従来のデータレイクの技術的課題をicebergは解消してくれる
- レコード変更による小さなファイルの生成により読み取り性能劣化
- 不整合が発生しうる(プロセス間の絡む更新のタイミングがずれて不整合とか
- 同時実行制御あり
- read→メタデータロードした時点のsnap書と参考しているためその後の更新の影響を受けない。
- write→楽観的並行性制御なので完全に保証はできない
- 同時実行制御あり
- 基本バックトラックみたいな機能がない
- Time Travelクエリがある(auroraのバックトラックみたいなイメージかと)
- テーブル操作に時間がかかる(ネトフリの例だとexplainだけで10分くらいかかった)
- メタデータを利用したプルーニングでスキャンが高速化
- スキーマ変更への追従が大変(スキーマ定義変更に伴いメタデータも変更する必要がありその手間がかかる)
- Icebergスキーマの更新は メタデータの変更そのため、更新を実行するためにデータファイルを書き換える必要なし
- 効率良いクエリのために物理構造把握する必要がある(ある程度whereとかで絞ってあげないと効率が悪い)
- hidden partitioningなるものでレイアウトに関するクエリを記載しなくて良い。勝手にプルーニングしてくれる
Icebergの課題
-
icebergは論理削除のために削除ファイルが作成されてそれがマージされたら削除されるため、オーバーヘッドの懸念があるため
- 削除ファイルをデータファイルに纏めるコンパクション運用が必要
-
スナップショットやバージョン管理のおかげで同時実行制御、タイムトラベル、ロールバックができるがストレージコストがかかる
- 定期削除する運用が必要
-
同時書き込み失敗時などにストレージに不要なファイルが溜まる→
- 定期的にクリーンアップする必要がある
- 競合が発生した場合は、手動でのクリーンアップが必要になることもある
-
RDSMSの代替にはならない(※SQLコマンドはサポートしている)
- テーブル単位でトランザクションが分離されるため
- レコードの一意性は保証されない
- OLAP指向で低遅延や大量かつ高頻度の同時書き込みに特化していない
へえ
s3汎用バケットでもIcebergを利用できる→あくまでテーブルフォーマットとしてのなので
汎用性バケットはカスタマイズが高い一方で運用負荷が高い(key,prefixはユーザ設計)というところ
S3tablesはkey,prefixなどの運用管理は自動
→汎用にあって tablesにない機能
S3汎用バケットとS3tablesによる構造の違いは以下

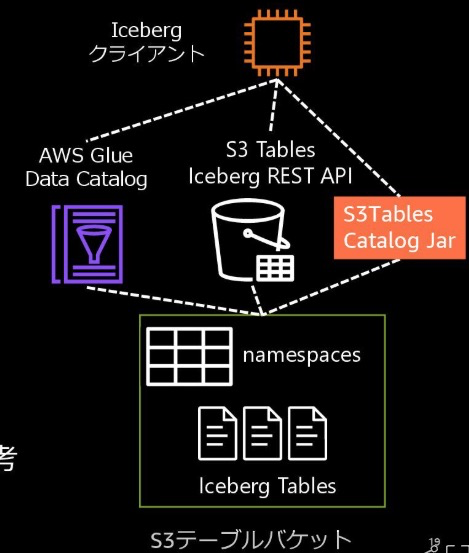
参考:https://speakerdeck.com/simosako/apache-iceberg-to-amazon-s3-tables?slide=18
こちらはデータ構造がすごく参考になる
https://speakerdeck.com/okaru/apache-iceberg
き

参考:https://docs.aws.amazon.com/AmazonS3/latest/userguide/s3-tables-integrating-aws.html
ソース:
https://aws.amazon.com/jp/blogs/news/manage-concurrent-write-conflicts-in-apache-iceberg-on-the-aws-glue-data-catalog/
https://aws.amazon.com/jp/blogs/news/interact-with-apache-iceberg-tables-using-amazon-athena-and-cross-account-fine-grained-permissions-using-aws-lake-formation/
https://bering.hatenadiary.com/entry/2025/01/18/234339
https://docs.aws.amazon.com/ja_jp/prescriptive-guidance/latest/apache-iceberg-on-aws/introduction.html
https://docs.aws.amazon.com/AmazonS3/latest/userguide/s3-tables.html
https://aws.amazon.com/jp/blogs/news/manage-concurrent-write-conflicts-in-apache-iceberg-on-the-aws-glue-data-catalog/
https://zenn.dev/dataheroes/articles/iceberg-the-definitive-guide-summary
https://speakerdeck.com/handy/20241220-s3-tablesnoshi-ifang-wojian-zheng-sitemita?slide=10
https://iceberg.apache.org/spark-quickstart/
https://www.google.com/search?q=s3+tables+aws+slide&sca_esv=905f7b0eae3ddda1&biw=1280&bih=1226&ei=LzA1aMezH7-k2roPxpnAgQI&ved=0ahUKEwiHh4S02cKNAxU_klYBHcYMMCAQ4dUDCBA&uact=5&oq=s3+tables+aws+slide&gs_lp=Egxnd3Mtd2l6LXNlcnAiE3MzIHRhYmxlcyBhd3Mgc2xpZGUyBRAhGKABMgUQIRigATIFECEYoAEyBRAhGKABMgUQIRifBUjYElAIWJ4RcAJ4AJABAJgBiAGgAesFqgEDMi41uAEDyAEA-AEBmAIJoAKIBsICCBAAGIAEGLADwgIHEAAYsAMYHsICCRAAGLADGAgYHsICBRAAGIAEwgIGEAAYFhgewgILEAAYgAQYhgMYigXCAggQABiABBiiBMICBRAAGO8FwgIEECEYFcICBhAAGA0YHsICBxAhGKABGAqYAwCIBgGQBgqSBwMzLjagB8wjsgcDMS42uAeDBg&sclient=gws-wiz-serp
https://speakerdeck.com/okaru/apache-iceberg
https://zenn.dev/shigeru_oda/articles/19b8c20ab44c67
https://speakerdeck.com/sagara/snowflakenokai-fa-yun-yong-kosutowoapache-icebergdexiao-lu-hua-siyou-ji-neng-tohuo-yong-li-nogoshao-jie
https://dev.classmethod.jp/articles/awsbasics-s3-tables-athena-apache-iceberg/
https://speakerdeck.com/simosako/apache-iceberg-to-amazon-s3-tables
https://speakerdeck.com/bering/apache-iceberg-woxue-bi-amazon-s3-tables-wohuo-yong-siyou
https://aws.amazon.com/jp/solutions/guidance/migrating-tabular-data-from-amazon-s3-to-s3-tables/
https://speakerdeck.com/handy/20241220-s3-tablesnoshi-ifang-wojian-zheng-sitemita
https://aws.amazon.com/jp/blogs/news/replicate-changes-from-databases-to-apache-iceberg-tables-using-amazon-data-firehose/
https://bering.hatenadiary.com/entry/2023/07/17/235246
https://www.snowflake.com/ja/guides/what-are-apache-iceberg-tables/