない.
機械学習モデルは以下のように定義しました.
class NeuralNetwork(nn.Module):
def __init__(self):
super(NeuralNetwork, self).__init__()
self.relu = nn.ReLU()
self.pool = nn.MaxPool2d(2,stride=2)
self.flatten = nn.Flatten()
self.conv1 = nn.Conv2d(3,8,5)
self.conv2 = nn.Conv2d(8,16,5)
self.fc1 = nn.Linear(16*51*93, 256)
self.fc2 = nn.Linear(256, 2)
def forward(self, x):
x = self.conv1(x) # 8*212*380
x = self.relu(x)
x = self.pool(x) # 8*106*190
x = self.conv2(x) # 16*102*186
x = self.relu(x)
x = self.pool(x) # 16*51*93
x = self.flatten(x)
x = self.fc1(x) # 256
x = self.relu(x)
x = self.fc2(x) # 2
return x
「えっ,こんな簡単にできるの!?」と思った.モデルを組んだらPyTorchが勝手に学習部分(backward)を作ってくれる.
機械学習モデルは単純な畳み込みニューラルネットワークになっていて,216×384ピクセルのRGB画像を入力するとYesかNoを出力してくれる.パラメータは全部テキトーだけど,まぁいいや!!.
6."どらやきチェッカー" に学習させる
プログラムができたので,スクショ画像を放り投げて"どらやきチェッカー"に学習させよう.
今回は,"どらやきあり" と "どらやきなし" の画像を800枚ずつ (合計1600枚)使って学習します.
具体的には,1600枚をごちゃまぜにして90%(1440枚)を学習データ,10%(160枚)をテストデータとします.
以下,実行結果です.
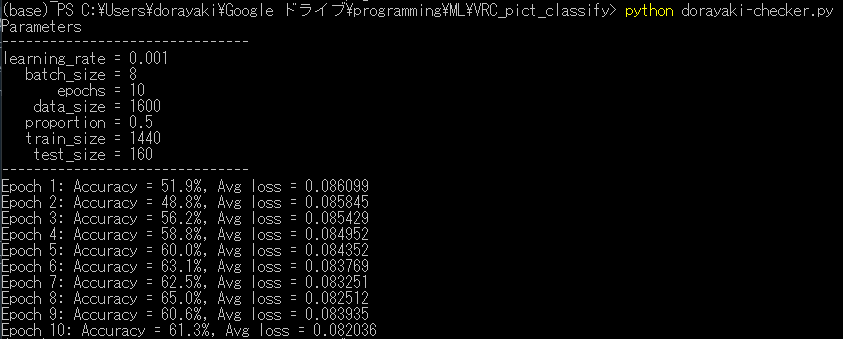
Accuracy は正解率,Avg lossは正解とのズレの大きさを表していると思ってください.
"あり" か "なし" かは適当に言っても50%の確率で当たるので,Accuracyが50%をどれだけ上回れるかが大事です.
学習後半での結果はだいたい62%くらいの正解率.まぁランダムよりはマシかなーってくらい.
実行時間はだいたい10分くらい,僕のPCがスゴイ音を鳴らしながら計算してくれました.グラボこわれちゃう.
ちなみに画像の解像度(216×384)を2倍にして実行したらメモリ不足で停止しました.
7. "どらやきチェッカー"を実用してみよう!
最近撮った50枚のスクショ("どらやきがある画像" と "どらやきが無い画像" を25枚ずつ)を用意しました(学習データとは独立).
さぁこれらの画像を分類できるかな?
出力結果をそれっぽく表にしてみました.
| あり(チェッカー) | なし(チェッカー) | |
|---|---|---|
| どらやきがある画像(25枚) | 19 | 6 |
| どらやきがない画像(25枚) | 13 | 12 |
正解率(Accuracy)は,(19+12) ÷ 50 = 0.62 (62%) でした. |
さらにこの50枚の画像を1枚ずつ見て判定結果と照らし合わせると,これがなかなかに面白い.
どらやきあり画像で,チェッカーが"あり"と判定した画像 (19枚)

4枚だけ抜粋.どらやきががっつり写ってて,ちゃんと認識できてる.
どらやきがあるのに,チェッカーが"なし" と判定した画像 (6枚)

判定成功したスクショと比べて,どらやきが小さかったり色がおかしかったりしている.
あー確かにこれは間違えちゃうよねぇーって感じがするのが面白いところ.
どらやきなし画像で,チェッカーが"なし"と判定した画像 (12枚)

まぁ実際写っていない.どらやきの髪飾りをどらやきと判定していないのは複雑ではある.
どらやきがないのに,チェッカーが"あり" と判定した画像 (13枚)

どらやきっぽい何かが写っている?ゆっくりの顔や茶髪の頭がどらやきに見えた可能性がありますね.
8. まとめ
PyTorchの練習のついでに何となく作り始めたどらやきチェッカーですが,
結果を可視化してみるとチェッカーくんが間違える気持ちが分かってきて面白かったです.
もっと精度を上げるには,パラメータのチューニングをしたり,機械学習分野のテクニックを学ばなきゃですね.
はぁー,つよつよPCが欲しい.
P.S. スクショに写ってる人で,写真載せてほしくないよーって人いたら教えてください.秒で消します.