今回は、Step6 です。Step5 で Twitter API から ADLS Gen2 への継続的なツイート データの蓄積ができるようになっていますので、このステップ以降は Azure Synapse Analytics での分析を行っていきます。
※Twitter API 自体については、Step1、Step2 をご参照ください。
※Step6 から開始できるように、GitHub にサンプルのツイート データ (Parquet ファイル) を共有しています。
Step6 の目標
Step5 までで、Twitter のツイート データを Azure Data Lake Storage Gen2 (ADLS Gen2) に Parquet 形式のファイルとして自動的に蓄積できるようになっています。このステップでは、Azure Synapse Analytics をセットアップし、Serverless SQL pool を使って、SQL 文でデータ分析をできるようにすることが目標です。

Azure Synapse Analytics (ワークスペース) のデプロイ
Azure Synapse Analytics は、以下のように複数の PaaS を統合した SaaS 型のサービスになっています。ワークスペースをデプロイすると、Studio / Serverless SQL / Pipelines がすぐに利用可能になります。Studio の利用は無償、Serverless SQL はクエリ実行時の処理データ量課金 (672円/TB。但し、2021/07/31 までは 10 TB/月は無償)、Pipelines はパイプラインやデータ フローの実行時間課金となります。価格の詳細は、Azure の価格ページをご参照ください。

手順 (1)
Azure ポータルの上部の検索ボックスから「synapse」と入力して、「Azure Synapse Analytics」を選択します。

手順 (2)
「+作成」をクリックします。
手順 (3)
「Synapse ワークスペースの作成」画面の「基本」タブでは、以下を入力し、「次へ」をクリックします。
- リソース グループ名
- ワークスペース名(グローバルで重複しない名前)
- 地域(ツイート データを蓄積している ADLS Gen2 ストレージと同じリージョン)
- ストレージ カウント名(ツイート データを蓄積している ADLS Gen2 ストレージ アカウント名 ※1)
- ファイル システム名(ツイート データを蓄積している ADLS Gen2 ファイル システム名 ※1)
※1: ツイート データを蓄積している ADLS Gen2 ストレージとは別に新規に作成しても構いません。その場合、後ほど、Synapse Studio にてツイート データを蓄積している ADLS Gen2 ストレージをリンク設定する必要があります。

手順 (4)
「Synapse ワークスペースの作成」画面の「セキュリティ」タブでは、以下を入力し、「次へ」をクリックします。
- 管理者ユーザー名(任意のユーザー名)
- パスワード
- パスワードの確認

手順 (5)
「Synapse ワークスペースの作成」画面の「ネットワーク」タブでは、「マネージド仮想ネットワークの有効化」をチェックし、「確認および作成」をクリックします。

手順 (6)
入力内容を確認した後、「作成」をクリックします。5-10 分ほどで、デプロイは完了します。


Synapse Studio の利用開始
Synapse Studio は、データ分析、アプリの開発、モニタリング、運用管理の為の包括的な Web ツールになっています。
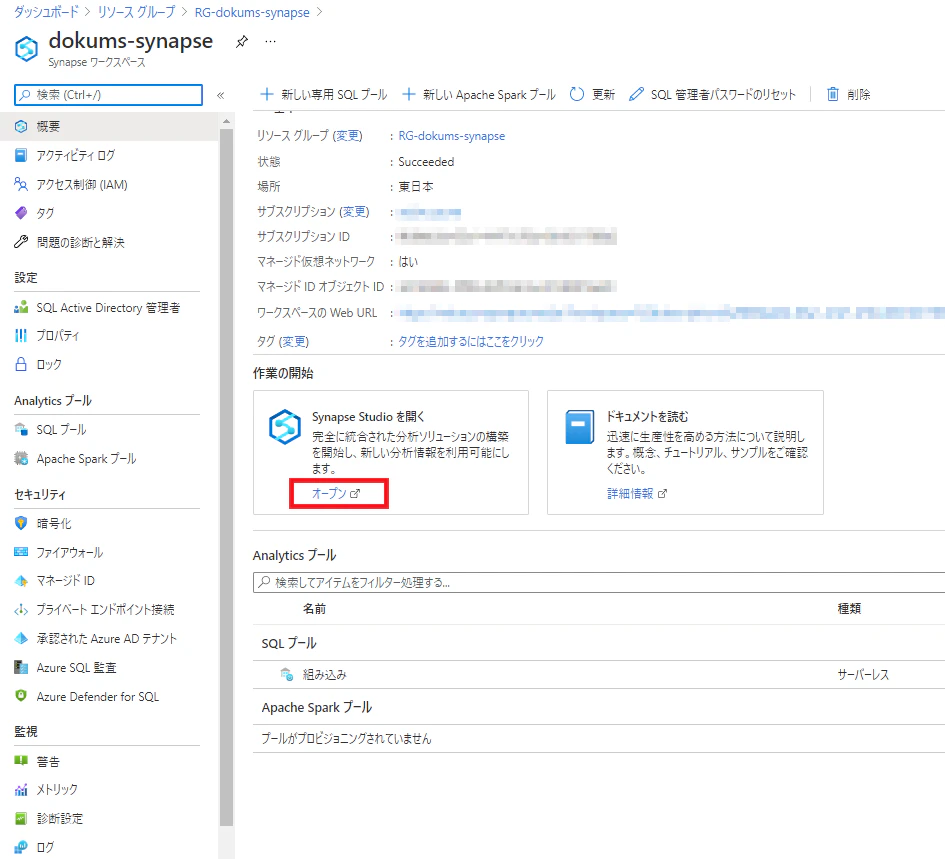
1. Synapse Studio の起動
作成した Synapse ワークスペース のページから、以下赤囲みの「オープン」をクリックして、Synapse Studio を起動します。
Synapse Studio の「ホーム」画面が開きます。左のブレードに利用目的に応じたハブ(「データ」「開発」「統合」「モニター」「管理」)が配置されています。

2. ツイート蓄積ファイルの一覧表示
「データ」ハブで、「リンク済み」タブ → 対象の ADLS Gen2 ファイルシステムを開き、ツイート データを蓄積しているフォルダーを見つけ、対象のフォルダーをダブルクリックして、作成されているファイルを一覧表示します。
※Step6 から開始したい方 (Step1 ~ Step5 を割愛される方) は、GitHub の Parquet ファイルをご利用ください。


Synapse Serverless SQL の利用開始
Serverless SQL は、データを配置する内部ストレージを持っておらず、ADLS Gen2 ストレージ上のファイル (現在、CSV / JSON / Parquet 形式のファイルに対応) に直接クエリを行います。データ量や処理負荷に応じて、自動的にノードを追加して処理することが出来る拡張性の高い仕組みになっています。

1. ADLS Gen2 ストレージへの認証
ユーザーによるインタラクティブな分析時のデフォルト認証方式は、Azure AD パススルー認証となり、ジョブとして自動化する際などは、Managed ID 認証 (Synapse Analytics ワークスペース名) を利用することになります。ADLS Gen2 ストレージの「アクセス制御 (IAM)」設定に、自分の Azure AD アカウント名 および Synapse Analytics ワークスペース名 (この場合、dokums-synapse) が、「ストレージ BLOB データ共同作成者」ロールとして表示されるか確認してください。もし、表示されていなければ、追加してください。

2. CREATE DATABASE の実施
データは保持しませんが、メタデータ (CREATE EXTERNAL TABLE / CREATE VIEW などの定義) を格納する為のデータベースを作成します。
手順 (1)
「開発」ハブを選択し、「+」→「SQL スクリプト」をクリックします。

手順 (2)
接続先:「組み込み」、データベースの使用:「master」の状態で、以下のクエリを実行します。データベース名 (ServerlessDB) は必要に応じて変更してください。サフィックスに「_UTF8」が付いた照合順序であれば、既定のエンコードとして問題ありませんが、「Latin1_General_100_BIN2_UTF8」は処理性能面で一番オーバーヘッドが少ない設定となります。

CREATE DATABASE ServerlessDB
COLLATE Latin1_General_100_BIN2_UTF8;
3. 特定ファイルに対するクエリ
手順 (1)
「データ」ハブで、ツイート データのファイルを一覧表示し、表示したいファイルを右クリックし、「新しい SQL スクリプト」→「上位 100 行を選択」をクリックし、クエリを自動生成します。

手順 (2)
「データベースの使用」として、先ほど作成した「ServerlessDB」を選択し、クエリを実行します。もし、データベースが候補に出て来なかったら、右の「最新の情報に更新」用のアイコンをクリックしてください。

4. ツイート データ全体に対するクエリ
ファイル パスについては、以下のようにワイルドカード (*) を使えます。ツイート データの蓄積の為に、ファイル パスに年月日時を入れてパーティション化していますので、その値を指定すれば、IO 範囲を絞ることができます。以下のクエリでは、ストレージ アカウント名とファイルシステム名を置換して実行してください。
-- ツイートデータの表示 (100 行)
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK 'https://your-storage-account.dfs.core.windows.net/your-filesystem/tweetdata/*/*/*/*/*.parquet',
FORMAT='PARQUET'
) AS [result]

-- トータル件数の取得
SELECT COUNT(*) total_rows FROM
OPENROWSET(
BULK 'https://your-storage-account.dfs.core.windows.net/your-filesystem/tweetdata/*/*/*/*/*.parquet',
FORMAT='PARQUET'
) AS [result]

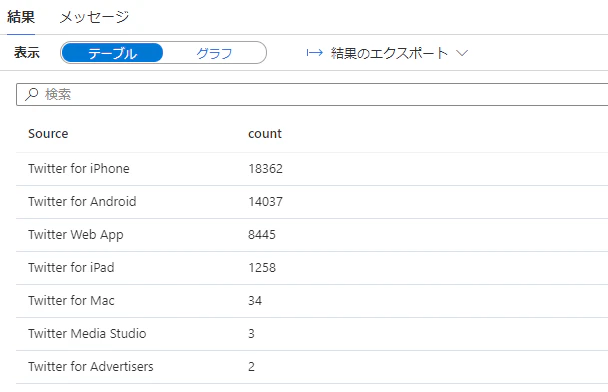
-- ツイートのソース (デバイス) 毎の比率
SELECT [Source], count(CreatedBy) AS [count] FROM (
SELECT distinct CreatedBy, [Source]
FROM
OPENROWSET(
BULK 'https://your-storage-account.dfs.core.windows.net/your-filesystem/tweetdata/*/*/*/*/*.parquet',
FORMAT='PARQUET'
) AS [result]
) AS T
GROUP BY [Source]
ORDER BY [count] DESC

5. 処理データ量の確認と制限
処理データ量は、課金に関わりますので、定期的に確認したり、制限を掛けておくことは重要です。
(1) クエリ毎の処理データ量
「モニター」ハブで、「SQL 要求」をクリックすると、実行したクエリの一覧を取得でき、「処理済みデータ」量を確認することができます。

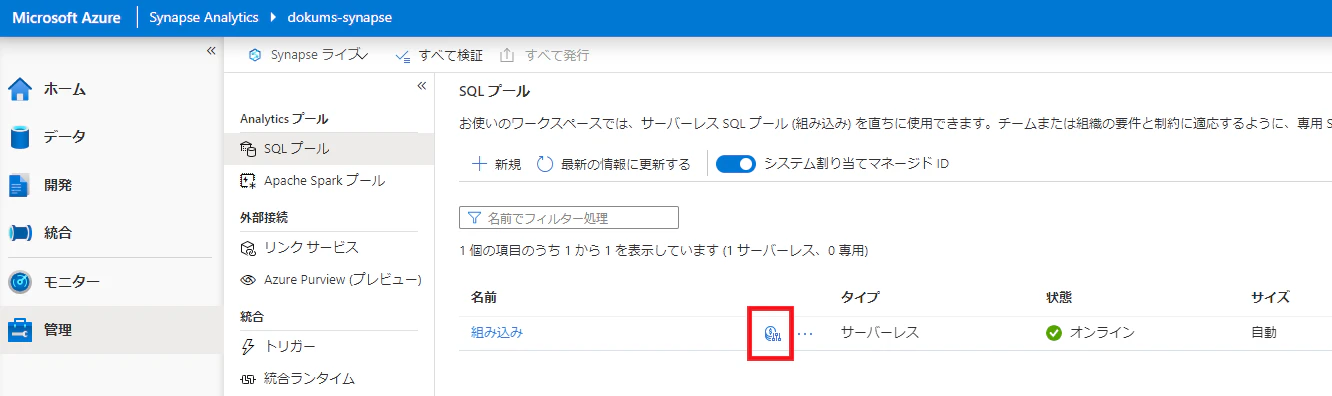
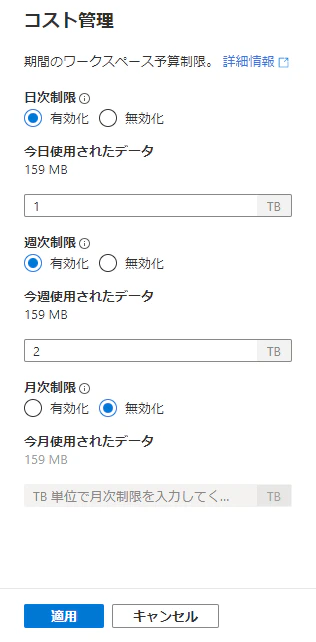
(2) Serverless SQL 合計の処理データ量
「管理」ハブで、「SQL プール」を表示し、組み込みプール (Serverless SQL) の赤囲みの「コイン」アイコンをクリックすると、「コスト管理」ブレードが表示され、処理データ量を日次、週次、月次の単位で確認、および、制限設定することができます。
次のステップへ
Step7 では、Azure Synapse Analytics - Apache Spark を利用して、ツイート データの感情分析とキーワード分析を行います。
参照
Azure Synapse Analytics での Synapse Studio SQL スクリプト
Azure Synapse Analytics ドキュメント - 概要
Azure Synapse Analytics 価格
Azure Synapse Analytics サイト