トランザクション分離レベルは とても大事な概念 だと言われているが自分の中でイマイチちゃんと理解できていないことに気付いたのでまとめることにしました。
少し調べてみるとデータベースごと呼び方が微妙に違ったりするため、それぞれのデータベースごとに書かれていることを比較しつつまとめていく。
まずはトランザクション分離レベルを理解する前に トランザクション とは何かをおさらいしておこうと思います。
トランザクションとは?
MySQL と SQL Server の公式のドキュメントを確認しそれぞれどんなことが書かれているか確認してみます。
MySQL
MySQL の用語集では以下のように書かれています。
トランザクションは、committed または ロールバック済 の作業の原子単位です。
トランザクションによってデータベースに複数の変更が行われた場合、トランザクションがコミットされるとすべての変更が完了し、トランザクションがロールバックされるとすべての変更が元に戻されます。
MySQL 8.0 リファレンスマニュアル - MySQL 用語集 - トランザクション より
SQL Server
SQL Server のドキュメントでは以下のように以下のように書かれています。
トランザクションは、1 つの作業を表す単位です。
トランザクションが成功すると、トランザクションの実行中に行われたすべてのデータ変更がコミットされ、データベースの変更が確定します。
エラーが発生したため、トランザクションを取り消すか、またはロールバックする必要がある場合、すべてのデータ変更は消去されます。
Microsoft Docs - トランザクション (Transact-SQL) - SQL Server より
公式ドキュメントを踏まえてトランザクションとは?
どちらも似たようなことが書かれていますが重要なことは下記の3つになるかと思います。
- トランザクションは 作業単位(複数の操作)
- 変更が コミット されると データベースの変更がされる
- 変更が ロールバック されると データベースの変更が元に戻る
トランザクションは 作業単位のこと でトランザクションの 開始時点と終了時点でデータ一貫している ことを指している。
分離とは?
トランザクションは分かったが分離とは一体何を指しているのだろうか?
それを理解するためには ACID 特性 を理解する必要があります。
ACID 特性
トランザクションにおける 特性 のことを指します。
トランザクションは Atomicity(原子性), Consistency(一貫性), Isolation(分離性), Durability(持続性) の頭文字をとって ACID と呼ばれる4つの特性を持っています。
Atomicity(原子性)
トランザクションの中で実行される操作は 全て実行されるか全て実行されないか のどちらかになります。部分的に実行されるということはありません。
Consistency(一貫性)
トランザクションの開始時点と終了時点で データが一貫した状態になる ことです。
複数のデータに渡って更新した場合は開始時点のデータか終了時点のデータのどちらかに必ずなります。
データが一貫した状態になる にはあらかじめ与えられた 整合性(外部キーとかCHECK節とか)を満たす ことも含まれていると思います。
Isolation(分離性・独立性)
トランザクションの実行中は 他のトランザクションからの影響を受けない という性質です。
それぞれのトランザクションは分離されているため完了するまでデータを見ることはできません。
Durability(持続性)
トランザクションの 実行された結果は永続的に確定となる。システム障害が発生してもトランザクションの実行された結果がなくなることはない。
結局、分離とは?
一言で終わってしまうのですが、ACID 特性のうち Isolation(分離性・独立性)のこと を指しているものになります。
トランザクション分離レベル
トランザクション と 分離 についてまとめてきましたが本題の トランザクション分離レベル に入っていこうと思います。
トランザクション分離レベル とは 複数のトランザクションが同時に実行した時 にどれほどの 一貫性や結果の正確性で実行するか を定義したものです。
なぜトランザクション分離レベルが存在しているのか?
データは 一貫性が保たれてかつ正確 な方が良いと思いませんか?
しかし 一貫性が保たれてかつ正確なデータ を求めようとするとアプリケーションの パフォーマンスが落ちる(速度が遅い) ことになります。
トランザクションは いい具合に並行で処理させられればパフォーマンスを上げる ことができるため、即応性と正確性のバランスを考えつつ個々のトランザクションごとにどの分離レベルを使うべきか判断していくことが大事でしょう。
トランザクション分離レベルの違いによって起こりうる問題
実際の分離レベルを説明する前にそれぞれの分離レベルで起こりうる問題を先に知っておきましょう。
またデータベースによって呼び方も変わってくるので MySQL, PostgreSQl, Oracle での違いも見ていきます。
ダーティリード(Dirty Read)
Dirty は「汚れた、汚い」などの意味があり、読み込まれたものが確定されたものではなく常に変わる可能性のあるデータなためダーティリードと呼ばれている。
ではそれぞれのデータベースではどんな風に書かれているか見ていきましょう。
信頼できないデータ、つまり別のトランザクションによって更新されたけれども、まだコミットされていないデータを取得する操作。
これは、コミットされた読み取りと呼ばれる分離レベルでのみ可能です。
この種の操作は、データベース設計の ACID 原則には準拠しません。これは非常にリスクが高いと見なされます。
データをロールバックできたり、コミットされる前にさらに更新できたりするためです。
この場合、ダーティー読み取りを行うトランザクションは、正確であると確定されていないデータを使用することになります。
その反対は読取り一貫性であり、一方で他のトランザクションがコミットしても、InnoDB によって、別のトランザクションによって更新された情報が読み取られないことが保証されます。
同時に実行されている他のトランザクションが書き込んで未だコミットしていないデータを読み込んでしまう。
未コミットのトランザクションが書き込んだデータを、別のトランザクションが読み取る現象。
ファジーリード・ノンリピータブルリード(Fuzzy Read・Nonrepeatable Read)
トランザクション内で 一度取得したデータを再度取得 した時、別のトランザクションによって 更新(UPDATE)され最初に取得したデータと中身が違って取得 されてしまうこと。
Fuzzy は「はっきりしない、ぼやけた」などの意味があり、読み込まれる内容が一致しなくてはっきりしないデータが取得されてしまうことからファジーリードと呼ばれている。
ではそれぞれのデータベースではどんな風に書かれているか見ていきましょう。
あるクエリーがデータを取得し、同じトランザクション内のその後のクエリーが同じデータであるはずのものを取得するけれども、それらのクエリーが異なる結果を返す状況 (その間にコミットしている別のトランザクションによって変更された)。
トランザクションが、以前読み込んだデータを再度読み込み、そのデータが(最初の読み込みの後にコミットした)別のトランザクションによって更新されたことを見出す。
Oracle - 非リピータブル・リード(ファジー読取り) より
あるトランザクションが以前に読み取ったデータをもう一度読み取ったときに、コミットされた別のトランザクションによってそのデータが変更または削除されたことが明らかになる現象。
たとえば、ユーザーがデータに変更があるかどうかを知るためにのみ、ある行を問い合せ、後で再度同じ行を問い合せるという現象などのことです。
ファントムリード(Phantom Read)
トランザクション内で 一度取得したデータを再度取得 した時、別のトランザクションによって 追加(INSERT)または削除(DELETE)され最初に取得したデータ数と違って取得 されてしまうこと。
Phantom は「幻影」という意味もあり同じクエリーを2回実行した時、1回目の実行結果の行数と2回目の実行結果の行数が違って取得され、まるで幻影を見ていたかのように感じしてしまうことからファントムリードと呼ばれています。
ではそれぞれのデータベースではどんな風に書かれているか見ていきましょう。
あるクエリーの結果セットに出現するけれども、以前のクエリーの結果セットにない行。
たとえば、あるクエリーがトランザクション内で 2 度実行されて、その間に別のトランザクションがそのクエリーの WHERE 句に一致する新しい行を挿入または行を更新したあとにコミットされた場合です。
トランザクションが、複数行のある集合を返す検索条件で問い合わせを再実行した時、別のトランザクションがコミットしてしまったために、同じ検索条件で問い合わせを実行しても異なる結果を得てしまう。
あるトランザクションが検索条件を満たす一連の行を戻す問合せを2回実行する間に、コミットされた別のトランザクションによってその条件を満たす新しい行が挿入されたことが明らかになる現象。
たとえば、トランザクションから従業員数を問い合せるとします。5分後に同じ問合せを実行したところ、他のユーザーが新規従業員のレコードを挿入したため、戻される従業員数が1人増えています。問合せ基準を満たすデータは増えていますが、ファジー読取りとは異なり、すでに読み取ったデータは変更されていません。
シリアライゼーションアノマリー(Serialization Anomaly)
シリアライゼーションアノマリーは PostgreSQL にしか記載されていない問題です。
ドキュメントには以下のように書かれています。
複数のトランザクションを正常にコミットした結果が、それらのトランザクションを1つずつあらゆる可能な順序で実行する場合とは一貫性がない。
ちょっと何を言っているのかわからないですね……。実際に実行してみて試してみます。
まずは Docker を使用して PostgreSQL を実行させましょう。
# Docker で PostgreSQL を起動させる
$ docker run --rm -d -p 5432:5432 -e POSTGRES_HOST_AUTH_METHOD=trust postgres
# 起動した PostgreSQL に接続する(予め PostgreSQL をインストールしておいてください)
$ psql -h localhost -p 5432 -U postgres
データベースを作成し tests テーブルを作成します。
-- サンプル用のデータベースを作成する
CREATE DATABASE sample;
-- 作成したデータベースを選択
\c sample
-- サンプル用のテーブルを作成する
CREATE TABLE tests (id serial PRIMARY KEY, type VARCHAR(255));
tests テーブルは以下のようになるようデータを追加します。
| id | type |
|---|---|
| 1 | hoge |
| 2 | fuga |
| 3 | hoge |
| 4 | fuga |
| 5 | hoge |
-- サンプルデータを追加する
INSERT INTO tests (id, type)
SELECT 1 AS id, 'hoge' AS type
UNION ALL SELECT 2 AS id, 'fuga' AS type
UNION ALL SELECT 3 AS id, 'hoge' AS type
UNION ALL SELECT 4 AS id, 'fuga' AS type
UNION ALL SELECT 5 AS id, 'hoge' AS type
;
psql で実際にシリアライゼーションアノマリーの例外を出してみる。
-- トランザクション1で実行(更新すると type カラムが全て hoge になる
BEGIN ISOLATION LEVEL SERIALIZABLE;
UPDATE tests SET type = 'hoge' WHERE type = 'fuga';
COMMIT;
-- トランザクション2で実行(更新すると type カラムが全て fuga になる
BEGIN ISOLATION LEVEL SERIALIZABLE;
UPDATE tests SET type = 'fuga' WHERE type = 'hoge';
COMMIT;
下記のようなメッセージが表示されます。
ERROR: could not serialize access due to read/write dependencies among transactions
DETAIL: Reason code: Canceled on identification as a pivot, during commit attempt.
HINT: The transaction might succeed if retried.
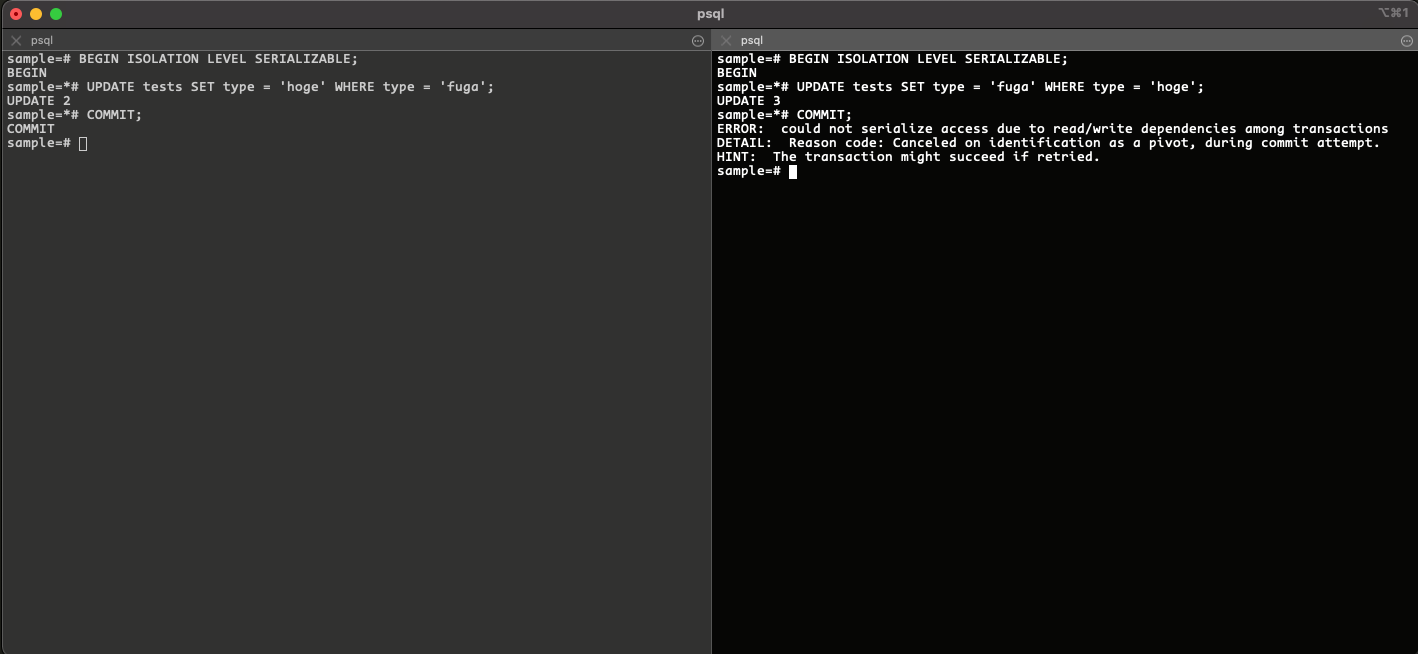
今回の例だと実行する UPDATE 文の実行順が変わることによって tests テーブルの内容が変わってしまいます。
実行順が変わると type が全て hoge か fuga のどちらかになってしまいます。こういった例のことを シリアライゼーションアノマリー と言うそうです。
分離レベルの種類と発生する問題の関係
トランザクション分離レベルは4種類あります。下記は分離レベルごとに発生しうる問題の一覧になります。
| 分離レベル | Dirty Read | Fuzzy Read | Phantom Read | パフォーマンス | デフォルト設定 |
|---|---|---|---|---|---|
| READ UNCOMMITTED | ⭕ | ⭕ | ⭕ | 🏃🏃🏃🏃 | |
| READ COMMITTED | ❌ | ⭕ | ⭕ | 🏃🏃🏃 | PostgreSQL, SQL Server, Oracle |
| REPEATABLE READ | ❌ | ❌ | ⭕ | 🏃🏃 | MySQL |
| SERIALIZABLE | ❌ | ❌ | ❌ | 🏃 |
PostgreSQL だけ Serialization Anomaly があるため少し表が違います。
| 分離レベル | Dirty Read | Fuzzy Read | Phantom Read | Serialization Anomaly |
|---|---|---|---|---|
| READ UNCOMMITTED | ⭕ (許容されるが発生しない) | ⭕ | ⭕ | ⭕ |
| READ COMMITTED | ❌ | ⭕ | ⭕ | ⭕ |
| REPEATABLE READ | ❌ | ❌ | ⭕ (許容されるが発生しない) | ⭕ |
| SERIALIZABLE | ❌ | ❌ | ❌ | ❌ |
ではそれぞれの分離レベルについて説明していきます。
READ UNCOMMITTED
Dirty Read, Fuzzy Read, Phantom Read の全てが発生しうる分離レベルです。
READ UNCOMMITTED と呼ばれている通り、確定されていないデータまで読み取る ためトランザクションの並行処理によってデータの正確性が損なわれる可能性がかなり高いです。
Oracle には用意されていない分離レベルのようです。
ではそれぞれのデータベースではどんな風に書かれているか見ていきましょう。
トランザクション間にもっとも少ない量の保護を提供する 分離レベル。
クエリーは、通常は別のトランザクションを待機する状況で進行することを許可される ロック戦略を採用します。 ただし、この追加パフォーマンスには、ほかのトランザクションによって変更されたけれどもまだコミットされていないデータ (ダーティー読み取りと呼ばれます) など、結果の信頼性の低いという犠牲が伴います。
PostgreSQLのリードアンコミッティドモードは、リードコミッティドのように動作します。
これは、PostgreSQLの多版型同時実行制御という仕組みに標準の分離レベルを関連付ける実際的な方法がこれしかないからです。
SQL Server - READ UNCOMMITTED より
他のトランザクションで変更されたが、まだコミットされていない行を、ステートメントで読み取れるように指定します。
READ COMMITTED
Fuzzy Read, Phantom Read のが発生しうる分離レベルです。
READ COMMITTED と呼ばれている通り、確定したデータを常に読み取る ためトランザクション内で再度読み込みを行った時、自身または別のトランザクションで変更された内容を読み取ってしまうことがあります。
PostgreSQL, SQL Server, Oracle のデフォルトの分離レベル になります。
ではそれぞれのデータベースではどんな風に書かれているか見ていきましょう。
分離レベルの 1 つ。パフォーマンスを向上させるために、トランザクション間の保護を一部緩和するロック戦略を使用します。
トランザクションは、ほかのトランザクションからのコミットされていないデータを見ることはできませんが、現在のトランザクションが開始したあとに別のトランザクションによってコミットされるデータを見ることはできます。
したがって、トランザクションは不良データを見ることはありませんが、見るデータはある程度ほかのトランザクションのタイミングに依存する場合があります。
PostgreSQL - リードコミッティド分離レベル より
PostgreSQLではリードコミッティドがデフォルトの分離レベルです。
トランザクションがこの分離レベルを使用すると、SELECT問い合わせ(FOR UPDATE/SHARE句を伴わない)はその問い合わせが実行される直前までにコミットされたデータのみを参照し、まだコミットされていないデータや、その問い合わせの実行中に別の同時実行トランザクションがコミットした更新は参照しません。
SQL Server - READ COMMITTED より
他のトランザクションで変更されたが、まだコミットされていないデータを、ステートメントで読み取れないように指定します。
これにより、ダーティ リードを防ぐことができます。 現在のトランザクション内にある各ステートメント間では、他のトランザクションによるデータの変更が可能です。この結果、反復不能読み取りやファントム データが発生することがあります。 このオプションは SQL Server 既定値です。
デフォルトのコミット読取り分離レベルでは、トランザクションによって実行されるすべての問合せにおいて、トランザクション開始前ではなく、問合せ開始前にコミット済のデータのみが戻されます。
この分離レベルは、トランザクションの競合がほとんど発生しないデータベース環境に適しています。
REPEATABLE READ
Phantom Read が発生しうる分離レベルです。
REPEATABLE READ と呼ばれている通り、読取り対象のデータを常に読み取る ため同じトランザクション内は再度読み込みを行っても毎回同じ値を読み込めるが、他のトランザクションで追加、削除したデータが読み取られてしまう可能性がある。
MySQL のデフォルトの分離レベル になります。
ではそれぞれのデータベースではどんな風に書かれているか見ていきましょう。
InnoDB のデフォルトの分離レベル。
クエリー対象の行が他の transactions によって変更されないようにするため、反復不可能な読み取りはブロックされますが、phantom の読取りはブロックされません。 トランザクション内のすべてのクエリーが同じスナップショットからのデータを見る、つまりトランザクションが開始した時点のデータを見るように、適度に厳密なロック戦略を使用します。
PostgreSQL - リピータブルリード分離レベル より
リピータブルリード分離レベルは、トランザクションが開始される前までにコミットされたデータのみを参照します。
コミットされていないデータや、そのトランザクションの実行中に別のトランザクションでコミットされた変更を参照しません。 (しかし、その問い合わせと同じトランザクション内で行われた過去の更新は、まだコミットされていませんが、参照します。)
これはSQLの標準規格で求められるものよりもより強く保証するもので、直列化異常を除いて、表 13.1で述べている現象をすべて防ぎます。
上で述べたように、これは標準規格によって明示的に許容されているもので、標準ではそれぞれの分離レベルが提供しなくてはならない最小の保護のみが示されています。
SQL Server - REPEATABLE READ より
他のトランザクションで変更されたがコミットされていないデータを、ステートメントで読み取れないように指定すると共に、現在のトランザクションが完了するまでは現在のトランザクションで読み取ったデータを他のトランザクションが変更できないように指定します。
読取り専用分離レベルはシリアライズ可能分離レベルと類似していますが、読取り専用トランザクションでは、SYSユーザー以外はトランザクションでデータを変更できません。
このため、読取り専用トランザクションでは、ORA-08177エラーは発生しません。読取り専用トランザクションは、トランザクション開始時点での一貫性を保つ必要があるレポートの生成に役立ちます。
SERIALIZABLE
最も強い分離レベルで安全にデータの操作が可能だが、パフォーマンスはあまりよくない。
SERIALIZABLE と呼ばれている通り、トランザクションの処理が 直列で実行した結果 と同じになります。
ではそれぞれのデータベースではどんな風に書かれているか見ていきましょう。
最も保守的なロック戦略を使用して、このトランザクションによって読み取られたデータが他の transactions によって挿入または変更されないようにする分離レベル。
この方法では、トランザクション内で同じクエリーを何度も実行でき、そのたびに同じ結果セットを取得することを保証できます。 現在のトランザクションが開始してから別のトランザクションによってコミットされたデータを変更しようとすると、現在のトランザクションは待機します。
シリアライザブル分離レベルは、最も厳しいトランザクションの分離性を提供します。
このレベルではトランザクションが同時にではなく、次から次へと、あたかも順に実行されているように逐次的なトランザクションの実行を全てのコミットされたトランザクションに対しエミュレートします。
次のことを指定します。
- 他のトランザクションで変更されたが、まだコミットされていないデータは、ステートメントで読み取れない。
- 現在のトランザクションが完了するまで、現在のトランザクションで読み取ったデータは他のトランザクションで変更できない。
- 現在のトランザクションが完了するまで、現在のトランザクションの任意のステートメントで読み取ったキー範囲に該当するキー値の行は、他のトランザクションで新しく挿入できない。
シリアライズ可能分離レベルでは、問合せ開始時ではなく、トランザクション開始時にコミット済の変更およびこのトランザクション自体が行った変更のみを参照できます。シリアライズ可能トランザクションは、他のユーザーがデータベースのデータを変更していないように認識される環境内で動作します。
MultiVersion Concurrency Control(MVCC)
REPEATABLE READ では Phantom Read が起こるためそれを考慮したプログラミングが必要かと思います。
しかし実際は Phantom Read の問題は発生しません。
なぜなら MultiVersion Concurrency Control(MVCC) という技術により問題は発生しないようになっているためです。
MVCC は 書き込み直前の状態(スナップショット)をデータベースが管理している ため、トランザクション内で書き込み直前の状態(スナップショット)を読み込むことで別のトランザクションで書き込まれたものが読み込まれることが無いようになっています。
PostgreSQL の表に 許容するが発生しない という表記があったと思いますがこれは MVCC の技術により発生しないようになっているからです。詳しい仕組みについては以下の資料を参照するとよいでしょう。
- MVCC による PostgreSQL の並列性 | Heroku Dev Center
- MySQL :: MySQL 8.0 リファレンスマニュアル :: 15.3 InnoDB マルチバージョン
- MySQLのMVCC - Qiita
まとめ
データベースによってデフォルトの設定が違うしそのまま使用した時にどういった問題が起こるのか把握しておくことが出来たのでまとめてみてよかったです。
PostgreSQL だけ独自の挙動があったので、今後どのデータベースを選択すべきかを考える1つの判断材料になりました。
データベースの技術選定という話だと MySQL の 5系では結合アルゴリズムが Nested Loops Join しかないし分析関数がなかったりまた PostgreSQL には Row Level Security(行セキュリティポリシー) があったりとエンジニアは何を選択して何を切るのか難しい世界だと感じる今日このごろです。