はじめに
本記事では、Adult Income データに対してロジスティック回帰(LR)を適用し、線形モデルがどの特徴量に重みを置いているのかを確認します。
具体的には、標準化した説明変数を用いて学習した際の係数(coef)を確認し、数値特徴量(NUM_COLS)の分布(赤:>50K、青:<=50K)とあわせて観察します。
前処理として、数値特徴量の欠損値処理およびカテゴリ変数の one-hot エンコーディングを行っています。
学習後の係数(coef)
| No | feature | Type | coef | abs_coef |
|---|---|---|---|---|
| 1 | capital-gain | NUM | 2.369197 | 2.369197 |
| 2 | marital-status_Married-civ-spouse | CAT | 0.737401 | 0.737401 |
| 3 | education_Preschool | CAT | -0.542018 | 0.542018 |
| 4 | marital-status_Never-married | CAT | -0.509156 | 0.509156 |
| 5 | education-num | NUM | 0.391563 | 0.391563 |
| 6 | hours-per-week | NUM | 0.376800 | 0.376800 |
| 7 | age | NUM | 0.312555 | 0.312555 |
| 8 | relationship_Own-child | CAT | -0.306367 | 0.306367 |
| 9 | capital-loss | NUM | 0.258429 | 0.258429 |
| 10 | relationship_Wife | CAT | 0.252896 | 0.252896 |
| 11 | occupation_Priv-house-serv | CAT | -0.252376 | 0.252376 |
| 12 | occupation_Other-service | CAT | -0.248173 | 0.248173 |
| 13 | occupation_Exec-managerial | CAT | 0.246674 | 0.246674 |
| 14 | marital-status_Divorced | CAT | -0.225327 | 0.225327 |
| 15 | sex_Male | CAT | 0.196429 | 0.196429 |
| 16 | sex_Female | CAT | -0.196429 | 0.196429 |
| 17 | occupation_Farming-fishing | CAT | -0.186420 | 0.186420 |
| 18 | relationship_Not-in-family | CAT | 0.151212 | 0.151212 |
| 19 | marital-status_Separated | CAT | -0.147457 | 0.147457 |
| 20 | education_Bachelors | CAT | 0.146747 | 0.146747 |
上位の係数を見ると、capital-gain が突出して大きな値をとっていることが分かります。次いで、education-num、hours-per-week、age といった数値特徴量が続いており、線形モデルがこれらの量的な情報に強く依存していることが確認できます。
一方で、marital-status や relationship、occupation などのカテゴリ特徴量も上位に現れており、属性情報も一定の影響を持っていることが分かります。
全体として、数値特徴量が主軸となりつつ、いくつかのカテゴリ特徴量が補助的に作用している構造が見て取れます。
数値特徴量(NUM_COLS)の分布(赤:>50K、青:<=50K)
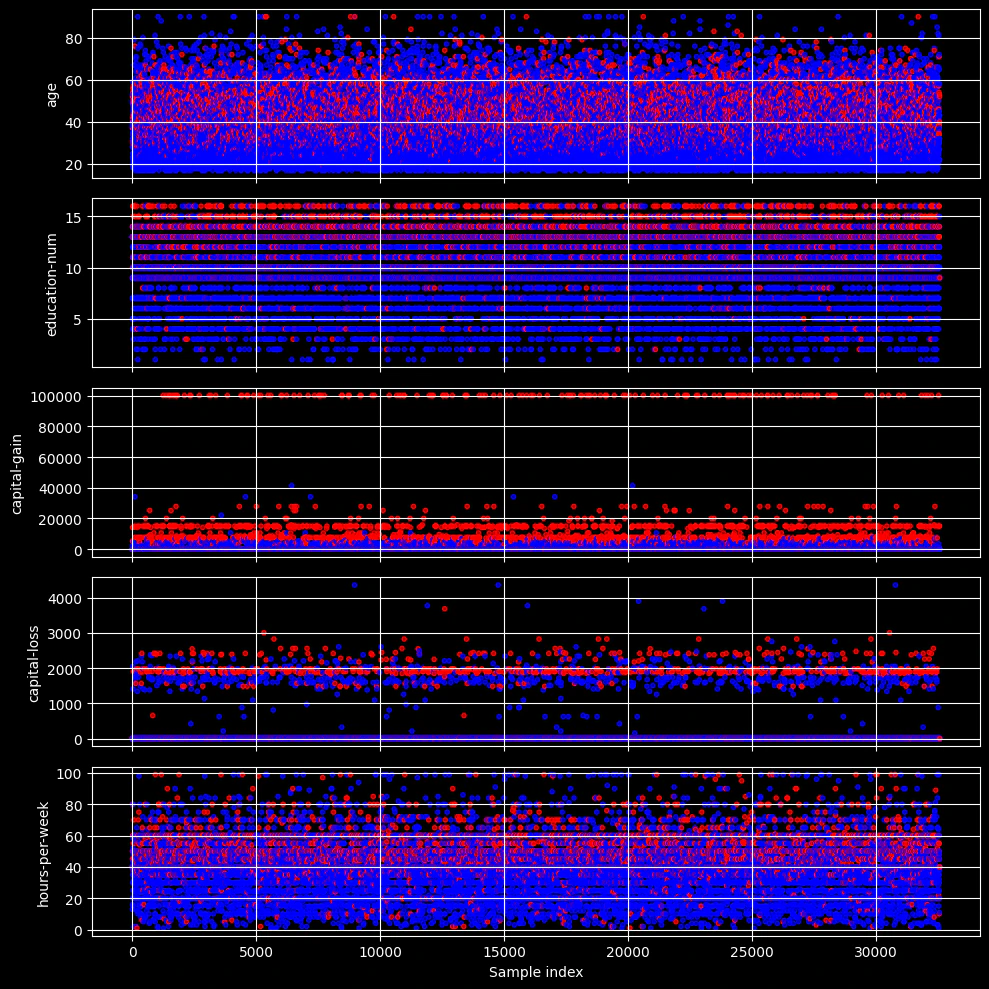
capital-gain では赤(>50K)が高値側に比較的はっきり現れています。一方で、education-num や hours-per-week、age では赤がやや高めに寄る傾向はあるものの、青(<=50K)との重なりも大きいです。
図を見ると、単一の特徴量だけで明確に分かれるというよりは、いくつかの数値特徴量に見られる偏りが重なっているように見えます。
係数の大きさとあわせてみると、capital-gain が突出している点は分布の様子とも整合しています。education-num や hours-per-week、age も上位に位置しており、散布図で見られた傾向と対応しています。
係数上位の特徴量は、分布上でもある程度の偏りを持っており、線形モデルがこうした特徴量を中心に判定している様子がうかがえます。
感想
係数と分布を並べてみることで、線形モデルがどの方向を重視しているのかを少し具体的にイメージできました。
単に数値を眺めるだけでなく、分布とあわせて見ることでモデルの挙動がより直感的に捉えられるように感じます。
Github
プロジェクト全体・Notebook・コードはこちら: