今回は、Step7 で、最終回となります。Step6 では、Twitter API から取得したツイート データを Synapse Serverless SQL から扱ってみました。このステップでは、Python (PySpark) を使って、もう少し分析っぽいことをしてみたいと思います。
※Twitter API 自体については、Step1、Step2 をご参照ください。
※Step7 から開始できるように、GitHub にサンプルのツイート データ (Parquet ファイル) を共有しています。
Step7 (最終回) の目標
このステップの目標は、Azure Synapse Analytics の Apache Spark と Azure Cognitive Services の Text Analytics API を使って、ツイート データの感情分析とキーフレーズ抽出&分析を実践し、その結果をテーブルとして保存することです。
Synapse Spark プール (Spark Cluster) の作成
Step6 で簡単に説明しましたが、Azure Synapse Analytics は、以下のように複数の PaaS を統合した SaaS 型のサービスになっています。その中で、Spark はインメモリ型の並列データ処理/機械学習プラットフォームとなっており、Azure Synapse Analytics ワークスペースをデプロイ後、Spark プール (Spark Cluster) を作成する必要があります。ワークスペースのデプロイ手順については、Step6 の手順をご参照ください。ここでは、Synapse Spark プール (Spark Cluster) の作成手順を説明します。

手順 (1)
Spark プールの作成は、Azure ポータルで対象の Azure Synapse Analytics ワークスペースから「Apache Spark プール」、もしくは、Synapse Studio の「管理」ハブ → 「Apache Spark プール」から行うことができます。いずれも、上部メニューの「+新規」をクリックしてください。
[Azure ポータル]

[Synapse Studio]

手順 (2)
ここでは、Synapse Studio での手順を説明します。「Apache Spark プールの作成」画面の「基本」タブでは以下の項目を入力し、「次へ」をクリックします。
- Apache Spark プール名:今回は SparkPool1 にしておきます
- ノードサイズ:今回は small にしておきます
- 自動スケーリング:有効にしておくと、負荷に応じてノード数が最小~最大の範囲で自動的に変動します。今回は有効にしておきます
-
ノード数:最小は 3 (Driver node:1 / Worker node:2)で、最大は 200 となります。必要に応じて最大を変更してください。

手順 (3)
「Apache Spark プールの作成」画面の「追加設定」タブでは、以下を入力し、「確認および作成」をクリックします。
- 自動一時停止中:自動停止 (Auto Terminate) の機能です。課金を少なくする為、今回は有効にしておきます。
- アイドル状態の時間 (分):利用しない時間がこの設定を超えると自動停止します。今回は 15 分のままとします。
-
Apache Spark:バージョンの設定です。今回は 2.4 のままとします。

手順 (4)
入力内容を確認した後、「作成」をクリックします。1 分ほどで作成は完了し、以下のように Spark プールが表示されます。
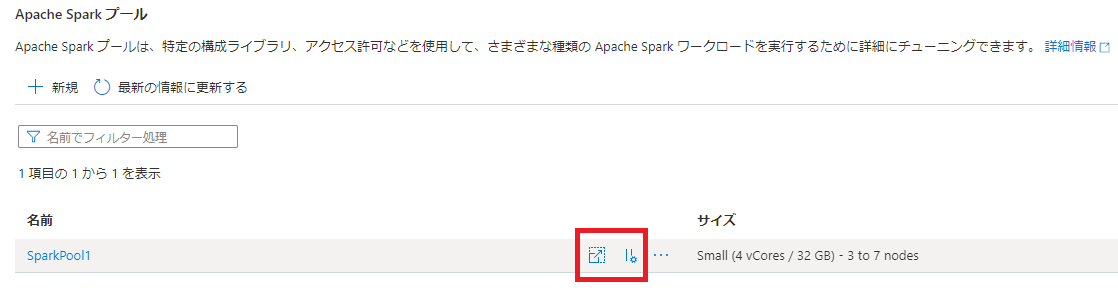
上記「サイズ」の左側に表示される赤枠の「スケーリング設定」アイコンをクリックすると、ノードサイズ、自動スケーリング、ノード数の設定を変更することが可能です。

上記「サイズ」の左側に表示される赤枠の「一時停止設定」アイコンをクリックすると、自動一時停止 の有効・無効、アイドル状態の時間の設定を変更することが可能です。

Text Analytics API のセットアップ
感情分析やキーフレーズ抽出を行う為、Azure Cognitive Services の Text Analytics API を利用できるようにします。
手順 (1)
Azure ポータルを開き、左上の「メニュー」を展開し、「+ リソースの作成」を選択します。
手順 (2)
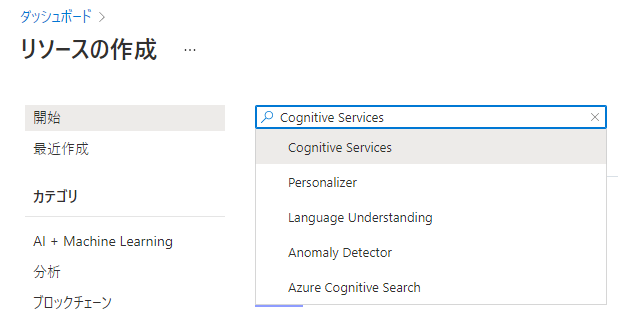
「リソースの作成」ページの検索ボックスで、「cognitive」と入力し、候補の「Cognitive Services」をクリックします。
手順 (3)
「作成」ボタンをクリックします。

手順 (4)
以下の項目を入力し、「確認および作成」をクリックします。
- リソース グループ名
- リージョン (Synapse ワークスペースと同じリージョンが望ましい)
- 名前 (グローバルで重複しない名称)
- 価格レベル (Standard S0)

手順 (5)
入力内容を確認後、「作成」をクリックします。

手順 (6)
作成した Cognitive Services の API Key を取得します。

Synapse Spark プールの利用開始
Synapse Spark の特徴は、作成したデータベースとテーブルのメタデータが、Synapse Analytics ワークスペース内のすべての Spark プールで共有されるとともに、Synapse Serverless SQL のメタデータとして自動的に反映される共有メタデータ モデルを提供していることです。これにより、ワークスペース内で、シームレスに ADLS Gen2 上のデータを扱うことが可能になります。
1. ADLS Gen2 ストレージへの認証
ユーザーによるインタラクティブな分析時のデフォルト認証方式は、Azure AD パススルー認証となり、ジョブとして自動化する際などは、Managed ID 認証 (Synapse Analytics ワークスペース名) を利用することになります。ADLS Gen2 ストレージの「アクセス制御 (IAM)」設定に、自分の Azure AD アカウント名 および Synapse Analytics ワークスペース名 (この場合、dokums-synapse) が、「ストレージ BLOB データ共同作成者」ロールとして表示されるか確認してください。もし、表示されていなければ、追加してください。

2. CREATE DATABASE
メタデータ (CREATE TABLE 定義) を格納する為のデータベースを作成します。
手順 (1)
Synapse Studio の「開発」ハブを選択し、「+」→「ノートブック」をクリックします。

手順 (2)
アタッチ先:「SparkPool1」、言語:「PySpark (Python)」の状態で、以下のスクリプトをセルの横にある「再生」ボタン、もしくは、セル内にカーソルを持って行き、Shift + Enter で実行します。データベース名 (sparkDB) は必要に応じて変更してください。
spark.sql('CREATE DATABASE sparkDB')

3. 感情分析とキーフレーズ抽出の実施
Azure Cognitive Services の Text Analytics API は、Spark で実行する為の mmlspark ライブラリ (Microsoft Machine Learning for Apache Spark) を提供していますので、公式ドキュメントに従って実行してみましょう。
手順 (1) Spark テーブルの作成
Synapse Studio の「開発」ハブを選択し、CREATE DATABASE を実行したノートブックを開きます。CREATE DATABASE を実行したセルの左下にある「+」ボタンをクリックし、「コード セル」を選択します。
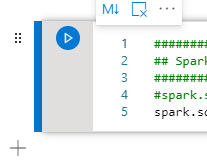
新しく作成されたセルに、以下の CREATE TABLE 文を入力し、セルの「再生」アイコンか、Shift + Enter でセルを実行してください。
- セルの先頭にある「%%言語」(以下の場合は、%%sql) を設定すると、ノートブックに設定された言語に関係なく、セル毎に実行する言語を設定できます。
- ツイート データ (Parquet ファイル群) のパスは、Step6 の Serverless SQL と同じになります。この Step7 から開始したい場合は、共有している GitHub のサンプルデータを ADLS Gen2 ストレージにアップロードしてください。
%%sql
----------------------------------------------------------------
-- Create TweetData table
----------------------------------------------------------------
CREATE TABLE IF NOT EXISTS sparkDB.TweetData
(
CreatedAt TIMESTAMP,
CreatedBy STRING,
Source STRING,
Text STRING
)
USING PARQUET
LOCATION 'abfss://<your_ADLS_filesystem_name>@<your_ADLS_storage_account>.dfs.core.windows.net/tweetdata/*/*/*/*/*.parquet'
[セルの実行結果]

手順 (2) ツイート データの確認
ノートブックにセルを追加して、以下の SQL を実行して、データの内容を確認します。指定した日付は変更してください。
%%sql
----------------------------------------------------------------
-- Select TweetData
----------------------------------------------------------------
SELECT * FROM sparkDB.TweetData
WHERE CreatedAt < '2021-05-23 00:00:00'
LIMIT(10)
[セルの実行結果]

手順 (3) ライブラリの参照
ここからは、新しいノートブック (同じノートブックを使っても問題はありません) を使いましょう。Azure Cognitive Services - Text Analytics API に必要なライブラリをインポートし、API 実行に必要な API Key を設定します。
###############################################################
## Cognitive Services - Text Analytics API
## https://docs.microsoft.com/ja-jp/azure/cognitive-services/big-data/getting-started
## https://docs.microsoft.com/ja-jp/azure/cognitive-services/big-data/samples-python
###############################################################
from mmlspark.cognitive import *
from pyspark.sql.functions import col
# Add your subscription key from Text Analytics (or a general Cognitive Service key)
service_key = "<your Cognitive Services API Key>"
[セルの実行結果]

手順 (4) Spark DataFrames (並列分散処理可能なデータフレーム) へのロード
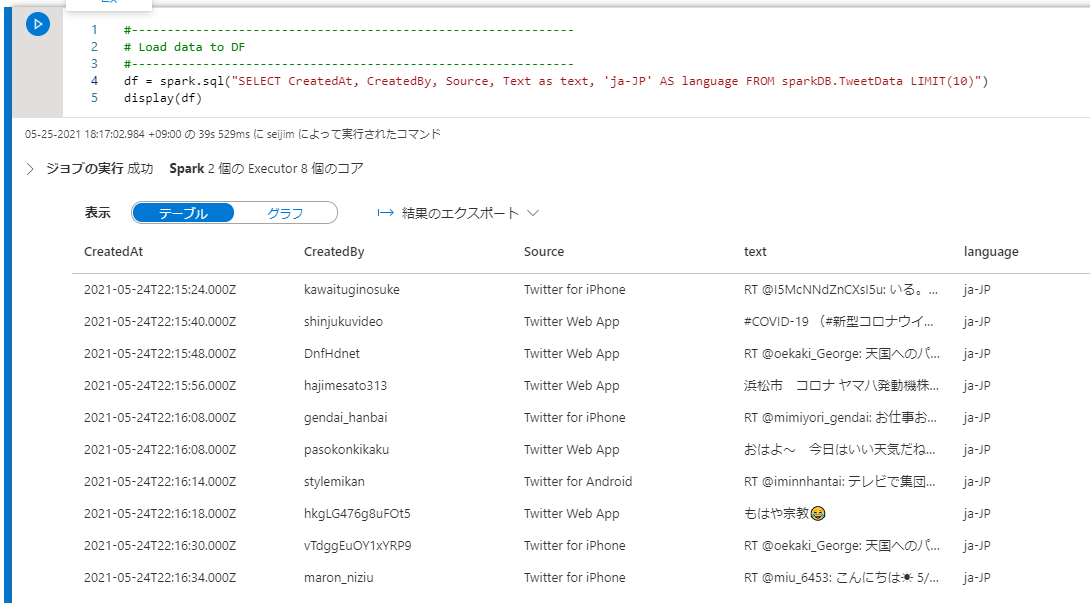
Text Analytics API に渡すパラメーターを設定した SQL を実行し、結果を DataFrame にロードします。API の動作を確認する段階ですので、この SQL では、10 件のデータ取得に留めます。
# --------------------------------------------------------------
# Load data to DF
# --------------------------------------------------------------
df = spark.sql("SELECT CreatedAt, CreatedBy, Source, Text as text, 'ja-JP' AS language FROM sparkDB.TweetData LIMIT(10)")
df.show()
[セルの実行結果]
手順 (5) Text Analytics API (感情分析) の呼び出しと結果の表示
Text Analytics API - TextSentiment() を使って、テキストから読み取れるポジティブ、中立、ネガティブの感情の信頼確率を取得します。
# --------------------------------------------------------------
# Infer sentiment of each DF row
# --------------------------------------------------------------
sentiment = (TextSentiment()
.setTextCol("text")
.setLocation("japaneast")
.setSubscriptionKey(service_key)
.setOutputCol("sentiment")
.setErrorCol("error")
.setLanguageCol("language"))
results = sentiment.transform(df)
display(results.select(
"text",
col("sentiment")[0].getItem("sentences")[0].getItem("confidenceScores").getItem("positive").alias("positive"),
col("sentiment")[0].getItem("sentences")[0].getItem("confidenceScores").getItem("neutral").alias("neutral"),
col("sentiment")[0].getItem("sentences")[0].getItem("confidenceScores").getItem("negative").alias("negative"),
))
[セルの実行結果]

手順 (6) Text Analytics API (キーフレーズ抽出) の呼び出しと結果の表示
Text Analytics API - KeyPhraseExtractor() を使って、キーフレーズ (複数) を抽出します。
# --------------------------------------------------------------
# Extract keyphrases of each DF row
# --------------------------------------------------------------
keyphrases = (KeyPhraseExtractor()
.setTextCol("text")
.setLocation("japaneast")
.setSubscriptionKey(service_key)
.setOutputCol("keys")
.setErrorCol("error")
.setLanguageCol("language"))
results = keyphrases.transform(df)
display(results.select(
"text",
#col("keys")[0].collect()
col("keys")[0].getItem("keyPhrases").alias("keyPhrases")
))
[セルの実行結果]

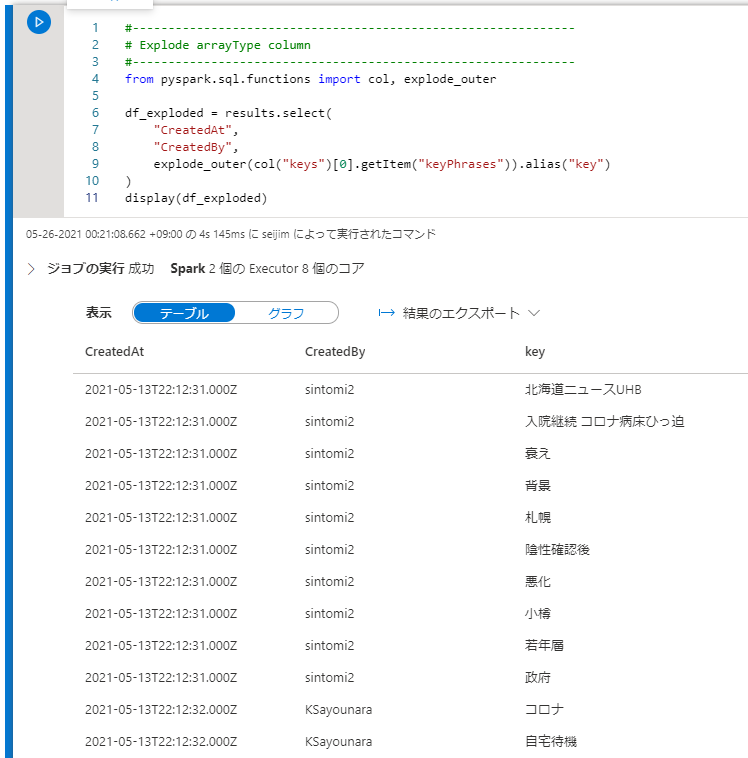
手順 (7) ArrayType カラムを縦方向 (行方向) に展開
キーフレーズの抽出結果は、1つのカラムに JSON の配列で返却されていました。これを集計し易いように縦方向 (行方向) に展開するのに、explode_outer 関数を利用します。
# --------------------------------------------------------------
# Explode arrayType column
# --------------------------------------------------------------
from pyspark.sql.functions import col, explode_outer
df_exploded = results.select(
"CreatedAt",
"CreatedBy",
explode_outer(col("keys")[0].getItem("keyPhrases")).alias("key")
)
display(df_exploded)
[セルの実行結果]
手順 (8) キーフレーズの集計
SQL で DataFrame を参照できるように、createOrReplaceTempView 関数で一時ビューを作成しておき、SQL でキーフレーズの集計を実行してみます。
df_exploded.createOrReplaceTempView("keysTable")
%%sql
----------------------------------------------------------------
-- Select TweetData
----------------------------------------------------------------
SELECT key, count(*) num FROM keysTable
GROUP BY key
ORDER BY num DESC
[セルの実行結果]

4. 分析結果をテーブルに保存し、集計分析を実施
項番 3 で、分析に必要なコードは揃いましたので、特定の日時までデータを全件読み出し、分析結果をテーブルに保存してみましょう。新しいノートブックを作成し、コードを記述して行きます。セル毎に実行しても、「すべて実行」しても構いません。
セル (1) ツイート データの読み込み
Cognitive Services API Key とツートデータの取得条件 (WHERE 句) を変更してください。
###############################################################
## Cognitive Services - Text Analytics API
## https://docs.microsoft.com/ja-jp/azure/cognitive-services/big-data/getting-started
## https://docs.microsoft.com/ja-jp/azure/cognitive-services/big-data/samples-python
###############################################################
from mmlspark.cognitive import *
from pyspark.sql.functions import col, explode_outer
# Add your subscription key from Text Analytics (or a general Cognitive Service key)
service_key = "<your Cognitive Services API Key>"
# Load data to DF
sqltext = '''
SELECT CreatedAt, CreatedBy, Source, Text as text, 'ja-JP' AS language
FROM sparkDB.TweetData
WHERE CreatedAt >= '2021-05-24 00:00:00'
AND CreatedAt < '2021-05-25 00:00:00'
'''
df = spark.sql(sqltext)
セル (2) 感情分析の実行
必要な項目を整形し、集計用テーブルへの保存に備えます。
# --------------------------------------------------------------
# Infer sentiment of each DF row
# --------------------------------------------------------------
sentiment = (TextSentiment()
.setTextCol("text")
.setLocation("japaneast")
.setSubscriptionKey(service_key)
.setOutputCol("sentiment")
.setErrorCol("error")
.setLanguageCol("language"))
res_sentiment = sentiment.transform(df)
# Edit sentiment DF
res_sentiment_edit = (res_sentiment.select(
"CreatedAt",
"CreatedBy",
"Source",
"text",
col("sentiment")[0].getItem("sentences")[0].getItem("confidenceScores").getItem("positive").alias("positive"),
col("sentiment")[0].getItem("sentences")[0].getItem("confidenceScores").getItem("neutral").alias("neutral"),
col("sentiment")[0].getItem("sentences")[0].getItem("confidenceScores").getItem("negative").alias("negative"),
))
# Create temp View
res_sentiment_edit.createOrReplaceTempView("sentimentView")
セル (3) 感情分析結果を格納するテーブル作成
DataFrame の関数で直接テーブルに追加保存することも出来ますが、ここではテーブルのスキーマを管理し易いように SQL で定義します。パーティションの定義も行い、性能面での考慮もします。
%%sql
----------------------------------------------------------------
-- Create analyzed TweetData table (Sentiment)
----------------------------------------------------------------
CREATE TABLE IF NOT EXISTS sparkDB.TweetSentimentData
(
CreatedAt TIMESTAMP,
CreatedBy STRING,
Source STRING,
text STRING,
sentiment STRING,
positive FLOAT,
neutral FLOAT,
negative FLOAT,
yy INT,
mm INT,
dd INT,
hh INT
)
USING PARQUET
PARTITIONED BY (yy, mm, dd, hh)
セル (4) 感情分析結果をテーブルに INSERT
後で集計し易いように、ポジティブ・中立・ネガティブの信頼確率だけでなく、sentiment というカラムに判定結果を格納します。
%%sql
----------------------------------------------------------------
-- Insert Data (Sentiment)
----------------------------------------------------------------
INSERT INTO sparkDB.TweetSentimentData
SELECT
CreatedAt,
CreatedBy,
Source,
text,
CASE WHEN (positive >= neutral) THEN
CASE WHEN (positive >= negative) THEN 'positive'
ELSE 'negative'
END
ELSE
CASE WHEN (neutral >= negative) THEN 'neutral'
ELSE 'negative'
END
END AS sentiment,
positive,
neutral,
negative,
year(CreatedAt) AS yy,
month(CreatedAt) AS mm,
day(CreatedAt) AS dd,
hour(CreatedAt) AS hh
FROM sentimentView
セル (5) キーフレーズ抽出と縦展開の実行
必要な項目を整形し、集計用テーブルへの保存に備えます。
# --------------------------------------------------------------
# Extract keyphrases of each DF row
# --------------------------------------------------------------
keyPhrases = (KeyPhraseExtractor()
.setTextCol("text")
.setLocation("japaneast")
.setSubscriptionKey(service_key)
.setOutputCol("keys")
.setErrorCol("error")
.setLanguageCol("language"))
res_keyPhrases = keyPhrases.transform(df)
# Explode arrayType column
res_key_exploded = res_keyPhrases.select(
"CreatedAt",
"CreatedBy",
explode_outer(col("keys")[0].getItem("keyPhrases")).alias("keyPhrase")
)
# Create temp View
res_key_exploded.createOrReplaceTempView("keyView")
セル (6) キーフレーズを格納するテーブル作成
DataFrame の関数で直接テーブルに追加保存することも出来ますが、ここではテーブルのスキーマを管理し易いように SQL で定義します。パーティションの定義も行い、性能面での考慮もします。
%%sql
----------------------------------------------------------------
-- Create analyzed TweetData table (KeyPhrase)
----------------------------------------------------------------
CREATE TABLE IF NOT EXISTS sparkDB.TweetKeyPhraseData
(
CreatedAt TIMESTAMP,
CreatedBy STRING,
keyPhrase STRING,
yy INT,
mm INT,
dd INT,
hh INT
)
USING PARQUET
PARTITIONED BY (yy, mm, dd, hh)
セル (7) キーフレーズ データをテーブルに INSERT
%%sql
----------------------------------------------------------------
-- Insert Data (KeyPhrase)
----------------------------------------------------------------
INSERT INTO sparkDB.TweetKeyPhraseData
SELECT
CreatedAt,
CreatedBy,
keyPhrase,
year(CreatedAt) AS yy,
month(CreatedAt) AS mm,
day(CreatedAt) AS dd,
hour(CreatedAt) AS hh
FROM keyView
セル (8) 感情分析結果テーブルとキーフレーズ テーブルの集計分析
感情分析結果テーブル sparkDB.TweetSentimentData は、感情分類 (ポジティブ・中立・ネガティブ) 単位に件数を集計し、キーフレーズ テーブル sparkDB.TweetKeyPhraseData の方は使われているキーフレーズ (ワード) の登場回数を集計し、それぞれ多い順に並べてみます。Twitter のツイートは、「コロナ」というキーワードでフィルタリングしたストリーム データを使い、24 時間収集を 2 週間ほど継続したものとなります。
Text Analytics API の精度検証は置いておいて、この結果のみから見えるのは、コロナ禍が1年以上続いていることもあり、ツイートの内容は比較的、冷静なもの (感情的な意見ではない) が多くなっていること、直近の緊急事態宣言、ワクチン、北海道、大阪への関心が高いこと、また、その情報リソースとして、「北海道ニュースUHB」や「jijimedical」がホットになっているのが分かります。
%%sql
----------------------------------------------------------------
-- Analyze sentiment of TweetData
----------------------------------------------------------------
SELECT sentiment, count(*) num
FROM sparkDB.TweetSentimentData
GROUP BY sentiment
ORDER BY num DESC

%%sql
----------------------------------------------------------------
-- Analyze keyPhrases of TweetData
----------------------------------------------------------------
SELECT keyPhrase, count(*) num
FROM sparkDB.TweetKeyPhraseData
GROUP BY keyPhrase
ORDER BY num DESC

Serverless SQL への Spark メタデータ自動反映
先述しましたが、Synapse Spark の特徴は、データベース定義やテーブル定義のメタデータが、Synapse ワークスペース全体で共有されるということです。Synapse Serverless SQL へも自動反映されており、テーブル名を sparkDB.TweetKeyPhraseData → sparkDB.dbo.TweetKeyPhraseData と変更するだけでアクセスが出来ます。SQL でインタラクティブに分析するには、プロビジョニングしたクラスターを起動する必要の無い Serverless SQL の方が素早く・低価格で出来ますので、データ加工は Spark で、データ分析は Serverless SQL でと分担することも可能です。
----------------------------------------------------------------
-- Analyze keyPhrases of TweetData (powered by Serverless SQL)
----------------------------------------------------------------
SELECT keyPhrase, count(*) num
FROM sparkDB.dbo.TweetKeyPhraseData
GROUP BY keyPhrase
ORDER BY num DESC
;

まとめ
Twitter API の C# での利用から始まり、Azure Functions による 24 時間のデータ収集&蓄積、Azure Synapse - Serverless SQL によるデータの確認、Azure Synapse - Apache Spark (Python) と Azure Cognitive Services - Text Analytics API によるデータ分析とデータ加工、そして、最後に加工済みデータを再度、Serverless SQL で集計分析してみました。
データ蓄積する期間や量にも寄ると思いますが、1,000 円以下で試せたのではないでしょうか。Azure の無料利用 (22,500 円のクレジット付) で十分遊べますので、是非トライしてみてください。
参照
Microsoft Machine Learning for Apache Spark
ビッグ データ向け Cognitive Services の Python サンプル - Text Analytics
Azure Cognitive Services - Text Analytics 概要
Azure Cognitive Services - Text Analytics
Azure Cognitive Services
Azure Synapse Analytics の共有メタデータ モデル
Azure Synapse Analytics の Apache Spark の主要な概念
Azure Synapse Analytics での Synapse Studio SQL スクリプト
Azure Synapse Analytics ドキュメント - 概要
Azure Synapse Analytics 価格
Azure Synapse Analytics サイト