はじめに
ネット販売をしている知人からアマゾンの商品を探したい依頼があったのでいろいろ調べてみたらscrapyというのを知り使ってみました。
ちなみに僕はこの分野で専門家ではないので説明が足りないかもしれません。ご了承ください。
この記事はMacを使い、最初からScrapyを動かすどころまで説明します。
では、Scrapyとは
スクレイピングとクローリングを行うPythonで作られたフレームワークだそうです。要は、公開されているHTMLページから特定のデータをマクロ的に収集するツールを作れるものです。json, csvのようなファイル形式で抽出ができれば、設定によりDBにも直接入れるもの可能らしいです。詳しい内容は他の記事を。。
僕は商品リストだけ抽出だけでよかったのでここでの説明はファイル形式になります。
ちなみにscrapyにもっと知りたい方はこちらのScrapy公式サイトをみてください。ドキュメント(英語)も用意してあります。
環境設定
まず、scrapyを動かすためにはいくつかインストールが必要です。この記事はMac基準で説明にします。ちなみにいろいろ記事をみてると Windowsは結構面倒なようなのでやめたほうが良いかもしれません。仮想環境を作り、Ubuntuで動かす方法もありだと思います。
[Windowに導入するのはこちら]
まず、Pythonをインストール
MacにはデフォルトでPython2.xがインストールされていると思いますが、今回はPython3.xをインストールします。
Python3をbrewを利用しインストールします。もし、brewがインストールされてない方はまずbrewのインストールをしてください。
https://brew.sh/index_ja.html
リンクでもありますが、ターミナルで下記のコマンドを実行すればOKです。
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
brewが準備できたらPython3をインストールです。ターミナルにbrew install python3と打ち込むだけです。
もし、インストール中に**”Warning: Building python3 from source:”**という警告メッセージが出てきたら、Xcodeのコマンドラインツールをインストールする必要があるので、
xcode-select --installを実行してXcodeのライセンスに同意してインストールを行ってください。
インストールを確認してみましょう。
下記のようにバージョン表示されたらOKです。
$ python -V
Python 3.6.0
$ pip3 -V
pip 9.0.1 from /usr/local/lib/python3.6/site-packages (python 3.6)
*pyenvを利用してPythonをインストールする方法もあるのでPythonバージョン管理が必要な方はこの方法でやってください。
https://qiita.com/yutaro_sakaguchi/items/72b17dfea1efa05aded4
scrapyをインストール
簡単。叩くだけです。
pip install scrapy
Scrapyプロジェクト生成
フレームワークがインストールできたらプロジェクを生成してみましょう。Railsみたいにターミナルからコマンドを叩きます。
$ scrapy startproject helloscrapy
$ tree helloscrapy/
helloscrapy/
├── helloscrapy
│ ├── __init__.py
│ ├── __pycache__
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ ├── __init__.py
│ └── __pycache__
└── scrapy.cfg
- treeコマンドを使うなら
brew install tree
コマンドを叩くとプロジェクトフォルダー、ファイルが作られます。フォルダー構造、ファイルについて簡単に説明します。
spider
データを取り出すクローラです。何かをスクラッピングしたい時にspider(スパイダー)を作成し、規則などのコードを書きます。
items
取り出したデータのモデルです。spiderによって生成されます。
pipelines
取り出したitemを処理していくパイプライン。データベースなどに入れる場合使います。(今回はファイル形式の抽出なので使いません。)
middlewares
よくわかりませんが、今回使わないです。
settings
色々な設定の定義をします。今回はいくつか修正します。
Spider(スパイダー)を作成
ではまずSpiderを定義します。Spiderを作るのもscrapyコマンドから生成します。
$ scrapy genspider AmazonProduct amazon.co.jp
のように叩きます。スパイダー(spider)名とターゲットになるドメインをパラメーターの入力です。
とりあえずコードを書こう
生成されたスパイダー(spider)をみてみましょう。
# -*- coding: utf-8 -*-
import scrapy
class AmazonProductSpider(scrapy.Spider):
name = 'AmazonProduct'
allowed_domains = ['amazon.co.jp']
start_urls = ['http://amazon.co.jp/']
def parse(self, response):
pass
parse関数はresponseを受け取ってそこからデータ(Itemのサブクラス、辞書オブジェクトなど)と次に見るべきURL(Requestオブジェクト)をyieldで返します。(HTMLページの構成によって対応する必要があります。)
僕の場合は下記のような条件でスクラッピングしてみました。
- 特定の商品がどのページにあるかを知りたい
- 特定の商品のみ保存したい
- Webpageはページングになっている。
- 取得した時間も保存したい
まず、完成したコードから説明をすると、
# -*- coding: utf-8 -*-
import scrapy
from pytz import timezone
from datetime import datetime as dt
from helloscrapy.items import MyproductsItem
class SearchproductsSpider(scrapy.Spider):
name = 'searchProducts'
allowed_domains = ['amazon.co.jp']
#パソコン・周辺機器カテゴリの「ケーブル」のキーワードでリングを設定しました。このように開始するリンクを設定します。また、複数設定もできます。
start_urls = (
'https://www.amazon.co.jp/s/ref=nb_sb_noss_1?__mk_ja_JP=%E3%82%AB%E3%82%BF%E3%82%AB%E3%83%8A&url=search-alias%3Dcomputers&field-keywords=%E3%82%B1%E3%83%BC%E3%83%96%E3%83%AB',
)
def parse(self, response):
for sel in response.xpath('//div[@class="s-item-container"]'):
#タイトルに含まれている文字列を指定
title_str = sel.xpath('div[@class="a-row a-spacing-none"]/div[@class="a-row a-spacing-mini"]/a[@class="a-link-normal s-access-detail-page s-color-twister-title-link a-text-normal"]/@title').extract_first()
if 'iPhone' in title_str:
#データ取得時間を設定
now = dt.now(timezone('Asia/Tokyo'))
date = now.strftime('%Y-%m-%d')
jst_time = now.strftime('%Y-%m-%dT%H-%M-%S')
product = MyproductsItem()
#タイトル
product['title'] = sel.xpath('div[@class="a-row a-spacing-none"]/div[@class="a-row a-spacing-mini"]/a[@class="a-link-normal s-access-detail-page s-color-twister-title-link a-text-normal"]/@title').extract_first()
#サームネイル
product['thumbnail'] = sel.xpath('div[@class="a-row a-spacing-base"]/div/a/img/@src').extract_first()
#キーワード
product['keyword'] = response.xpath('//input[@id="twotabsearchtextbox"]/@value').extract_first()
#リンク
product['detail_link'] = sel.xpath('div[@class="a-row a-spacing-none"]/div[@class="a-row a-spacing-mini"]/div[position()=1]/a/@href').extract_first()
#ページカウント
product['page_count'] = response.xpath('//div[@id="bottomBar"]/div/span[@class="pagnCur"]/text()').extract_first()
#ページURL
product['url'] = response.url
#データ取得時刻
product['timestamp'] = jst_time
yield product
#次のリンクをチェックし、Requestを発行します。
next_page = response.xpath('//a[@id="pagnNextLink"]/@href')
if next_page:
url = response.urljoin(next_page[0].extract())
yield scrapy.Request(url, callback=self.parse)
# pass
ソースから2行目のfrom pytz import timezoneがありますが、これは時間取得のため、pytzのパッケージです。(使うためには下記のコマンドで先にインストールが必要です。)
pip install pytz
そして、外部で環境へdeployの時にはrequirements.txtにpytzを追加が必要があります。
(あとで説明しますが、クラウドサービスを利用する場合に必要です。)
他にはコメントで説明をしているのですぐ分かると思いますが、主にHTMLのタグから知りたい文字列を探し、条件比較、文字列を抽出するのがメインです。そのためにはXPathというセレクターの使い方を覚える必要があります。
XPathの文法は下記のドキュメントを参考してください。
https://doc.scrapy.org/en/latest/topics/selectors.html
最後に、スクラッピングしたデータはMyproductsItemモデルに保存していますが、このモデルはitems.pyに定義します。
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class MyproductsItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
thumbnail = scrapy.Field()
keyword = scrapy.Field()
detail_link = scrapy.Field()
page_count = scrapy.Field()
url = scrapy.Field()
timestamp = scrapy.Field()
# pass
デバックのやり方
ます、スクラッピングするページの構造を確認しなければなりません。僕の場合Chromeを使いました。
メニューバーから「表示」ー>「開発/管理」ー>「デベロッパーツール」を選択します。
その後、知りたい文字列を選択し、右クリックで「検証」を選択すると該当するタグが分かります。
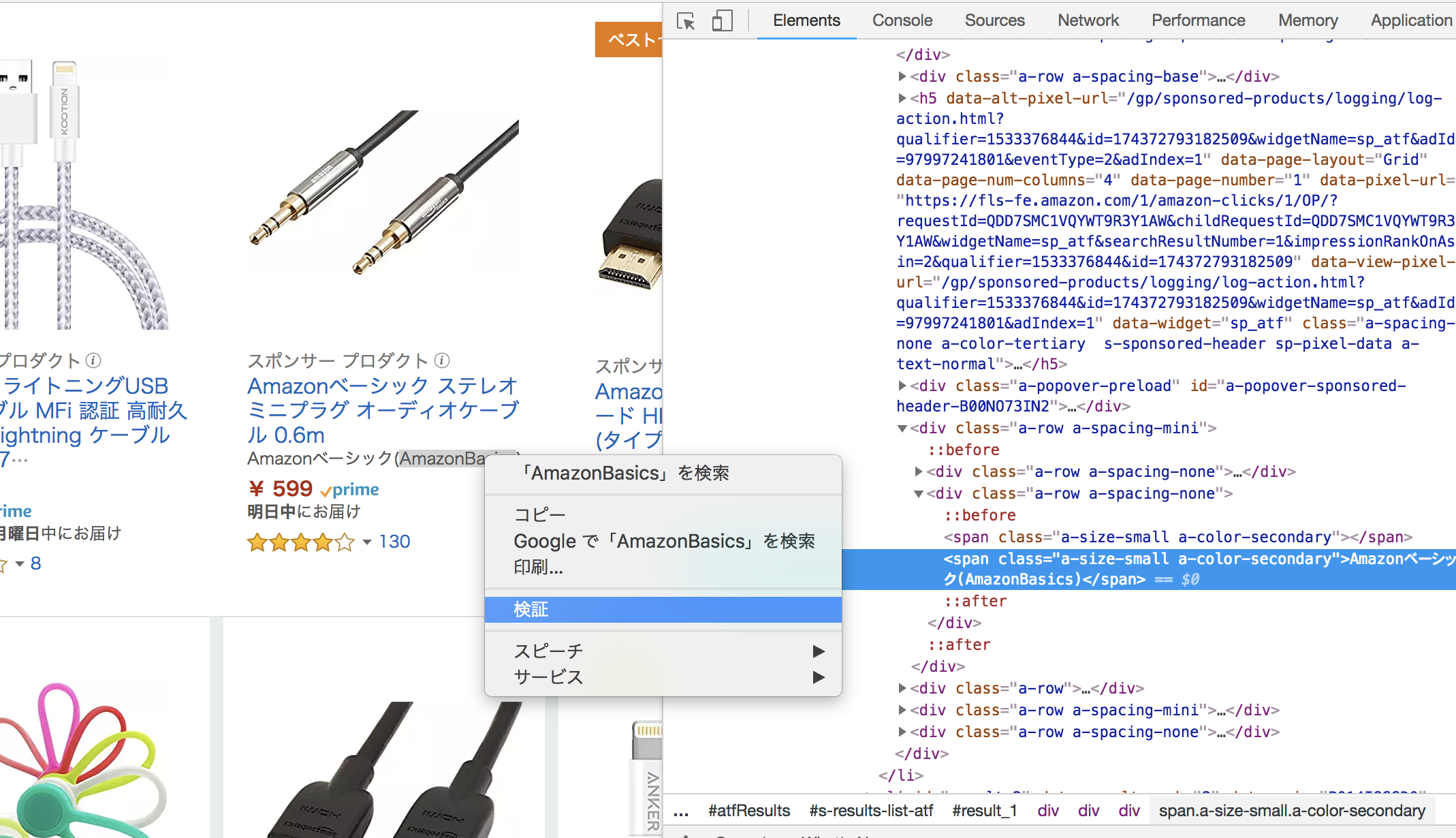
どのタグでどのような構成であるのかが分かったらXPathで形式で書きましょう。書いたXPathを検証するには下記のコマンドで確認できます。
scrapy shell 「"スクラッピングするURL"」
ターミナルから下記のように叩きます。
scrapy shell "https://www.amazon.co.jp/s/ref=nb_sb_noss_1?__mk_ja_JP=%E3%82%AB%E3%82%BF%E3%82%AB%E3%83%8A&url=search-alias%3Dcomputers&field-keywords=%E3%82%B1%E3%83%BC%E3%83%96%E3%83%AB"
実行できから下記のコマンドでXPathをresponseから検証できます。
response.xpath('//input[@id="twotabsearchtextbox"]@value').extract()[0]
実行モードを中止したい場合はCtrl+Dで終了します。
実行する前に設定しないといけないこと(重要)
settings.pyを少し編集します。
特に、DOWNLOAD_DELAYを短くするとウェブサイトを攻撃するようになってしまうので十分注意が必要です。
あと、情報取集のルールであるrobots.txtを従う設定もTrueにしましょう。
# 日本語文字化けのためにEncode設定、そして出力形式を指定します。(csvの代わりにjsonも可能です)
FEED_EXPORT_ENCODING='utf-8'
FEED_FORMAT = 'csv'
# 1つのページをダウンロードしてから、次のページをダウンロードすするまでの間隔(単位:秒)
DOWNLOAD_DELAY = 10
# robots.txtがある場合は、それに従うかどうか
ROBOTSTXT_OBEY = True
# 再帰的に探査を行う深さ(0は無制限)
DEPTH_LIMIT = 5
実行してみる
それが一通り完成できたら、クローラー実行&ファイル出力できます。
scrapy crawl AmazonProduct -o sample_data.csv
もっと楽な方法もある
有料サービスでありますが、scrapyをクラウドでできます。spider実行、管理から抽出データの管理、スケジュールもできるので本格的にやってみたい方は良いサービスだと思います。1つまでは無料なので簡単なテストもできます。
最後に
Pythonで経験がない僕もとりあえず、クローラーを作ることができました。プログラミングの経験がある方だと目的に合うクローラーは作れると思います。