こんにちは、donaldchiです。
今回はICML2019で発表されたKnowledge Graph Embeddingに関する論文を読んだのでメモを共有します。メモなので、ざっくりした部分が結構あります。何か間違ったところや指摘があれば、コメント欄で書いてくださると幸いです。
論文情報
- タイトル:Learning to Exploit Long-term Relational Dependencies in Knowledge Graphs
- 著者:Lingbing Guo, Zequn Sun, Wei Hu
一言まとめ
従来のKnowledge Graph embeddingは「Knowledge Graphに置いて似たようなエンティティは似たような関係の役割(relational roles)を持つ」という仮説の元で**fact (s,r,o)を学習し、エンティティ(entity)や関係(relation)の分散表現を求めています。しかし、factのみに注目した場合、得れれた分散表現に「表現力が低い」、「情報伝搬が不充分」などの問題があります。これらの問題を解決するために、論文の手法ではrelational path(同じエンティティを持つfact列)**に注目することを提案し、Entity AlignmentタスクでSOTAを達成しています。
背景
Knowledge Graphについて
Knowledge Graph(KG)は現実世界での知識(Knowledge)を構造化された事実(fact)構造で表現した有向グラフのことです。
例えば、
- United Kingdomで使う言語は英語である
- Tim Berners-Lee(World Wide Web(WWW)を考案し、ハイパーテキストシステムを実装・開発した人物 from Wikipedia)はイギリス人である
- Tim Berners-Leeは英語が話せる
- Tim Berners-LeeはW3Cの雇用者である
とう事実は元にKnowledge Graphを作成した場合は、以下のようなグラフができます。
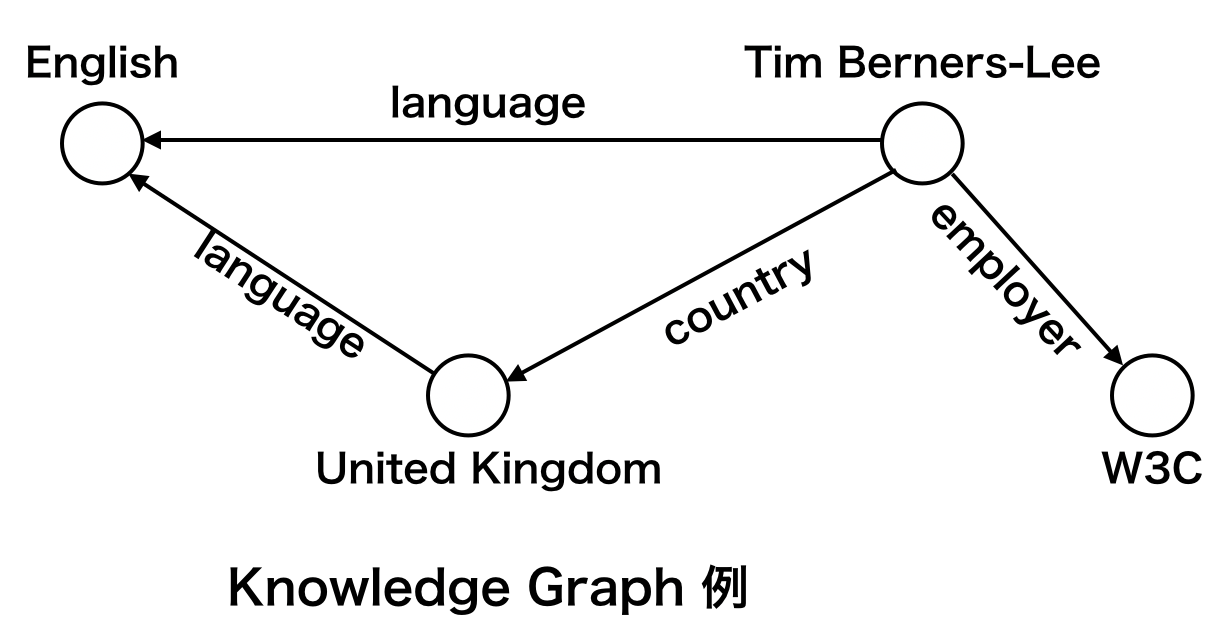
Knowledge Graphに置いて、グラフノードは**エンティティ(Entity)と呼び、エンティティ間のグラフエッジを関係(Relation)**と呼びます。
事実はエンティティと関係からなる**トリプル(triple)構造(s, r, o)**で表現します。トリプル構造の各要素は s: subject entity, r: relaiton, o: object entityと名前をつけています。
上の例だとKnowledge Graphが
- ($Tim Berners-Lee, language, English$)
- ($United Kingdom, language, English$)
- ($Tim Berners-Lee, country, United Kingdom$)
- ($Tim Berners-Lee, employer, W3C$)
などの事実から構成されることになります。
Knowledge Graph応用に置けるタスク
Knowledge Graphを応用するには以下のようなタスクがあります。
- Entity Alignment
- Knowledge Graphを跨るembeddingを学習し、複数のKnowledge Graphを同時に使えるようにする
- 理由
- 既存Knowledge Graphのスケールが不充分であるため、複数のKnowledge Graphを統合する必要がある
- ドメイン別に作られている複数のKnowledge Graphを繋げて使うと嬉しい
- 同じドメインに置けるKnowledge Graphでも作成人によって違うドメイン知識、違う作成基準を持つため生成されたKnowledge Graphが違う構造を持つ
- Knowledge Graph Completion (a.k.a Link Prediction)
- 単体Knowledge Graphでもmissing factsが多く存在するため、補完する必要がある
これらのタスクに対して、いろんなアプローチがありますが、embeddingベースで取り込むのが一般的であるらしいです。
問題点
今までのKnowledge Graph Embedding手法は「similar entities are likely to have similar relational roles」という大前提の元で、事実に注目してエンティティや関係の分散表現を求めていました。
しかし、従来のEmbedding手法には以下のような問題点が存在します。
- 分散表現の表現力が低い
- 同じobject entityを持つsubject entity達が似たような分散表現になる可能性が高い
- エンティティの次数分布(degree distribution, degree: エンティティが関与した事実の数)がlong-tail構造になっているため、次数が小さいエンティティの表現力が低い傾向がある
- 情報伝搬が充分にされていない
- この問題はEntity Alignmentに限る話
- Entity Alignmentでは、一定数のエンティティや関係に事前にわかっている分散表現を与え(Seed Alignment), それらの情報を伝搬させることで、cross knowledge graphに置けるエンティティや関係の分散表現を求める
- 事実のみに注目すると、one-hop neighborsのみを考慮することになるので、seed alignmentされたエンティティ/関係から遠いエンティティ/関係ほど表現力が低くなる可能性がある
関連手法
Knowledge Graph embeddingの代表的な手法にTransE(Bordes et al.,2013)という手法があります。
この手法は、エンティティと関係の分散表現を同じベクトル空間に落とし、それら分散表現間の演算で事実を表現することを前提に分散表現を求めています。
具体的には、**fact(s, r, o)**の要素間で $s + r \approx o$の関係が成り立つように各要素の分散表現を求めています。
従って、例えば事実 ($Alfred , Hitchcock, Director , Of, Psycho$)に置いて、関係 Director Of は $Director , of \approx Psycho - Alfred , Hitchcock$で表現できるようになります。
提案手法でもこの考えを用いて事実に注目することにします。
提案手法
RSN
論文では **Recurrent Skipping Networks (RSN)**というモデルを提案しています。
提案手法は従来手法と違く**fact(s,r,o)**ではなく、Relational Pathを学習することを提案します。
Relational Pathはざっくりいうと同じエンティティを持つ事実を繋げて得たpathのことを指します。
例えば、上のKnowlege Graphの
- ($Tim Berners-Lee, country, United Kingdom$)
- ($Tim Berners-Lee, employer, W3C$)
という二つの事実を使ってrelation pathを作成すると以下のようなものが得られます。
($United , Kingdom \to country^- \to Tim , Berners-Lee \to employer \to W3C$)
このうち、($United , Kingdom, country^-, Tim , Berners-Lee$)は($Tim Berners-Lee, country, United Kingdom$)と逆の方向を持つトリプル構造(reverse triple)を指しています。
提案手法はRelational Pathを以下のような構造のモデルに通すことでエンティティや関係の分散表現を求めています。
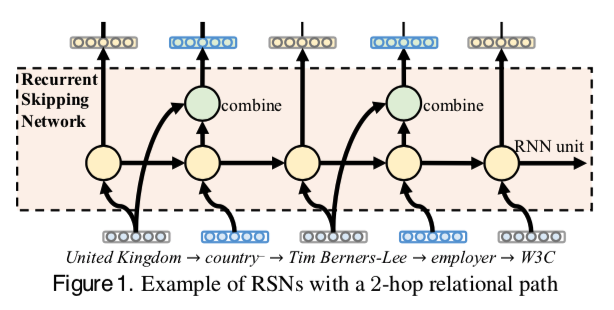
RNNと似たような構造を持っていて、hidden stateを通して、pathの中で情報伝搬を行っています。一方、RNNと違って、今回はエンティティや関係が持つ情報を遠くまで伝搬するだけてなく、事実からの情報も学習させたいため、skipping mechanismを使ってエンティティと関係のcombinationを取り入れています。 ($s + r \approx o$関係も学習に取り入れるため)
さらに、skipping mechanismを用いることで、RNN, RRN(recurrent residual network)と以下のような区別がつくらしいですが、この部分はまだはっきりわかっていなく、説明は省略します。

RSNを用いたEnd-to-End Framework
論文では、RSNを用いてEntity Alignmentタスクに取り込むためにEnd-to-End Frameworkを提案しています。
End-to-End Framework構造
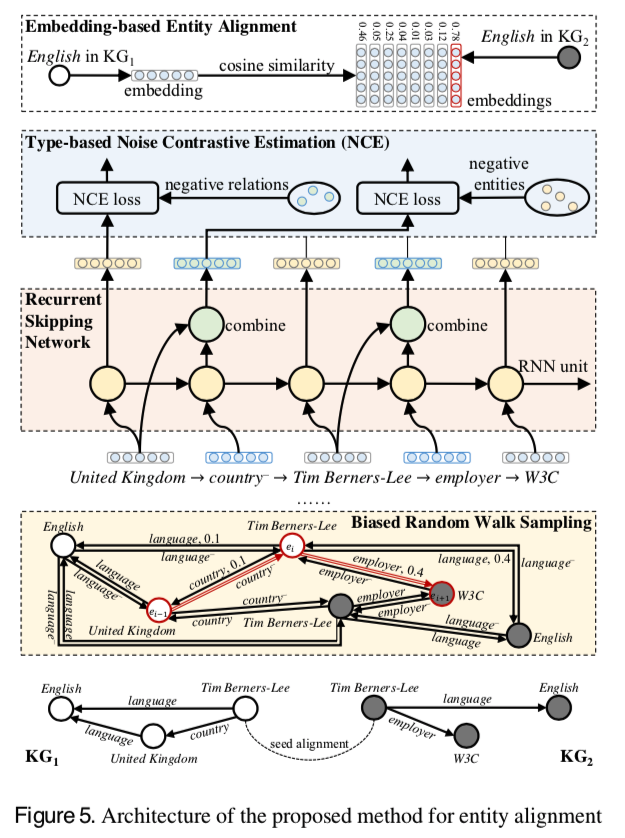
Biased Random Walk Sampling
Knowledge Graphの中の全てのrelation pathを考慮しようとすると膨大な計算量がかかります。従って論文ではrandom walk samplingを行います。
さらに、今回の場合seed alignmentが持つ情報をより遠く且つKnowledge Graph間で充分に伝搬させるのが目的であるため、バイアス付きのrandom walk samplingを行います。
- Knowledge Graph内でのsampling
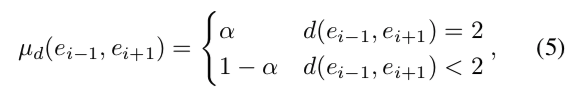
- $d(e_{i-1}, e_{i+1})$ : エンティティ$e_{i-1}$ とエンティティ$e_{i+1}$の距離
- $parameter: \alpha > 0.5$で一歩前で選んだエンティティ$e_{i-1}$の2-hop先エンティティを選ぶ
- Knowledge Graph間でのsampling
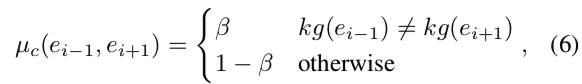
- エンティテい$e_i$に注目した場合、なるべく一歩前で選んだエンティティ$e_{i-1}$と次に選ぶ候補エンティティ$e_{i+1}$が同じkonwledge graphに属するものでないようにする
- $parameter \beta > 0.5$ : 確率$\beta$で次のエンティティ$e_{i+1}$を違うknowledge graphから選ぶ
Type-based Noise Contrastive Estimation(NCE)
エンティティ、関係の数が膨大であるため、学習において全てのlossを計算するのは非常に時間かかる操作になります。
そのため、論文ではnegative samplingを通して得たサンプリングエンティティ、関係のlossを計算し、全体lossの近似として使っています。
negative samplingは noise probability distributionという分布を元にサンプリングを行っていますが、説明は省略します。
実験
論文では、今回の提案手法でEntity Alignment問題に取り込む他に全く同じ構造を使ってEntity Completionにも挑戦しています。
データセット
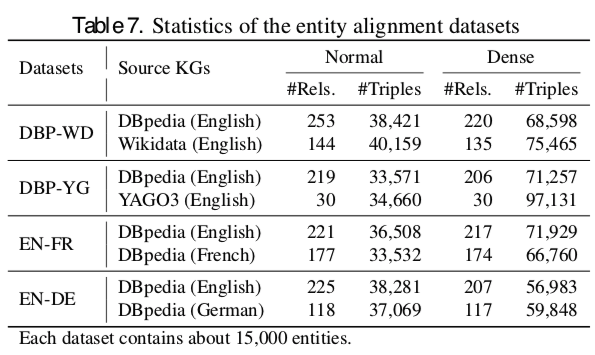
- Entity Alignmentタスクでは上のデータセットを使っている
- **segment-based random PageRank sampling (SRPRS)**という手法で母集団とほぼ同じdegree distributionを持つようにサンプリングしている
- KG completionタスクではFreebase, WordNetデータを使っている
結果
Entity Alignment Results
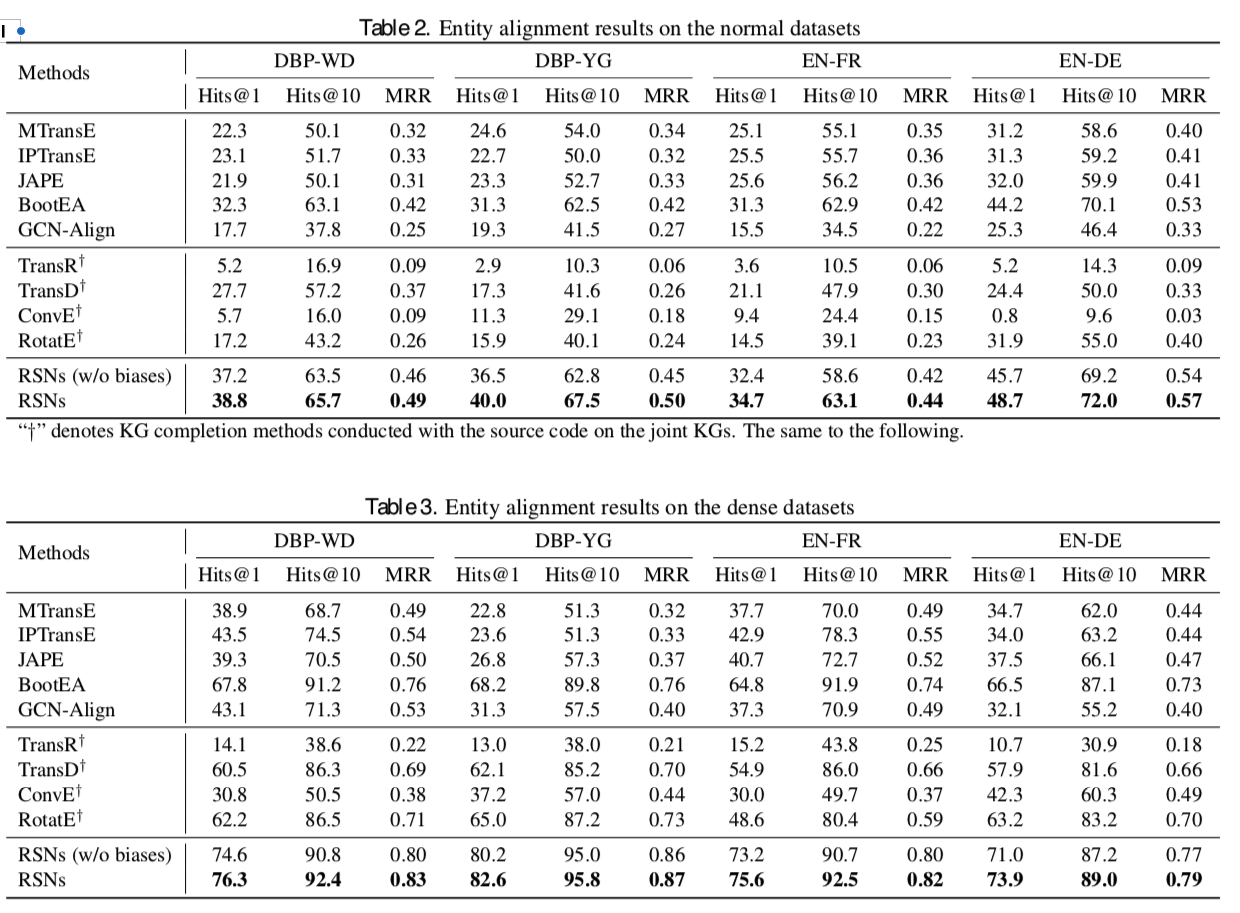
- SOTAを達成している
- denseデータの場合、relational pathの数が多いため、従来手法と比べるとより大きいパフォーマンス差を出している
Knowledge Completion
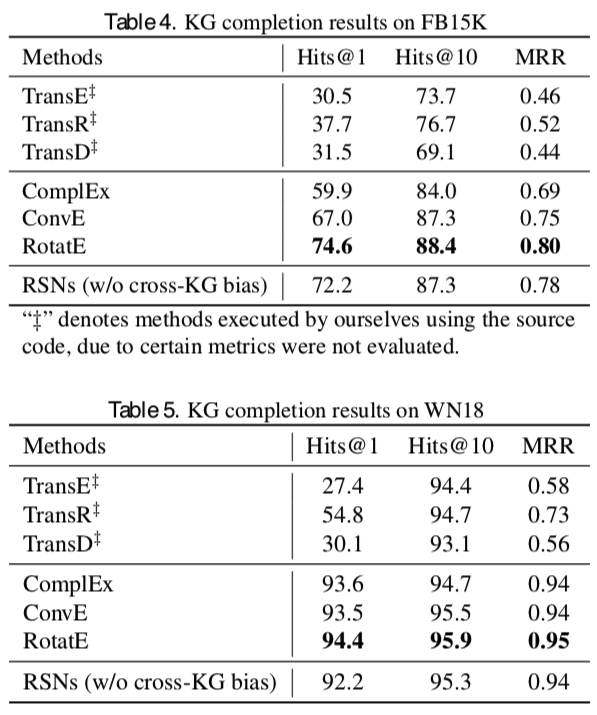
- 最高のパフォーマンスを出してはいないがcompetitiveな結果は出している
- 他の手法はKnowledge Completionタスクに特化した手法であることを考えると、提案手法の方は汎用性がある
まとめ
今回の論文を読んで個人的には以下のようなものが得られました。
- message passing algorithmで情報伝搬の仕組み
- GCN(Graph Convolutional Network)的考え
- PageRank的考え
- RNN的考え (long-term info を持つデータを入力)
- 小まめな知識
- データサンプリング
- segment-based random PageRank sampling(SRPRS)
- オリジナルデータと同じdegree distributionを持つようにサンプリングが可能
- segment-based random PageRank sampling(SRPRS)
- データセットの比較手法 (measure distribution difference)
- サンプリング結果とオリジナルデータの分布がどれぐらい違うかを測る
- Kolmogorov-Smirnov (K-S) test
- loss関数計算
- Type-based Noise-contrastive estimation
- negative samplingを行うことで、loss関数の計算量を減らす
-Weight initialize method
- negative samplingを行うことで、loss関数の計算量を減らす
- Xavier initializer (用調査)
- Type-based Noise-contrastive estimation
- データサンプリング