はじめに
社内でAWS DeepRacer人口が増えてきており、ちょっと乗り遅れてしまった人向けにAWS DeepRacer勉強会基礎編を社内で開催したのでその内容を公開します。
本記事では基礎編のハイパーパラメータについて解説しています。
その他の勉強会の内容については、以下の記事をご確認ください。
- 社内勉強会:AWS DeepRacer基礎編(モデル作成)を開催した
- 社内勉強会:AWS DeepRacer基礎編(ログ取得)を開催した
- 社内勉強会:AWS DeepRacer応用編(ログの分析・可視化)を開催した
ハイパーパラメータ概要
ハイパーパラメータとは、機械学習アルゴリズムの挙動を制御するために人が設定するパラメータのことです。
AWS DeepRacerでは以下のハイパーパラメータが使用されています。
| ハイパーパラメータ | 有効な値 | 意味 |
|---|---|---|
| 勾配降下のバッチサイズ | 32/64/128/256/512 | 直近の車両エクスペリエンスの数はエクスペリエンスバッファから無作為に抽出され、基盤となるニューラルネットワークの重みを更新するために使用されます。 |
| エポック数 | 3-10 | 勾配降下中にニューラルネットワークの重みを更新するためにトレーニングデータを通過する回数です。 |
| 学習率 | 1e-8 - 1e-3 | 学習率は、勾配降下の更新がネットワークの重みにどれだけ寄与するかを制御します。 |
| エントロピー | 0 - 1 | ポリシーに無作為性を追加するタイミングを決定するために使用されます。 |
| 割引係数 | 0 - 1 | 将来の報酬が期待される報酬にどのくらい寄与するかを指定します。 |
| 損失タイプ | 平均二乗誤差/Huber損失 | ネットワークの重みを更新するために使用される損失(目的)関数のタイプを指定します。 |
| 各ポリシー更新反復間のエクスペリエンスエピソードの数 | 5 - 100 | ポリシーネットワークの重み付けを学習する ためのトレーニングデータを取得するために使用されるエクスペリエンスバッファのサイズ。 |
出典)AWS DeepRacer開発者ガイド > モデルのトレーニングと評価 >
AWS DeepRacerコンソールを使用したモデルのトレーニングと評価 >ハイパーパラメータを体系的に調整する
用語の定義
ハイパーパラメータの意味を理解する上で必要な用語の定義を確認します。
- エピソード:車両が任意の出発点から出発し、最終的にトラックを完走するかまたはトラックから外れるまでの期間
-
エクスペリエンスバッファ:トレーニング中にさまざまな長さの一定数のエピソードにわたって収集された多数の順序付けられたデータ点
- エピソードの集合体
- エクスペリエンスバッファからランダムに抽出したデータを用いてモデルの学習を行う
ハイパーパラメータのイメージ
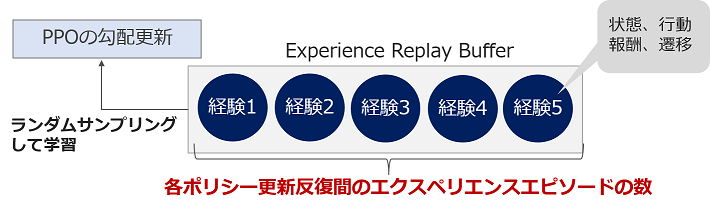
各ポリシー更新反復間のエクスペリエンスエピソード数
AWS DeepRacerで使用している強化モデルのトレーニングアルゴリズムは**PPO(Proximal Policy Optimization)**です。
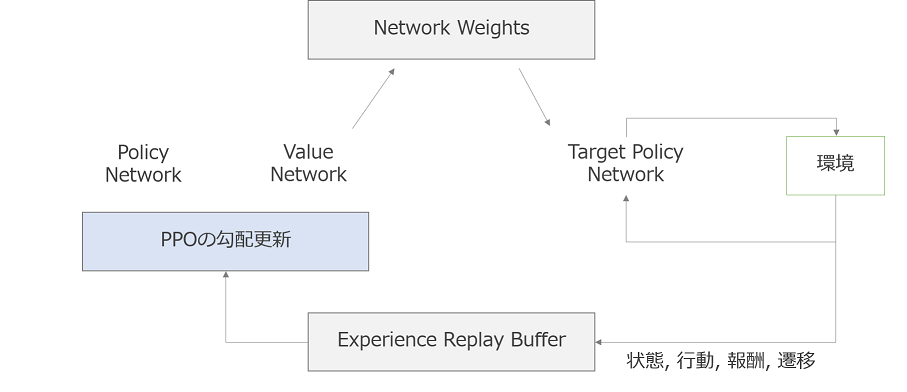
Experience Replay Buffer及び、ハイパーパラメータの各ポリシー更新反復間のエクスペリエンスエピソード数のイメージは以下になります。
勾配降下のバッチサイズ・エポック数・学習率・損失タイプ
AWS DeepRacer含む機械学習が目指すものは、モデルの予測値と実際値との誤差をなくすことです。
モデルの予測値と損失値の差を損失関数で定義し、損失関数の最小値を求めることが機械学習の目指すものと言い換えることができます。
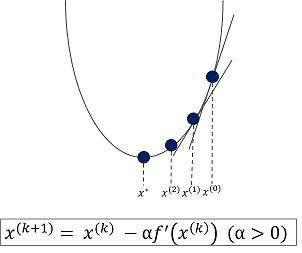
一般に、機械学習では勾配降下法という手法を用いて最適解(損失関数の最小値)を探索します。
勾配降下法のイメージは以下の図のようになります。
損失タイプ
AWS DeepRacerでは、モデルの予測値と絶対値の差に使われる損失関数を、平均二乗誤差とHuber損失から選択することができます。
学習率
**学習率(α)**は一度でどれだけ学習を進めるかを定義しています。値を大きくするとより早く学習が進みますが、大きくしすぎると発散する危険があります。反対に、小さくするとより細かく学習できますが、局所解に陥るなどの危険があります。
エポック数
**エポック数(k)**は、1つの学習データを繰り返し学習する回数になります。エポック数は過学習が起きず、学習データでの精度と検証データでの精度がともに高くなるような値に指定する必要があります。
勾配降下のバッチサイズ
学習データセットをサブセットに分けたときのデータ数です。
エントロピー
エントロピーは**「わからなさ」「不確実性」「予測できなさ」**の意味であり、AWS DeepRacerではエントロピーを大きくするほど、アクションスペースを広く探索することになります。つまり、訓練中のアクションスペースの選択にランダム性を持たせることができます。
割引係数
将来の報酬を算出する式は以下の式で定義されています。
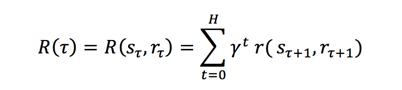
**割引係数(γ)**は、将来の報酬が期待される報酬にどれだけ影響を及ぼすか、つまり、実行するアクションを決める上でどれだけ将来を考慮するかを示しています。
例)
- γ=0の場合:現在の状態・行動だけを考慮
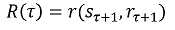
- γ=0.9の場合:ある程度近い未来を考慮
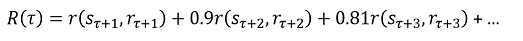
ハイパーパラメータの考察
数値を上げたときのメリットデメリットの考察は以下になります。
| パラメータ | メリット | デメリット |
|---|---|---|
| 勾配降下のバッチサイズ | 重みの更新が安定化する | トレーニングに必要な時間が長くなる |
| エポック数 | トレーニングの精度を上げることが可能 | トレーニングに必要な時間が長くなる |
| 学習率 | 早くトレーニングさせることが可能 | 報酬が収束しづらくなる |
| エントロピー | 行動にランダム性を持たせることが可能 | トレーニングに必要な時間が長くなる |
| 割引係数 | 将来のステップを考慮したうえでアクションスペースを選択 | トレーニングに必要な時間が長くなる |
| 各ポリシー更新反復間のエクスペリエンスエピソードの数 | 重みの更新が安定化する | トレーニングに必要な時間が長くなる |
まとめ
本記事では、AWS DeepRacerで使用されるハイパーパラメータについての解説を行いました。
解釈に間違いがあるかもしれませんが、ご容赦いただければと思います。